Spark优化篇:数据倾斜解决
数据倾斜是指我们在并行进行数据处理的时候,由于数据散列引起Spark的单个Partition的分布不均,导致大量的数据集中分布到一台或者几台计算节点上,导致处理速度远低于平均计算速度,从而拖延导致整个计算过程过慢,影响整个计算性能。
数据倾斜带来的问题
单个或者多个Task长尾执行,拖延整个任务运行时间,导致整体耗时过大。单个Task处理数据过多,很容易导致OOM。
数据倾斜的产生原因
数据倾斜一般是发生在 shuffle 类的算子、SQL函数导致,具体如以下:
| 类型 | RDD | SQL |
|---|---|---|
| 去重 | distinct | distinct |
| 聚合 | groupByKey、reduceByKey、aggregateByKey | group by |
| 关联 | join、left join、right join | join、left join、right join |
通过Spark web ui event timeline观察明显长尾任务:
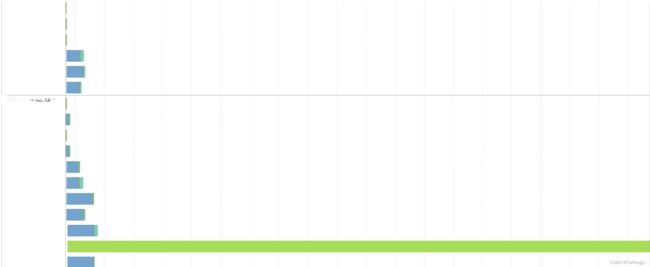

数据倾斜大Key定位
RDD进行抽取:
val cscTopKey: Array[(Int, Row)] = sampleSKew(sparkSession,"default.tab_spark","id")
println(cscTopKey.mkString("\n"))
def sampleSKew( sparkSession: SparkSession, tableName: String, keyColumn: String ): Array[(Int, Row)] = {
val df: DataFrame = sparkSession.sql("select " + keyColumn + " from " + tableName)
val top10Key: Array[(Int, Row)] = df
.select(keyColumn).sample(withReplacement = false, 0.1).rdd
.map(k => (k, 1)).reduceByKey(_ + _)
.map(k => (k._2, k._1)).sortByKey(ascending = false)
.take(10)
top10Key
} SQL进行抽取:
SELECT
id,conut(1) as cn
FROM
default.tab_spark_test_3
GROUP BY id
ORDER BY cn DESC
LIMIT 100;100000,2000012
100001,1600012
100002,1单表数据倾斜优化
为了减少 shuffle 数据量以及 reduce 端的压力,通常 Spark SQL 在 map 端会做一个partial aggregate(通常叫做预聚合或者偏聚合),即在 shuffle 前将同一分区内所属同 key 的记录先进行一个预结算,再将结果进行 shuffle,发送到 reduce 端做一个汇总,类似 MR 的提前Combiner,所以执行计划中 HashAggregate 通常成对出现。 但是这种也会出现问题,如果key重复的量级特别大,Combiner也是解决不了本质问题。
解决方案:
Add Salt局部聚合 2、Remove Salt全局聚合
sparkSession.udf.register("random_prefix", ( value: Int, num: Int ) => randomPrefixUDF(value, num))
sparkSession.udf.register("remove_random_prefix", ( value: String ) => removeRandomPrefixUDF(value))
//t1 增加前缀,t2按照加盐的key进行聚,t3去除加盐,聚合
val sql =
"""
|select
| id,
| sum(sell) totalSell
|from
| (
| select
| remove_random_prefix(random_id) id,
| sell
| from
| (
| select
| random_id,
| sum(pic) sell
| from
| (
| select
| random_prefix(id, 6) random_id,
| pic
| from
| default.tab_spark_test_3
| ) t1
| group by random_id
| ) t2
| ) t3
|group by
| id
""".stripMargin
def randomPrefixUDF( value: Int, num: Int ): String = {
new Random().nextInt(num).toString + "_" + value
}
def removeRandomPrefixUDF( value: String ): String = {
value.toString.split("_")(1)
} 表关联数据倾斜优化
1、适用场景
适用于 join 时出现数据倾斜。
2、解决逻辑
1、将存在倾斜的表,根据抽样结果,拆分为倾斜 key(skew 表)和没有倾斜 key(common)的两个数据集;
2、将 skew 表的 key 全部加上随机前缀,然后对另外一个不存在严重数据倾斜的数据集(old 表)整体与随机前缀集作笛卡尔乘积(即将数据量扩大 N 倍,得到 new 表)。
3、打散的 skew 表 join 扩容的 new 表
union common 表 join old 表
以下为打散大 key 和扩容小表的实现思路
1、打散大表:实际就是数据一进一出进行处理,对大 key 前拼上随机前缀实现打散;
2、扩容小表:实际就是将 DataFrame 中每一条数据,转成一个集合,并往这个集合里循环添加 10 条数据,最后使用 flatmap 压平此集合,达到扩容的效果。
/**
* 打散大表 扩容小表 解决数据倾斜
*
* @param sparkSession
*/
def scatterBigAndExpansionSmall(sparkSession: SparkSession): Unit = {
import sparkSession.implicits._
val saleCourse = sparkSession.sql("select *from sparktuning.sale_course")
val coursePay = sparkSession.sql("select * from sparktuning.course_pay")
.withColumnRenamed("discount", "pay_discount")
.withColumnRenamed("createtime", "pay_createtime")
val courseShoppingCart = sparkSession.sql("select * from sparktuning.course_shopping_cart")
.withColumnRenamed("discount", "cart_discount")
.withColumnRenamed("createtime", "cart_createtime")
// TODO 1、拆分 倾斜的key
val commonCourseShoppingCart: Dataset[Row] = courseShoppingCart.filter(item => item.getAs[Long]("courseid") != 101 && item.getAs[Long]("courseid") != 103)
val skewCourseShoppingCart: Dataset[Row] = courseShoppingCart.filter(item => item.getAs[Long]("courseid") == 101 || item.getAs[Long]("courseid") == 103)
//TODO 2、将倾斜的key打散 打散36份
val newCourseShoppingCart = skewCourseShoppingCart.mapPartitions((partitions: Iterator[Row]) => {
partitions.map(item => {
val courseid = item.getAs[Long]("courseid")
val randInt = Random.nextInt(36)
CourseShoppingCart(courseid, item.getAs[String]("orderid"),
item.getAs[String]("coursename"), item.getAs[String]("cart_discount"),
item.getAs[String]("sellmoney"), item.getAs[String]("cart_createtime"),
item.getAs[String]("dt"), item.getAs[String]("dn"), randInt + "_" + courseid)
})
})
//TODO 3、小表进行扩容 扩大36倍
val newSaleCourse = saleCourse.flatMap(item => {
val list = new ArrayBuffer[SaleCourse]()
val courseid = item.getAs[Long]("courseid")
val coursename = item.getAs[String]("coursename")
val status = item.getAs[String]("status")
val pointlistid = item.getAs[Long]("pointlistid")
val majorid = item.getAs[Long]("majorid")
val chapterid = item.getAs[Long]("chapterid")
val chaptername = item.getAs[String]("chaptername")
val edusubjectid = item.getAs[Long]("edusubjectid")
val edusubjectname = item.getAs[String]("edusubjectname")
val teacherid = item.getAs[Long]("teacherid")
val teachername = item.getAs[String]("teachername")
val coursemanager = item.getAs[String]("coursemanager")
val money = item.getAs[String]("money")
val dt = item.getAs[String]("dt")
val dn = item.getAs[String]("dn")
for (i <- 0 until 36) {
list.append(SaleCourse(courseid, coursename, status, pointlistid, majorid, chapterid, chaptername, edusubjectid,
edusubjectname, teacherid, teachername, coursemanager, money, dt, dn, i + "_" + courseid))
}
list
})
// TODO 4、倾斜的大key 与 扩容后的表 进行join
val df1: DataFrame = newSaleCourse
.join(newCourseShoppingCart.drop("courseid").drop("coursename"), Seq("rand_courseid", "dt", "dn"), "right")
.join(coursePay, Seq("orderid", "dt", "dn"), "left")
.select("courseid", "coursename", "status", "pointlistid", "majorid", "chapterid", "chaptername", "edusubjectid"
, "edusubjectname", "teacherid", "teachername", "coursemanager", "money", "orderid", "cart_discount", "sellmoney",
"cart_createtime", "pay_discount", "paymoney", "pay_createtime", "dt", "dn")
// TODO 5、没有倾斜大key的部分 与 原来的表 进行join
val df2: DataFrame = saleCourse
.join(commonCourseShoppingCart.drop("coursename"), Seq("courseid", "dt", "dn"), "right")
.join(coursePay, Seq("orderid", "dt", "dn"), "left")
.select("courseid", "coursename", "status", "pointlistid", "majorid", "chapterid", "chaptername", "edusubjectid"
, "edusubjectname", "teacherid", "teachername", "coursemanager", "money", "orderid", "cart_discount", "sellmoney",
"cart_createtime", "pay_discount", "paymoney", "pay_createtime", "dt", "dn")
// TODO 6、将 倾斜key join后的结果 与 普通key join后的结果,uinon起来
df1
.union(df2)
.write.mode(SaveMode.Overwrite).insertInto("sparktuning.salecourse_detail")
}