sharding-jdbc(2)-快速入门
使用sharding-jdbc完成对订单表的水平分表,通过快速入门程序的开发,快速体验sharding-jdbc的使用方法。
手动创建两张表:t_order_1和t_order_2,这两张表示订单拆分后的表,通过sharding-jdbc向订单表插入数据,按照一定的分片规则,主键为偶数的进入t_order_2,主键为奇数的进入t_order_1。
通过sharding-jdbc查询数据,根据SQL语句的内容从t_order_1或t_order_2查询数据
第1步、创建订单库order_db,然后在order_db中创建表t_order_1、t_order_2表
1)、创建订单库order_db
CREATE DATABASE `order_db` CHARACTER SET 'utf8' COLLATE 'utf8_general_ci';2)、创建t_order_1和t_order_2表
DROP TABLE IF EXISTS `t_order_1`;
CREATE TABLE `t_order_1` (
`order_id` bigint(20) NOT NULL COMMENT '订单id',
`price` decimal(10, 2) NOT NULL COMMENT '订单价格',
`user_id` bigint(20) NOT NULL COMMENT '下单用户id',
`status` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '订单状态',
PRIMARY KEY (`order_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
DROP TABLE IF EXISTS `t_order_2`;
CREATE TABLE `t_order_2` (
`order_id` bigint(20) NOT NULL COMMENT '订单id',
`price` decimal(10, 2) NOT NULL COMMENT '订单价格',
`user_id` bigint(20) NOT NULL COMMENT '下单用户id',
`status` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '订单状态',
PRIMARY KEY (`order_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;创建完成后,如下:

第2步、创建maven工程,并在pom.xml中引入依赖
org.apache.shardingsphere
sharding‐jdbc‐spring‐boot‐starter
4.0.0‐RC1
引入sharding-jdbc和springBoot整合的jar包
第3步、编写程序
1)、分片规则配置
分片规则配置是sharding-jdbc进行对分库分表操作的重要依据,配置内容包括:数据源、主键生成策略、分片策略等。
server.port=56081
spring.application.name = sharding-jdbc-simple-demo
server.servlet.context-path = /sharding-jdbc-simple-demo
spring.http.encoding.enabled = true
spring.http.encoding.charset = UTF-8
spring.http.encoding.force = true
spring.main.allow-bean-definition-overriding = true
mybatis.configuration.map-underscore-to-camel-case = true
#sharding-jdbc分片规则配置
#数据源
spring.shardingsphere.datasource.names = m1
spring.shardingsphere.datasource.m1.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.m1.url = jdbc:mysql://localhost:3306/order_db?useUnicode=true
spring.shardingsphere.datasource.m1.username = root
spring.shardingsphere.datasource.m1.password = root
# 指定t_order表的数据分布情况,配置数据节点 m1.t_order_1,m1.t_order_2
spring.shardingsphere.sharding.tables.t_order.actual-data-nodes = m1.t_order_$->{1..2}
# 指定t_order表的主键生成策略为SNOWFLAKE
spring.shardingsphere.sharding.tables.t_order.key-generator.column=order_id
spring.shardingsphere.sharding.tables.t_order.key-generator.type=SNOWFLAKE
# 指定t_order表的分片策略,分片策略包括分片键和分片算法
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.sharding-column = order_id
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.algorithm-expression = t_order_$->{order_id % 2 + 1}
# 打开sql输出日志
spring.shardingsphere.props.sql.show = true
swagger.enable = true
logging.level.root = info
logging.level.org.springframework.web = info
logging.level.com.itheima.dbsharding = debug
logging.level.druid.sql = debug
2)、数据操作
package com.wzy.dao;
import org.apache.ibatis.annotations.Insert;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Param;
import org.apache.ibatis.annotations.Select;
import org.springframework.stereotype.Component;
import java.math.BigDecimal;
import java.util.List;
import java.util.Map;
/**
* Created by Administrator.
*/
@Mapper
@Component
public interface OrderDao {
/**
* 插入订单
* @param price
* @param userId
* @param status
* @return
*/
@Insert("insert into t_order(price,user_id,status)values(#{price},#{userId},#{status})")
int insertOrder(@Param("price") BigDecimal price, @Param("userId") Long userId, @Param("status") String status);
/**
* 根据id列表查询订单
* @param orderIds
* @return
*/
@Select("")
List3)、测试
编写启动类,代码如下:
package com.wzy;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class ShardingJdbcSimpleBootstrap {
public static void main(String[] args) {
SpringApplication.run(ShardingJdbcSimpleBootstrap.class, args);
}
}
测试
package com.wzy.test;
import com.wzy.ShardingJdbcSimpleBootstrap;
import com.wzy.dao.OrderDao;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import java.math.BigDecimal;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
/**
* @author Administrator
* @version 1.0
**/
@RunWith(SpringRunner.class)
@SpringBootTest(classes = {ShardingJdbcSimpleBootstrap.class})
public class OrderDaoTest {
@Autowired
OrderDao orderDao;
@Test
public void testInsertOrder(){
for(int i=1;i<20;i++){
orderDao.insertOrder(new BigDecimal(i),1L,"SUCCESS");
}
}
@Test
public void testSelectOrderbyIds(){
List ids = new ArrayList<>();
ids.add(373897739357913088L);
ids.add(373897037306920961L);
List 执行结果如下:
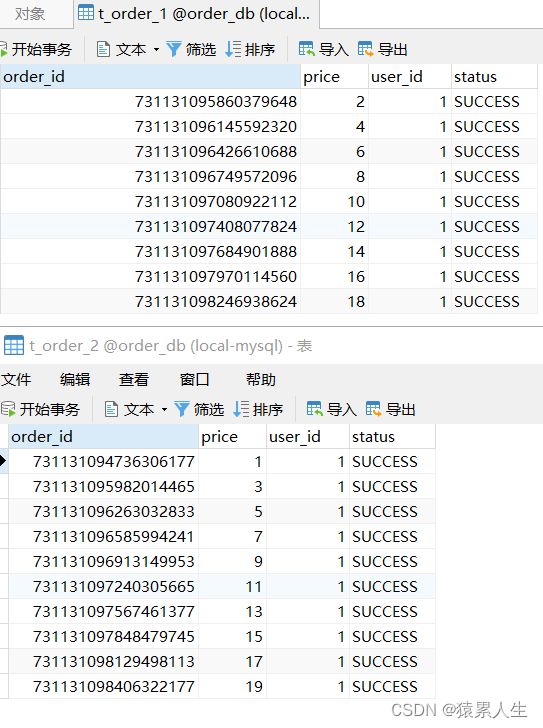
通过日志发现,order_id为奇数的被插入到t_order_2表,为偶数的被插入到t_order_1表,达到了预期目标。
通过执行testSelectOrderbyIds,可以发现根据传入的order_id的奇偶不同,sharding-jdbc分别去不同的表检索数据.
如果id为偶数,则从t_order_1表中查询。

如果id为奇数,则从t_order_2表中查询
执行流程分析:
通过日志分析,sharding-jdbc在拿到用户要执行的sql之后做了如下事情:
1)、解析sql,获取片键值,在本例中为order_id
2)、sharding-jdbc通过规则配置t_order_$->{order_id%2+1},知道了当order_id为偶数时,应该往t_order_1表插数据,为奇数时,往t_order_2插数据。
3)、于是sharding-jdbc根据order_id的值改写sql语句,改写后的SQL语句是真实所要执行的SQL语句。
4)、执行改写后的真实sql语句
5)、将所有真正执行sql的结果进行汇总合并,返回。