Elasticsearch:使用 Elasticsearch ingest pipeline 丰富数据
在我之前的文章:
-
Elasticsearch:如何使用 Elasticsearch ingest 节点来丰富日志和指标
-
Elasticsearch:enrich processor (7.5发行版新功能)
我有详细描述如何使用 ingest pipeline 来丰富数据。在今天的文章中里,我们来更加详细地使用一个具体的例子来进行展示。更多官方文档描述,我们可以详细参阅文章 Enrich your data | Elasticsearch Guide [8.8] | Elastic。
什么是丰富数据
简单地说,我们可以使用其他的数据集里的数据添加到现有的数据集中。这样在我们的最终的数据集中,它含有另外一个数据集里的数据供我们分析数据。我们知道如果是独立于 Elasticsearch 的数据库,我们只有通过 Logstash 来完成这种操作。针对两个不同的 Elasticsearch 索引来说,我们可以使用 enrich processor 来完成两个不同的数据集之间的 “join” 操作。比如:

如上所示,我们有两个数据集:registration 及 customer。他们的数据分别如上所示。 它们是以 JSON 格式来进行表达的。我们可以通过 email 进行关联,那么最终我们可以得到如图右边的那个被丰富的数据。这个数据它不仅含有 registraion 里的数据,而且它还含有 customer 里的数据。从某种意义上讲,我们把两个不同的数据集通过 email 进行关联,并最终形成了一个被丰富的数据集。这个对于我们最终分析数据非常有效。
Elasticsearch enrich processor 的工作流程如下:

数据描述
我们假想有一个活动的 signup 应用。在活动签名的时候这个应用收集了如下的信息:

如上所示,它只含有 email,location_id,paid_amount 及 product 四个字段的信息。这个信息被保存于一个 CSV 文件中。之后,市场部门提供了更多的信息表格给我我们。这些信息包含 location,member_type 及 user 等信息。
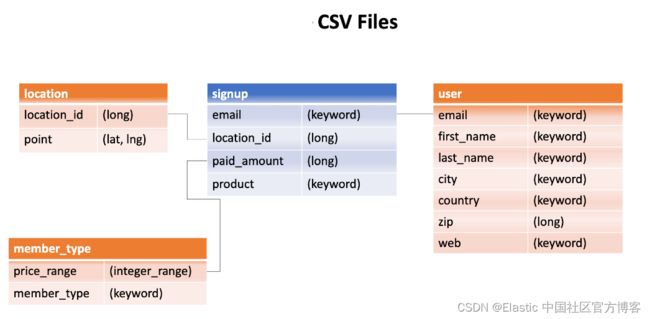
为了方便大家理解这个问题,我们可以在地址 GitHub - liu-xiao-guo/elasticsearch-ingest 找到相应的数据表述:
location.csv

user.csv

member_type.csv
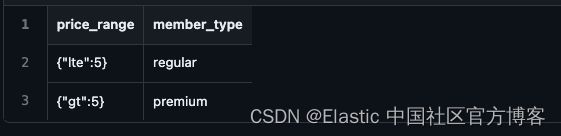
signup.csv

我们希望通过 enrich processor 的处理,我们最终能得到像如下结果的数据集:
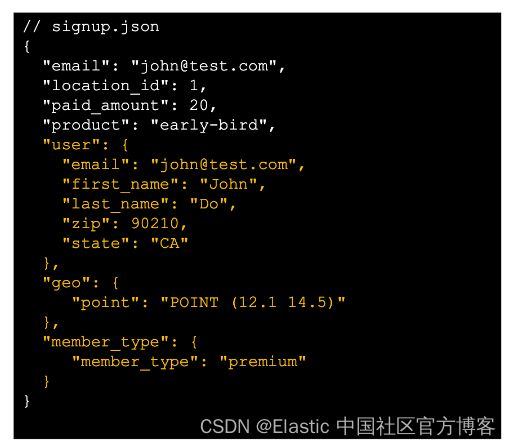
也就是说,我们通过 enrich processor 的一番操作,我们可以把匹配的 user,location 及 member_type 信息添加进来,也即丰富原来的数据。
导入数据
我们可以使用 Kibana 来写入数据:
导入 user.csv





导入 location.csv


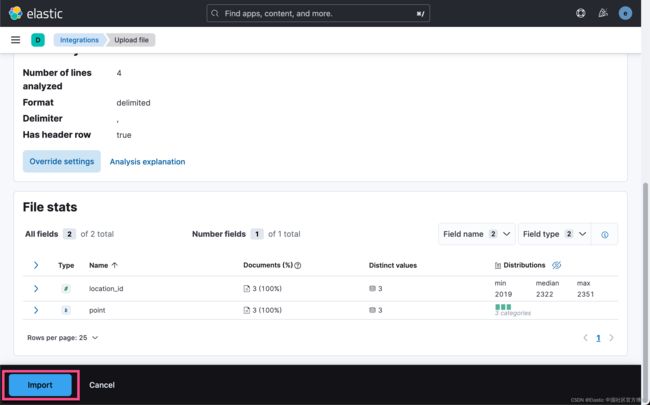
 在上面我们需要修改 point 为 geo_point 数据类型。
在上面我们需要修改 point 为 geo_point 数据类型。

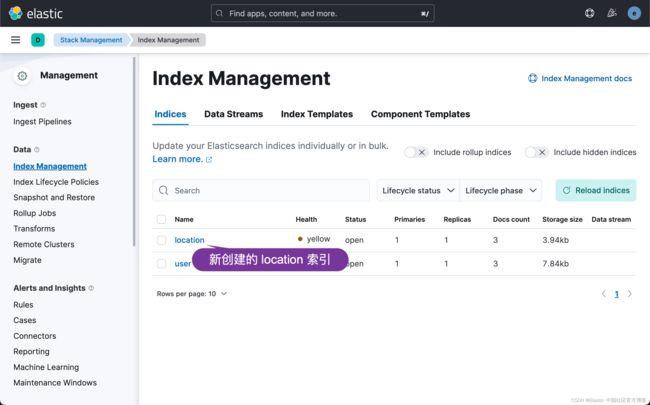

导入 member_type.csv
按照同样的方法,我们来导入 member_type.csv:


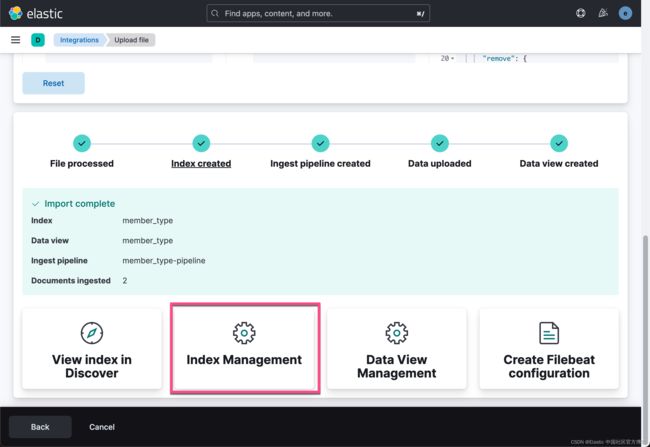
 在上面,我们添加了如下的 json processor:
在上面,我们添加了如下的 json processor:
{
"json" : {
"field" : "price_range"
}
}


创建 enrich policy
我们可以参考链接:https://github.com/liu-xiao-guo/elasticsearch-ingest/blob/master/part-2/policy/user.txt
// Create users policy
PUT /_enrich/policy/user_policy
{
"match": {
"indices": "user",
"match_field": "email",
"enrich_fields": ["first_name", "last_name", "city", "zip", "state"]
}
}
PUT /_enrich/policy/user_policy/_execute我们在 Kibana 中运行上面的命令。在上面的 user_policy 中,我们使用 user 索引中的 email 字段,如果有匹配的话,那么 user 索引中相应的文档的 first_name,last_name,city,zip 及 state 将被丰富到文档中。
我们参考链接:https://github.com/liu-xiao-guo/elasticsearch-ingest/blob/master/part-2/policy/location.txt
PUT /_enrich/policy/location_policy
{
"match": {
"indices": "location",
"match_field": "location_id",
"enrich_fields": ["point"]
}
}
PUT /_enrich/policy/location_policy/_execute在 Kibana 中运行上面的命令。
我们参考链接:https://github.com/liu-xiao-guo/elasticsearch-ingest/blob/master/part-2/policy/member_type.txt
// Create member_type policy
PUT /_enrich/policy/member_type_policy
{
"range": {
"indices": "member_type",
"match_field": "price_range",
"enrich_fields": ["member_type"]
}
}
PUT /_enrich/policy/member_type_policy/_execute我们在 Kibana 中运行上面的命令。
我们可以在 index management 中查看到新生成的 enrich index:
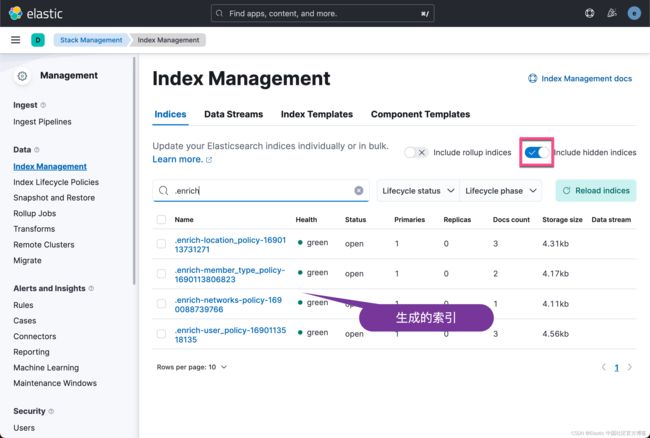
导入 signup.csv

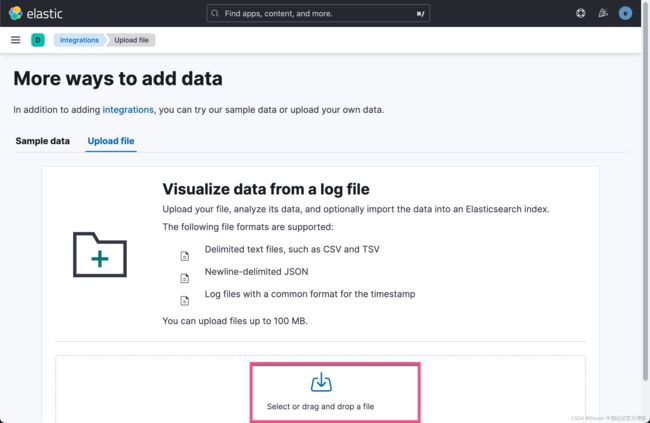
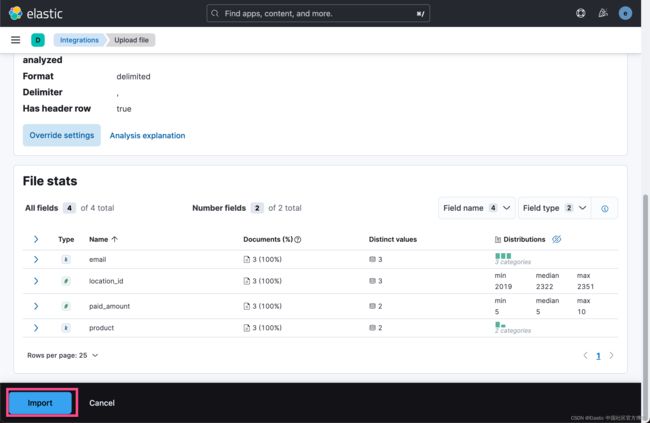
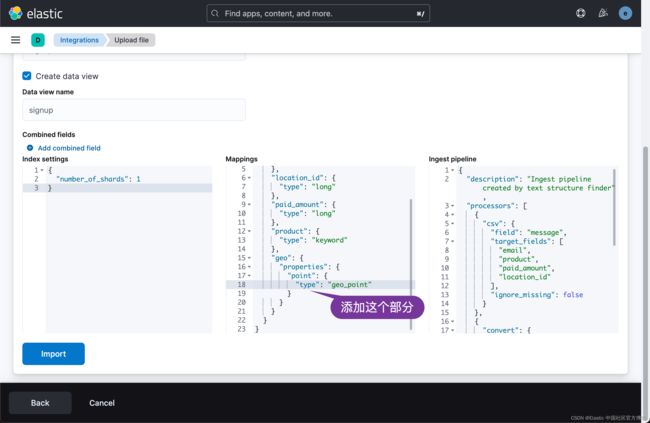
如果你看看我们之前想要的结果的数据 mapping:
我们需要添加 geo 字段:
"geo": {
"properties": {
"point": {
"type": "geo_point"
}
}
}我们需要更进一步修改 ingest pipeline。我们参考链接:https://github.com/liu-xiao-guo/elasticsearch-ingest/blob/master/part-2/pipeline/signup.json

我们需要添加如下的三个 enrich processor:
{
"enrich" : {
"description": "Add 'user' data based on 'email'",
"policy_name": "user_policy",
"field" : "email",
"target_field": "user",
"max_matches": "1"
}
},
{
"enrich" : {
"description": "Add 'member_type' data based on 'paid_amount'",
"policy_name": "member_type_policy",
"field" : "paid_amount",
"target_field": "member_type",
"max_matches": "1"
}
},
{
"enrich" : {
"description": "Add 'geo' data based on 'location_id'",
"policy_name": "location_policy",
"field" : "location_id",
"target_field": "geo",
"max_matches": "1"
}
},点击上面的 import 按钮:



我们接下来针对 signup 索引来做一个搜索:
GET signup/_search?filter_path=**.hits上面的命令返回的结果为:
{
"hits": {
"hits": [
{
"_index": "signup",
"_id": "Q9mvgokBWubr9hCu1VXI",
"_score": 1,
"_source": {
"member_type": {
"member_type": "regular",
"price_range": {
"lte": 5
}
},
"geo": {
"location_id": 2351,
"point": "POINT(-71.61 42.28)"
},
"product": "earlybird",
"paid_amount": 5,
"user": {
"zip": 9303,
"city": "Arleta",
"last_name": "Fly",
"state": "CA",
"first_name": "Marty",
"email": "[email protected]"
},
"email": "[email protected]",
"location_id": 2351
}
},
{
"_index": "signup",
"_id": "RNmvgokBWubr9hCu1VXI",
"_score": 1,
"_source": {
"member_type": {
"member_type": "regular",
"price_range": {
"lte": 5
}
},
"geo": {
"location_id": 2322,
"point": "POINT(-71.63 42.56)"
},
"product": "earlybird",
"paid_amount": 5,
"user": {
"zip": 58008,
"city": "Springfield",
"last_name": "Simpson",
"state": "OR",
"first_name": "Homer",
"email": "[email protected]"
},
"email": "[email protected]",
"location_id": 2322
}
},
{
"_index": "signup",
"_id": "RdmvgokBWubr9hCu1VXI",
"_score": 1,
"_source": {
"member_type": {
"member_type": "premium",
"price_range": {
"gt": 5
}
},
"geo": {
"location_id": 2019,
"point": "POINT(-72.68 42.2)"
},
"product": "regular",
"paid_amount": 10,
"user": {
"zip": 99686,
"city": "Valdez",
"last_name": "Riker",
"state": "AK",
"first_name": "Will",
"email": "[email protected]"
},
"email": "[email protected]",
"location_id": 2019
}
}
]
}
}从上面的输出中,我们可以看出来我们已经成功地丰富了 signup 索引。