模型部署系列 | 01: 基于Triton部署Resnet18(附完整代码,建议收藏)
简介
醉后不知天在水,满船清梦压星河。

小伙伴们好,我是微信公众号《小窗幽记机器学习》的小编:卖猪脚饭的小女孩。今天开始一个新专题:模型部署。本文作为作为模型部署系列的开篇,主要介绍如何使用Triton Server部署Pytorch格式的模型,并利用NVIDIA官方提供的工具进行服务性能测试。
完整代码其实都在文章里面了,如想进一步交流欢迎在微信公众号:《小窗幽记机器学习》上添加小编微信。更多、更新文章欢迎关注微信公众号:小窗幽记机器学习。后续会持续整理模型加速、模型部署、模型压缩、LLM、AI艺术等系列专题,敬请关注。
环境准备
创建容器
本文实验使用Triton官方提供的镜像nvcr.io/nvidia/tritonserver:22.10-py3,创建容器:
docker run --gpus all --privileged --name='triton_test' -v /data/home/:/home -itd nvcr.io/nvidia/tritonserver:22.10-py3 bash
如果出现如下报错:
docker: Error response from daemon: could not select device driver "" with capabilities: [[gpu]].
可以参考官方提供的解决方案:
$ distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
$ curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
$ curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
$ sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit
$ sudo systemctl restart docker
安装包
进入容器(docker exec -it triton_test bash)后,安装本次实验所需要的包:
pip3 install torch torchvision torchaudio -i https://pypi.tuna.tsinghua.edu.cn/simple
导出TorchScript格式
本文实验的模型是PyTorch格式,可以直接使用Triton Server的PyTorch Backend,即 LibTorch。为此,需要先将Pytorch模型格式转为TorchScript格式。更多关于TorchScript模型格式的介绍及其推理加速可以在微信公众号《小窗幽记机器学习》参考之前的文章。
具体的模型格式转换代码如下:
# -*- encoding: utf-8 -*-
'''
@File : check_jit.py
@Time : 2022/11/12 15:31:12
@Author : Jason
@Desc : 转为 TorchScript
'''
import os
os.environ['TORCH_HOME']='/share/model_zoo/cv'
"""
默认情况下环境变量TORCH_HOME的值为~/.cache
"""
import torch
import torchvision
import pdb
import time
from tqdm import tqdm
import numpy as np
def convert_resnet18_torchscript():
"""
将 resnet18 转为 TorchScript 模型格式
"""
# An instance of your model.
model = torchvision.models.resnet18(pretrained=True)
# Switch the model to eval model
model.eval()
# An example input you would normally provide to your model's forward() method.
example = torch.rand(1, 3, 224, 224)
# Use torch.jit.trace to generate a torch.jit.ScriptModule via tracing.
trace_model = torch.jit.trace(model, example) # torch.jit.ScriptModule
raw_output = model(example)
trace_model_output = trace_model(example)
np.testing.assert_allclose(raw_output.detach().numpy(), trace_model_output.detach().numpy())
# Save the TorchScript model
trace_model.save("/model_zoo/cv/model.pt")
convert_resnet18_torchscript()
基于 Triton Server 提供服务
这个章节主要介绍如何基于Triton Server 部署模型服务及其如何从客户端发送请求测试模型服务。
服务端部署模型
由于NVIDIA官方镜像中已经安装Triton Server,所以可以直接用tritonserver启动服务。启动 tritonserver 的命令如下
tritonserver --model-store=/home/cv/resnet18
如果只想指定某块具体的GPU可以:
CUDA_VISIBLE_DEVICES=0 tritonserver --model-store=/home/cv/resnet18
如果出现类似如下错误:
E1114 07:20:37.015475 1434 model_repository_manager.cc:996] Poll failed for model directory '1': Invalid model name: Could not determine backend for model '1' with no backend in model configuration. Expected model name of the form 'model.'.
说明配置文件中的模型名和模型仓库中模型目录名不一致。本文测试代码的目录结构如下:
cv/
|-- cat.jpg
|-- resnet18
| `-- resnet18_pytorch
| |-- 1
| | `-- model.pt
| |-- config.pbtxt
| `-- labels.txt
|-- test.py
`-- test_client.py
由于启动 Triton Server的时候指定的模型仓库是/home/cv/resnet18,所以,在模型仓库中具体使用的模型名要与配置文件config.pbtxt中的name: "resnet18_pytorch"一致。换句话说,resnet18目录下的resnet18_pytorch需要与config.pbtxt中的name字段的值相同。
健康检查
在启动Triton Server之后,可以向其发送运行状况检查的指令。在 shell 中运行以下命令:
curl -v localhost:8000/v2/health/ready
运行结果如下:
* Trying 127.0.0.1:8000...
* TCP_NODELAY set
* Connected to localhost (127.0.0.1) port 8000 (#0)
> GET /v2/health/ready HTTP/1.1
> Host: localhost:8000
> User-Agent: curl/7.68.0
> Accept: */*
>
* Mark bundle as not supporting multiuse
< HTTP/1.1 200 OK
< Content-Length: 0
< Content-Type: text/plain
<
* Connection #0 to host localhost left intact
客户端发送请求
方法1: 基于tritonclient
在利用Triton启动模型inference服务之后,可以用官方提供的
安装官方的客户端API:
pip3 install tritonclient[all]
在客户端发送请求到Triton Server端整个过程如下:先读取一张图片的数据,然后转换成 [ N, 3, -1, -1 ] 的格式,之后发送请求做分类。因为在模型配置文件中,已经指定了标签信息的文件(即labels.txt),所以在分类的时候可以指定是否获取分类结果。具体是在InferRequestedOutput类中,可以指定class_count参数,设置数量,表示获取 topN 分类结果。
以下Python脚本由几个步骤组成:
- 设置客户端
- 读取数据,设置一次请求的输入和输出
- 发起请求,获取结果,输出结果。
具体的客户端请求示例代码:
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
'''
@File : triton_client.py
@Time : 2022/11/11 16:47:04
@Author : Jason
@Desc : None
'''
import numpy as np
import tritonclient.http as httpclient
import torch
from PIL import Image
if __name__ == '__main__':
triton_client = httpclient.InferenceServerClient(url='127.0.0.1:8000')
image = Image.open('./cat.jpg')
image = image.resize((224, 224), Image.ANTIALIAS)
image = np.asarray(image)
image = image / 255
image = np.expand_dims(image, axis=0)
image = np.transpose(image, axes=[0, 3, 1, 2])
image = image.astype(np.float32)
inputs = []
inputs.append(httpclient.InferInput('INPUT__0', image.shape, "FP32"))
inputs[0].set_data_from_numpy(image, binary_data=False)
outputs = []
outputs.append(httpclient.InferRequestedOutput('OUTPUT__0', binary_data=False, class_count=3)) # class_count 表示 topN 分类
# outputs.append(httpclient.InferRequestedOutput('OUTPUT__0', binary_data=False))
results = triton_client.infer('resnet18_pytorch', inputs=inputs, outputs=outputs)
output_data0 = results.as_numpy('OUTPUT__0')
print(output_data0.shape)
print(output_data0)
运行结果如下:
(1, 3)
[['12.973857:281:TABBY' '12.180863:283:PERSIAN CAT'
'12.151930:285:EGYPTIAN CAT']]
可以看出,上述模型服务的预测结果是TABBY。
方法2: 基于 curl
真实的url是ip:<端口>/v2/models/。具体到本文示例,可以如下发送请求:
curl -v -X POST http://127.0.0.1:8000/v2/models/resnet18_pytorch/versions/1/infer -H 'content-type: application/json' -d @data.json
其中data.json是待post的body数据,需要包括以下几个字段。
name:指定输入的名称,与config.pbtxt中定义的输入要一致。data:模型inference最终的输入。所以,需要把预处理等其他变换操作预先做好。shape:输入data的尺寸,注意需要与config.pbtxt中的对齐。datatype:输入数据的类型,需要与config.pbtxt中的数据类型相同。
具体的data.json内容如下:
{"inputs": [{"name": "INPUT__0", "data": [[[[0.9843137264251709, 0.9137254953384399,...0.9960784316062927, 0.9921568632125854, 1.0]]]], "shape": [1, 3, 224, 224], "datatype": "FP32"}]}
请求的返回结果:
{"model_name":"resnet18_pytorch","model_version":"1","outputs":[{"name":"OUTPUT__0","datatype":"FP32","shape":[1,1000],"data":[-2.5201759338378908,-0.6822084784507752,...,4.254262447357178,7.1425909996032719]}]}
方法3:基于requests
那么如果想要基于 requests 构建请求呢?由于上述方法2已经知道具体的url,那么可以用Python中的requests直接发送请求。具有代码如下:
import numpy as np
from PIL import Image
import requests
import json
url = "http://127.0.0.1:8000/v2/models/resnet18_pytorch/versions/1/infer"
image = Image.open('./cat.jpg')
image = image.resize((224, 224), Image.ANTIALIAS)
image = np.asarray(image)
image = image / 255
image = np.expand_dims(image, axis=0)
image = np.transpose(image, axes=[0, 3, 1, 2])
image = image.astype(np.float32) # (1, 3, 224, 224)
input_dict = [{'name': 'INPUT__0', 'data':image.tolist(), "shape": [1, 3, 224, 224], "datatype": "FP32"}]
input_data = json.dumps({"inputs": input_dict})
headers = {"content-type": "application/json"}
json_response = requests.post(url, data=input_data, headers=headers)
outputs = json.loads(json_response.text)
result = np.array(outputs['outputs'][0]['data'])
top_N = 3
top_index = np.argpartition(result, -top_N)[-top_N:]
top_logits = result[top_index]
label_list = []
with open("resnet18/resnet18_pytorch/labels.txt", 'r', encoding='utf-8') as fin:
for i in fin.readlines():
label_list.append(i.strip())
id2label = {i: label for i, label in enumerate(label_list)}
label2id = {label: i for i, label in enumerate(label_list)}
top_labels = [id2label[t] for t in top_index]
new_result = []
for logit, id, label in zip(top_logits, top_index, top_labels):
# print("{}:{}:{}".format(logit, id, label))
new_result.append((logit, id, label))
# 重新排序
new_result = sorted(new_result, key=lambda x:x[0], )
print("Final result=", new_result)
运行结果如下:
Final result= [(12.973052978515625, 281, 'TABBY'), (12.17898941040039, 283, 'PERSIAN CAT'), (12.150209426879883, 285, 'EGYPTIAN CAT')]
可以看出,运行结果和triton_client的结果基本一致。
性能测试
性能测试工具
Triton 已经提供性能相关的客户端接口和客户端工具,本文这里先简要介绍,下一小节再从实测角度选择其中一个工具进行性能调优。
Triton 提供了两个接口,直接使用上面的 Python 客户端就可以获取到这些数据。
- metrics,Triton 以 Prometheus 的格式将测量的数据暴露出来。具体参考官方文档
- statistics,请求相关的统计数据。具体参考官方文档
Triton 到底提供了哪些客户端工具?熟练使用这些客户端工具有助于做好性能测量和优化。从软件演进的角度来看,下面的工具一个比一个更加自动化。
-
perf_analyzer,可以测量吞吐、延迟等。具体参考官方文档
-
model_analyzer,利用 perf_analyzer 来进行性能分析,测量 GPU 内存和利用率。具体可以参考官方Repo。
-
model_navigator,自动化部署模型。具体可以参考官方Repo
在指标Metrics上,提供了四类数据:
- GPU 使用率
- GPU 内存情况
- 请求次数统计
- 请求延迟数据。
其中 GPU 使用情况是每个 GPU 每秒的情况,因此向 metrics 接口获取数据的时候,可以获取到当前秒 GPU 的使用情况。更详细的说明可以参考官方文档。
在statistics 统计信息可以使用客户端工具获得,它记录了从 Triton 启动以来发生的所有活动。具体可以参考官方文档。
关于 模型分析工具 model_analyzer, 英伟达的开发者专门写了一篇文章介绍这个工具。
model_analyzer 可以通过 pip 安装:pip3 install triton-model-analyzer,安装完之后输入model-analyzer --help可以看到如下输出。model_analyzer 实际上是由三个子命令 (subcommand) 组成的。
usage: model-analyzer [-h] [-q] [-v] [-m {online,offline}] {profile,analyze,report} ...
positional arguments:
{profile,analyze,report}
Subcommands under Model Analyzer
profile Run model inference profiling based on specified CLI or config options.
analyze Collect and sort profiling results and generate data and summaries.
report Generate detailed reports for a single config
optional arguments:
-h, --help show this help message and exit
-q, --quiet Suppress all output except for error messages.
-v, --verbose Show detailed logs, messags and status.
-m {online,offline}, --mode {online,offline}
Choose a preset configuration mode.
关于 模型自动化部署 model_navigator
官方的介绍称这是一个自动化工具。第一步,会将模型转换成可用的格式,并应用一些 Triton 后端优化。第二步,它使用 Triton Model Analyzer 来找到最好的模型配置,以提供性能。更新详细的信息可以参考官方的Repo。
性能实测
NVIDIA 提供三个性能测试工具:perf_analyzer, model_analyzer, model_nagivator。perf_analyzer 只能测量吞吐和延迟,model_analyzer 在这基础上还可以获得 GPU 内存和使用率。因此,本文采用 model_analyzer 来测量和分析模型的性能。
model_analyzer 的安装可以参考官方文档:
pip3 install triton-model-analyzer
开始测量
运行下面的命令,指定待测量模型:
model-analyzer profile --model-repository /home/cv/resnet18/ --profile-models resnet18_pytorch --override-output-model-repository
报错:
[Model Analyzer] Running perf_analyzer failed with exit status 99:
error: failed to create concurrency manager: input INPUT__0 contains dynamic shape, provide shapes to send along with the request
这是因为模型使用了 dynamic shape,所以导致 triton 不知道应该发送什么样的向量给 server。所以这里把config.pbtxt中input中的dims 从 [3, -1, -1] 改为 [3, 224, 224]。model_analyzer 会设置 2n 的并发量做性能测试,这个 concurrency 是并发的线程数量。之后会不断提高模型实例的数量来测,直到 GPU 利用率或者显存满了。另外会分别再测试一组是否开启 dynamic batching这个选项,之后还会测试 preferred batch size 大小。
部分日志如下:
[Model Analyzer] Starting a local Triton Server
[Model Analyzer] No checkpoint file found, starting a fresh run.
[Model Analyzer] Profiling server only metrics...
[Model Analyzer]
[Model Analyzer] Creating model config: resnet18_pytorch_config_default
[Model Analyzer]
[Model Analyzer] Profiling resnet18_pytorch_config_default: client batch size=1, concurrency=1
[Model Analyzer] Profiling resnet18_pytorch_config_default: client batch size=1, concurrency=2
[Model Analyzer] Profiling resnet18_pytorch_config_default: client batch size=1, concurrency=4
[Model Analyzer] Profiling resnet18_pytorch_config_default: client batch size=1, concurrency=8
[Model Analyzer] Profiling resnet18_pytorch_config_default: client batch size=1, concurrency=16
[Model Analyzer] Profiling resnet18_pytorch_config_default: client batch size=1, concurrency=32
[Model Analyzer] Profiling resnet18_pytorch_config_default: client batch size=1, concurrency=64
[Model Analyzer] No longer increasing concurrency as throughput has plateaued
[Model Analyzer]
[Model Analyzer] Creating model config: resnet18_pytorch_config_0
[Model Analyzer] Setting instance_group to [{'count': 1, 'kind': 'KIND_GPU'}]
[Model Analyzer] Setting max_batch_size to 1
[Model Analyzer] Enabling dynamic_batching
[Model Analyzer]
[Model Analyzer] Profiling resnet18_pytorch_config_0: client batch size=1, concurrency=1
[Model Analyzer] Profiling resnet18_pytorch_config_0: client batch size=1, concurrency=2
[Model Analyzer] Profiling resnet18_pytorch_config_0: client batch size=1, concurrency=4
[Model Analyzer] Profiling resnet18_pytorch_config_0: client batch size=1, concurrency=8
[Model Analyzer] Profiling resnet18_pytorch_config_0: client batch size=1, concurrency=16
[Model Analyzer] Profiling resnet18_pytorch_config_0: client batch size=1, concurrency=32
[Model Analyzer] Profiling resnet18_pytorch_config_0: client batch size=1, concurrency=64
[Model Analyzer] No longer increasing concurrency as throughput has plateaued
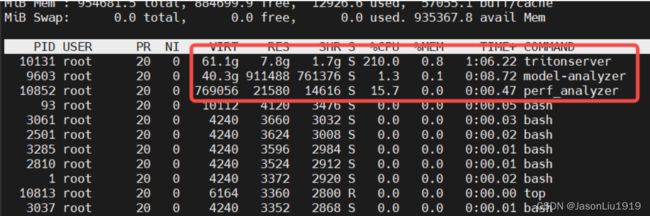
生成报告
测试好了之后,先输入下面的命令安装依赖。生成分析报告和详细报告。
wget https://github.com/wkhtmltopdf/packaging/releases/download/0.12.6-1/wkhtmltox_0.12.6-1.focal_amd64.deb
apt update
apt install ./wkhtmltox_0.12.6-1.focal_amd64.deb -f
mkdir analysis_results
model-analyzer analyze --analysis-models resnet18_pytorch -e analysis_results
运行结果如下:
[Model Analyzer] Loaded checkpoint from file /home/checkpoints/0.ckpt
[Model Analyzer] Exporting Summary Report to analysis_results/reports/summaries/resnet18_pytorch/result_summary.pdf
[Model Analyzer] Exporting server only metrics to analysis_results/results/metrics-server-only.csv
[Model Analyzer] Exporting inference metrics to analysis_results/results/metrics-model-inference.csv
[Model Analyzer] Exporting GPU metrics to analysis_results/results/metrics-model-gpu.csv
[Model Analyzer]
[Model Analyzer] To generate detailed reports for the 3 best configurations, run `model-analyzer report --report-model-configs resnet18_pytorch_config_18,resnet18_pytorch_config_5,resnet18_pytorch_config_6 --export-path analysis_results`
根据上述信息选择对应的配置文件:
model-analyzer report --report-model-configs resnet18_pytorch_config_18,resnet18_pytorch_config_5,resnet18_pytorch_config_6 -e analysis_results
运行结果如下:
[Model Analyzer] Loaded checkpoint from file /home/checkpoints/0.ckpt
[Model Analyzer] Exporting Detailed Report to analysis_results/reports/detailed/resnet18_pytorch_config_18/detailed_report.pdf
[Model Analyzer] Exporting Detailed Report to analysis_results/reports/detailed/resnet18_pytorch_config_5/detailed_report.pdf
[Model Analyzer] Exporting Detailed Report to analysis_results/reports/detailed/resnet18_pytorch_config_6/detailed_report.pdf
model_analyzer会尝试搜索两种不同的配置,一种是最小化时延的 online mode,另一种是最大化吞吐的 offline mode。默认情况下搜索时延最小化的方案,即默认是 online mode。
分析报告
以下3个图是 online mode下最好的3个配置的详细报告。
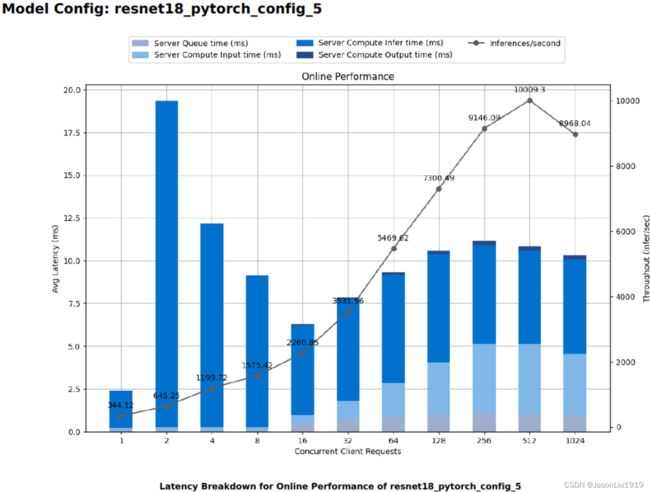
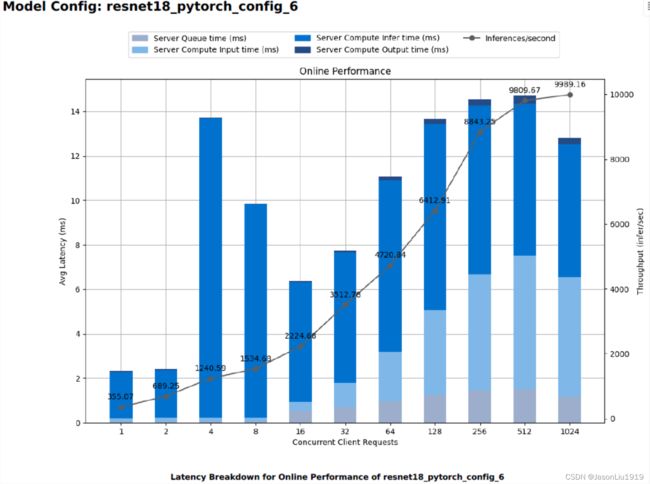
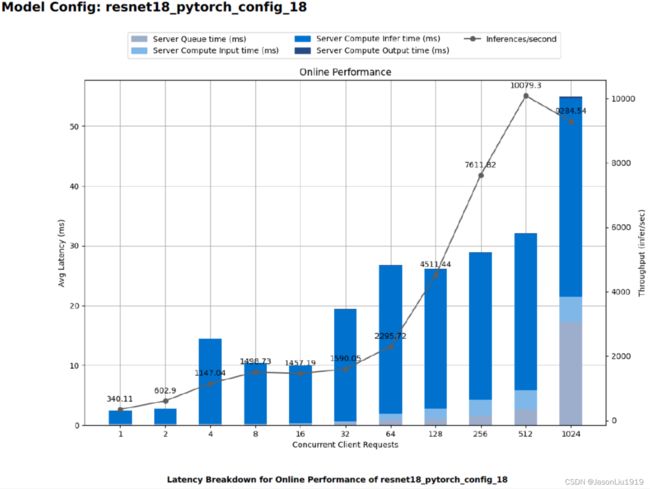
因为这是个多目标优化问题,所以究竟该选择怎么样的配置取决于业务场景的约束。triton 对这个的处理过于简单,比如 online mode 直接选择延迟最小的那个配置。实际上是因为这个问题和业务场景太相关,并且需要的配置项太多了,以至于只能简化处理。复杂的逻辑、业务相关的逻辑需要交给用户自己去做选择。
拓展说明
model_analyzer通过暴力搜索选项找到最优配置,这些选项有些是 triton 自动配置的,一些是需要手动配置才会进行搜索的。更多的模型配置选项可以参考官方的模型配置搜索文档。
但是上述文档没有说明启动的时候,如何才可以使用那些配置文件。因此关于使用这些配置文件以使得model_analyzer过程能够使用自定义的模型配置选项,可以去查阅官方的 CLI 文档。
性能调优和指标
前文提到使用model_analyzer测量性能的时候,会尝试搜索不同配置选项下的性能。那么影响性能的选项有哪些呢?
配置选项:
- Instance Group,每个设备上使用多少个模型实例。模型实例占内存,但可以提高利用率
- Dynamic Batching,是否开启 batching。 将请求积攒到一定数量后,再做推理。
- Preferred Batch Sizes, 可以设置不同的数值,在一定的排队时间内,如果达到了其中一个数值,就马上做请求,而不用等待其他请求。
- Model Rate Limiter,约束模型的执行。
- Model Queue Policy,排队时间等待策略。
- Model Warmup,避免第一次启动的延迟。
- Model Response Cache, 这是最近增加的特性,是否开启缓存。如果遇到了相同的请求,就会使用缓存。
指标
不同场景的Serving,优化目标可能不同。目标是多个的,复杂的,并不是那么单一。既想最小化延迟的同时,又要最大化吞吐。目标严重依赖于应用场景,因此只有确立目标,才可以往那个方向尽可能的优化。
- 延迟
- 吞吐
- GPU 利用率
- GPU 内存占用
- GPU 功耗
- 业务相关的指标:比如在尽可能少的设备上放尽可能多的模型
关于Triton Server的其他细节,留待后续详解,敬请留意!