Python爬虫实战(四):利用代理IP爬取某瓣电影排行榜并写入Excel(附上完整源码)
1. 爬虫和代理IP的关系
爬虫是指通过编写程序自动获取互联网上的信息的技术。爬虫可以模拟人的行为,在网页上浏览、点击、输入数据等,从而获取网页上的各种信息,如文本、图片、视频等。爬虫可以用于各种目的,如搜索引擎的索引、数据分析、信息监测等。
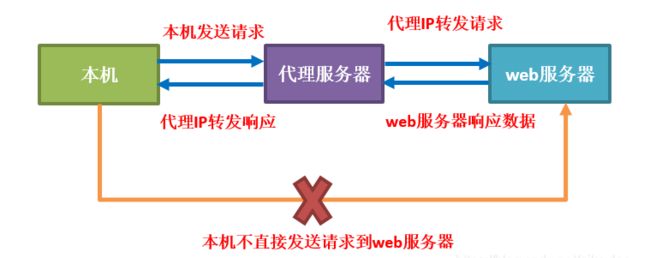
代理IP是指通过中间服务器转发网络请求的技术。在爬虫中,使用代理IP可以隐藏真实的访问源,防止被目标网站封禁或限制访问。代理IP可以分为正向代理和反向代理。正向代理是由客户端主动使用代理服务器来访问目标网站,而反向代理是目标网站使用代理服务器来处理客户端的请求。
2. 使用代理IP的好处
使用代理IP可以带来以下好处:
- 隐藏真实的访问源,保护个人或机构的隐私和安全。
- 绕过目标网站的访问限制,如IP封禁、地区限制等。
- 分散访问压力,提高爬取效率和稳定性。
- 收集不同地区或代理服务器上的数据,用于数据分析和对比。
然而,使用代理IP也存在一些挑战和注意事项:
- 代理IP的质量参差不齐,有些代理服务器可能不稳定、速度慢或存在安全风险。
- 一些目标网站会检测和封禁常用的代理IP,需要不断更换和验证代理IP的可用性。
- 使用代理IP可能增加网络请求的延迟和复杂性,需要合理配置和调整爬虫程序。
- 使用代理IP需要遵守相关法律法规和目标网站的使用规则,不得进行非法活动或滥用代理IP服务。
博主这里使用的亮数据家的动态代理IP,IP质量很高个人感觉还不错,公司用户可以免费使用:点击试用
3. 爬取目标
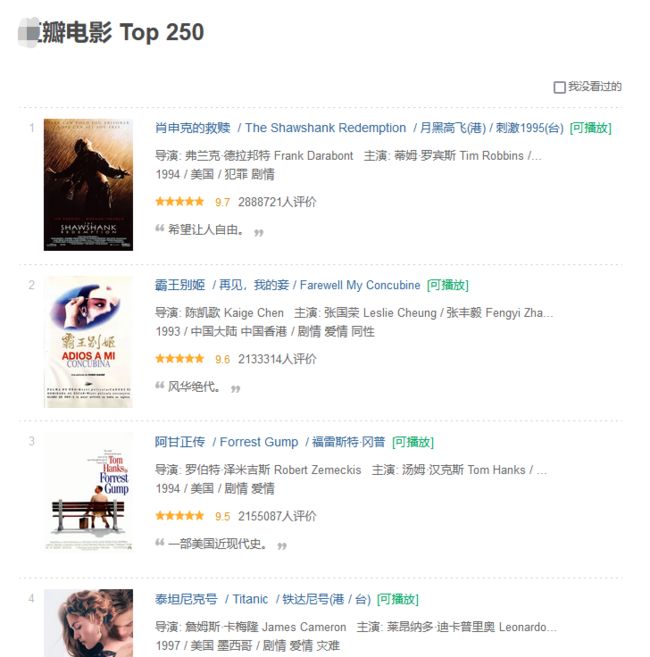
这次爬虫实战的目标是某瓣电影Top250排行榜,爬取的字段:排名、电影名、评分、评价人数、制片国家、电影类型、上映时间、主演、影片链接
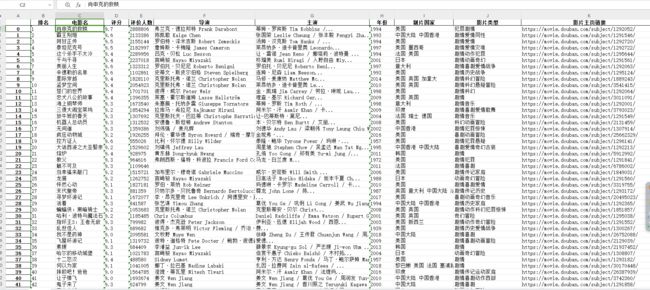
预期效果写入Excel:
4. 准备工作
Python:3.10
编辑器:PyCharm
第三方模块,自行安装:
pip install requests # 网页数据爬取
pip install pandas # 数据处理
pip install xlwt # 写入Excel
pip install lxml # 提取网页数据
5. 爬虫实现
5.1 获取代理IP
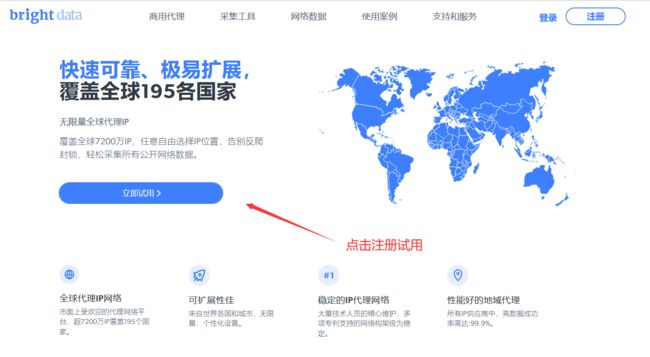
1、打开亮数据的官网,点击立刻使用:点击试用
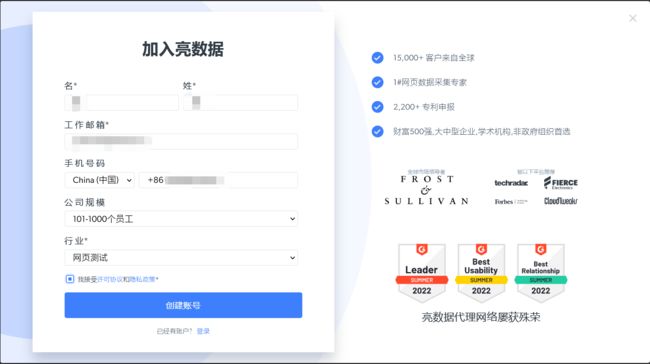
2、输入账号密码注册账号:
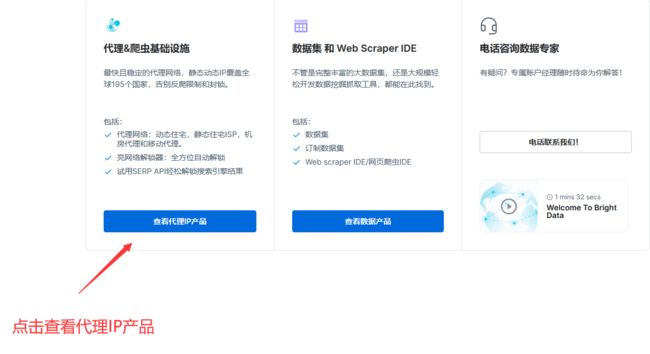
3、注册后以后点击查看代理IP产品:
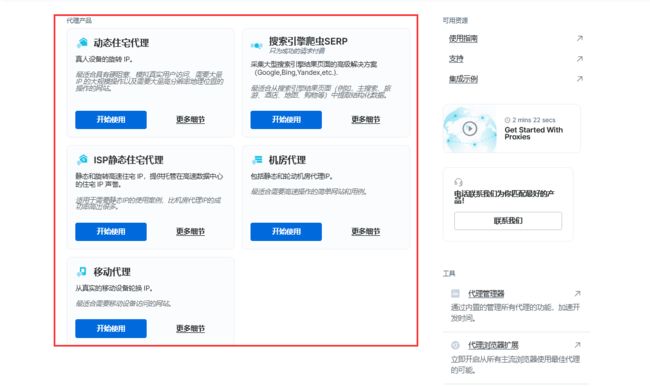
4、选择适合自己ide产品,如果你使用公司邮件注册,可以找客服开通免费试用:
5、获取代理IP后通过proxies参数添加代理发送请求,案例代码:
proxies = {
"http": "http://IP地址:端口号", # http型
"https": "https://IP地址:端口号" # https型
}
response = requests.get(url,headers=headers,proxies=proxies)
5.2 导入模块
import re # 正则,用于提取字符串
import pandas as pd # pandas,用于写入Excel文件
import requests # python基础爬虫库
from lxml import etree # 可以将网页转换为Elements对象
import time # 防止爬取过快可以睡眠一秒
5.3 设置翻页
首先我们来分析一下网站的翻页,一共有10页:

第一页主页为:
https://movie.douban.com/top250?start=0&filter=
第二页:
https://movie.douban.com/top250?start=25&filter=
第三页:
https://movie.douban.com/top250?start=50&filter=
可以看出每页只有start=后面的参数每次上涨25,所以用循环来构造10页网页链接:
def main():
data_list = [] # 空列表用于存储每页获取到的数据
for i in range(10):
url = 'https://movie.douban.com/top250?start='+str(i*25)+'&filter='
5.4 发送请求
这里我们创建一个get_html_str(url)函数传入网页url链接,通过添加请求头和代理IP发送请求获取网页源码(注意:这里代理IP这里需要看5.1 获取代理IP自己去获取,博主的已过期):
def get_html_str(url):
"""发送请求,获取响应"""
# 请求头模拟浏览器
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'}
# 添加代理IP(这里代理IP这里需要看`5.1 获取代理IP`自己去获取,博主的已过期)
proxies = {
"http": "http://183.134.17.12:9181",
}
# 添加请求头和代理IP发送请求
response = requests.get(url,headers=headers,proxies=proxies)
# 获取网页源码
html_str = response.content.decode()
# 返回网页源码
return html_str
5.5 提取数据
当我们拿到网页源码后,创建一个get_data(html_str,data_list)函数传入html_str也就是网页源码、data_list用于存储数据,就可以使用xpath开始解析数据了
1、分析网页结构,可以看到每一个电影都在ol标签下的li标签下:
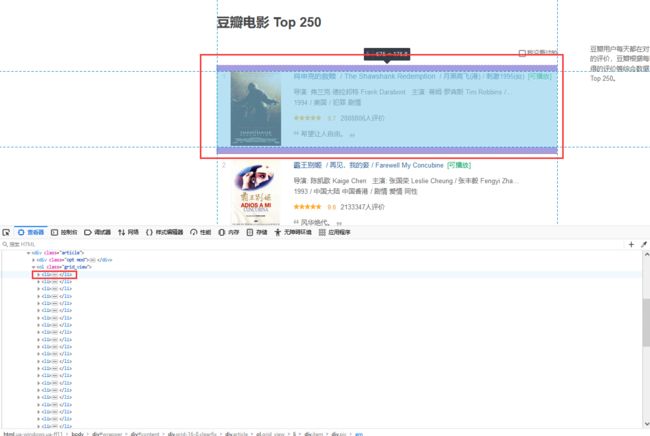
2、然后我们看li标签的数据是否完整,可以看到我们需要的字段都有:
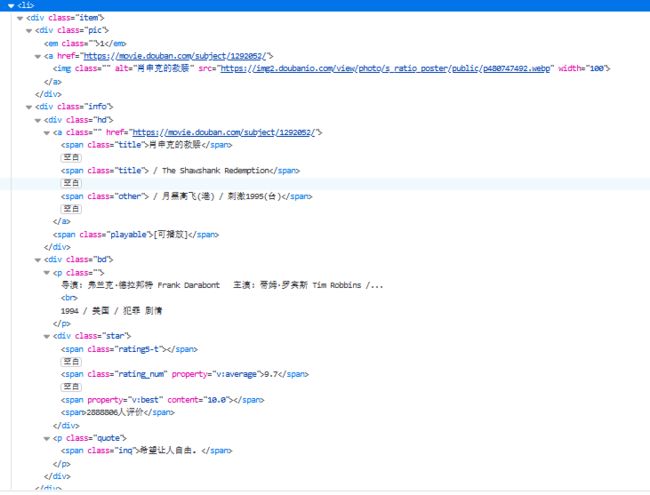
3、接下来开始写解析代码:
def get_data(html_str, data_list):
"""提取数据写入列表"""
# 将html字符串转换为etree对象方便后面使用xpath进行解析
html_data = etree.HTML(html_str)
# 利用xpath取到所有的li标签
li_list = html_data.xpath("//ol[@class='grid_view']/li")
# 打印一下li标签个数看是否和一页的电影个数对得上
print(len(li_list)) # 输出25,没有问题
# 遍历li_list列表取到某一个电影的对象
for li in li_list:
# 用xpath获取每一个字段信息
# 排名
ranking = li.xpath(".//div[@class='pic']/em/text()")[0]
# 电影名
title = li.xpath(".//div[@class='hd']/a/span[1]/text()")[0]
# 评分
score = li.xpath(".//span[@class='rating_num']/text()")[0]
# 评价人数
evaluators_number = li.xpath(".//div[@class='star']/span[4]/text()")[0]
evaluators_number = evaluators_number.replace('人评价', '') # 将'人评价'替换为替换为空,更美观
# 导演、主演
str1 = li.xpath(".//div[@class='bd']/p[1]//text()")[0]
# 利用正则提取导演名
try:
director = re.findall("导演: (.*?)主演", str1)[0]
director = re.sub('\xa0', '', director)
except:
director = None
# 利用正则提取主演
try:
performer = re.findall("主演: (.*)", str1)[0]
performer = re.sub('\xa0', '', performer)
except:
performer = None
# 上映时间、制片国家、电影类型都在这里标签下
str2 = li.xpath(".//div[@class='bd']/p[1]//text()")[1]
#
try:
# 通过斜杠进行分割
str2_list = str2.split(' / ')
# 年份
year = re.sub('[\n ]', '', str2_list[0])
# 制片国家
country = str2_list[1]
# 影片类型
type = re.sub('[\n ]', '', str2_list[2])
except:
year = None
country = None
type = None
url = li.xpath(".//div[@class='hd']/a/@href")[0]
print({'排名': ranking, '电影名': title, '评分': score, '评价人数': evaluators_number, '导演': director,
'主演': performer, '年份': year, '制片国家': country, '影片类型': type, '影片主页链接': url})
data_list.append(
{'排名': ranking, '电影名': title, '评分': score, '评价人数': evaluators_number, '导演': director,
'主演': performer, '年份': year, '制片国家': country, '影片类型': type, '影片主页链接': url})
运行结果:

5.6 保存数据
当我们提取完数据以后就可以写入用pandas写入Excel表格中,创建into_excel(data_list)函数,将存储数据的data_list列表作为参数传入,然后用pandas的to_excel函数写入excel表格:
def into_excel(data_list):
# 创建DataFrame对象
df = pd.DataFrame(data_list)
# 写入excel文件
df.to_excel('电影Top250排行.xlsx')
5.7 调用主函数
第一步设置翻页,然后获取网页源码,接着提取数据,限制爬取的速度,最后写入Excel文件
def main():
data_list = [] # 空列表用于存储每页获取到的数据
# 1. 设置翻页
for i in range(10):
url = 'https://movie.douban.com/top250?start=' + str(i * 25) + '&filter='
# 2. 获取网页源码
html_str = get_html_str(url)
# 3. 提取数据
get_data(html_str, data_list)
# 4. 限制爬取的速度
time.sleep(5)
# 5. 写入excel
into_excel(data_list)
5.8 完整源码
这里附上完整源码(注意:get_html_str(url)函数中的代理IP这里需要看5.1 获取代理IP自己去获取,博主的已过期),然后直接运行程序即可:
import re # 正则,用于提取字符串
import pandas as pd # pandas,用于写入Excel文件
import requests # python基础爬虫库
from lxml import etree # 可以将网页转换为Elements对象
import time # 防止爬取过快可以睡眠一秒
def get_html_str(url):
"""发送请求,获取响应"""
# 请求头模拟浏览器
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'}
# 添加代理IP(这里代理IP这里需要看`5.1 获取代理IP`自己去获取,博主的已过期)
proxies = {
"http": "http://183.134.17.12:9181",
}
# 添加请求头和代理IP发送请求
response = requests.get(url, headers=headers, proxies=proxies) #
# 获取网页源码
html_str = response.content.decode()
# 返回网页源码
return html_str
def get_data(html_str, data_list):
"""提取数据写入列表"""
# 将html字符串转换为etree对象方便后面使用xpath进行解析
html_data = etree.HTML(html_str)
# 利用xpath取到所有的li标签
li_list = html_data.xpath("//ol[@class='grid_view']/li")
# 打印一下li标签个数看是否和一页的电影个数对得上
print(len(li_list)) # 输出25,没有问题
# 遍历li_list列表取到某一个电影的对象
for li in li_list:
# 用xpath获取每一个字段信息
# 排名
ranking = li.xpath(".//div[@class='pic']/em/text()")[0]
# 电影名
title = li.xpath(".//div[@class='hd']/a/span[1]/text()")[0]
# 评分
score = li.xpath(".//span[@class='rating_num']/text()")[0]
# 评价人数
evaluators_number = li.xpath(".//div[@class='star']/span[4]/text()")[0]
evaluators_number = evaluators_number.replace('人评价', '') # 将'人评价'替换为替换为空,更美观
# 导演、主演
str1 = li.xpath(".//div[@class='bd']/p[1]//text()")[0]
# 利用正则提取导演名
try:
director = re.findall("导演: (.*?)主演", str1)[0]
director = re.sub('\xa0', '', director)
except:
director = None
# 利用正则提取主演
try:
performer = re.findall("主演: (.*)", str1)[0]
performer = re.sub('\xa0', '', performer)
except:
performer = None
# 上映时间、制片国家、电影类型都在这里标签下
str2 = li.xpath(".//div[@class='bd']/p[1]//text()")[1]
#
try:
# 通过斜杠进行分割
str2_list = str2.split(' / ')
# 年份
year = re.sub('[\n ]', '', str2_list[0])
# 制片国家
country = str2_list[1]
# 影片类型
type = re.sub('[\n ]', '', str2_list[2])
except:
year = None
country = None
type = None
url = li.xpath(".//div[@class='hd']/a/@href")[0]
print({'排名': ranking, '电影名': title, '评分': score, '评价人数': evaluators_number, '导演': director,
'主演': performer, '年份': year, '制片国家': country, '影片类型': type, '影片主页链接': url})
data_list.append(
{'排名': ranking, '电影名': title, '评分': score, '评价人数': evaluators_number, '导演': director,
'主演': performer, '年份': year, '制片国家': country, '影片类型': type, '影片主页链接': url})
def into_excel(data_list):
# 创建DataFrame对象
df = pd.DataFrame(data_list)
# 写入excel文件
df.to_excel('电影Top250排行.xlsx')
def main():
data_list = [] # 空列表用于存储每页获取到的数据
# 1. 设置翻页
for i in range(10):
url = 'https://movie.douban.com/top250?start=' + str(i * 25) + '&filter='
# 2. 获取网页源码
html_str = get_html_str(url)
# 3. 提取数据
get_data(html_str, data_list)
# 4. 限制爬取的速度
time.sleep(5)
# 5. 写入excel
into_excel(data_list)
if __name__ == "__main__":
main()
程序运行完毕后生成excel文件:
6. 获取免费定制数据
上面我们讲了如何利用Python爬虫获取数据,博主估摸着还是有很多小伙伴不知道怎么写爬虫代码,博主使用亮数据代理IP时偶然发现竟然还有免费的数据集可以下载,不会爬虫和想偷懒的小伙伴可以省事了:
1、进入亮数据官网,点击网络数据,然后点击获取获取免费样本:点击免费领取

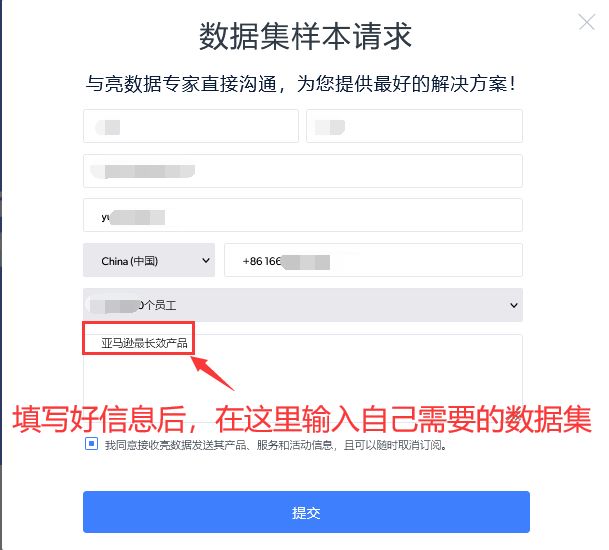
2、输入好个人信息和需要的数据集名称后,点击提交:
3、然后等着客服免费送数据集就可以啦,欧耶:
