Go语言学习笔记(狂神说)
Go语言学习笔记(狂神说)
视频地址:https://www.bilibili.com/video/BV1ae41157o9
1、聊聊Go语言的历史
聊聊Go语言的历史-KuangStudy-文章
2、Go语言能做什么
下面列举的是原生使用Go语言进行开发的部分项目。
Docker
Docker 是一种操作系统层面的虚拟化技术,可以在操作系统和应用程序之间进行隔离,也可以称之为容器。Docker 可以在一台物理服务器上快速运行一个或多个实例。例如,启动一个 CentOS 操作系统,并在其内部命令行执行指令后结束,整个过程就像自己在操作系统一样高效。
项目链接:https://github.com/docker/docker
Go语言
Go语言自己的早期源码使用C语言和汇编语言写成。从 Go 1.5 版本后,完全使用Go语言自身进行编写。Go语言的源码对了解Go语言的底层调度有极大的参考意义,建议希望对Go语言有深入了解的读者读一读。
项目链接:https://github.com/golang/go
Kubernetes
Google 公司开发的构建于 Docker 之上的容器调度服务,用户可以通过 Kubernetes 集群进行云端容器集群管理。系统会自动选取合适的工作节点来执行具体的容器集群调度处理工作。其核心概念是 Container Pod(容器仓)。
项目链接:https://github.com/kubernetes/kubernetes
etcd
一款分布式、可靠的 KV 存储系统,可以快速进行云配置。由 CoreOS 开发并维护键值存储系统,它使用Go语言编写,并通过 Raft 一致性算法处理日志复制以保证强一致性。
项目链接:https://github.com/coreos/etcd
beego
beego 是一个类似 Python 的 Tornado 框架,采用了 RESTFul 的设计思路,使用Go语言编写的一个极轻量级、高可伸缩性和高性能的 Web 应用框架。
项目链接:https://github.com/astaxie/beego
martini
一款快速构建模块化的 Web 应用的Go语言框架。
项目链接:https://github.com/go-martini/martini
codis
国产的优秀分布式 Redis 解决方案。可以将 codis 理解成为 Web 服务领域的 Nginx,它实现了对 Redis 的反向代理和负载均衡。
项目链接:https://github.com/CodisLabs/codis
delve
Go语言强大的调试器,被很多集成环境和编辑器整合。
项目链接:https://github.com/derekparker/delve
哪些大公司在用
Go语言是谷歌在 2009 年发布的一款编程语言,自面世以来它以高效的开发效率和完美的运行速度迅速风靡全球,被誉为“21 世纪的C语言”。
现在越来越多的公司开始使用Go语言开发自己的服务,同时也诞生了很多使用Go语言开发的服务和应用,比如 Docker、k8s 等,下面我们来看一下,有哪些大公司在使用Go语言。
作为创造了Go语言的 google 公司,当然会力挺Go语言了。Google 有很多基于 Go 开发的开源项目,比如 kubernets,docker,大家可以参考《哪些项目使用Go语言开发》一节了解更多的Go语言开源项目。
Facebook 也在使用Go语言,为此他们还专门在 Github 上建立了一个开源组织 facebookgo。大家可以通过 https://github.com/facebookgo 访问查看 facebook 开源的项目,其中最具代表性的就是著名平滑重启工具 grace。
腾讯
腾讯在 15 年就已经做了 Docker 万台规模的实践。因为腾讯主要的开发语言是 C/C++ ,所以在使用Go语言方面会方便很多,也有很多优势,不过日积月累的 C/C++ 代码很难改造,也不敢动,所以主要在新业务上尝试使用 Go。
百度
百度主要在运维方面使用到了Go语言,比如百度运维的一个 BFE 项目,主要负责前端流量的接入,其次就是百度消息通讯系统的服务器端也使用到了Go语言。
七牛云
七牛云算是国内第一家选Go语言做服务端的公司。早在 2011 年,当Go语言的语法还没完全稳定下来的情况下,七牛云就已经选择将 Go 作为存储服务端的主体语言。
京东
京东云消息推送系统、云存储,以及京东商城的列表页等都是使用Go语言开发的。
小米
小米对Go语言的支持,在于运维监控系统的开源,它的官方网址是 http://open-falcon.org/ 此外,小米互娱、小米商城、小米视频、小米生态链等团队都在使用Go语言。
360
360 对Go语言的使用也不少,比如开源的日志搜索系统 Poseidon,大家可以通过.
https://github.com/Qihoo360/poseidon 查看,还有 360 的推送团队也在使用Go语言。
除了上面提到的,还有很多公司开始尝试使用Go语言,比如美团、滴滴、新浪等。
Go语言的强项在于它适合用来开发网络并发方面的服务,比如消息推送、监控、容器等,所以在高并发的项目上大多数公司会优先选择 Golang 作为开发语言。
Go语言代码清爽
Go语言语法类似于C语言,因此熟悉C语言及其派生语言([C++]、[C#]、Objective-C 等)的人都会迅速熟悉这门语言。
C语言的有些语法会让代码可读性降低甚至发生歧义。Go语言在C语言的基础上取其精华,弃其糟粕,将C语言中较为容易发生错误的写法进行调整,做出相应的编译提示。
去掉循环冗余括号
Go语言在众多大师的丰富实战经验的基础上诞生,去除了C语言语法中一些冗余、烦琐的部分。下面的代码是C语言的数值循环:
// C语言的for数值循环for(int a =0;a<10;a++){// 循环代码}
在Go语言中,这样的循环变为:
for a :=0; a<10; a++ {// 循环代码}
for 两边的括号被去掉,int 声明被简化为:=,直接通过编译器右值推导获得 a 的变量类型并声明。
去掉表达式冗余括号
同样的简化也可以在判断语句中体现出来,以下是C语言的判断语句:
if(表达式){// 表达式成立}
在Go语言中,无须添加表达式括号,代码如下:
if表达式{// 表达式成立}
强制的代码风格
Go语言中,左括号必须紧接着语句不换行。其他样式的括号将被视为代码编译错误。这个特性刚开始会使开发者有一些不习惯,但随着对Go语言的不断熟悉,开发者就会发现风格统一让大家在阅读代码时把注意力集中到了解决问题上,而不是代码风格上。
同时Go语言也提供了一套格式化工具。一些Go语言的开发环境或者编辑器在保存时,都会使用格式化工具对代码进行格式化,让代码提交时已经是统一格式的代码。
不再纠结于 i++ 和 ++i
C语言非常经典的考试题为:
int a, b;
a = i++;
b = ++i;
这种题目对于初学者简直摸不着头脑。为什么一个简单的自增表达式需要有两种写法?
在Go语言中,自增操作符不再是一个操作符,而是一个语句。因此,在Go语言中自增只有一种写法:
i++
如果写成前置自增++i,或者赋值后自增a=i++都将导致编译错误。
3、Go语言环境安装
下载地址:https://studygolang.com/dl
下载完成后一路next即可!
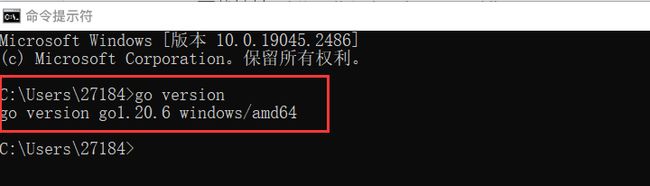
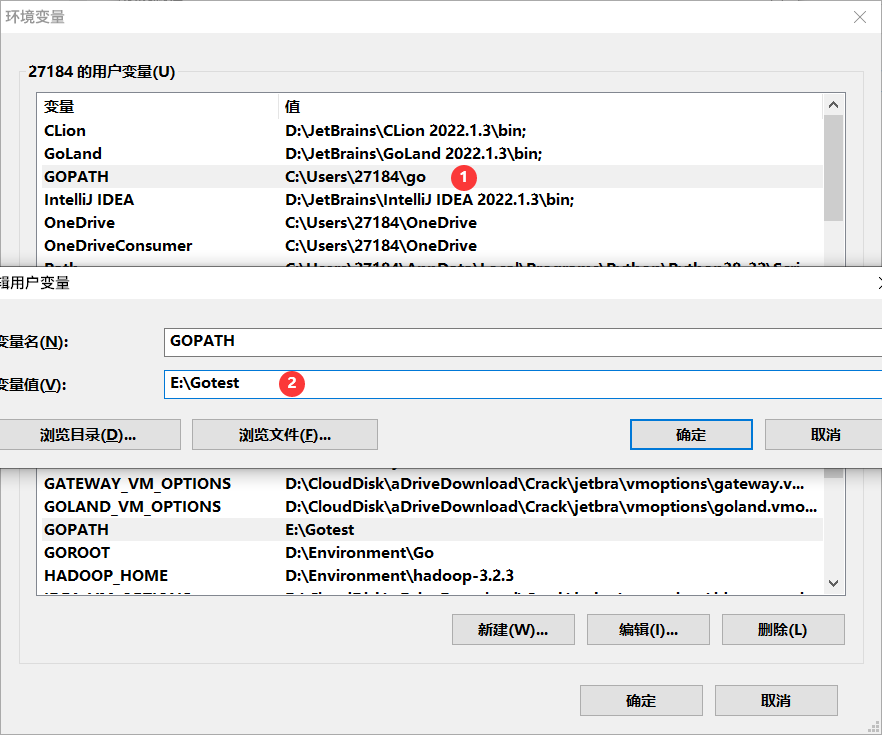
接下来去配置环境变量。Go语言需要一个安装目录,还需要一个工作目录。即GOROOT和GOPATH。

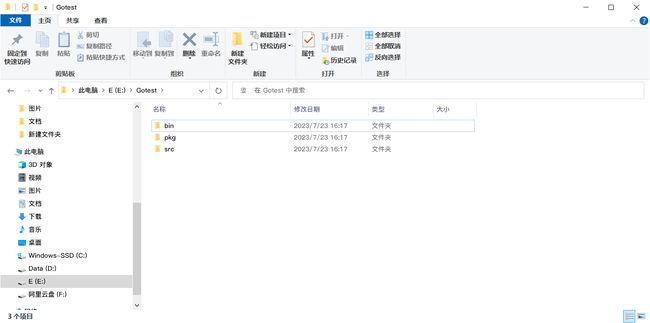
在**GOPATH**对应的目录下,需要建三个文件夹。src、pkg、bin。
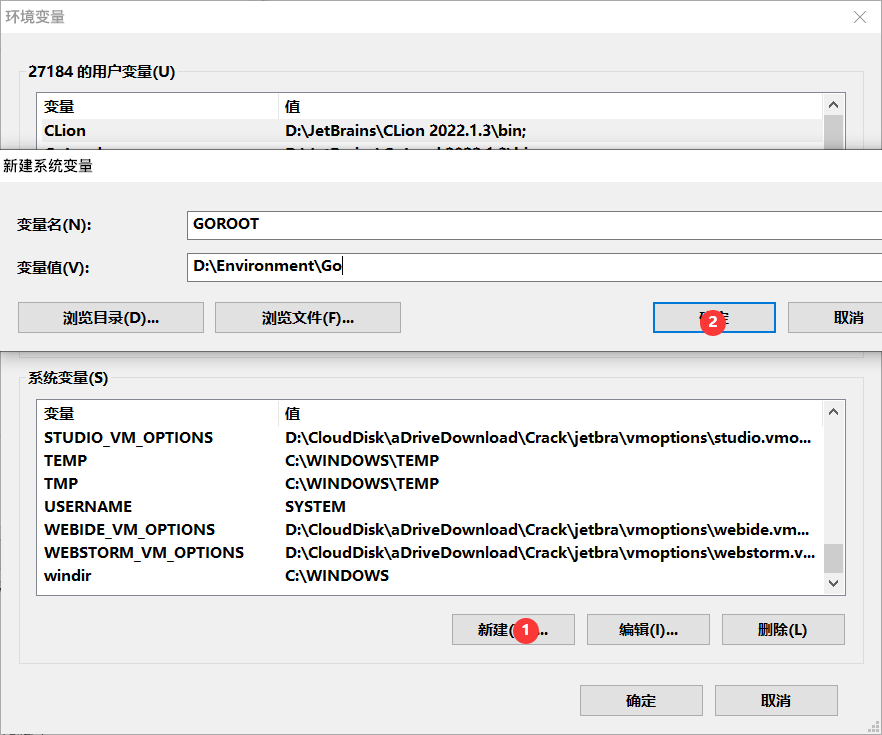
接下来改一下用户变量:
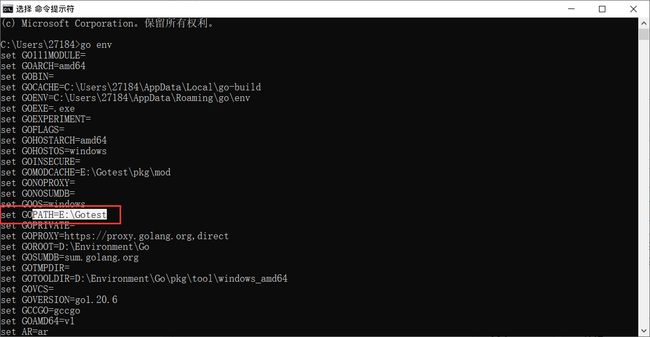
打开cmd进行验证:
4、GoLand安装
如果是学生的话,可以通过大学邮箱每次免费申请1年的正版软件
如果是个人学习使用,可以通过一些公众号等自行下载破解~
5、HelloWorld
新建一个Hello.go文件
package main
import "fmt"
func main(){
fmt.Println("Hello World!")
}
打开当前文件夹的cmd
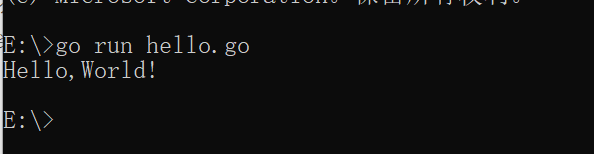
用GoLang编写HelloWorld
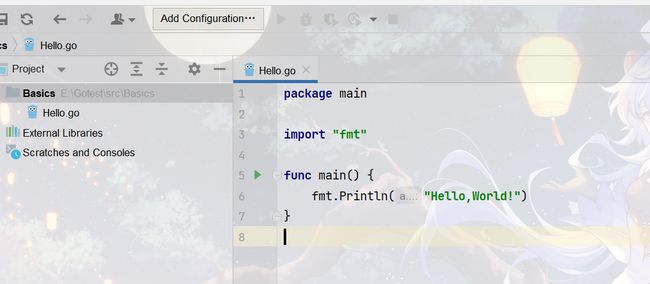

在Go语言里,命名为main 的包具有特殊的含义。Go语言的编译程序会试图把这种名字的包编译为二进制可执行文件。所有用Go语言编译的可执行程序都必须有一个名叫main的包。一个可执行程序有且仅有一个main包。
6、基础语法
6.1、注释
package main
import "fmt"
// 我是单行注释
/*
我是多行注释
这是main函数,是程序的入口
*/
func main() {
fmt.Println("Hello,World!")
}
6.2、变量
package main
import "fmt"
func main() {
//name就是变量
var name string = "kuangshen"
name = "zhangsan"
fmt.Println(name)
}
6.3、变量的定义
Go语言是静态类型语言,就是所有的类型我们都需要明确的去定义
我们声明一个变量一般是使用var关键字
var name type
- 第一个var是声明变量的关键字,是固定的写法,大家记住即可
- 第二个name,就是我们变量的名字,你可以按照自己的需求给它定一个名字
- 第三个type,就是用来代表变量的类型
//定义一个字符串变量 name
var name String
//定义一个数字类型变量 int
var age int
批量定义变量
package main
import "fmt"
func main() {
var (
name string
age int
addr string
)
fmt.Println(name, age, addr)
}

如果没有显式的给变量赋值,系统自动赋予它该类型的默认值
- 整形和浮点型变量的默认值为0和0.0
- 字符串变量的默认值为空字符串
- 布尔型变量默认为false
- 切片、函数、指针变量的默认为nil
6.4、变量初始化
变量初始化的标准格式
// = 是赋值,将右边的值赋给左边的变量
var name string = "ss"
短变量声明并初始化
package main
import "fmt"
func main() {
name := "kuangshen"
age := 3
fmt.Printf("name:%s,age:%d",name,age)
}
这是Go语言的推导声明写法,编译器会自动根据右值的类型推断出左值的类型
因为简洁和灵活的特点,简短变量声明被广泛用于大部分的局部变量的声明和初始化
注意:
由于使用了 := ,而不是赋值的 = ,因此推导声明写法的左值**必须是没有被定义**过的,若定义过,将会发生编译错误
打印变量类型
fmt.Printf("%T,%T", name, age)
// string,int
6.5、打印内存地址
func main() {
var num int = 5
fmt.Printf("num:%d的内存地址为:%p\n", num, &num)
num = 100
fmt.Printf("num:%d的内存地址为:%p\n", num, &num)
}
/*
num:5的内存地址为:0xc0000a6058
num:100的内存地址为:0xc0000a6058
*/
6.6、变量交换
func main() {
/*
传统交换
a = 100;
b = 200
temp = 0;
temp = a;
a = b;
b = temp;
*/
var a int = 100
var b int = 200
b, a = a, b
fmt.Println(a, b)
}
/*
200 100
*/
6.7、匿名变量
匿名变量的特点是一个下画线"__",本身就是一个特殊的标识符,被称为空白标识符。它可以像其他标识符那样用于变量的声明或赋值(任何类型都可以赋值给它),但任何赋给这个标识符的值都将被抛弃,因此这些值不能在后续的代码中使用,也不可以使用这
个标识符作为变量对其它变量进行赋值或运算。使用匿名变量时,只需要在变量声明的地方使用下画线替换即可。
func main() {
a, _ := test()
fmt.Println(a)
}
func test() (int, int) {
return 100, 200
}
假如在未来我们需要接收一个对象的某个属性,其他属性就使用匿名变量接收。
匿名变量不占用内存空间,不会分配内存,且匿名变量与匿名变量之间也不会因为多次声明而无法使用。
6.8、变量的作用域
一个变量(常量、类型或函数)在程序中都要一定的作用范围,称之为作用域。
了解变量的作用域对我们学习Go语言来说是比较重要的,因为Go语言会在编译时检查每个变量是否使用过,一旦出现未使用的变量,就会报编译错误。如果不能理解变量的作用域,就有可能会带来一些不明所以的编译错误。
局部变量
在函数体内声明的变量称为局部变量,作用域只在函数体内。
func main() {
// a就是局部变量
a, _ := test()
fmt.Println(a)
}
全局变量
在函数体外声明的变量称之为全局变量,全局变量只需要在一个源文件中定义,就可以在所有源文件中使用,当然,不包含这个全局变量的源文件需要使用"import"关键字引入全局变量所在的源文件之后才能使用这个全局变量。
全局变量声明必须以var 关键字开头,如果想要在外部包中使用全局变量的首字母必须大写。
var name string = "s"
func main() {
var name string = "a"
fmt.Println(name)
}
/*
a //就近原则
*/
6.9、常量
在Go语言中,我们使用**const**关键字来定义常量,常量的值不允许改变,一般用大写表示。
func main() {
const URL string = "192.168.1.1" //显式定义
const URL2 = "192.168.1.1" //隐式定义
const a, b, c = 3.14, "www.baidu.com", true //同时定义
fmt.Println(a, b, c)
}
iota,特殊常量,可以认为是一个可以被编译器修改的常量。iota是go语言的常量计数器
iota在const关键字出现时将被重置为0(const内部的第一行之前),const 中每新增一行常量声明将使iota计数一次(iota可理解为const语句块中的行索引)。
iota可以被用作枚举值:
func main() {
const (
a = iota
b = iota
c = iota
)
fmt.Println(a, b, c)
}
/*
0 1 2
*/
只要在同一组里,iota的值都会从0开始增加。
func main() {
const (
a = iota
b
c
d = "haha"
e
f = 100
g
h = iota
i
)
const (
j = iota
k
)
fmt.Println(a, b, c, d, e, f, g, h, i)
}
/*
0 1 2 haha haha 100 100 7 8 0 1
*/
7、基本数据类型
Go语言是一种静态类型的编程语言,在Go编程语言中,数据类型用于声明函数和变量。数据类型的出现是为了把数据分成所需内存大小不同的数据,编程的时候需要用大数据的时候才需要申请大内存,就可以充分利用内存。编译器在进行编译的时候,就要知道每个值的类型,这样编译器就知道要为这个值分配多少内存,并且知道这段分配的内存表示什么。
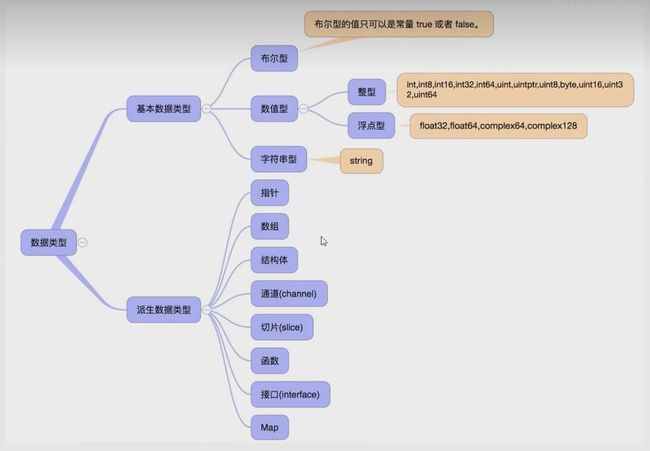
7.1、布尔型
布尔型的值只可以是常量true或者false。
默认值是false。
func main() {
var b1 bool
var b2 bool
b1 = true
b2 = false
fmt.Printf("%T,%t\n", b1, b1)
fmt.Printf("%T,%t\n", b2, b2)
}
/*
bool,true
bool,false
*/
7.2、数字类型
整型int和浮点型float32、float64,Go语言支持整型和浮点型数字,并且支持复数,其中位的运算采用补码。
Go也有基于架构的类型,例如:unit无符号、int有符号
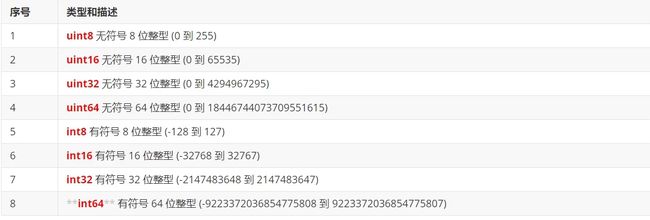
func main() {
var i1 int8
var i2 uint8
i1, i2 = 100, 200
fmt.Println(i1)
fmt.Println(i2)
}
浮点型,Go语言中默认是float64

func main() {
var money float64 = 3.14
fmt.Printf("%T,%f\n", money, money) //默认6位小数打印,四舍五入
}
常见的别名

7.3、字符与字符串
字符与字符串
func main() {
var str string
str = "Hello,Go"
fmt.Printf("%T,%s\n", str, str)
v1 := 'A'
v2 := "A"
fmt.Printf("%T,%s\n", v1, v1)
fmt.Printf("%T,%s\n", v2, v2)
}
/*
string,Hello,Go
int32,%!s(int32=65) //可以看到单引号定义的变量实际是int32类型,实际上打印的是对应ASCII表中的十进制值
string,A
*/
部分用法
func main() {
// 拼接
fmt.Printf("aaa" + "bbb\n")
// 转义
fmt.Printf("hello\"bbb\n")
// 换行
fmt.Printf("hello\nbbb")
// Tab
fmt.Printf("hello\tbbb")
}
/*
aaabbb
hello"bbb
hello
bbb
hello bbb
*/
7.4、数据类型的转换
在必要以及可行的情况下,一个类型的值可以被转换成另一种类型的值。由于Go语言不存在隐式类型转换,因此所有的类型转换都必须显式的声明。
类型B的值 = 类型B(类型A的值)
func main() {
a := 3.14
b := int(a)
fmt.Println(a)
fmt.Println(b)
}
/*
3.14
3 //直接舍去小数
*/
尽量小转大,因为大转小会造成精度丢失。
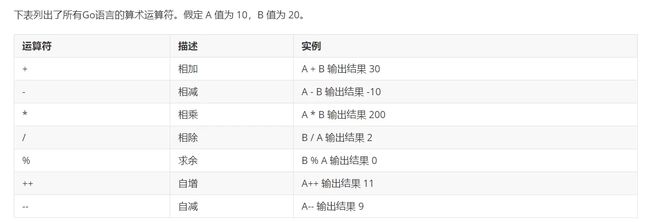
8、运算符
8.1、算数运算符
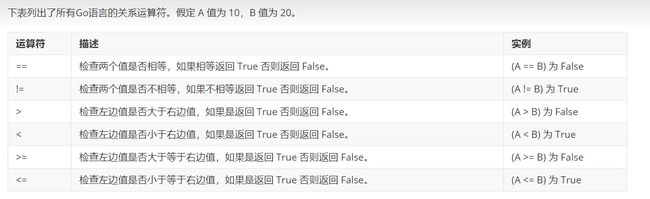
8.2、关系运算符
8.3、逻辑运算符

8.4、位运算符
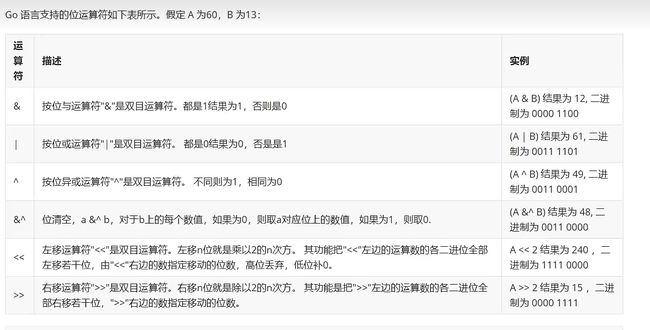
8.5、赋值运算符
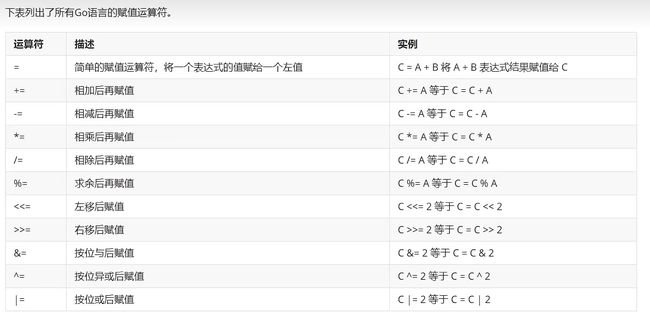
这里其实学过其他语言的话对这些运算符应该都认识,如果学过C语言,其实Go语言的很多格式和C是一样的。
9、流程控制
9.1、if语句
进行一次判断,根据判断的结果执行不同的代码段。
/*
if 判断条件 { //判断条件的括号可加可不加
满足条件执行的代码
} else {
不满足执行的代码
}
*/
package main
import "fmt"
func main() {
score := 90
name := "zhuwenjie"
// 测试1
if score >= 90 && score <= 100 {
fmt.Println("A")
} else if score >= 80 && score < 90 {
fmt.Println("B")
} else if score >= 70 && score < 80 {
fmt.Println("C")
} else if score >= 60 && score < 70 {
fmt.Println("D")
} else {
fmt.Println("不及格")
}
fmt.Println()
// 嵌套if
if score >= 90 {
if name == "zhuwenjie" {
fmt.Println("正确")
} else {
fmt.Println("姓名不正确")
}
} else {
fmt.Println("成绩不正确")
}
}
9.2、switch和fallthrough
switch语句用于基于不同条件执行不同动作,每一个case分支都是唯一的,从上至下逐一测试,直到匹配为止。
package main
import "fmt"
func main() {
score := 90
switch score {
case 90:
fmt.Println("A")
fallthrough // fallthrough 会无视下一个case的条件,直接执行
case 80:
fmt.Println("B")
case 60,70:
fmt.Println("B")
default:
fmt.Println("D)
}
}
/*
A
B
*/
switch语句的执行从上至下,直到找到匹配项,找到之后也不需要再加break,switch默认情况下case最后自带break语句。
9.3、for语句
for循环是一个循环控制结构,可以执行指定次数的循环。
package main
import "fmt"
func main() {
for i := 1; i <= 9; i++ { //打印99乘法表
for j := 1; j <= i; j++ {
fmt.Printf("%d*%d=%d\t", j, i, j*i)
}
fmt.Println()
}
}
9.4、break与continue
break 结束当前整个循环
package main
import "fmt"
func main() {
for i := 1; i <= 10; i++ {
if i == 5 {
break
}
fmt.Println(i)
}
}
/*
1
2
3
4
*/
continue 结束本次循环
package main
import "fmt"
func main() {
for i := 1; i <= 10; i++ {
if i == 5 {
continue
}
fmt.Println(i)
}
}
/*
1
2
3
4
6
7
8
9
10
*/
9.5、遍历字符串
package main
import "fmt"
func main() {
score := 90
name := "zhuwenjie"
println(len(name)) // len(str) 获得字符串的长度
fmt.Printf("%c,%d\n", name[1], name[1])
for i := 0; i < len(name); i++ {
fmt.Printf("%c,%d\n", name[i], name[i])
}
// i是下标,v是对应元素
for i, v := range name { // for i, v := range name 其中i是下标,v是该下标对应的值
fmt.Printf("%d,%c,%d\n", i, v, v)
}
}
10、函数
什么是函数
- 函数是基本的代码块,用于执行一个任务
- Go程序至少要有一个main函数
- 通过函数来划分功能,逻辑上每个函数执行指定的任务
- 函数声明告诉了编译器函数的名称、返回类型和参数
10.1、函数的声明
Go语言中函数定义格式如下:
func function_name( [parameter list] ) [return_types] {
函数体
}
- 无参无返回值函数
package main
func main() {
printInfo()
}
func printInfo() {
println("我执行了printInfo函数")
}
- 有一个参数的函数
package main
func main() {
printInfo(5)
}
func printInfo(a int) {
println(a)
}
- 有两个参数的函数
package main
func main() {
println(add(1, 2))
}
func add(a int, b int) int {
c := a + b
return c
}
- 有一个返回值的函数
package main
func main() {
println(add(1, 2))
}
func add(a int, b int) int {
c := a + b
return c
}
- 有多个返回值的函数
package main
func main() {
add, del := addAndDel(1, 2)
println(add, del)
}
func addAndDel(a int, b int) (int, int) {
c := a + b
d := a - b
return c, d
}
10.2、形参和实参
package main
func main() {
// 形参与实参要一一对应,包括类型和顺序
add, del := addAndDel(1, 2)
println(add, del)
}
// addAndDel 计算两个数相加和相减的结果
// 形式参数: a b 定义函数时,用来接收外部传入数据的参数
// 实际参数: 1 2 调用函数时,传给形参的实际数据
func addAndDel(a int, b int) (int, int) {
c := a + b
d := a - b
//一个函数在定义时如果有返回值,那么函数中必须使用return语句
return c, d
}
10.3、可变参数
概念:一个参数的参数类型确定,但个数不确定,就可以使用可变参数。
func myfunc(arg ...int){}
// arg ...int 告诉编译器这个函数接收不定数量的参数,类型全是int
package main
func main() {
println(getSum(1, 3, 5, 7, 9))
}
func getSum(nums ...int) int {
sum := 0
for _, num := range nums {
sum += num
}
return sum
}
注意事项:
- 如果一个函数的参数是可变参数,同时还有其他参数,可变参数要放在参数列表的最后
- 一个函数的参数列表中最多只能有一个可变参数
10.4、参数传递
按照数据的存储特点来分:
- 值类型的数据:操作的是数据本身,基础数据类型、array、struct…
- 引用类型的数据:操作的是数据的地址,slice、map、chan…
10.4.1、值传递
package main
import "fmt"
func main() {
//值传递
arr := [4]int{1, 2, 3, 4}
fmt.Println(arr)
update(arr, 1, 100)
fmt.Println(arr)
}
// 更改数组中某个元素的值
func update(arr [4]int, j int, target int) {
arr[j] = target
fmt.Println(arr)
}
/*
[1 2 3 4] //未修改前数组的值
[1 100 3 4] //update方法里修改后的值
[1 2 3 4] //修改后数组的值
*/
这里学过C的话其实很容易明白,C语言里本身就有值传递和引用传递,程序会为每一个函数开辟一个空间,因此如果是值传递的类型,在这个函数里改变的其实是原来数据的拷贝,因此对原来的数据并没有造成影响。
10.4.2、引用传递
package main
import "fmt"
func main() {
//引用传递
arr := []int{1, 2, 3, 4}
fmt.Println(arr)
update(arr, 1, 100)
fmt.Println(arr)
}
// 更改切片中某个元素的值
func update(arr []int, j int, target int) {
arr[j] = target
fmt.Println(arr)
}
/*
[1 2 3 4]
[1 100 3 4]
[1 100 3 4]
*/
可以看到函数里对于切片数据的更改也同步到了原切片上,对于引用数据类型来说,传递的其实是这个参数对应的地址,因此对这个参数的修改能同步到原函数里。
10.5、函数变量的作用域
主要分为全局变量和局部变量,使用时遵循就近原则。
- 定义在函数内的是局部变量
- 定义在函数外的是全局变量
10.6、递归函数
定义:一个函数自己调用自己,就叫做递归函数
注意:递归函数一定要有出口,否则会形成死循环
/*
以求1~5的和为例 getSum(i)
则getSum(5) = getSum(4) + 5
getSum(4) = getSum(3) + 4
getSum(3) = getSum(2) + 3
getSum(2) = getSum(1) + 2
getSum(1) = 1
*/
package main
func main() {
println(getSum(5))
}
func getSum(num int) int {
if num == 1 {
return 1
} else {
return getSum(num-1) + num
}
}
10.7、defer
defer语义:推迟、延迟
在Go语言中,使用defer关键字来延迟一个函数或者方法的执行。
package main
import "fmt"
func main() {
f("1")
fmt.Println("2")
defer f("3")
fmt.Println("4")
}
func f(s string) {
fmt.Println(s)
}
/*
1
2
4
3
*/
defer函数或方法:该函数或方法的执行被延迟
- 如果一个函数中添加了多个defer语句,当函数执行到最后时,这些defer语句会按照逆序执行,最后该函数返回。特别是当进行一些打开资源的操作时,遇到错误需要提前返回,在返回前需要关闭相应的资源,不然容易造成资源泄露问题。
- 如果有很多调用defer,那么defer用的是后进先出(栈)模式。
package main
import "fmt"
func main() {
f("1")
defer f("2")
defer f("3")
fmt.Println("4")
}
func f(s string) {
fmt.Println(s)
}
/*
1
4
3
2
*/
需要注意的是,在执行到defer语句的时候,函数里的形参就已经传递进去了,只是函数被延迟执行了。
package main
import "fmt"
func main() {
a := 10
fmt.Println("begin a=", a)
defer f(a)
a++
fmt.Println("end a=", a)
}
func f(s int) {
fmt.Println(s)
}
/*
begin a= 10
end a= 11
10
*/
常用场景:
-
对象.close() 临时文件的删除
-
- 文件.open
- defer 文件.close
- 对文件进行操作
-
Go语言中关于异常的处理,使用panic()和recover()
-
- panic 函数用于引发恐慌,导致函数中断执行
- recover 函数用于恢复程序的执行,recover() 语法上要求必须在 defer 中执行
10.8、函数本质的探究
函数本身也是有数据类型的,func()
package main
import "fmt"
func main() {
fmt.Printf("%T", fs) // func()
}
func fs() {
}
既然函数本身有数据类型,那么它就可以作为变量,可以赋值。
package main
import "fmt"
func main() {
fmt.Printf("%T\n", fs)
//定义函数类型的变量
var ff func(int, int) = fs
ff(1, 2)
//看看ff和fs是否相同
fmt.Println(ff)
fmt.Println(fs)
}
func fs(a int, b int) {
fmt.Println(a + b)
}
/*
func(int, int)
3
0x107fe40
0x107fe40
*/
函数在Go语言中是复合类型,可以看做是一种特殊的变量。
函数名 ():调用返回结果
函数名:指向函数体的内存地址,一种特殊类型的指针变量
10.9、匿名函数推导
package main
import "fmt"
func main() {
// 函数正常执行
f1()
// 匿名函数就是没有名字的函数
f2 := f1
f2()
// 匿名函数,函数体后增加一个()执行,通常只能执行一次
func() {
fmt.Println("我是一个匿名函数")
}()
// 将匿名函数赋值,单独进行调用
f3 := func() {
fmt.Println("我是一个匿名函数...")
}
f3()
// 定义带参数的匿名函数
func(a int, b int) {
fmt.Println(a, b)
}(1, 2)
// 定义带返回值的匿名函数
r1 := func(a int, b int) int {
return a + b
}(10, 20) //带了()就是函数调用
fmt.Println(r1)
}
func f1() {
fmt.Println("我是f1函数")
}
/*
我是f1函数
我是f1函数
我是一个匿名函数
我是一个匿名函数...
1 2
30
*/
Go语言是支持函数式编程:
- 将匿名函数作为另外一个函数的参数,回调函数
- 将匿名函数作为另外一个函数的返回值,可以形成闭包结构
10.10、回调函数
fun1(),fun2()
将fun1函数作为fun2函数的参数
fun2函数:叫做高阶函数,接收了一个函数作为参数
fun1函数:叫做回调函数,作为另外一个函数的参数
package main
import "fmt"
func main() {
// 正常执行
r1 := add(1, 2)
fmt.Println(r1)
// 封装
r2 := oper(3, 4, add) //加
fmt.Println(r2)
r3 := oper(8, 4, sub) //减
fmt.Println(r3)
r4 := oper(8, 4, func(i int, i2 int) int { //乘
return i * i2
})
fmt.Println(r4)
r5 := oper(8, 4, func(i int, i2 int) int { //除
if i2 == 0 {
fmt.Println("除数不能为0")
return 0
}
return i / i2
})
fmt.Println(r5)
}
// 高阶函数
func oper(a int, b int, fun func(int, int) int) int {
r := fun(a, b)
return r
}
func add(a int, b int) int {
return a + b
}
func sub(a int, b int) int {
return a - b
}
/*
3
7
4
32
2
*/
10.11、闭包的理解
package main
import "fmt"
/*
一个外层函数中,有内层函数,这个内层函数会操作外层函数的局部变量
且该外层函数的返回值就是该内层函数
这个内层函数和外层函数的局部变量,统称为闭包结构
此时局部变量的声明周期就会发生变化,正常的局部变量会随着函数的调用而创建,随着函数的结束而销毁
但是闭包中外层函数的局部变量并不会随着外层函数的结束而销毁,因为内层函数还在继续使用
*/
func main() {
r1 := increment()
fmt.Println(r1)
fmt.Println(r1())
v2 := r1()
fmt.Println(v2)
fmt.Println(r1())
fmt.Println(r1())
fmt.Println(r1())
r2 := increment()
fmt.Println(r2())
}
func increment() func() int {
// 局部变量i
i := 0
// 定义一个匿名函数,给变量自增并返回
fun := func() int {
i++
return i
}
return fun
}
/*
0x8ae800
1
2
3
4
5
1
*/