第J1周:ResNet-50算法实战与解析
- 本文为365天深度学习训练营 中的学习记录博客
- 参考文章:365天深度学习训练营-第J1周:ResNet-50算法实战与解析
- 原作者:K同学啊|接辅导、项目定制
目录
-
- 理论知识储备
- 一、环境配置
- 二、数据读取
- 三、构建网络
-
-
- IdentityBlock
- ConvBlock
- ResNet50
-
- 四、训练与测试
- 五、正式训练
本周任务:
●1.请根据本文 TensorFlow 代码,编写出相应的 Pytorch 代码
●2.了解残差结构
●3.是否可以将残差模块融入到C3当中(自由探索)
理论知识储备
深度残差网络ResNet(deep residual network)在2015年由何恺明等提出,因为它简单与实用并存,随后很多研究都是建立在ResNet-50或者ResNet-101基础上完成。
ResNet主要解决深度卷积网络在深度加深时候的“退化”问题。在一般的卷积神经网络中,增大网络深度后带来的第一个问题就是梯度消失、爆炸,这个问题Szegedy提出BN层后被顺利解决。BN层能对各层的输出做归一化,这样梯度在反向层层传递后仍能保持大小稳定,不会出现过小或过大的情况。但是作者发现加了BN后再加大深度仍然不容易收敛,其提到了第二个问题–准确率下降问题:层级大到一定程度时准确率就会饱和,然后迅速下降,这种下降即不是梯度消失引起的也不是过拟合造成的,而是由于网络过于复杂,以至于光靠不加约束的放养式的训练很难达到理想的错误率。
准确率下降问题不是网络结构本身的问题,而是现有的训练方式不够理想造成的。当前广泛使用的优化器,无论是SGD,还是RMSProp,或是Adam,都无法在网络深度变大后达到理论上最优的收敛结果。
作者在文中证明了只要有合适的网络结构,更深的网络肯定会比较浅的网络效果要好。证明过程也很简单:假设在一种网络A的后面添加几层形成新的网络B,如果增加的层级只是对A的输出做了个恒等映射(identity mapping),即A的输出经过新增的层级变成B的输出后没有发生变化,这样网络A和网络B的错误率就是相等的,也就证明了加深后的网络不会比加深前的网络效果差。
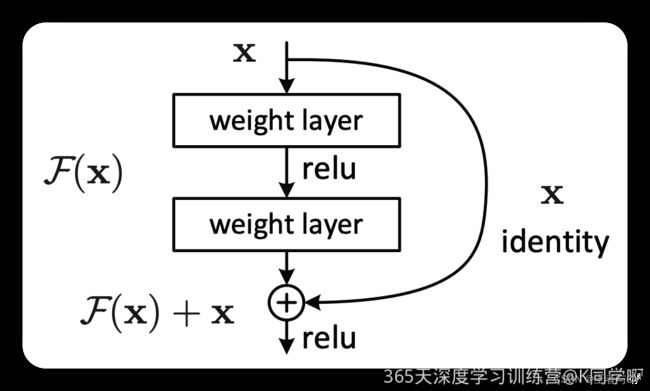
图1 残差模块
何恺明提出了一种残差结构来实现上述恒等映射(图1):整个模块除了正常的卷积层输出外,还有一个分支把输入直接连到输出上,该分支输出和卷积的输出做算术相加得到最终的输出,用公式表达就是
H(x)=F(x)+x,x是输入,F(x)是卷积分支的输出,H(x)是整个结构的输出。可以证明如果F(x)分支中所有参数都是0,H(x)就是个恒等映射。残差结构人为制造了恒等映射,就能让整个结构朝着恒等映射的方向去收敛,确保最终的错误率不会因为深度的变大而越来越差。如果一个网络通过简单的手工设置参数值就能达到想要的结果,那这种结构就很容易通过训练来收敛到该结果,这是一条设计复杂的网络时通用的规则。

图2 两种残差单元
图2左边的单元为 ResNet 两层的残差单元,两层的残差单元包含两个相同输出的通道数的 3x3 卷积,只是用于较浅的 ResNet 网络,对较深的网络主要使用三层的残差单元。三层的残差单元又称为 bottleneck 结构,先用一个 1x1 卷积进行降维,然后 3x3 卷积,最后用 1x1 升维恢复原有的维度。另外,如果有输入输出维度不同的情况,可以对输入做一个线性映射变换维度,再连接后面的层。三层的残差单元对于相同数量的层又减少了参数量,因此可以拓展更深的模型。通过残差单元的组合有经典的 ResNet-50,ResNet-101 等网络结构。
一、环境配置
import torch
from torchvision import datasets, transforms
import torch.nn as nn
import time
import numpy as np
import matplotlib.pyplot as plt
import torchsummary as summary
from collections import OrderedDict
二、数据读取
data_dir = './data/bird_photos'
# 归一化参数是怎么来的, tf模型中没有归一化这个过程会不会导致结果不一致?
raw_transforms = transforms.Compose(
[
transforms.Resize(224),#中心裁剪到224*224
transforms.ToTensor(),#转化成张量)
])
def random_split_imagefolder(data_dir, transforms, random_split_rate=0.8):
_total_data = datasets.ImageFolder(data_dir, transform=transforms)
train_size = int(random_split_rate * len(_total_data))
test_size = len(_total_data) - train_size
_train_datasets, _test_datasets = torch.utils.data.random_split(_total_data, [train_size, test_size])
return _total_data, _train_datasets, _test_datasets
batch_size = 32
total_data, train_datasets, test_datasets = random_split_imagefolder(data_dir, raw_transforms, 0.8)
三、构建网络
IdentityBlock
IdentityBlock类是一个残差块。残差块是深度残差网络中的基本构建块,可以帮助网络更好地学习和优化。通过将恒等映射和输入进行相加后再进行非线性变换来学习残差。其中,卷积层被用来提取特征,批归一化层用于规范化输出。ReLU激活函数被应用在恒等映射之后和最终的输出上,帮助网络学习非线性关系。
class IdentityBlock(nn.Module):
def __init__(self, in_channel, kl_size, filters):
super(IdentityBlock, self).__init__()
# 定义卷积层和批归一化层
filter1, filter2, filter3 = filters
# 第一个卷积层
self.cov1 = nn.Conv2d(in_channels=in_channel, out_channels=filter1, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(num_features=filter1)
self.relu = nn.ReLU(inplace=True)
# 第二个卷积层
self.cov2 = nn.Conv2d(in_channels=filter1, out_channels=filter2, kernel_size=kl_size, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(num_features=filter2)
# 第三个卷积层
self.cov3 = nn.Conv2d(in_channels=filter2, out_channels=filter3, kernel_size=1, stride=1, padding=0)
self.bn3 = nn.BatchNorm2d(num_features=filter3)
def forward(self, x):
# 前向传播函数
# 定义identity(恒等映射)
identity = self.cov1(x)
identity = self.bn1(identity)
identity = self.relu(identity)
# 进行两次卷积操作,并使用批归一化和ReLU激活函数
identity = self.cov2(identity)
identity = self.bn2(identity)
identity = self.relu(identity)
identity = self.cov3(identity)
identity = self.bn3(identity)
# 将恒等映射和输入相加,并使用ReLU激活函数
x = x + identity
x = self.relu(x)
return x
ConvBlock
ConvBlock类是一个卷积块。卷积块是深度残差网络中的基本构建块,它通过使用跨步卷积(stride convolution)来降低特征图的尺寸。
通过使用跨步卷积来降低特征图的尺寸,并通过恒等映射进行尺寸匹配。卷积层被用来提取特征,批归一化层用于规范化输出。ReLU激活函数被应用在恒等映射之后和最终的输出上,帮助网络学习非线性关系。这个卷积块可以用于深度残差网络的构建。
class ConvBlock(nn.Module):
def __init__(self, in_channel, kl_size, filters, stride_size=2):
super(ConvBlock, self).__init__()
filter1, filter2, filter3 = filters
# 第一个卷积层,使用跨步卷积
self.cov1 = nn.Conv2d(in_channels=in_channel, out_channels=filter1, kernel_size=1, stride=stride_size, padding=0)
self.bn1 = nn.BatchNorm2d(num_features=filter1)
self.relu = nn.ReLU(inplace=True)
# 第二个卷积层,不使用跨步卷积
self.cov2 = nn.Conv2d(in_channels=filter1, out_channels=filter2, kernel_size=kl_size, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(num_features=filter2)
# 第三个卷积层
self.cov3 = nn.Conv2d(in_channels=filter2, out_channels=filter3, kernel_size=1, stride=1, padding=0)
self.bn3 = nn.BatchNorm2d(num_features=filter3)
# 恒等映射用于在跨步卷积和卷积层之间进行尺寸匹配
self.short_cut = nn.Conv2d(in_channels=in_channel, out_channels=filter3, kernel_size=1, stride=stride_size, padding=0)
def forward(self, x):
# 前向传播函数
# 定义identity(恒等映射)
identity = self.cov1(x) # 使用跨步卷积
identity = self.bn1(identity)
identity = self.relu(identity)
# 进行两次卷积操作,并使用批归一化和ReLU激活函数
identity = self.cov2(identity)
identity = self.bn2(identity)
identity = self.relu(identity)
identity = self.cov3(identity)
identity = self.bn3(identity)
# 使用恒等映射调整尺寸
short_cut = self.short_cut(x)
x = identity + short_cut
x = self.relu(x)
return x
ResNet50
class Resnet50_Model(nn.Module):
def __init__(self):
super(Resnet50_Model, self).__init__()
self.in_channels = 3
self.layers = [2, 3, 5, 2]
# ============= 基础层
# 方法1
self.cov0 = nn.Conv2d(self.in_channels, out_channels=64, kernel_size=7, stride=2, padding=3)
self.bn0 = nn.BatchNorm2d(num_features=64)
self.relu0 = nn.ReLU(inplace=False)
self.maxpool0 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.basic_layer = nn.Sequential(
self.cov0,
self.bn0,
self.relu0,
self.maxpool0
)
self.layer1 = nn.Sequential(
ConvBlock(64, 3, [64, 64, 256], 1),
IdentityBlock(256, 3, [64, 64, 256]),
IdentityBlock(256, 3, [64, 64, 256]),
)
self.layer2 = nn.Sequential(
ConvBlock(256, 3, [128, 128, 512]),
IdentityBlock(512, 3, [128, 128, 512]),
IdentityBlock(512, 3, [128, 128, 512]),
IdentityBlock(512, 3, [128, 128, 512]),
)
self.layer3 = nn.Sequential(
ConvBlock(512, 3, [256, 256, 1024]),
IdentityBlock(1024, 3, [256, 256, 1024]),
IdentityBlock(1024, 3, [256, 256, 1024]),
IdentityBlock(1024, 3, [256, 256, 1024]),
IdentityBlock(1024, 3, [256, 256, 1024]),
IdentityBlock(1024, 3, [256, 256, 1024]),
)
self.layer4 = nn.Sequential(
ConvBlock(1024, 3, [512, 512, 2048]),
IdentityBlock(2048, 3, [512, 512, 2048]),
IdentityBlock(2048, 3, [512, 512, 2048]),
)
# 输出网络
self.avgpool = nn.AvgPool2d((7, 7))
# classfication layer
# 7*7均值后2048个参数
self.fc = nn.Sequential(nn.Linear(2048, N_classes),
nn.Softmax(dim=1))
def forward(self, x):
x = self.basic_layer(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
四、训练与测试
from torch.utils.data import DataLoader
from tqdm import tqdm
def train_and_test(model, loss_func, optimizer, epochs=25):
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
summary.summary(model, (3, 224, 224))
record = []
best_acc = 0.0
best_epoch = 0
train_data = DataLoader(train_datasets, batch_size=batch_size, shuffle=True)
test_data = DataLoader(test_datasets, batch_size=batch_size, shuffle=True)
train_data_size = len(train_data.dataset)
test_data_size = len(test_data.dataset)
for epoch in range(epochs):#训练epochs轮
epoch_start = time.time()
print("Epoch: {}/{}".format(epoch + 1, epochs))
model.train()#训练
train_loss = 0.0
train_acc = 0.0
valid_loss = 0.0
valid_acc = 0.0
for i, (inputs, labels) in enumerate(train_data):
inputs = inputs.to(device)
labels = labels.to(device)
#print(labels)
# 记得清零
optimizer.zero_grad()
outputs = model(inputs)
loss = loss_func(outputs, labels)
loss.backward()
optimizer.step()
train_loss += loss.item() * inputs.size(0)
ret, predictions = torch.max(outputs.data, 1)
correct_counts = predictions.eq(labels.data.view_as(predictions))
acc = torch.mean(correct_counts.type(torch.FloatTensor))
train_acc += acc.item() * inputs.size(0)
with torch.no_grad():
model.eval()#验证
for j, (inputs, labels) in enumerate(test_data):
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
loss = loss_func(outputs, labels)
valid_loss += loss.item() * inputs.size(0)
ret, predictions = torch.max(outputs.data, 1)
correct_counts = predictions.eq(labels.data.view_as(predictions))
acc = torch.mean(correct_counts.type(torch.FloatTensor))
valid_acc += acc.item() * inputs.size(0)
avg_train_loss = train_loss / train_data_size
avg_train_acc = train_acc / train_data_size
avg_valid_loss = valid_loss / test_data_size
avg_valid_acc = valid_acc / test_data_size
record.append([avg_train_loss, avg_valid_loss, avg_train_acc, avg_valid_acc])
if avg_valid_acc > best_acc :#记录最高准确性的模型
best_acc = avg_valid_acc
best_epoch = epoch + 1
epoch_end = time.time()
print("Epoch: {:03d}, Training: Loss: {:.4f}, Accuracy: {:.4f}%, \n\t\tValidation: Loss: {:.4f}, Accuracy: {:.4f}%, Time: {:.4f}s".format(
epoch + 1, avg_valid_loss, avg_train_acc * 100, avg_valid_loss, avg_valid_acc * 100,
epoch_end - epoch_start))
print("Best Accuracy for validation : {:.4f} at epoch {:03d}".format(best_acc, best_epoch))
return model, record
五、正式训练
epochs = 25
model = Resnet50_Model()
loss_func = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(),lr=0.0001)
model, record = train_and_test(model, loss_func, optimizer, epochs)
torch.save(model, './Best_Resnet50.pth')
record = np.array(record)
plt.plot(record[:, 0:2])
plt.legend(['Train Loss', 'Valid Loss'])
plt.xlabel('Epoch Number')
plt.ylabel('Loss')
plt.ylim(0, 1.5)
plt.savefig('Loss.png')
plt.show()
plt.plot(record[:, 2:4])
plt.legend(['Train Accuracy', 'Valid Accuracy'])
plt.xlabel('Epoch Number')
plt.ylabel('Accuracy')
plt.ylim(0, 1)
plt.savefig('Accuracy.png')
plt.show()
参考文章:http://t.csdn.cn/y3kG2