【FLink-2-Flink算子-SourceOperator】
FLink-2-Flink算子-SourceOperator
- SourceOperator
-
- 1.fromElements()
- 2.fromCollection()¶llelCollection()
- 3.readFile()&readTextFile()
- 4.KafkaSource(生成常用)
- 5.自定义Source
SourceOperator
Flink的Source算子和Sink算子,核心包中包含的种类很少,基本上都是需要去引入各种connector插件来获得。
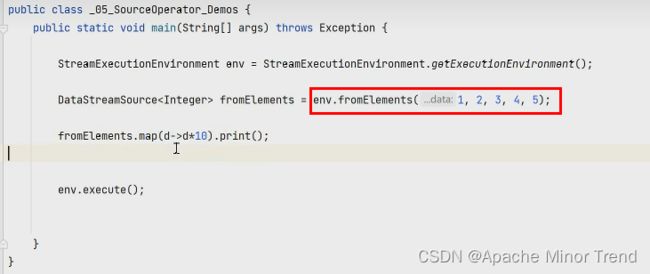
1.fromElements()
2.fromCollection()¶llelCollection()
fromCollection()方法返回的source算子是单并行度的算子
parallelCollection()方法返回的source算子是多并行度的算子

3.readFile()&readTextFile()

4.KafkaSource(生成常用)
- 老版本KafkaSource 相关代码如下
//设置 Kafka 相关参数
Properties properties = new Properties();
//设置 Kafka 的地址和端口
properties.setProperty("bootstrap.servers", "node-1.:9092,node-2:9092,node-3:9092");
//读取偏移量策略:如果没有记录偏移量,就从头读,如果记录过偏移量,就接着读
properties.setProperty("auto.offset.reset", "earliest");
//设置消费者组 ID
properties.setProperty("group.id", "g1");
//没有开启 checkpoint,让 flink 提交偏移量的消费者定期自动提交偏移量 properties.setProperty("enable.auto.commit", "true");
//创建 FlinkKafkaConsumer 并传入相关参数
FlinkKafkaConsumer<String> kafkaConsumer = new FlinkKafkaConsumer<>(
"test", //要读取数据的 Topic 名称
new SimpleStringSchema(), //读取文件的反序列化 Schema
properties //传入 Kafka 的参数
);
//使用 addSource 添加 kafkaConsumer
DataStreamSource<String> lines = env.addSource(kafkaConsumer);
注意:目前这种方式无法保证 Exactly Once,Flink 的 Source 消费完数据后,将偏移量定期的写入到 Kafka 的__consumer_offsets 中, 这种方式虽然可以记录偏移量,但是无法保证 Exactly Once;
- 新版本的KafkaSource 相关代码如下:
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.kafka.clients.consumer.OffsetResetStrategy;
public class Flink_Source_Demo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
/**
* 创建kafkaSource
*/
KafkaSource<String> kafkaSource = KafkaSource.<String>builder()
//设置订阅的主题
.setTopics("test01")
//设置消费者组id
.setGroupId("gp01")
//设置kafka服务器地址
.setBootstrapServers("hadoop102:9092")
//初始消费位置指定:
// OffsetsInitializer.committedOffsets(OffsetResetStrategy.LATEST) 消费起始位移选择之前所提交的偏移量(如果没有设置提交的偏移量,那么则读取参数里面这是的偏移量位置)
// OffsetsInitializer.earliest() 消费起始位移直接选择 “最早”
// OffsetsInitializer.latest() 消费起始位移直接选择 “最晚”
// OffsetsInitializer.offsets(Map) 消费起始位移选择为:方法传入的每个分区和对应的起始偏移量
.setStartingOffsets(OffsetsInitializer.committedOffsets(OffsetResetStrategy.LATEST))
// .setStartingOffsets(OffsetsInitializer.earliest())
// .setStartingOffsets(OffsetsInitializer.latest())
// .setStartingOffsets(OffsetsInitializer.offsets(Map))
//设置value数据的反序列化器
.setValueOnlyDeserializer(new SimpleStringSchema())
//开启kafka底层消费者的自动位移提交机制
// 它会把最新的消费位移提交到kafka的consumer_offsets中
// 就算把自动位移提交机制开启,KafkaSource依然不依赖自动位移提交机制
// (宕机重启时,优先从flink自己的状态中去获取偏移量<更可靠>)
.setProperty("auto.offset.commit","true")
//把本source算子设置为 Bounded属性(有界流)
// 将来 本source去读取数据的时候,读到指定的位置,就停止读取并退出
// 主要应用场景:常用于补数或重跑某一段历史数据
// .setBounded(OffsetsInitializer.committedOffsets())
//把本source算子设置为 Unbounded属性(无界流)
// 但是并不会一直读数据,而是到达指定位置就停止读取,但程序不退出
// 主要应用场景:需要从kafka中读取某一段固定长度的数据,然后拿着这段数据去跟另外一个真正的无界流联合处理
// .setUnbounded(OffsetsInitializer.committedOffsets())
.build();
DataStreamSource<String> kafkaDS = env.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(), "kafka-source");
kafkaDS.print();
env.execute();
}
}
新版kafka偏移量的提交方式,会将偏移量保存在自己的算子中,宕机重启的时候,优先从flink的算子中获取偏移量。
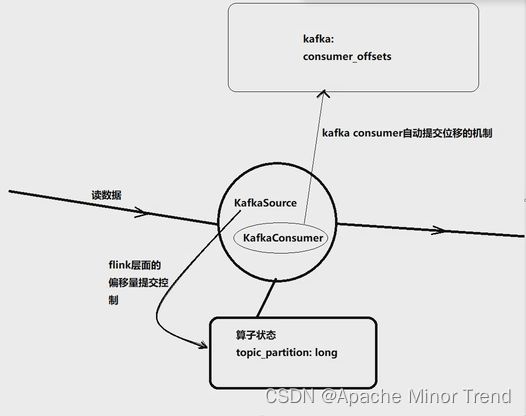
新版本 API 中,flink 会把 kafka 消费者的消费位移记录在算子状态中,这样就实现了消费位移状态的容错,从而可以支持端到端的 exactly-once;
5.自定义Source
自定义source
可以实现 SourceFunction 或者继承 RichSourceFunction,这两者都是非并行的source算子
也可实现 ParallelSourceFunction 或者继承 RichParallelSourceFunction,这两者都是可并行的source算子
– 带Rich的,都拥有open(),close(),getRuntimeContext()方法
– 带Parallel的,都可多实例并行执行。
具体代码案例如下:
import com.alibaba.fastjson.JSON;
import lombok.*;
import org.apache.commons.lang3.RandomStringUtils;
import org.apache.commons.lang3.RandomUtils;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.ParallelSourceFunction;
import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction;
import org.apache.flink.streaming.api.functions.source.RichSourceFunction;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
/**
* 自定义source
*/
public class CustomSourceDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<EventLog> dataStreamSource = env.addSource(new MySourceFunction());
// dataStreamSource.map(value -> JSON.toJSONString(value)).print();//lambda表达式
dataStreamSource.map(JSON::toJSONString).print();//lambda表达式
env.execute();
}
}
class MySourceFunction implements SourceFunction<EventLog>{
volatile boolean flag = true;
@Override
public void run(SourceContext<EventLog> ctx) throws Exception {
EventLog eventLog = new EventLog();
String[] events = {"appLaunch","pageLoad","adShow","adClick","itemShare","itemCollect"};
while (flag){
eventLog.setGuid(RandomUtils.nextLong(1,1000));
eventLog.setSessionId(RandomStringUtils.randomAlphabetic(12).toUpperCase());
eventLog.setTimeStamp(System.currentTimeMillis());
eventLog.setEventId(events[RandomUtils.nextInt(0,events.length)]);
ctx.collect(eventLog);
Thread.sleep(RandomUtils.nextInt(500,1500));
}
}
@Override
public void cancel() {
flag=false;
}
}
class MyParallelFunction implements ParallelSourceFunction<EventLog>{
@Override
public void run(SourceContext<EventLog> ctx) throws Exception {
}
@Override
public void cancel() {
}
}
class MyRichSourceFunction extends RichSourceFunction<EventLog>{
volatile boolean flag = true;
/**
* source组件初始化
* @param parameters
* @throws Exception
*/
@Override
public void open(Configuration parameters) throws Exception {
//getRuntimeContext().getState()
}
/**
* source组件生成数据的过程(核心工作逻辑)
* @param ctx
* @throws Exception
*/
@Override
public void run(SourceContext<EventLog> ctx) throws Exception {
EventLog eventLog = new EventLog();
String[] events = {"appLaunch","pageLoad","adShow","adClick","itemShare","itemCollect"};
while (flag){
eventLog.setGuid(RandomUtils.nextLong(1,1000));
eventLog.setSessionId(RandomStringUtils.randomAlphabetic(12).toUpperCase());
eventLog.setTimeStamp(System.currentTimeMillis());
eventLog.setEventId(events[RandomUtils.nextInt(0,events.length)]);
ctx.collect(eventLog);
Thread.sleep(RandomUtils.nextInt(500,1500));
}
}
/**
* job取消调用的方法
*/
@Override
public void cancel() {
flag=false;
}
/**
* job结束调用方法
* @throws Exception
*/
@Override
public void close() throws Exception {
System.out.println("组件被关闭了。。。。。");
}
}
class MyRichParallelSourceFunction extends RichParallelSourceFunction<EventLog>{
@Override
public void open(Configuration parameters) throws Exception {
}
@Override
public void run(SourceContext<EventLog> ctx) throws Exception {
}
@Override
public void cancel() {
}
@Override
public void close() throws Exception {
}
}
@NoArgsConstructor
@AllArgsConstructor
@Getter
@Setter
@ToString
class EventLog{
private long guid;
private String sessionId;
private String eventId;
private long timeStamp;
}