大数据基础入门 ------文章来源于:某个入门课程
文章目录
- 第一课:大数据基础入门
-
- 什么是大数据?
- java和大数据的关系
- 学习大数据需要的基础和路线
- 第二课:Hadoop的背景起源 一
-
- 分布式存储
- 如何解决大数据的存储?(HDFS)
- 第三课: hadoop的背景起源 二
-
- 一、什么是大数据,本质?
- 二、如何解决大数据的计算?分布式计算(MapReduce
- 第四课:Hadoop的背景起源三
-
- 第一节:关系型数据库的特点
- 第二节:什么是BigTable?(HBase)
- 第五课:MapReduce概述
-
- 第一节:MapReduce编程模型
- 第二节:WordCount的流程分析
-
- 1、伪分布环境运行WordCount
- 2、分析的数据流动的过程(重要): 运行原理和机制
- 第六课:Spark概述
-
- Spark基础
-
- 第一节:什么是Spark?Spark的特点和结构
- 第二节:搭建Spark的伪分布模式环境
- spark编程基础
- Hadoop生态
-
- 简介
- 参考链接
- Hive SQL
第一课:大数据基础入门
什么是大数据?
大量的数据
举例:
1、商品推荐: 问题:(1)大量的订单如何存储? (2)大量的订单如何计算?
2、天气预报: 问题:(1)大量的天气数据如何存储?(2)大量的天气数据如何计算?
大数据本质:存储和计算的问题
- 分布式文件系统(分布式存储)
- 分布式计算
java和大数据的关系
- hadoop :基于Java语言开发
- spark: 基于Scala语言,Scala基于Java语言
学习大数据需要的基础和路线
Java基础(JavaSE)—> 类、继承、I/O、反射、泛型*****
Linux基础(Linux的操作) —> 创建文件、目录、vi编辑器***
注意:不需要java EE哦
2、学习路线:
(1)Java基础和Linux基础
(2)Hadoop的学习:体系结构、原理、编程
第一阶段:HDFS、MapReduce、HBase(NoSQL数据库)
第二阶段:数据分析引擎 —> Hive、Pig
数据采集引擎 —> Sqoop、Flume
第三阶段:HUE:Web管理工具
ZooKeeper:实现Hadoop的HA(好可用性)
Oozie: 工作流引擎
(3)Spark的学习
()第一个阶段:Scala编程语言
()第二个阶段:Spark Core-----> 基于内存,数据的计算
()第三个阶段:Spark SQL -----> 类似Oracle中的SQL语句
()第四个阶段:Spark Streaming —> 进行实时计算(流式计算):比如:自来水厂
(4)Apache Storm:类似Spark Streaming —> 进行实时计算(流式计算):比如:自来水厂
(*)NoSQL:Redis基于内存的数据库
第二课:Hadoop的背景起源 一
分布式存储
HDFS(Hadoop Distributed File System)来源于 GFS(Google File System)
如何解决大数据的存储?(HDFS)
分布式文件系统(HDFS,来源于GFS)
举例:
10G数据要保存到6G硬盘上
问题:
-
硬盘不够大
- 多几块硬盘
- 理论上:无穷大
-
数据不够安全
- 冗余度
- HDFS默认冗余度:3
- 解决上传多份所产生的效率问题:采用水平复制。上传完后服务器端进行水平复制
- 传输按照数据块为单位:hadoop2.x:128M

-
Hadoop的安装模式
- 本地模式 :1台
- 伪分布模式:1台 (要配置ssh免密登陆,生成秘钥对儿,并且将公钥放到本地。打开配置文件的登陆开关)
- 全分布模式:3台 一台namenode 两台datanode
第三课: hadoop的背景起源 二
一、什么是大数据,本质?
(1)数据的存储:分布式文件系统(分布式存储)-----> HDFS: Hadoop Distributed File System
(2)数据的计算:分布式计算
二、如何解决大数据的计算?分布式计算(MapReduce
(1)什么是PageRank(MapReduce的问题的来源)
() 搜索排名
(2)MapReduce(Java语言实现)基础编程模型: 把一个大任务拆分成小任务,再进行汇总
() 更简单一点例子
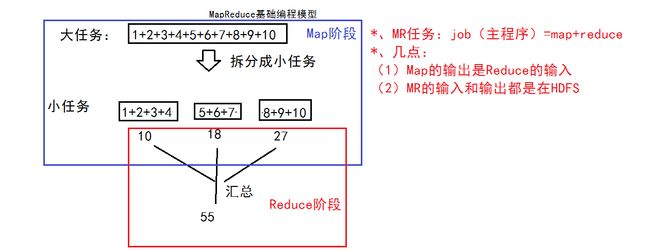
用java实现MapReduce模型
HDFS->Map->Reduce->HDFS
第四课:Hadoop的背景起源三
BigTable ----> 大表 ----> NoSQL数据库:HBase
第一节:关系型数据库的特点
1、什么是关系型数据库?基于关系模型(基于二维表)所提出的一种数据库。
例如(Oracle、MySQL、SQL Server)
2、ER(Entity-Relationalship)模型:通过增加外键来减少数据的冗余
3、举例:学生-系
第二节:什么是BigTable?(HBase)
: 把所有的数据保存到一张表中,采用冗余 —> 好处:提高效率
1、因为有了bigtable的思想:NoSQL:HBase数据库
2、HBase基于Hadoop的HDFS的
3、描述HBase的表结构

今天任务:研究zookeeper 和 大数据面试问题!!! 别看无谓的东西了
第五课:MapReduce概述
第一节:MapReduce编程模型
map reduce,
见hadoop起源
第二节:WordCount的流程分析
1、伪分布环境运行WordCount
hadoop jar hadoop-mapreduce-examples-2.4.1.jar wordcount /data/input/data.txt /data/output/wc
输入 -> 输出
2、分析的数据流动的过程(重要): 运行原理和机制

k1 v1 偏移量数据
k2 v2 k3 v3 相同类型
k4 v4 汇总
输出到HDFS
第六课:Spark概述
Spark基础
第一节:什么是Spark?Spark的特点和结构
1、什么是Spark?
Spark是一个针对大规模数据处理的快速通用引擎。
类似MapReduce,都进行数据的处理
2、Spark的特点:
(1)基于Scala语言、Spark基于内存的计算
(2)快:基于内存
(3)易用:支持Scala、Java、Python
(4)通用:Spark Core、Spark SQL、Spark Streaming
MLlib、Graphx (框架)
(5)兼容性:完全兼容Hadoop
3、Spark体系结构:主从结构
(1)主节点:Master
(2)从节点:Worker
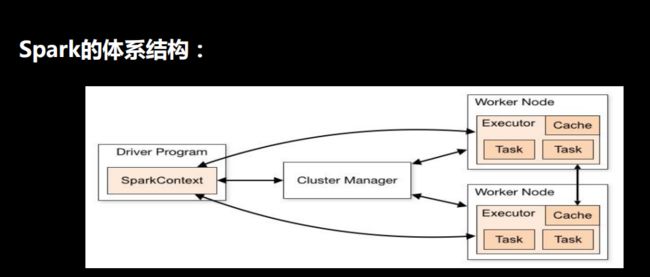
左侧是客户端,右侧是服务器端
cluster是master节点
第二节:搭建Spark的伪分布模式环境
1、解压:tar -zxvf spark-2.1.0-bin-hadoop2.4.tgz -C ~/training/
2、配置参数文件: conf/spark-env.sh
export JAVA_ HOME=/usr/lib/jvm/java-8-openjdk-amd64/jre
export SPARK_MASTER_HOST=DESKTOP-EMFKL37
export SPARK_MASTER_PORT=7077
conf/slaves ----> 从节点的主机信息
bigdata11
3、启动Spark伪分布环境
sbin/start-all.sh
Spark Web Console: http://192.168.88.11:8080
spark编程基础
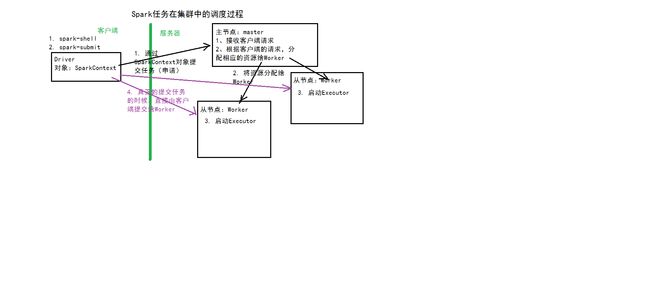
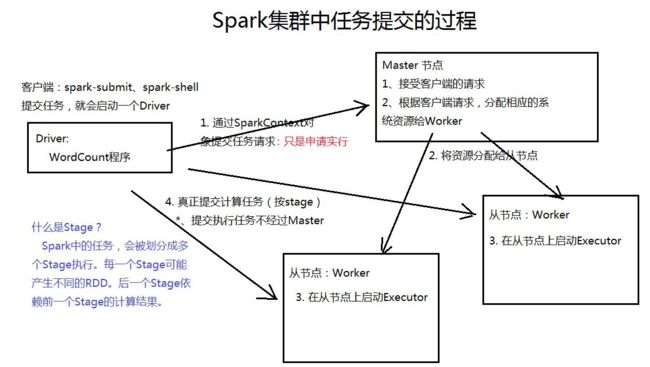
Hadoop生态
简介
通常情况下,Hadoop应用于分布式环境。就像之前Linux的状况一样,厂商集成和测试Apache Hadoop生态系统的组件,并添加自己的工具和管理功能。
HDFS –
Hadoop分布式文件系统,GFS的Java开源实现,运行于大型商用机器集群,可实现分布式存储。
MapReduce–
一种并行计算框架,Google MapReduce模型的Java开源实现,基于其写出来的应用程序能够运行在由上千个商用机器组成的大型集群上,并以一种可靠容错的方式并行处理T级别及以上的数据集。
Zookeeper –
分布式协调系统,Google Chubby的Java开源实现,是高可用的和可靠的分布式协同(coordination)系统,提供分布式锁之类的基本服务,用于构建分布式应用。
Hbase –
基于Hadoop的分布式数据库,Google BigTable的开源实现,是一个有序、稀疏、多维度的映射表,有良好的伸缩性和高可用性,用来将数据存储到各个计算节点上。
Hive 一一
是为提供简单的数据操作而设计的分布式数据仓库,它提供了简单的类似SQL语法的HiveQL语言进行数据查询。
Cloudbase 一一
基于Hadoop的数据仓库,支持标准的SQL语法进行数据查询。
Pig 一一
大数据流处理系统。建立于Hadoop之上为并行计算环境提供了一套数据工作流语言和执行框架。
Mahout 一一
基于HadoopMapReduce的大规模数据挖掘与机器学习算法库。
Oozie 一一
MapReduce工作流管理系统。
Sqoop —一 数据转移系统,是一个用来将Hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库中的数据导入Hadoop的HDFS中、也可以将HDFS的数据导入关系型数据库中。
Flume 一一 一个可用的、可靠的、分布式的海量日志采集、聚合和传输系统。
Scribe 一一 Facebook开源的日志收集聚合框架系统。
参考链接
hadoop生态系统的详细介绍-详细一点
https://blog.csdn.net/wdr2003/article/details/79692886
HBase 和 Hive 的差别是什么,各自适用在什么场景中?
https://www.zhihu.com/question/21677041/answer/185664626
如何用形象的比喻描述大数据的技术生态?Hadoop、Hive、Spark 之间是什么关系?
https://www.zhihu.com/question/27974418/answer/156227565
Hadoop学习路线图
http://blog.fens.me/hadoop-family-roadmap/
Hive SQL
Hive SQL教程
谓词下推
结论:
所谓下推,即谓词过滤在map端执行;所谓不下推,即谓词过滤在reduce端执行
inner join时,谓词任意放都会下推
left join时,左表的谓词应该写在where后,右表的谓词应写在后
right join时,左表的谓词应该写在join后,右表的谓词应写在where后
————————————————
版权声明:本文为CSDN博主「迷路剑客」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/baichoufei90/article/details/85264100