python爬虫基础入门——利用requests和BeautifulSoup
(本文是自己学习爬虫的一点笔记和感悟)
经过python的初步学习,对字符串、列表、字典、元祖、条件语句、循环语句……等概念应该已经有了整体印象,终于可以着手做一些小练习来巩固知识点,写爬虫练习再适合不过。
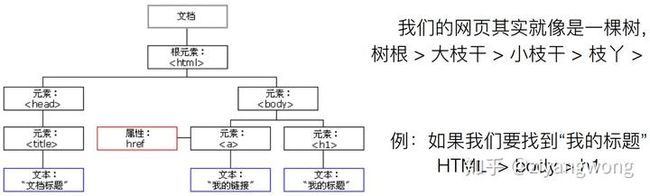
1. 网页基础
爬虫的本质就是从网页中获取所需的信息,对网页的知识还是要有一点了解。百度百科对HTML的定义:HTML,超文本标记语言,是一种标识性的语言。它包括一系列标签.通过这些标签可以将网络上的文档格式统一,使分散的Internet资源连接为一个逻辑整体。HTML文本是由HTML命令组成的描述性文本,HTML命令可以说明文字,图形、动画、声音、表格、链接等。
当然,网页并不仅仅只有HTML,它只能实现静态效果,我们经常看到的网页都还有有美化样式的CSS和实现动态效果的JavaScipt。爬虫对前端语言要求不高,能找到自己需要爬取的信息就足够了,当然有前端基础的童鞋爬虫会更顺手。