第十二章:Tell Me Where to Look:Guided Attention Inference Network ——告诉我看哪里:引导注意力推断网络
0.摘要
只使用粗略标签的弱监督学习可以通过反向传播梯度来获得深度神经网络的视觉解释,如注意力地图。这些注意力地图可以作为对象定位和语义分割等任务的先验知识。在一个常见的框架中,我们解决了以前方法中建模这些注意力地图的三个缺点:(1)首次将注意力地图作为端到端训练的明确且自然的组成部分,(2)直接在这些地图上提供自我指导,通过探索网络自身的监督来改善它们,(3)在使用弱监督和额外监督之间无缝地建立桥梁(如果可用)。尽管方法简单,但在语义分割任务上的实验证明了我们方法的有效性。我们在PASCAL VOC 2012测试集和验证集上明显超越了最先进的方法。此外,所提出的框架不仅可以解释学习者的关注焦点,还可以通过直接指导向特定任务回馈。在温和的假设下,我们的方法也可以理解为现有弱监督学习器的插件,以提高其泛化性能。
1.引言
弱监督学习[3,26,33,36]近年来在计算机视觉领域引起了广泛关注,作为解决标记数据稀缺性的热门解决方案。例如,只使用图像级别的标签,可以通过在卷积神经网络(CNN)上进行反向传播来获得给定输入的注意力地图。这些地图与网络对特定模式和任务的响应相关。注意力地图上每个像素的值揭示了该像素在输入图像上对网络最终输出的贡献程度。已经证明,可以从这些注意力地图中提取定位和分割信息,而无需额外的标记工作[39]。
然而,仅通过分类损失进行监督时,注意力地图通常只覆盖目标对象的小而最具区分性的区域[11,28,39]。尽管这些注意力地图仍然可以作为分割等任务的可靠先验知识,但是如果注意力地图能够尽可能完整地覆盖目标前景对象,将进一步提高性能。为此,最近的几项工作要么依赖于通过迭代擦除步骤组合多个网络的多个注意力地图[31],要么整合来自多个网络的注意力地图[11]。我们设想一个端到端的框架,可以在训练阶段直接将任务特定的监督应用于注意力地图。而不是 passively 利用训练好的网络注意力。
另一方面,作为解释网络决策的有效方式,注意力地图可以帮助找到训练网络的限制。例如,在仅具有图像级别对象类别标签的对象分类任务中,当前景对象偶然总是与相同的背景对象相关联时,我们可能会遇到训练数据中的病理性偏差(也在[24]中指出)。图1显示了“船”的示例类别,其中可能存在对水作为干扰因素的偏置,具有高相关性。在这种情况下,训练没有动机仅关注前景类别,当测试数据没有相同的相关性时(“水中的船”),泛化性能可能会受到影响。虽然已经有尝试通过重新平衡训练数据来消除这种偏差,但我们提出将注意力地图明确建模为训练的一部分。其中一个好处是我们能够显式地控制注意力,并可以在提供最小的注意力监督时投入手动努力,而不是重新平衡数据集。虽然如何手动平衡数据集以避免偏差可能不总是清楚,但通常可以将注意力引导到感兴趣的区域。我们还观察到,即使没有额外的监督,我们的显式自我引导注意力模型已经改善了泛化性能。
我们的贡献是:
(a) 在训练过程中直接对注意力地图进行监督的方法,同时学习弱标记的任务;
(b) 在训练过程中使用自我引导方案,强制网络将注意力整体集中在对象上,而不仅仅是最具区分性的部分;
(c) 将直接监督和自我引导相结合,无缝地从仅使用弱标签扩展到在一个共同的框架中使用完全监督。
我们使用语义分割作为感兴趣的任务进行实验,结果显示我们的方法在PASCAL VOC 2012分割测试集和验证集上分别达到了55.3%和56.8%的mIoU。当在训练中使用有限的像素级监督时,它也自信地超过了可比较的最先进方法,分别达到了60.5%和62.1%的mIoU。

图1. 提出的引导注意力推断网络(GAIN)使网络的注意力可以在线训练,并且可以以端到端的方式直接在注意力地图上插入不同类型的监督。我们从网络本身探索了自我引导监督,并在额外的监督可用时提出了GAINext。这些引导可以优化注意力地图以适应感兴趣的任务。
2.相关工作
由于深度神经网络在许多领域取得了巨大的成功[7,34,35,37],因此提出了各种方法来解释这个黑盒子[3,26,33,38]。视觉注意力是一种试图解释图像的哪个区域对网络决策负责的方法。在[26,29,33]中,应用基于误差反向传播的方法来可视化对预测类别有帮助的区域。[3]提出了一种反馈方法来捕捉自顶向下的神经注意力,可以用来显示与任务相关的区域。CAM [39]显示了平均池化层比全连接层更能生成代表任务相关区域的注意力地图。受到人类自上而下视觉注意力模型的启发,[36]提出了一种新的反向传播方法,Excitation Backprop,用于在网络层次结构中从上到下传递信号。最近,Grad-CAM [24]将CAM [39]扩展到许多不同的可用架构,用于图像字幕和VQA等任务,有助于解释模型的决策。与所有试图解释网络的这些方法不同,我们首次建立了一个端到端模型,直接在这些解释上提供监督,具体而言是网络的注意力。我们验证了监督可以引导网络集中注意我们预期的区域,这将有益于相应的视觉任务。
许多方法严重依赖于网络注意力提供的位置信息。从仅有的图像级标签学习,训练好的分类网络的注意力地图可以用于弱监督对象定位[17,39]、场景分割[12]等任务。然而,仅使用分类损失进行训练的注意力地图只覆盖了感兴趣对象的小而最有区别性的区域,与需要定位密集、内部和完整区域的任务要求相去甚远。为了弥补这一差距,[28]提出了在训练图像中随机隐藏补丁的方法,当最有区别性的部分被隐藏时,迫使网络寻找其他相关部分。这种方法可以被视为一种增加训练数据的方式,并且对前景对象的大小有很强的假设(即对象大小与补丁大小的关系)。[31]使用训练网络的注意力地图擦除原始输入图像的最有区别性的区域。他们重复这个擦除和发现动作的步骤对擦除的图像进行几步操作,并结合每个步骤的注意力地图得到一个更完整的注意力地图。类似地,[11]使用两阶段学习策略,并结合两个网络的注意力地图来获取感兴趣对象的更完整区域。在第一步中,训练一个传统的全卷积网络(FCN)[16]来寻找图像的最有区别性的部分。然后,这些最显著的部分被用来抑制第二个网络的特征图,以迫使其集中注意力于下一个最重要的部分。然而,这些方法要么依赖于同一个训练网络的注意力地图在不同的擦除步骤上的组合,要么依赖于不同网络的注意力。单个网络的注意力仍然只局限于最有区别性的区域。我们提出的GAIN模型与之前的方法有根本的不同。由于我们的模型可以以端到端的方式直接在网络的注意力上提供监督,这是其他所有方法[11,24,28,31,36,39]无法做到的,我们设计了不同类型的损失函数来指导网络集中注意感兴趣对象的整个区域。因此,我们不需要多次擦除或者合并注意力地图。我们单个训练好的网络的注意力已经更加完整和改进了。
识别数据集中的偏差[30]是网络注意力的另一个重要应用。[24]分析了训练模型的注意力地图的位置,以找出数据集的偏差,从而帮助他们构建一个更好的无偏数据集。然而,在实际应用中,很难去除数据集的所有偏差,并且构建一个新的数据集也非常耗时。如何保证学习网络的泛化能力仍然是一个具有挑战性的问题。与现有方法不同,我们的模型可以通过直接在网络的注意力上提供监督,并引导网络集中注意力于任务关键区域,从根本上解决这个问题。因此,我们训练好的模型对数据集的偏差具有鲁棒性。
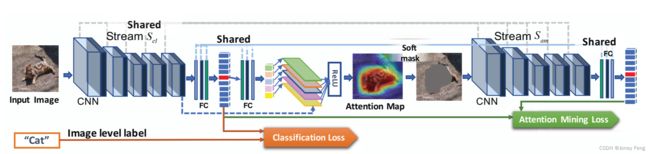
图2. GAIN具有两个共享参数的网络流:Scl和Sam。Scl旨在找出有助于识别对象的区域,而Sam则试图确保所有这些有助于识别的区域都已被发现。注意力地图通过这两个损失函数的联合在线生成和可训练。
3.提出的方法——GAIN
由于注意力地图反映了输入图像上支持网络预测的区域,我们提出了引导注意力推理网络(GAIN),旨在在训练网络进行感兴趣任务时监督注意力地图。通过这种方式,网络的预测是基于我们希望网络关注的区域。我们通过以端到端的方式使网络的注意力可训练来实现这一目标,这是其他任何现有工作[11,24,28,31,36,39]都没有考虑的。在本节中,我们描述了GAIN的设计及其针对感兴趣任务的扩展。
3.1.对网络注意力进行自我指导
如第1节所提到的,经过训练的分类网络的注意力地图可以作为弱监督语义分割方法的先验知识。然而,仅仅通过分类损失进行监督,注意力地图通常只覆盖感兴趣对象的小而具有辨别力的区域。这些注意力地图可以作为分割的可靠先验知识,但一个更完整的注意力地图肯定可以帮助提高整体性能。
为了解决这个问题,我们的GAIN以一种正则化的引导方式直接在注意力地图上建立约束。如图2所示,GAIN有两个网络流,分类流Scl和注意力挖掘流Sam,它们共享参数。Scl流的约束旨在找出有助于识别类别的区域。Sam流确保所有对分类决策有贡献的区域都包含在网络的注意力中。通过这种方式,注意力地图变得更加完整、准确,并且为分割任务量身定制。关键在于我们通过两个损失函数的联合,使得注意力地图可以在线生成和可训练。
基于Grad-CAM [24]的基本框架,我们简化了注意力地图的生成过程。在每次推理中,可以获得与输入样本相对应的注意力地图,因此在训练阶段可以对其进行训练。在Scl流中,对于给定的图像I,设fl,k为第l层中单位k的激活。对于来自真实标签的每个类别c,我们计算与fl,k的激活图相对应的分数sc关于类别c的梯度。这些反向传播的梯度将通过全局平均池化层[14],得到在方程式1中定义的神经元重要性权重wl,k c。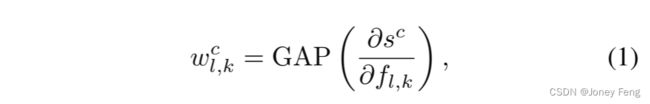
这里的GAP(·)表示全局平均池化操作。在这里,我们在通过反向传播获得wl,k c之后不更新网络的参数。由于wl,k c表示支持类别c预测的激活图fl,k的重要性,我们将权重矩阵wc作为卷积核,在激活图矩阵fl上进行2D卷积,然后通过ReLU操作得到注意力地图Ac,如方程式2所示。注意力地图现在可以在线训练,并且对Ac的约束将影响网络的学习:
其中,l是来自最后一个卷积层的表示,其特征在详细的空间信息和高级语义之间具有良好的平衡[26]。然后,我们使用可训练的注意力地图Ac生成一个软掩码,将其应用于原始输入图像,使用方程式3得到I∗c。I∗c表示网络当前对于类别c的关注之外的区域。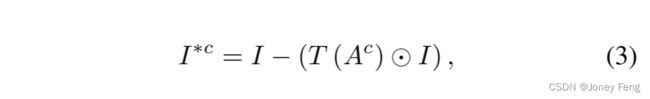

然后,I∗c被用作Sam流的输入,以获得类别预测得分。由于我们的目标是引导网络关注兴趣类别的所有部分,我们要求I∗c尽量少地包含属于目标类别的特征,即在注意力地图的高响应区域之外的区域理想情况下不包含任何可以触发网络识别类别c对象的像素。从损失函数的角度来看,它试图最小化类别c的I∗c的预测得分。为了实现这一目标,我们设计了被称为注意力挖掘损失的损失函数,如方程式5所示。
其中,Lcl用于多标签和多类别分类,我们在这里使用了多标签软边界损失。对于特定任务,可以使用其他损失函数。α是权重参数,我们在所有实验中都使用α=1。在Lself的指导下,网络学习尽可能扩展对目标类别识别有贡献的输入图像的关注区域,使得注意力地图适应任务,例如语义分割。联合优化还防止擦除所有像素。我们在第4节中验证了带有自我指导的GAIN的有效性。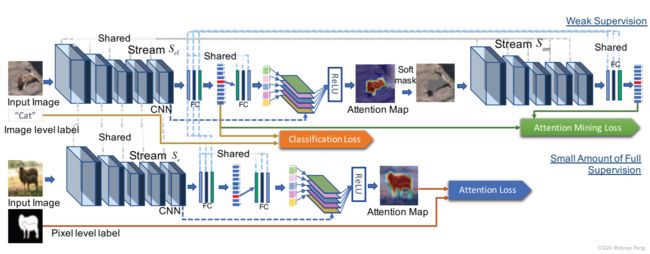
图3. GAINext的框架。像素级注释无缝地集成到GAIN框架中,为注意力地图提供直接监督,以优化语义分割任务。
3.2.GAINext: 整合额外监督
除了让网络自己探索注意力地图的引导外,我们还可以通过使用少量额外的监督来告诉网络应该关注图像中的哪个部分,以控制注意力地图的学习过程。基于这种在注意力地图上施加额外监督的思想,我们引入了GAIN的扩展版本:GAINext,它可以无缝地将额外监督集成到我们的弱监督学习框架中。我们在第4节中展示了使用GAINext改进弱监督语义分割任务的示例。此外,当测试数据和训练数据来自非常不同的分布时,我们还可以应用GAINext来指导网络学习对数据集偏差鲁棒的特征,提高其泛化能力。
继续在第3.1节之后,我们仍然以弱监督语义分割任务作为示例应用来解释GAINext。在训练阶段生成可训练的注意力地图的方法与自我指导的GAIN相同。除了Lcl和Lam,我们根据给定的外部监督设计了另一个损失函数Le。我们将Le定义为:
其中,Hc表示额外的监督,例如我们示例中的像素级分割掩码。由于生成像素级分割图非常耗时,我们更感兴趣的是使用仅有非常少量的具有外部监督的数据可以带来的好处,这与图3中展示的GAINext框架完美契合。在这个框架中,我们添加了一个外部流Se,这三个流共享所有参数。流Se的输入图像包括图像级标签和像素级分割掩码。通过流Se仅使用非常少量的像素级标签就可以在GAINext中获得性能提升(在我们的实验中,训练中使用的像素级标签仅占总体标签的1∼10%)。流Scl的输入包括仅带有图像级标签的训练集中的所有图像。GAINext的最终损失函数Lext定义如下: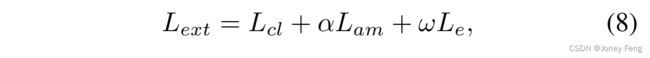
其中,Lcl和Lam的定义在第3.1节中,ω是权重参数,取决于我们希望在额外监督上放置多少重点(在我们的实验中,我们使用ω=10)。GAINext也可以很容易地修改以适应其他任务。一旦我们得到与网络最终输出对应的激活图fl,k,我们可以使用Le来引导网络关注与所关注任务相关的关键区域。在第5节中,我们展示了这种修改的一个示例,以指导网络学习对数据集偏差鲁棒的特征,并提高其泛化能力。在这种情况下,额外的监督以边界框的形式存在。
4.语义分割实验
为了验证GAIN的有效性,我们在第3.1节和第3.2节之后使用弱监督语义分割任务作为示例应用。该任务的目标是将每个像素分类为不同的类别。在弱监督设置中,最近的大多数方法[11,12,31]主要依赖于仅使用图像级标签训练的模型生成的定位线索,并考虑其他约束(如物体边界)来训练分割网络。因此,定位线索的质量是这些方法性能的关键。
与最先进的方法[16,24,39]生成的仅定位最具区分性区域的注意力地图相比,GAIN指导网络关注表示感兴趣类别的整个区域,这可以提高弱监督分割的性能。为了验证这一点,我们将我们的注意力地图应用于SEC [12],这是一种最先进的弱监督语义分割方法之一。按照SEC [12]的方法,我们通过对GAIN生成的注意力地图应用阈值操作来获取我们的定位线索:对于每个类别的注意力地图,选择所有得分大于最大得分的20%的像素。我们多次应用[15]来获取背景线索,然后使用相同的推理过程和CRF [13]的参数训练SEC模型生成分割结果。

表1.在PASCAL VOC 2012语义分割验证集和分割测试集上比较弱监督语义分割方法。weak表示图像级标签,pixel表示像素级标签。隐式使用像素级监督是我们遵循的一个协议,如[31]中所定义的,即像素级标签仅在训练先验中使用,而在分割框架的训练中仅使用弱标签,例如我们的情况下使用SEC [12]方法。
4.1.数据集和实验设置
数据集和评估指标。我们在PASCAL VOC 2012图像分割基准[6]上评估我们的结果,该数据集包括20个前景类别。整个数据集被分为三组:训练集、验证集和测试集(分别表示为train、val和test),分别包含1464、1449和1456张图像。按照常见的设置[4,12],我们还使用[8]提供的增广训练集。结果得到的训练集有10582张弱注释图像,我们将其用于训练我们的模型。我们在验证集和测试集上与其他方法进行比较,并使用mIoU作为评估指标。
实现细节。我们使用在ImageNet [5]上预训练的VGG [27]作为GAIN生成注意力地图的基础网络。我们使用Pytorch [1]来实现我们的模型。我们将批大小设置为1,学习率设置为10^-5。我们使用随机梯度下降(SGD)来训练网络,并在35个epochs后终止训练。在我们使用不同的数据集和项目进行实验时,并没有观察到最大最小优化问题的任何收敛问题。我们的总损失在1个epoch和15个epoch后分别降低了约90%和98%。对于弱监督分割框架,按照SEC [12]的设置,我们使用DeepLab-CRFLargeFOV [4],它是VGG网络[27]的略微修改版本。使用Caffe [10]实现,DeepLab-CRFLargeFOV [4]将输入大小定义为321×321,并生成大小为41×41的分割掩模。在这个阶段,我们的训练过程与[12]相同。我们使用批大小为15的SGD进行8000次迭代训练。初始学习率为10^-3,每2000次迭代学习率减小10倍。
4.2.与当下主流方法的比较
我们将我们的方法与其他最先进的仅使用图像级标签的弱监督语义分割方法进行比较。按照[31]的方法,我们将它们分为两类。对于纯粹使用图像级标签的方法,我们将我们基于GAIN的SEC方法(在表中表示为GAIN)与SEC [12]、AE-PSL [31]、TPL [11]、STC [32]等进行比较。对于另一类方法,隐式使用像素级监督意味着尽管这些方法只使用图像级标签训练分割网络,但它们使用一些额外的技术,这些技术使用像素级监督进行训练。我们基于GAINext的SEC方法(在表中表示为GAINext)属于这种设置,因为它使用了非常少量的像素级标签来进一步改进网络的注意力地图,并且在训练SEC分割网络时不依赖于任何像素级标签。其他在这种设置中的方法,如AF-MCG [39]、TransferNet [9]和MIL-seg [20],也包含在比较中。表1显示了在PASCAL VOC 2012分割验证集和分割测试集上的结果。
在纯粹使用图像级标签的方法中,我们基于GAIN的SEC在这两个数据集上的mIoU分别为55.3%和56.8%,表现最好,比SEC [12]基准提高了4.6%和5.1%。此外,GAIN比AE-PSL [31]提高了0.3%和1.1%,比TPL [11]提高了2.2%和3.0%。这两种方法也旨在在注意力地图中覆盖感兴趣类别的更多区域。与它们相比,我们的GAIN使得注意力地图可以进行训练,而无需像[11,31]中所提出的迭代擦除或将来自不同网络的注意力地图组合起来。
通过隐式使用像素级监督,我们基于GAINext的SEC在使用200个随机选择的带有像素级标签的图像(整个数据集的2%)作为额外监督时,mIoU分别达到了58.3%和59.6%。它的表现已经比依赖于在PASCAL VOC上以全监督方式训练的MCG生成器[2]的AF-MCG [39]提高了4%和4.1%。当像素级监督增加到1464张图像时,我们的GAINext的性能跃升到了60.5%和62.1%,这是这个具有挑战性任务的竞争性基准上的新的最先进结果。图4显示了一些语义分割的定性结果,表明基于GAIN的方法有助于发现更完整和准确的感兴趣类别区域。
我们还在图5中展示了基于GAIN的方法生成的注意力地图的定性结果,与Grad-CAM [24]相比,GAIN覆盖了更多属于感兴趣类别的区域。仅使用了2%的像素级标签,GAINext覆盖了更完整和准确的感兴趣类别区域,以及更少的背景区域(例如,在图5的第二行中,船周围的海洋和车下的道路)。
关于GAINext的更多讨论,我们对不同数量的像素级标签对性能的影响很感兴趣。在第4.1节中采用相同的设置,我们添加了更多随机选择的像素级标签来进一步改进注意力地图,并将它们应用于SEC [12]中。从表2的结果中,我们发现当提供更多的像素级标签来训练生成注意力地图的网络时,GAINext的性能会提高。同样地,没有使用像素级标签来训练SEC分割框架。我们还在不使用CRF的VOC 2012 seg.val.和seg.test数据集上评估性能,如表3所示。
图4.在PASCAL VOC 2012分割验证集上的定性结果。它们是由SEC(我们的基准框架),基于GAIN的SEC和基于GAINext的SEC生成的,隐式地使用了200个随机选择(2%)的额外监督。
表2.在PASCAL VOC 2012分割验证集上使用不同数量的像素级监督隐式地使用我们基于GAINext的SEC进行注意力地图学习过程的结果。

图5.由Grad-CAM [24]、我们的GAIN和用200个随机选择(2%)的额外监督的GAINext生成的注意力地图的定性结果。
表3.在PASCAL VOC 2012分割验证集和测试集上没有使用CRF的语义分割结果。显示的数字是mIoU。
5.使用有偏数据的指导学习
在本节中,我们设计了两个实验来验证我们的方法具有使分类网络对数据集偏差具有鲁棒性并改善其泛化能力的潜力,通过为其注意力提供指导。
船舶实验。如图1所示,在PASCAL VOC数据集上训练的分类网络在预测图像中是否存在船只时,会将注意力集中在海洋和水域而不是船只上。因此,模型未能学习到正确的模式或特征来识别船只,受到训练集中的偏差的影响。为了验证这一点,我们构建了一个测试数据集,名为“偏船”数据集,包含两类图像:没有海洋或水域的船只图像;以及没有船只的海洋或水域图像。我们从互联网上收集了每种情况下的50张图像。然后,我们在这个偏船测试数据集上测试了没有注意力引导、GAIN和GAINext的模型,这些模型在第3.2节和第4.2节中进行了描述。结果报告在表4中。这些模型恰好是在第4.2节中训练的模型。一些定性结果显示在图6中。
可以看到,仅使用图像级监督的GAIN,我们在船只数据集上的整体准确率得到了提高。这可能归因于GAIN能够教导学习者捕捉目标对象的所有相关部分,在这种情况下,即图像中的船只本身和周围的水域。因此,当图像中没有船只而只有水时,网络更有可能生成一个负面预测。然而,尽管有了自我引导的帮助,由于训练数据的偏差,GAIN仍然无法完全将船只与水区分开来。
另一方面,使用少量的像素级标签训练的GAINext在这两种情况下都观察到了类似水平的改进。这些结果背后的原因可能是像素级标签能够准确告诉学习者目标对象的相关特征、组成部分或部分,因此可以将图像中的实际船只与水区分开来。这再次支持了通过直接在注意力地图上提供额外的指导,可以大大减轻训练数据中的偏差所带来的负面影响。
工业相机实验。这个实验旨在验证模型的泛化能力,针对具有高度对称形状的工业相机定义了两个方向类别。如图7所示,只有相机表面上的缝隙和小标记等特征可以有效地区分它们的方向。然后,我们构建了一个训练集和两个测试集。训练集和测试集1从Dt中采样而来,没有重叠。测试集2则是从不同的相机视角和背景下获取的。训练集中每个方向类别有350张图像,总共有700张图像;测试集1和测试集2中每个类别有100张图像。我们在训练集上训练了基于VGG的Grad-CAM和我们的GAINext方法。在训练GAINext时,我们使用手动绘制的边界框(每个类别20个,仅占整个训练数据的5%)作为外部监督。
在测试过程中,尽管Grad-CAM可以很好地对测试集1中的图像进行分类,但在受到数据集偏差的影响时,在测试集2上只能得到随机的猜测结果。相反,使用GAINext,网络能够将注意力集中在边界框标签指定的区域,因此在使用测试集2进行测试时可以观察到更好的泛化效果。这些结果再次表明,我们提出的GAINext有潜力减轻训练数据中偏差的影响,并指导学习者更好地进行泛化。
图6。Grad-CAM[24],我们的GAIN和GAINext在偏船数据集上生成的定性结果。- #表示训练中使用的船只像素级标签的数量,这些标签是从VOC 2012中随机选择的。仅当识别到船只时,才显示与船只对应的注意力地图。
表4。Grad-CAM[24]与我们的GAIN和GAINext在偏船数据集上进行分类准确性测试的结果比较。PL标签表示在训练中使用的船只像素级标签,这些标签是随机选择的。

图7。我们的玩具实验的数据集和定性结果。每张图像中的关键区域都用红色边界框标记。GT表示真实的方向类别标签。
6.概括
我们提出了一个框架,可以直接指导弱监督学习深度神经网络生成更准确和完整的注意力地图。我们通过将注意力地图不再是事后思考,而是在训练过程中的一等公民,实现了这一目标。大量实验证明,所得到的系统在无需进行递归处理的情况下,自信地优于现有技术水平。所提出的框架可以用于改善在训练过程中使用偏倚数据时网络的鲁棒性和泛化性能,以及更好地定位和分割先验的注意力地图的完整性。未来,将我们的方法应用于除了分类之外的其他高级任务,并探索回归类型任务如何从更好的注意力中受益,可能会有启发性的。