python实现逻辑回归-清风数学建模-二分类水果数据
所用数据
二分类水果数据
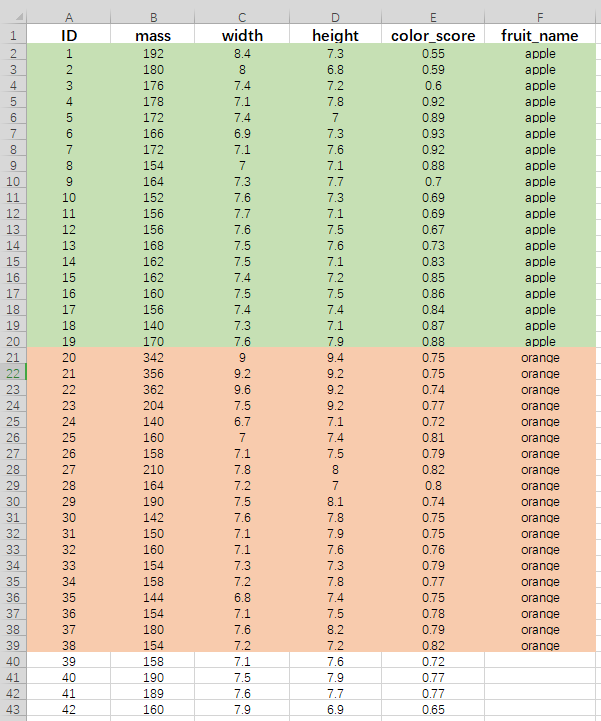
1.数据预处理
可以看到有4个特征,2种分类结果,最后4个没有分类结果的数据是拿来预测的
# 1. 数据预处理
import pandas as pd
df = pd.read_excel('oridata/二分类水果数据.xlsx',usecols=lambda col:col!='ID') #不读入第一列ID
df_willpred = df[df['fruit_name'].isnull()].drop(columns='fruit_name') #把要预测的对象拆分出来(最后4个)
df = df[~df['fruit_name'].isnull()] #去除最后4个数据
X = df.drop(columns='fruit_name') # 取出4列feature
Y = df['fruit_name'] # 取出target
X(特征)

…

Y(target)

2. 数据可视化
# 2. 可视化数据
import seaborn as sns
import matplotlib.pyplot as plt
## 不同特征组合对于不同类别的花的散点分布
sns.pairplot(data=df,hue='fruit_name')# 参数详解:data-数据集,hue-数据集中的目标变量
plt.show()
## 特征箱型图
column_name=list(X.columns)
fig,axes=plt.subplots(2,2,figsize=(10, 5))
idx=0
for i in range(2):
for j in range(2):
sns.boxplot(data=df,x='fruit_name',y=column_name[idx],palette='pastel',ax=axes[i,j])
# 参数详解:data-数据集,x,y-从数据集中取横坐标、纵坐标,palette-调色,ax-子图位置坐标
idx+=1
plt.show()


3. 划分test和train
# 3. 划分test和train
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2,random_state=111)
#参数详解:test_size:用多少样本量做测试集,random_state:随便取数,只是为了每一次运行结果都相同
4.模型搭建
# 4. 模型搭建
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(solver='liblinear',random_state=111) # 初始化模型,sovler为求解器类型,,random_state同上
model.fit(X_train, Y_train) # 训练
5. 模型分类结果和准确率
# 5. 模型分类结果和准确率
## 查看test的分类结果
Y_test_pred = model.predict(X_test)
Y_pred_proba = model.predict_proba(X_test)
Y_train_pred=model.predict(X_train)
tmp = pd.DataFrame()
tmp['Y_test'] = list(Y_test[:20]) #[:20] 只是保证每一列个数相等
tmp['Y_pred_proba'] = list(Y_pred_proba[:20])
tmp['Y_test_pred'] = list(Y_test_pred[:20])
## 模型准确率
from sklearn.metrics import accuracy_score
print("train分类准确率:",accuracy_score(Y_train_pred, Y_train))
print("test分类准确率:",accuracy_score(Y_test_pred, Y_test))
![]()
6. 预测分类
# 6. 预测分类
print(model.predict(df_willpred))
最后四个预测结果:
![]()
7. 计算混淆矩阵
# 7. 混淆矩阵
from sklearn.metrics import confusion_matrix
confusion_matrix_res=confusion_matrix(Y_test,Y_test_pred)
sns.heatmap(data=confusion_matrix_res,annot=True,cmap='Blues')
plt.show()

完整代码
# 1. 数据预处理
import pandas as pd
df = pd.read_excel('oridata/二分类水果数据.xlsx',usecols=lambda col:col!='ID') #不读入第一列ID
df_willpred = df[df['fruit_name'].isnull()].drop(columns='fruit_name') #把要预测的对象拆分出来(最后4个)
df = df[~df['fruit_name'].isnull()] #去除最后4个数据
X = df.drop(columns='fruit_name') # 取出4列feature
Y = df['fruit_name'] # 取出target
# 2. 可视化数据
import seaborn as sns
import matplotlib.pyplot as plt
## 不同特征组合对于不同类别的花的散点分布
sns.pairplot(data=df,hue='fruit_name')# 参数详解:data-数据集,hue-数据集中的目标变量
plt.show()
## 特征箱型图
column_name=list(X.columns)
fig,axes=plt.subplots(2,2,figsize=(10, 5))
idx=0
for i in range(2):
for j in range(2):
sns.boxplot(data=df,x='fruit_name',y=column_name[idx],palette='pastel',ax=axes[i,j])
# 参数详解:data-数据集,x,y-从数据集中取横坐标、纵坐标,palette-调色,ax-子图位置坐标
idx+=1
plt.show()
# 3. 划分test和train
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2,random_state=111)
#参数详解:test_size:用多少样本量做测试集,random_state:随便取数,只是为了每一次运行结果都相同
# 4. 模型搭建
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(solver='liblinear',random_state=111) # 初始化模型,sovler为求解器类型,,random_state同上
model.fit(X_train, Y_train) # 训练
# 5. 模型分类结果和准确率
## 查看test的分类结果
Y_test_pred = model.predict(X_test)
Y_pred_proba = model.predict_proba(X_test)
Y_train_pred=model.predict(X_train)
tmp = pd.DataFrame()
tmp['Y_test'] = list(Y_test[:20]) #[:20] 只是保证每一列个数相等
tmp['Y_pred_proba'] = list(Y_pred_proba[:20])
tmp['Y_test_pred'] = list(Y_test_pred[:20])
## 模型准确率
from sklearn.metrics import accuracy_score
print("train分类准确率:",accuracy_score(Y_train_pred, Y_train))
print("test分类准确率:",accuracy_score(Y_test_pred, Y_test))
# 6. 预测分类
print(model.predict(df_willpred))
# 7. 混淆矩阵
from sklearn.metrics import confusion_matrix
confusion_matrix_res=confusion_matrix(Y_test,Y_test_pred)
sns.heatmap(data=confusion_matrix_res,annot=True,cmap='Blues')
plt.show()
总结
- 先用特征组合展示数据散点图,从直观上看哪些特征能有效区分水果
- 分类准确率不算太高:清风视频里用的spss准确率也只有76%,因此属于正常范围