Kafka 部署安装及相关操作记录
文章目录
- 安装部署
- Windows
- 启动
- 节点加入退出
- produce 分区策略
- Leader选举流程
- Leader Partition自动平衡
- 消费者
-
- 消费者平衡
- 消费者组
- Rebalance 重平衡
- 压缩算法
- 序列化反序列化
- Broker 重要参数
安装部署
官网安装地址
目前Kafka已经内置了zookeeper,不需要单独下载zookeeper
安装前提,kafka安装运行最低支持jdk7;本篇演示版本是基于jdk1.8
Windows
windows下载后解压即可
进入kafka安装目录
进入conf目录,修改server配置 :
config\server.properties
log.dirs:日志文件修改为自定义的日志目录,我的是

listeners:服务器监听的地址,修改如下(一般默认9092,不需要修改):
listeners=PLAINTEXT://localhost:9092
zookeeper配置文件为zookeeper.properties
只需修改一处,dataDir:zookeeper存储数据的路径修改自定义的目录,要用反斜杠/
# dataDir=/tmp/zookeeper
dataDir=D:\StudyData\MQ\Kafka\kafka_2.13-3.2.1\zookeeper-data
启动
进入kafka安装目录
zookeeper启动 :
.\bin\windows\zookeeper-server-start.bat .\config\zookeeper.properties
kafka ,server启动
.\bin\windows\kafka-server-start.bat .\config\server.properties
创建Topic
.\bin\windows\kafka-topics.bat --create --bootstrap-server localhost:9092 --topic test --partitions 1 --replication-factor 1
选项说明:
–topic 定义 topic 名
–replication-factor 定义副本数
–partitions 定义分区数
查看Topic
.\bin\windows\kafka-topics.bat --list --bootstrap-server localhost:9092
发送消息
>.\bin\windows\kafka-console-producer.bat --broker-list localhost:9092 --topic test
> hello
接收/消费消息
> .\bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic test
hello world
加上重头消费参数 : --from-beginning
修改分区数(注意:分区数只能增加,不能减少)
.\bin\windows\kafka-topics.bat --bootstrap-server hadoop102:9092 --alter --topic first --partitions 3
查看 主题的详情
.\bin\windows\kafka-topics.bat --bootstrap-server hadoop102:9092 --describe --topic first
节点加入退出
服役新节点
创建一个要均衡的主题
[atguigu@hadoop102 kafka]$ vim topics-to-move.json
{
"topics": [
{"topic": "first"}
],
"version": 1
}
生成一个负载均衡的计划
[atguigu@hadoop102 kafka]$ bin/kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092 --topics-to-move-json-file topics-to-move.json --broker-list "0,1,2,3" --generate
Current partition replica assignment
{"version":1,"partitions":[{"topic":"first","partition":0,"replic
as":[0,2,1],"log_dirs":["any","any","any"]},{"topic":"first","par
tition":1,"replicas":[2,1,0],"log_dirs":["any","any","any"]},{"to
pic":"first","partition":2,"replicas":[1,0,2],"log_dirs":["any","
any","any"]}]}
Proposed partition reassignment configuration
{"version":1,"partitions":[{"topic":"first","partition":0,"replic
as":[2,3,0],"log_dirs":["any","any","any"]},{"topic":"first","par
tition":1,"replicas":[3,0,1],"log_dirs":["any","any","any"]},{"to
pic":"first","partition":2,"replicas":[0,1,2],"log_dirs":["any","
any","any"]}]}
创建副本存储计划(所有副本存储在 broker0、broker1、broker2、broker3 中)。
vim increase-replication-factor.json
#输入一下内容
{"version":1,"partitions":[{"topic":"first","partition":0,"replic
as":[2,3,0],"log_dirs":["any","any","any"]},{"topic":"first","par
tition":1,"replicas":[3,0,1],"log_dirs":["any","any","any"]},{"to
pic":"first","partition":2,"replicas":[0,1,2],"log_dirs":["any","
any","any"]}]}
执行副本存储计划
[atguigu@hadoop102 kafka]$ bin/kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092 --reassignment-json-file increase-replication-factor.json --execute
验证副本存储计划
[atguigu@hadoop102 kafka]$ bin/kafka-reassign-partitions.sh --
bootstrap-server hadoop102:9092 --reassignment-json-file increase-replication-factor.json --verify
Status of partition reassignment:
Reassignment of partition first-0 is complete.
Reassignment of partition first-1 is complete.
Reassignment of partition first-2 is complete.
Clearing broker-level throttles on brokers 0,1,2,3
Clearing topic-level throttles on topic first
退役旧节点
先按照退役一台节点,生成执行计划,然后按照服役时操作流程执行负载均衡。
[atguigu@hadoop102 kafka]$ vim topics-to-move.json
{
"topics": [
{"topic": "first"}
],
"version": 1
}
创建执行计划。
[atguigu@hadoop102 kafka]$ bin/kafka-reassign-partitions.sh --
bootstrap-server hadoop102:9092 --topics-to-move-json-file
topics-to-move.json --broker-list "0,1,2" --generate
Current partition replica assignment
{"version":1,"partitions":[{"topic":"first","partition":0,"replic
as":[2,0,1],"log_dirs":["any","any","any"]},{"topic":"first","par
tition":1,"replicas":[3,1,2],"log_dirs":["any","any","any"]},{"to
pic":"first","partition":2,"replicas":[0,2,3],"log_dirs":["any","
any","any"]}]}
Proposed partition reassignment configuration
{"version":1,"partitions":[{"topic":"first","partition":0,"replic
as":[2,0,1],"log_dirs":["any","any","any"]},{"topic":"first","par
tition":1,"replicas":[0,1,2],"log_dirs":["any","any","any"]},{"to
pic":"first","partition":2,"replicas":[1,2,0],"log_dirs":["any","
any","any"]}]}
创建副本存储计划(所有副本存储在 broker0、broker1、broker2 中)
[atguigu@hadoop102 kafka]$ vim increase-replication-factor.json
{"version":1,"partitions":[{"topic":"first","partition":0,"replic
as":[2,0,1],"log_dirs":["any","any","any"]},{"topic":"first","par
tition":1,"replicas":[0,1,2],"log_dirs":["any","any","any"]},{"to
pic":"first","partition":2,"replicas":[1,2,0],"log_dirs":["any","
any","any"]}]}
执行副本存储计划
[atguigu@hadoop102 kafka]$ bin/kafka-reassign-partitions.sh --
bootstrap-server hadoop102:9092 --reassignment-json-file increase-replication-factor.json --execute
验证副本存储计划
[atguigu@hadoop102 kafka]$ bin/kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092 --reassignment-json-file
increase-replication-factor.json --verify
Status of partition reassignment:
Reassignment of partition first-0 is complete.
Reassignment of partition first-1 is complete.
Reassignment of partition first-2 is complete.
Clearing broker-level throttles on brokers 0,1,2,3
Clearing topic-level throttles on topic first
produce 分区策略
分区策略
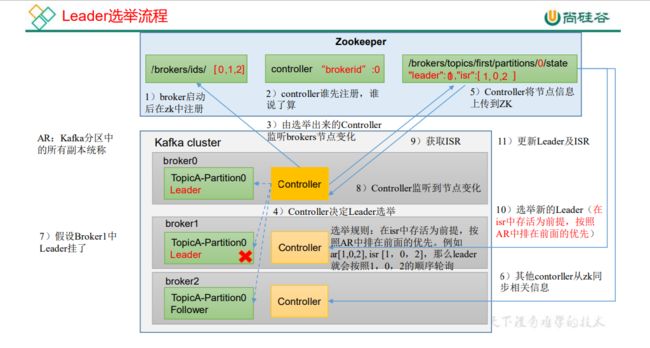
Leader选举流程
kafka leader选举有三种:
- broker leader选举
- partitions副本leader选举
- 消费组leader选举
Broker leader选举
controller知识点
controller知识点
一个broker leader可以理解为一台机器,broker leader主要负责监控管理分区和副本的状态,在分区与副本状态发生变化时做出相应操作。比如:分区的leader副本出现了故障,那么broker leader需要进行分区leader副本的选举。Broker leader称为Controller控制器。
选举过程
broker们会向zk进行节点/controller的创建,谁先创建成功谁就是leader,并将自己的brokerId写入节点的值中,如果其它的broker发现节点的值不为-1,则放弃选举成为follower。
如果这个kafka broker controller宕机了,在zookeeper上面的那个临时节点就会消失,此时所有的kafka broker又会一起去 Zookeeper上注册一个临时节点,因为只有一个Kafka Broker会注册成功,其他的都会失败,所以这个成功在Zookeeper上注册临时节点的这个Kafka Broker会成为Kafka Broker Controller,其他的Kafka broker叫Kafka Broker follower 。
防止脑裂
当旧的leader重新上线后,而集群中新的leader已经选出来了,整个集群就有两个leader,这就是脑裂。如何避免这种情况呢?
Kafka是通过使用epoch number(纪元编号,也称为隔离令牌)来完成的。epoch number只是单调递增的数字,第一次选出Controller时,epoch number值为1,如果再次选出新的Controller,则epoch number将为2,依次单调递增。
每个新选出的controller通过Zookeeper 的条件递增操作获得一个全新的、数值更大的epoch number 。其他Broker 在知道当前epoch number 后,如果收到由controller发出的包含较旧(较小)epoch number的消息,就会忽略它们,即Broker根据最大的epoch number来区分当前最新的controller。
controller的功能
- 监听分区变化,副本选举工作,重分区工作
- 监听主题变化
- 监听broker变化
- auto.leader.rebalance.enble(kafka的均衡机制)如果开启,则定期进行leader选举(不建议开启,对消费者影响较大,见auto.leader.rebalance.enable说明)
controller需要监听zk上数据变化,并同步给其它节点,这些数据有:分区数变化,新的leader副本等。在controller出现之前,所有节点都需要订阅ZK的事件,这会有羊群效应。有了controller之后,会通过一个LindBlockQueue,然后使用一个专有的线程对处理,来避免羊群效应的问题。
分区副本leader选举
分区副本leader选举触发情况:
- 分区副本创建或分区上下线的时候
- 分区副本重新分配,因为需要保持一定负载均衡(分区的时候,数据的均衡保证不了)
- broker节点宕机
- 消费者leader选举
随机的方式,从一个hash列表中取一个消费者作为leader。
leader的选举是因为某一个消费者leader下线了,这时候就出现同一组中消费者数量的变化,这就不得不提到消费组的再均衡。由于一些原因,分区没有人消费了,那么就需要将它们重新分配给新的消费者或者存活着的消费者,这个再均衡的过程会引起stop the world的情况。
哪些情况会发生再均衡的情形呢?
- 同一组中消费者数量发生变化
- 主题的分区数发生变化,加减分区
- 组协调者节点下线
Leader Partition自动平衡
正常情况下,Kafka本身会自动把Leader Partition均匀分散在各个机器上,来保证每台机器的读写吞吐量都是均匀的。但是如果某
些broker宕机,会导致Leader Partition过于集中在其他少部分几台broker上,这会导致少数几台broker的读写请求压力过高,其他宕机的
broker重启之后都是follower partition,读写请求很低,造成集群负载不均衡。
相关配置参数
- auto.leader.rebalance.enable,默认是true。自动Leader Partition 平衡
- leader.imbalance.per.broker.percentage,默认是10%。每个broker允许的不平衡的leader的比率。如果每个broker超过了这个值,控制器会触发leader的平衡。
- leader.imbalance.check.interval.seconds,默认值300秒。检查leader负载是否平衡的间隔时间。
消费者
消费者平衡
每个消费者都会和coordinator保持心跳(默认3s),一旦超时(session.timeout.ms=45s),该消费者会被移除,并触发再平衡;
或者消费者处理消息的时间过长(max.poll.interval.ms5分钟),也会触发再平衡
四种主流的分区分配策略: Range、RoundRobin、Sticky、CooperativeSticky。
消费者组
Consumer Group 是 Kafka 提供的可扩展且具有容错性的消费者机制.
Kafka 仅仅使用 Consumer Group 这一种机制,却同时实现了传统消息引擎系统的两大模型:
如果所有实例都属于同一个 Group,那么它实现的就是消息队列模型;
如果所有实例分别属于不同的 Group,那么它实现的就是发布 / 订阅模型。
Kafka 实现广播消息:不同消费组订阅同一topic即可
Rebalance 重平衡
Rebalance 重平衡
topic下面有4个分区,一个消费者组下面有两个消费者,那么正常情况下每个消费者消费2个分区。但是当某个消费者意外宕机的情况下,kafka会感知到消费这的下线情况,此时,存活的消费者组将消费topic所有分区的数据。简单地理解,这就是Rebalance重平衡做的事情。
触发条件:
- 消费者组发生变更 - 如加入新的消费者实例;消费者实例崩溃等
- 订阅关系发生变化 - 如使用基于正则表达式的订阅,当匹配新topic时 触发重平衡
- topic 分区数发生变化 - 对已有topic集群进行动态扩容 触发重平衡
session.timeout.ms :
kafka消费者管理者用于检测客户端故障的时间间隔。一般而言客户端发送周期性心跳给服务端,表示其存活状态。如果在会话超时到期之前服务端没有收到心跳,则服务端将从消费者组中删除该客户端,并重新启动重平衡。默认值 45秒
Consumer Group 可以使用正则表达式的方式订阅主题,比如 consumer.subscribe(Pattern.compile("t.*c")) 就表明该 Group 订阅所有以字母 t 开头、字母 c 结尾的主题。
Rebalance 的弊端是什么呢?总结起来有以下 3 点:
- Rebalance 影响 Consumer 端 TPS。这个之前也反复提到了,这里就不再具体讲了。总之就是,在 Rebalance期间,Consumer 会停下手头的事情,什么也干不了。
- Rebalance 很慢。如果你的 Group 下成员很多,就一定会有这样的痛点。如Group 下有几百个 Consumer 实例,Rebalance 一次要几个小时。在那种场景下,Consumer Group 的 Rebalance 已经完全失控了。
- Rebalance 效率不高。当前 Kafka 的设计机制决定了每次 Rebalance 时,Group 下的所有成员都要参与进来,而且通常不会考虑局部性原理,但局部性原理对提升系统性能是特别重要的。
哪些 Rebalance 是“不必要的”:
- 第一类非必要 Rebalance 是因为未能及时发送心跳,导致 Consumer 被“踢出”Group 而引发的。
- 设置 session.timeout.ms = 6s。
- 设置 heartbeat.interval.ms = 2s。
- 要保证 Consumer 实例在被判定为“dead”之前,能够发送至少 3 轮的心跳请求,即 session.timeout.ms >= 3 * heartbeat.interval.ms。
- 第二类非必要 Rebalance 是 Consumer 消费时间过长导致的
例:Consumer 消费数据时需要将消息处理之后写入到 MongoDB。显然,这是一个很重的消费逻辑。MongoDB 的一丁点不稳定都会导致 Consumer 程序消费时长的增加。此时,max.poll.interval.ms 参数值的设置显得尤为关键。如果要避免非预期的 Rebalance,你最好将该参数值设置得大一点,比你的下游最大处理时间稍长一点。就拿 MongoDB 这个例子来说,如果写 MongoDB 的最长时间是 7 分钟,那么你可以将该参数设置为 8 分钟左右。
压缩算法
压缩是一种时间换空间的动作。具体来说就是用CPU时间去换取磁盘空间或网络I/O传输量,希望以较小的CPU开销带来更少的磁盘占用或者更少的网络I/O传输。
Kafka 自 0.7.x 版本便开始支持压缩特性,producer 端能够将一批消息压缩成一条消息发送,而 broker 端将这条压缩消息写入本地日志文件。
当 consumer 获取到这条压缩消息时,它会自动地对消息进行解压缩,还原成初始的消息集合返还给用户。
如果使用一句话来总结 Kafka 压缩特性的话,那么就是一producer 压缩,broker 压缩,consumer 解压。
所谓的 broker 端保持是指 broker 端在通常情况下不会进行解压缩操作,它只是原样保存消息而已。
这里的“通常情况下”表示要满足一定的条件。
如果有些前置条件不满足(比如需要进行消息格式的转换等),那么 broker 端就需要对消息进行解压缩然后再重新压缩,看下例。
在kafka中压缩可能发生在两个地方:生产者端和broker端。
生产者程序中配置compression.type参数即表示开启指定类型的压缩算法。如
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("acks", "all");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 开启GZIP压缩
props.put("compression.type", "gzip");
Producer<String, String> producer = new KafkaProducer<>(props);
上面是在生产者中压缩,生产者启动压缩是很正常的操作,那为什么还要在broker中使用压缩算法呢?
其实大部分情况下 Broker 从 Producer 端接收到消息后仅仅是原封不动地保存而不会对其进行任何修改。但是有两种特殊情况:
- Broker 端指定了和 Producer 端不同的压缩算法。
这是是生产者和 Broker 的关联。一旦在 Broker 端设置了不同的 compression.type 值,就一定要小心了,因为可能会发生预料之外的压缩 / 解压缩操作,通常表现为 Broker 端 CPU 使用率飙升。 - Broker 端发生了消息格式转换。
所谓的消息格式转换主要是为了兼容老版本的消费者程序,一般是 V1 和 V2 消息版本转换带来的。会使其丧失零拷贝的功效。为了兼容老版本的格式,Broker 端会对新版本消息执行向老版本格式的转换。这个过程中会涉及消息的解压缩和重新压缩。一般情况下这种消息格式转换对性能是有很大影响的,除了这里的压缩之外,它还让 Kafka 丧失了引以为豪的 Zero Copy 特性。
第一种使用不同的压缩算法很好理解。
在 Kafka 2.1.0 版本之前,Kafka 支持 3 种压缩算法:GZIP、Snappy 和 LZ4。
从 2.1.0 开始,Kafka 正式支持 Zstandard 算法(简写为 zstd)。它是 Facebook 开源的一个压缩算法,能够提供超高的压缩比(compression ratio)
压缩算法有:GZIP、Snappy 、 LZ4和Zstandard 算法(简写为 zstd)
看一个压缩算法的优劣,有两个重要的指标:
1:一个指标是压缩比。
2:另一个指标就是压缩 / 解压缩吞吐量,比如每秒能压缩或解压缩多少 MB 的数据
不同算法压缩性能:
- 吞吐量方面:LZ4 > Snappy > zstd 和 GZIP
- 压缩比方面:zstd > LZ4 > GZIP > Snappy
- 网络带宽:使用 Snappy 算法占用的网络带宽最多,zstd 最少
- CPU使用率:压缩时 Snappy 算法使用的 CPU 较多一些,而在解压缩时 GZIP 算法则可能使用更多的 CPU。
压缩算法一般选择 zstd
补充知识点kafka的消息格式
补充知识点kafka的消息格式
序列化反序列化
在发送消息到broken之前,会先进行序列化变成字节数组。Kafka的broker中所有的消息都是字节数组,消费者获取到消息之后,需要先对消息进⾏反序列化处理,然后才能交给⽤户程序消费处理。
消费者的反序列化器包括key的和value的反序列化器;key.deserializer、value.deserializer
需要实现 org.apache.kafka.common.serialization.Deserializer 接⼝。
系统提供了该接⼝的⼦接⼝以及实现类:
- org.apache.kafka.common.serialization.ByteArrayDeserializer
- org.apache.kafka.common.serialization.ByteBufferDeserializer
- org.apache.kafka.common.serialization.BytesDeserializer
- org.apache.kafka.common.serialization.DoubleDeserializer
- org.apache.kafka.common.serialization.FloatDeserializer
- org.apache.kafka.common.serialization.IntegerDeserializer
- org.apache.kafka.common.serialization.LongDeserializer
- org.apache.kafka.common.serialization.ShortDeserializer
- org.apache.kafka.common.serialization.StringDeserializer
⾃定义反序列化
⾃定义反序列化类,需要实现 org.apache.kafka.common.serialization.Deserializer 接⼝。
package luu.demo.kafka.consumer;
import luu.demo.kafka.model.User;
import org.apache.kafka.common.serialization.Deserializer;
import java.nio.ByteBuffer;
import java.util.Map;
public class UserDeserializer implements Deserializer<User> {
@Override
public void configure(Map<String, ?> configs, boolean isKey) {
}
@Override
public User deserialize(String topic, byte[] data) {
ByteBuffer allocate = ByteBuffer.allocate(data.length);
allocate.put(data);
allocate.flip();
int userId = allocate.getInt();
int length = allocate.getInt();
System.out.println(length);
String username = new String(data, 8, length);
return new User(userId, username);
}
@Override
public void close() {
}
}
MyConsumer
package luu.demo.kafka.consumer;
import luu.demo.kafka.model.User;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.util.Collections;
import java.util.HashMap;
import java.util.Map;
import java.util.function.Consumer;
public class MyConsumer {
public static void main(String[] args) {
Map<String, Object> configs = new HashMap<>();
configs.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "node1:9092");
configs.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class);
configs.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
UserDeserializer.class);
configs.put(ConsumerConfig.GROUP_ID_CONFIG, "consumer1");
configs.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
configs.put(ConsumerConfig.CLIENT_ID_CONFIG, "con1");
KafkaConsumer<String, User> consumer = new KafkaConsumer<String, User>(configs);
consumer.subscribe(Collections.singleton("tp_user_01"));
ConsumerRecords<String, User> records = consumer.poll(Long.MAX_VALUE);
records.forEach(new Consumer<ConsumerRecord<String, User>>() {
@Override
public void accept(ConsumerRecord<String, User> record) {
System.out.println(record.value());
}
});
// 关闭消费者
consumer.close();
}
}
Broker 重要参数
| 参数名称 | 描述 |
|---|---|
| replica.lag.time.max.ms | ISR 中,如果 Follower 长时间未向 Leader 发送通信请求或同步数据,则该 Follower 将被踢出 ISR。该时间阈值,默认 30s。 |
| auto.leader.rebalance.enable | 默认是 true。 自动 Leader Partition 平衡。 |
| leader.imbalance.per.broker.percentage | 默认是 10%。每个 broker 允许的不平衡的 leader的比率。如果每个 broker 超过了这个值,控制器会触发 leader 的平衡。 |
| leader.imbalance.check.interval.seconds | 默认值 300 秒。检查 leader 负载是否平衡的间隔时间。 |
| log.segment.bytes | Kafka 中 log 日志是分成一块块存储的,此配置是指 log 日志划分 成块的大小,默认值 1G。 |
| log.index.interval.bytes | 默认 4kb,kafka 里面每当写入了 4kb 大小的日志(.log),然后就往 index 文件里面记录一个索引。 |
疑问
消费者拉取时间间隔
Kafka 延迟队列
生产操作学习博客(知乎)
CommitFailedException异常
面试知识点
32 道常见的 Kafka 面试题
kafka的副本同步机制