Datax使用篇
在说Datax前,先简单描述一下什么是ETL
ETL,是英文Extract-Transform-Load的缩写
在做数据的传输转换时,其中一种实现方案的选择是Datax
代码:https://github.com/alibaba/DataX
Datax是一款比较方便的数据同步工具,可以进行库库的同步
1. 安装部署
下载地址:http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
1.1. 下载datax.tar.gz
1.2. linux 下新建文件夹datax
1.3. 将datax.tar.gz上传至datax文件夹
1.4. 解压文件:tar -zxvf datax.tar.gz
1.5. datax默认支持的是python2;如果环境是python3的需要处理以下python版本
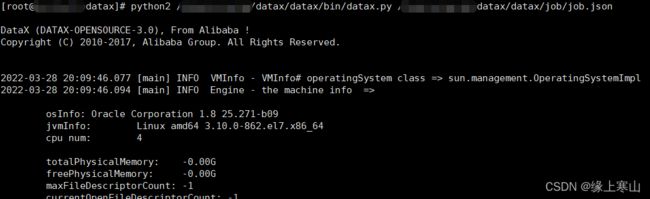
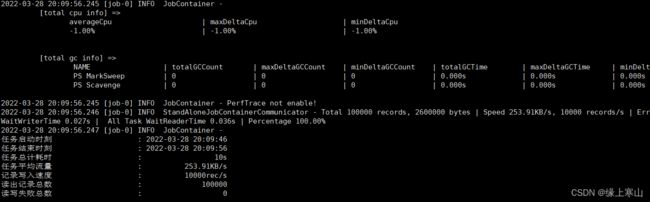
1.6. 解压后自检:python /[PATH]/datax/bin/datax.py /[PATH]/datax/job/job.json
出现下面的界面就表示安装成功
2. 使用
在Java中通过执行linux命令,来执行datax
Process proc = Runtime.getRuntime().exec(new String[]{"/bin/sh", "-c", "python /[PATH]/datax/bin/datax.py /[PATH]/datax/job/job.json"});其中命令后面可以夹参数 -p,例如传递数据库的地址用户名密码之类
看一个实际的例子
同步任务:test.job
{
"job": {
"content": [
{
"reader": {
"name": "reader",
"parameter": {
"username": "${readerdbname}",
"password": "${readerdbpassword}",
"connection": [
{
"table": [
"test_source"
],
"jdbcUrl": [
"${readerdburl}"
]
}
],
"column": [
"field"
]
}
},
"writer": {
"name": "writer",
"parameter": {
"username": "${writerdbname}",
"password": "${writerdbpassword}",
"connection": [
{
"table": [
"test_target"
],
"jdbcUrl": "${writerdburl}"
}
],
"column": [
"field"
],
"preSql": [
"truncate table test_target"
]
}
}
}
],
"setting": {
"speed": {
"channel": 1,
"byte": 104857600
},
"errorLimit": {
"record": 10,
"percentage": 0.05
}
}
}
}Process proc = Runtime.getRuntime().exec(new String[]{"/bin/sh", "-c", "python /[PATH]/datax/bin/datax.py /[PATH]/datax/job/test.job -p -Dreaderdburl=jdbc:oracle:thin:@127.0.0.1:1521/ORCL -Dreaderdbname=orcl -Dreaderdbpassword=orcl -Dwriterdburl=jdbc:oracle:thin:@127.0.0.1:1521/ORCL -Dwriterdbname=orcl -Dwriterdbpassword=orcl"});执行后test_source的数据就会同步至test_target中
3. 注意点
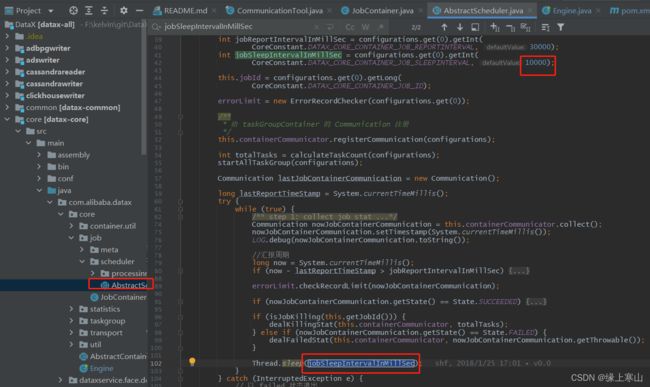
3.1. 同步时有的时候会很慢,有个参数需要进行配置
配置文件:datax/conf/core.json中
sleepInterval这个参数默认是没有的,默认值是10000,不改的话会很慢,可以把这个值调小,执行的间隔就会变短(不调整的话,及时任务只需要1ms,也得等10s才能结束)

Datax中的源码位置为
3.2. 如果java程序使用Jenkins方式启动,如果是非登陆模式启动,则会导致环境变量不生效,从而导致java、python等命令不生效,这个要注意,一旦出现,非常难排查,没有什么日志会提示此类错误
-- 有缘登山,寒山不寒