【Java开发】Spring Cloud 08 :链路追踪
任何一个架构难免会出现bug,微服务相比于单体架构日志查询更为困难,因此spring cloud推出了Sleuth等组件的链路追踪技术来实现报错信息的定位及查询。
项目源码:尹煜 / coupon-yinyu · GitCode
1 调用链追踪
我们可以想象这样一个场景,你负责的是一个庞大的电商微服务架构系统,每个服务之间都有复杂的上下游调用关系,而且并发量还不小,每秒上万 QPS 不在话下。
在这个微服务系统中,用户通过浏览器的 H5 页面访问系统,这个用户请求会先抵达微服务网关组件,然后网关再把请求分发给各个微服务。所以你会发现,用户请求从发起到结束要经历很多个微服务的处理,这里面还涉及到消息组件的集成。
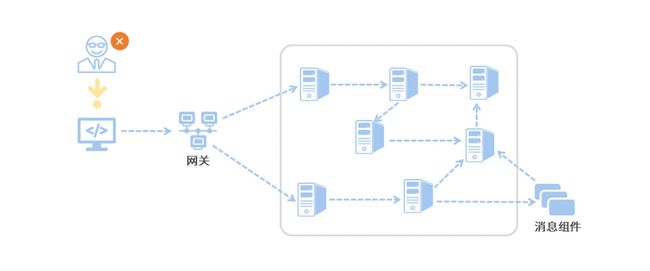
现在问题来了,突然有一天,有用户上报,说他在页面端看到了一个报错,每次点击下单都会报一个 500 错误。如果问题被交到了你手上,你该怎么排查呢?
作为开发人员我们知道 500 错误是 Internal Server Error,这个异常可能发生在任何阶段,就算在同一时刻也可能有多条不同服务的 Error 日志。在一个没有链路追踪的微服务系统里,线上 Bug 排查无异于大海捞针,因为你根本无法梳理出一次请求的前后调用链。
因为缺少订单 ID 之类的唯一主键,你就很难缩小排查范围,只能耗费大量的时间用肉眼走查每一条日志。你需要找到用户所有下单记录的起始 log,从前往后挨个摸排,从蛛丝马迹中梳理服务调用之间的关系并定位最终的问题,可见这种方式十分低效。
如果你想提高线上异常排查的效率,那么首先要做的一件事就是:将一次调用请求中所有访问到的微服务日志前后串联起来。这就像拔出萝卜带出泥一样,只要你找到了本次调用的任何一条日志,你就可以顺藤摸瓜将前后的关联日志信息全部找到。这就是“调用链追踪”技术要完成的工作了。
那么调用链追踪是如何实现日志信息串联的呢?简单来说,链路追踪技术会为每次服务调用生成一个全局唯一的 ID(后面我们叫它 Trace ID),从本次服务调用的起点到终点,这个过程中的所有日志信息都会被打上 Trace ID 的烙印。这样一来,根据日志中的 Trace ID,我们就能很清晰地梳理出一次服务请求前后都经过了哪些微服务节点。
就像下面这张图一样,我们将调用链追踪应用到线上 Bug 排查的场景之后,一整条调用链(实线箭头)已是跃然纸上。我们只要找出当前用户下单请求的任意一条日志,就能根据这条日志中的 Trace ID 将整个调用链拎出来,到底是哪个服务调用环节的异常导致了用户下单失败,我们也就一目了然了。

2 Sleuth 介绍
接下来了解一下 Spring Cloud 的链路追踪组件 Sleuth 是如何实现链路追踪的,也就是分析它的底层逻辑。
调用链追踪有两个任务,一是标记出一次调用请求中的所有日志,二是梳理日志间的前后关系。前面提到了一个 Trace ID,它是用来标记调用链的全局唯一 ID。你一定可以联想到,Trace ID 完成的是第一个任务:标记。不过呢,Trace ID 并不能表达日志信息的前后关系,那么 Sleuth 是如何解决这个问题的呢?
Sleuth 是通过打入到 Log 中的“卧底”来串联前后日志的。你集成了 Sleuth 组件之后,它会向你的日志中打入三个“特殊标记”,其中一个标记你应该已经清楚了,那便是 Trace ID。剩下的两个标记分别是 Span ID 和 Parent Span ID,这俩用来表示调用的前后顺序关系。
所谓 Span,它是 Sleuth 下面的一个基本工作单元,当服务请求抵达当前单元时,Sleuth 就会为这个单元分配一个独一无二的 Span ID,并标记单元的开始时间和结束时间,这样就可以记录每个单元的处理用时了。
而 Parent Span ID 呢,顾名思义,它指向了当前单元的父级单元,也就是上游的调用者。一个环环相扣的调用链就通过 Parent Span ID 被串了起来。
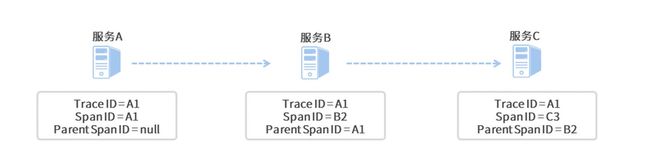
从上面的图中可以看出,这个服务请求调用了三个微服务,分别为服务 A、服务 B 和服务 C。在一条调用链中,不管你调用了多少个微服务,Sleuth 为本次调用生成的全局唯一 Trace ID 都会贯穿整个链路,所图中三个微服务所对应的日志 Trace ID 都是 A1。
由于服务 A 是调用链的起点,所以它并没有父级单元,因此它的 Parent Span ID 为空,而起始单元的 Span ID 和 Trace ID 则是相同的,值都为 A1。对于服务 B 来说,它的父级调用单元是服务 A,因此它的 Parent Span ID 指向了服务 A 的 Span ID,即 A1;同理,服务 C 的 Parent Span ID 指向了服务 B 的 Span ID,即 B2。
当然啦,上面的图示只是一个简化的流程,在实际的项目中,一次服务调用可不光只会生成一个 Span。比如说服务 A 请求通过 OpenFeign 组件调用了服务 B,那么服务 A 接收用户请求的过程就是一个单元,而 OpenFeign 组件发起远程调用的过程又是另一个单元,由此可见单元的颗粒度其实是非常小的。
通过这些 Sleuth 的特殊标记,我们就可以根据时间顺序,将一次服务请求经过的调用节点都梳理出来,这样你就能迅速发现报错信息发生在哪个阶段。下边是使用 Zipkin 生成的链路追踪的可视化信息。你可以看出,每个服务调用都以时间先后顺序规整好了,红色的部分就是发生线上 Exception 的服务。

除了 Trace 和 Span 之外,Sleuth 还有一个特殊的数据结构,叫做 Annotation,被用来记录一个具体的“事件”。
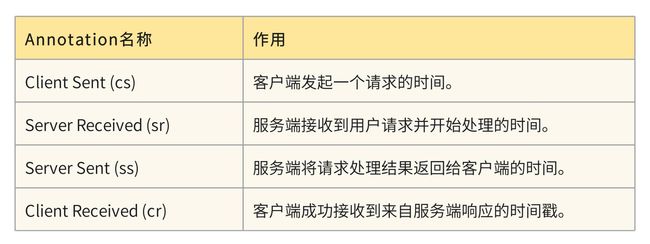
以服务 A 调用服务 B 的场景来说,服务 A 是一个 Client,也就是发起调用的一方,而服务 B 是一个 Server,也就是处理请求的一方。

如果你用服务 B 的 ss 减去 sr,你就可以得到请求在服务 B 阶段的处理时间;如果用服务 B 的 sr 减去服务 A 的 cs,就可以得到服务 A 到服务 B 之间的网络调用延迟时间;如果用服务 A 的 cr 减去 cs,就可以得到当次请求从发起到结束所花费的总时间。
本项目将使用业界主流的 Sleuth + Zikpin + ELK 构建起这套完整的线上异常排查流程。
3 集成 Sleuth 和 Zipkin
3.1 实现链路打标
我们的微服务模块在运行过程中会输出各种各样的日志信息,为了能在日志中打印出特殊的标记,我们需要将 Sleuth 的打标功能集成到各个微服务模块中。Sleuth 提供了一种无感知的集成方案,只需要添加一个依赖项,再做一些本地启动参数配置就可以开启打标功能了,整个过程不需要做任何的代码改动。
所以第一步,我们需要将 Sleuth 的依赖项添加到模板服务、优惠计算服务和用户服务的 pom.xml 文件中。
org.springframework.cloud
spring-cloud-starter-sleuth
第二步,我们打开微服务模块的 application.yml 配置文件,在配置文件中添加采样率和每秒采样记录条数。
spring:
sleuth:
sampler:
# 采样率的概率,100%采样
probability: 1.0
# 每秒采样数字最高为1000
rate: 1000你可以从代码中看到,配置文件里设置了一个 probability,它应该是一个 0 到 1 的浮点数,用来表示采样率。这里设置的 probability 是 1,就表示对请求进行 100% 采样。如果我们把 probability 设置成小于 1 的数,就说明有的请求不会被采样。如果一个请求未被采样,那么它将不会被调用链追踪系统 Track 起来。
你还会在代码中看到 rate 参数,它代表每秒最多可以对多少个 Request 进行采样。这有点像一个“限流”参数,如果超过这个阈值,服务请求仍然会被正常处理,但调用链信息不会被采样。
到这里,我们的 Sleuth 集成工作就已经搞定了。这时你只要启动项目,顺手调用几个 API,就能在控制台的日志信息里看到 Sleuth 默认打印出来的 Trace ID 和 Span ID。比如这里调用了 Customer 服务的优惠券查询接口,在日志中,你可以看到两串随机生成的数字和字母混合的 ID,其中排在前面的那个 ID 就是 Trace ID,而后面则是 Span ID。
DEBUG [coupon-customer-serv,69e433d6432522e4,936d8af942b703d2] 81584
--- [io-20002-exec-1] c.g.c.customer.feign.TemplateService:xxxx3.2 Sleuth 打标原理
以 Customer 微服务为例,在我们访问 findCoupon 接口查询优惠券的时候,用户微服务通过 OpenFeign 组件向 Template 微服务发起了一次查询请求。
Sleuth 为了将 Trace ID 和 Customer 服务的 Span ID 传递给 Template 微服务,它在 OpenFeign 的环节动了一个手脚。Sleuth 通过 TracingFeignClient 类,将一系列 Tag 标记塞进了 OpenFeign 构造的服务请求的 Header 结构中。
半仙老师在 TracingFeignClient 的类中打了一个 Debug 断点,将 Request 的 Header 信息打印了出来:

在这个 Header 结构中,我们可以看到有几个以 X-B3 开头的特殊标记,这个 X-B3 就是 Sleuth 的特殊接头暗号。其中 X-B3-TraceId 就是全局唯一的链路追踪 ID,而 X-B3-SpanId 和 X-B3-ParentSpandID 分别是当前请求的单元 ID 和父级单元 ID,最后的 X-B3-Sampled 则表示当前链路是否是一个已被采样的链路。通过 Header 里的这些信息,下游服务就完整地得到了上游服务的情报。
以上是 Sleuth 对 OpenFeign 动的手脚。为了应对调用链中可能出现的各种不同组件,Sleuth 内部构造了各式各样的适配器,用来在不同组件中使用同样的接头暗号“X-B3-*”,这样就可以传递链路追踪的信息。如果你对这部分的源码感兴趣,你可以深入研究 spring-cloud-sleuth-instrumentation 和 spring-cloud-sleuth-brave 两个依赖包的源代码,了解更加详细的实现过程。
搞定了链路打标之后,我们怎样才能通过 Trace ID 来查询链路信息呢?这时就要找 Zipkin 来帮忙了。
3.3 Zipkin 收集并查看链路数据
Zipkin 是一个分布式的 Tracing 系统,它可以用来收集时序化的链路打标数据。通过 Zipkin 内置的 UI 界面,我们可以根据 Trace ID 搜索出一次调用链所经过的所有访问单元,并获取每个单元在当前服务调用中所花费的时间。(个人认为对于小型项目来说,Zipkin没有必要)
为了搭建一条高可用的链路信息传递通道,以 RabbitMQ 作为中转站,让各个应用服务器将服务调用链信息传递给 RabbitMQ,而 Zipkin 服务器则通过监听 RabbitMQ 的队列来获取调用链数据。相比于让微服务通过 Web 接口直连 Zipkin,使用消息队列可以大幅提高信息的送达率和传递效率。
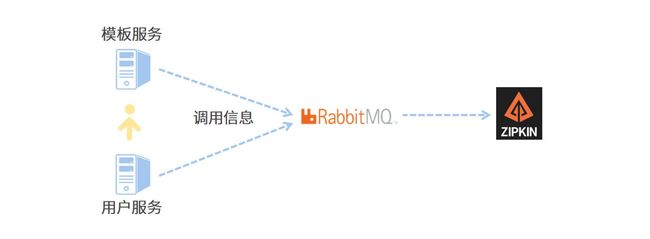
下面手动搭建 Zikpin 服务器。
① 搭建 Zipkin 服务器
首先,我们要下载一个 Zipkin 的可执行 jar 包,这里推荐使用 2.23.9 版本的 Zipkin 组件。你可以通过访问maven 的中央仓库下载 zipkin-server-2.23.9-exec.jar 文件,这边已将版本参数添加到了地址中,不过你可以将地址超链接复制出来,通过修改 URL 中的版本参数来下载指定版本。
搭建 Zipkin 有两种方式,一种是直接下载 Jar 包,这是官方推荐的标准集成方式;另一种是通过引入 Zipkin 依赖项的方式,在本地搭建一个 Spring Boot 版的 Zipkin 服务器。如果你需要对 Zipkin 做定制化开发,那么可以采取后一种方式。
接下来,我们需要在本地启动 Zipkin 服务器。我们打开命令行,在下载下来的 jar 包所在目录执行以下命令,就可以启动 Zipkin 服务器了。
java -jar zipkin-server-2.23.9-exec.jar --zipkin.collector.rabbitmq.addresses=localhost:5672要注意的是,命令行中设置了 zipkin.collector.rabbitmq.addresses 参数,所以 Zipkin 在启动阶段将尝试连接 RabbitMQ,你需要确保 RabbitMQ 始终处于启动状态。Zipkin 已经为我们内置了 RabbitMQ 的默认连接属性,如果没有特殊指定,那么 Zipkin 会使用 guest 默认用户登录 RabbitMQ。如果你想要切换用户、指定默认监听队列或者设置连接参数,那么可以在命令行中添加以下参数进行配置。

启动成功后,你可以在命令行看到 Zipkin 的特色 Logo,以及一行 Serving HTTP 的运行日志。
最后,我们只需要验证消息监听队列是否已就位就可以了。我们使用 guest 账号登录 RabbitMQ,并切换到“Queues”面板,如果 Zipkin 和 RabbitMQ 的对接一切正常,那么你会在 Queues 面板下看到一个名为 zipkin 的队列,如下图所示。

到这里,我们就完成了 Zipkin 服务器的创建。接下来,你还需要将应用程序生成的链路数据发送给 Zipkin 服务器。
② 传送链路数据到 Zipkin
方案中使用 RabbitMQ 作为中转站来传递链路调用数据,因此应用程序并不需要直连 Zipkin,而是需要接入到 RabbitMQ,并将链路数据发布到 RabbitMQ 中的“zipkin”队列中就可以了。
首先,我们需要在每个微服务模块的 pom.xml 中添加 Zipkin 适配插件和 Stream 的依赖。其中,Stream 是 Spring Cloud 中专门用来对接消息中间件的组件。
org.springframework.cloud
spring-cloud-sleuth-zipkin
org.springframework.cloud
spring-cloud-stream-binder-rabbit
接下来,我们需要将 Zipkin 的配置信息添加到每个微服务模块的 application.yml 文件中。
在配置项中,通过 zipkin.sender.type 属性指定了传输类型为 RabbitMQ,除了 RabbitMQ 以外,Zipkin 适配器还支持 ActiveMQ、Kafka 和直连的方式,推荐你使用 Kafka 和 RabbitMQ 来保证消息投递的可靠性和高并发性。 spring.zipkin.rabbitmq 属性声明了消息组件的连接地址和消息投递的队列名称。
spring:
zipkin:
sender:
type: rabbit
rabbitmq:
addresses: 127.0.0.1:5672
queue: zipkin有一点你需要注意,在应用中指定的队列名称,一定要同 Zipkin 服务器所指定的队列名称保持一致,否则 Zipkin 无法消费链路追踪数据。
到这里,我们就完成了一套完整的链路追踪系统的搭建,是不是很简单呢?接下来,就可以把你的应用启动起来,通过 Postman 发起几个跨服务的调用了。
4 ELK 实现日志检索
前边我们借助 Sleuth 和 Zikpin 的合力,搭建了一套调用链追踪系统,它可以帮助我们串联调用链中的上下游访问单元,快速定位线上异常出现在哪个环节。不过呢,光有 Tracing 能力似乎还不够,如果我们想要更深一步调查异常背后的原因,那必须完整还原这个异常问题的案发现场。
在线上环境中,我们无法像操作本地开发环境一样去打断点一步步调试问题,服务器的 Remote Debug 端口通常也是被禁用的,我们唯一能重现案发现场的途径就是日志信息。因此,我们还要去构建一套日志检索系统,作为线上异常排查的辅助工具。
4.1 ELK介绍
ELK 并不是一个技术框架的名称,它其实是一个三位一体的技术名词,ELK 的每个字母都来自一个技术组件,它们分别是 Elasticsearch(简称 ES)、Logstash 和 Kibana。取这三个组件各自的首字母,就组成了所谓的 ELK。

Logstash 扮演了一个日志收集器的角色。它可以从多个数据源对数据进行采集,也可以对数据做初步过滤和清洗,比如将数据转换成通用格式、隐匿敏感数据等。
Elasticsearch 是一个分布式的搜索和数据分析引擎。它在整套方案中扮演了日志存储和分词器的角色。Elasticsearch 会收到来自 Logstash 的日志信息,并将这些日志信息集中存储起来。同时,Elasticserch 还对外提供了多种 RESTful 风格的接口,上层应用可以通过这些接口完成数据查找和分析的任务。
Kibana 在整个 Elastic 方案中扮演了一个“花瓶”的角色。它提供了一套 UI 界面,让我们可以对 Elasticsearch 中存储的数据进行查找。同时,它还提供了各种统计报表的功能,如柱状图、饼图、时序统计分析、图谱关联分析等等。当然了,报表数据都来自于 Elasticsearch。
现在,你已经了解了 Elasticsearch、Logstash 和 Kibana 的用途和三者间的关系。接下来,我们就来动手搭建 ELK 环境。
4.2 搭建 ELK 环境
我们有两种搭建 ELK 环境的方法,一种是分别搭建 Elasticsearch、Logstash 和 Kibana 的集群,并将这些组件相互集成起来。就算我们可以通过 Docker 技术分别搭建三者的镜像环境,环境配置和启动异常排查还是有些麻烦的,很容易劝退初学者。
因此,这里推荐你使用一种更简单的搭建方式,那就是直接下载 sebp/elk 镜像。因为 sebp/elk 镜像已经为我们集成了完整的 ELK 环境,只需要稍加配置就能迅速构建 ELK 环境,而且异常排查也比较方便。为了安装 sebp/elk 镜像,你要先确保本地电脑上已经安装了 Docker 环境。
① 下载 ELK 镜像
搭建 ELK 环境的第一步,就是下载 sebp/elk 镜像。你可以在命令行运行以下命令,来下载 7.16.1 标签的镜像文件。因为镜像文件相当庞大,所以这个下载过程是非常漫长的。
docker pull sebp/elk:7.16.1为什么需要你选择 7.16.1 标签呢?因为默认情况下,docker 会尝试获取 LASTEST 标签也就是最新版本的镜像文件,而 Elastic 的版本一直处于不断更新发布的过程中。为了保证你能获得和本节课一致的集成体验,推荐使用同样的镜像版本。
在这里重点提醒两个点:
一定要记得尽可能多给 Docker 容器分配一些内存。否则,Elasticsearch 很容易启动失败,要知道 ES 可是一个非常吃内存的组件,推荐为 Docker 分配不低于 5G 的内存。
低配电脑可以降低 ELK 镜像版本。如果你的电脑配置比较吃紧,无法分配高内存,那么你可以尝试获取更低版本的 ELK 组件,因为版本越高对系统的资源要求越高。你可以在Docker Hub上查看 sebp/elk 镜像的版本信息,再选择适合自己电脑配置的进行下载。
② 创建 ELK 容器
你可以在命令行使用如下命令创建并启动一个 ELK 容器,在这段命令中,Elasticsearch、Logstash 和 Kibana 指定的启动端口分别为 9200、5044 和 5601。命令中的–name elk 参数指定了新创建的 Container 的名称为“elk”,当然了,这里你可以更换成自己喜欢的名称。
sudo docker run -p 5601:5601 -p 9200:9200 -p 5044:5044 -it --name elk sebp/elk这里要注意的是,以上命令只用在容器创建的时候执行一次即可。一旦容器被创建完成,后续你就可以使用 docker 的标准命令来启动、关闭和重启容器了。
上面这行命令不光会创建容器,还会尝试启动 ELK 的组件,这个过程可能会花费几分钟。你可以在浏览器中访问“localhost:9200”来验证 ES 是否成功被启动,正常情况下,你应该能在浏览器中看到 ES 集群的版本号等信息,这就说明 ES 启动成功了。
而 Kibana 的启动时间会更长一些,你可以在浏览器中访问“localhost:5601”来访问 Kibana 的网页。
如果启动过程中出现异常,你可以从启动日志中找到异常原因。首先你需要执行下面的命令,进入到 Container 内部。然后,使用 cd 命令进入到 /var/log 文件夹,在这里你可以找到 ES、Logstash 和 Kibana 的启动日志,查看具体的报错。
docker exec -it elk /bin/bash接下来,我们需要对 Logstash 配置项做一些修改,定义数据传输方式。
③ 配置 Logstash
我们使用 docker exec 命令进入到 elk 容器之后,需要使用编辑器打开 /etc/logstash/conf.d/02-beats-input.conf 文件,它是用来配置 Logstash 的输入输出源的文件。你可以使用 vi 命令或者 vim 命令进入文件编辑模式,接下来你需要将文件中的内容替换为以下配置项。
input {
tcp {
port => 5044
codec => json_lines
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "yinyu"
}
}在上面的文件中,指定 Logstash 使用 TCP 插件作为数据输入源,并从 5044 端口收集数据,格式为 JSON,你可以通过这个链接访问 TCP 插件的完整参数列表。
同时,这边还通过 output 参数将处理过后的日志数据输出到了 ES 组件中,这里配置了 ES 的地址和数据索引,你可以点击这里的链接获取 ES 插件的详细信息。修改完成之后记得一定要保存文件。
Logstash 支持多种类型的输入和输出源,你可以结合自己的项目架构,选择适合的数据源。如果你对这部分内容感兴趣,可以分别参考以下的两个配置文档:
Input plugins
Output plugins
接下来,你还需要在容器外部执行下面这行命令,通过重启 ELK 容器,让 Logstash 重新加载最新的配置项。
docker restart elk到这里,ELK 容器就配置完成了,接下来我们需要将微服务生成的日志发送到 ELK 容器中。
4.3 对接 ELK 容器
应用程序对接 ELK 的过程很简单,只有两处改动,一处是添加依赖项,另一处是添加 logback 配置文件。
首先,你需要为三个微服务项目添加 logstash-logback-encoder 依赖项,它提供了对接 Logstash 的日志输出组件,这里使用了 7.0.1 的稳定版本。
net.logstash.logback
logstash-logback-encoder
7.0.1
接下来,你需要在每个项目的 src/main/resources 路径下创建 logback-spring.xml 组件,在这个文件中,我们定义了两个 Appender 用来输出日志信息。
第一个是 ConsoleAppender,它可以将日志信息打印到控制台上。这里使用了 Spring Boot 默认的日志格式。
DEBUG
${CONSOLE_LOG_PATTERN}
utf8
第二个是 LogstashTcpSocketAppender,由于我们在 ELK 容器中指定了使用 TCP 的方式接收日志信息,所以这个 Appender 对象专门用来构建 JSON 格式化数据发送到 Logstash。在下面的代码中,你可以看到日志的主体信息,以及 Span、Trace 等链路追踪信息作为了 JSON 数据的一部分。
127.0.0.1:5044
UTC
{
"severity": "%level",
"service": "${applicationName:-}",
"trace": "%X{traceId:-}",
"span": "%X{spanId:-}",
"pid": "${PID:-}",
"thread": "%thread",
"class": "%logger{40}",
"rest": "%message"
}
这里贴出的只是 logback-spring.xml 文件的一部分,你可以到代码仓库查看完整的代码。
到这里,我们就完成了所有的对接工作。接下来,你只要在本地启动微服务项目,然后发起几个服务调用,生成一些 Log 文件,我们就能够在 Kibana 中查看到日志信息了。
4.4 查看 Kibana 日志信息
当 ELK 容器处于运行状态时,你可以在浏览器中打开“localhost:5601”地址访问 Kibana 系统。不过,在使用 Kibana 做日志查询之前,你还需要添加一个 Index。这里所说的 Index 其实是 ES 中的一个查询参数。
由于之前在 ELK 容器的 Logstash 配置项中指定了 Index=yinyu,这个值会作为 Index 参数,Logstash 向 ES 传输日志信息的时候,会将“yinyu”写入 ES。
为了简化配置,所有的日志信息都归在了 yinyu 这个索引之下,当然了,你也可以在 Logstash 配置文件中通过表达式动态生成 Index 的值。
如果你有了一个 Trace ID 或者 Span ID,那么你可以直接在 Kibana 的 Discover 页面查询这个 ID 对应的所有详细日志信息。当然了,根据 ES 对日志的分词结果,你还可以借助 Kibana 的 KQL 表达式构造复杂查询条件。

到这里,我们就完成了线上日志查询系统的搭建,当然ELK是相对来说较为高端了,对于小型项目来说更为简单的实现方式就行。
总结
本章节通过 ELK 镜像搭建了一套完整的日志查询系统,这个过程中的重点是配置 Logstash 的输入输出数据源。出于简化难度的目的,这里没有使用 filebeat 或者 kafka 之类的输入源,而是使用了 TCP Socket 方式,让业务系统直接把日志信息传输到 Logstash。从高可用的角度出发,我们通常并不会将业务系统与 Logstash 直连,取而代之的是将日志写入本地文件,然后通过 Filebeat 之类的工具收集本地 log 文件,并传输给 Logstash。