EXPLAIN四种输出格式&MySQL监控分析视图——sys schema
EXPLAIN四种输出格式
这里谈谈EXPLAIN的输出格式。EXPLAIN可以输出四种格式:传统格式,JSON格式,TREE格式以及可视化输出。用户可以根据需要选择适用于自己的格式。
EXPLAIN四种输出格式
传统格式
传统格式简单明了,输出是一个表格形式,概要说明查询计划。
EXPLAIN SELECT s1.key1, s2.key1 FROM s1 LEFT JOIN s2 ON s1.key1 = s2.key1 WHERE
s2.common_field IS NOT NULL;
JSON格式
第1种格式中介绍的EXPLAIN语句输出中缺少了一个衡量执行计划好坏的重要属性——成本。而JSON格式是四种格式里面输出信息最详尽的格式,里面包含了执行的成本信息。
- JSON格式:在EXPLAIN单词和真正的查询语句中间加上
FORMAT=JSON。
EXPLAIN FORMAT=JSON SELECT ....
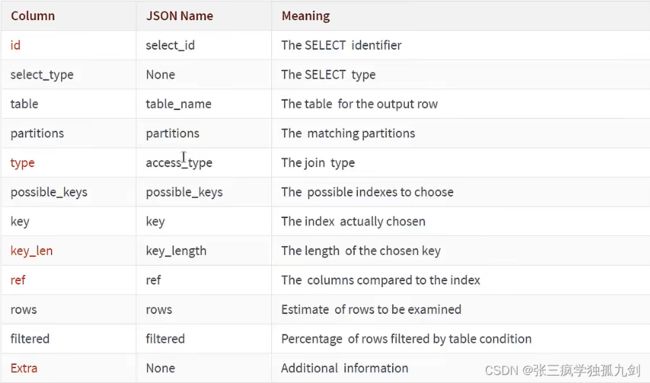
- EXPLAIN的Column与JSON的对应关系:(来源于MySQL 5.7文档)
这样我们就可以得到一个json格式的执行计划,里面包含该计划花费的成本,比如这样:
EXPLAIN FORMAT=JSON SELECT * FROM s1 INNER JOIN s2 ON s1.key1 = s2.key2 WHERE s1.common_field = 'a'\G
这种事JSON格式的
{
"query_block": {
"select_id": 1,
# 花费的成本信息
"cost_info": {
"query_cost": "2102.20"
},
"nested_loop": [
{
"table": {
"table_name": "s1",
"access_type": "ALL",
"possible_keys": [
"idx_key1"
],
"rows_examined_per_scan": 9895,
"rows_produced_per_join": 989,
"filtered": "10.00",
"cost_info": {
"read_cost": "914.80",
"eval_cost": "98.95",
"prefix_cost": "1013.75",
"data_read_per_join": "1M"
},
"used_columns": [
"id",
"key1",
"key2",
"key3",
"key_part1",
"key_part2",
"key_part3",
"common_field"
],
"attached_condition": "((`atguigudb1`.`s1`.`common_field` = 'a') and (`atguigudb1`.`s1`.`key1` is not null))"
}
},
{
"table": {
"table_name": "s2",
"access_type": "eq_ref",
"possible_keys": [
"idx_key2"
],
"key": "idx_key2",
"used_key_parts": [
"key2"
],
"key_length": "5",
"ref": [
"atguigudb1.s1.key1"
],
"rows_examined_per_scan": 1,
"rows_produced_per_join": 989,
"filtered": "100.00",
"index_condition": "(cast(`atguigudb1`.`s1`.`key1` as double) = cast(`atguigudb1`.`s2`.`key2` as double))",
"cost_info": {
# IO成本+检测的rows * (1 - filter)条记录的CPU的成本
"read_cost": "989.50",
"eval_cost": "98.95",
"prefix_cost": "2102.20",
"data_read_per_join": "1M"
},
"used_columns": [
"id",
"key1",
"key2",
"key3",
"key_part1",
"key_part2",
"key_part3",
"common_field"
]
}
}
]
}
}
read_cost是由下边这两部分组成的:IO成本- 检测
rows × (1 - filter)条记录的 CPU 成本
小贴士: rows和filter都是我们前边介绍执行计划的输出列,在JSON格式的执行计划中,rows
相当于rows_examined_per_scan,filtered名称不变。
eval_cost是这样计算的:
检测rows * filter条记录的成本。
prefix_cost就是单独查询s1表的成本,也就是:
read_cost + eval_cost
data_read_per -join表示在此次查询中需要读取的数据量。
对于s2表的cost_info部分是这样是:
"cost_info": {
"read_cost": "914.80",
"eval_cost": "98.95",
"prefix_cost": "1013.75",
"data_read_per_join": "1M"
},
由于s2表是被驱动表,所以可能被读取多次,这里的read_cost和eval_cost是访问多次s2表后累
加起来的值,大家主要关注里边儿的prefix_cost的值代表的是整个连接查询预计的成本,也就是单
次查询s1表和多次查询s2表后的成本的和,也就是:
968.80 + 193.76 + 2034.60 = 3197.16
TREE格式
TREE格式是8.0.16版本之后引入的新格式,主要根据查询的各个部分之间的关系和各部分的执行顺序来描述如何查询。
mysql> EXPLAIN FORMAT=TREE SELECT * FROM s1 INNER JOIN s2 ON s1.key1 = s2.key2 WHERE s1.common_field = 'a'\G
*************************** 1. row ***************************
EXPLAIN: -> Nested loop inner join (cost=2102.20 rows=990)
-> Filter: ((s1.common_field = 'a') and (s1.key1 is not null)) (cost=1013.75 rows=990)
-> Table scan on s1 (cost=1013.75 rows=9895)
-> Single-row index lookup on s2 using idx_key2 (key2=s1.key1), with index condition: (cast(s1.key1 as double) = cast(s2.key2 as double)) (cost=1.00 rows=1)
1 row in set, 1 warning (0.00 sec)
可视化输出
可视化输出,可以通过MySQL Workbench可视化查看MysQL的执行计划。通过点击Workbench的放大镜图标,即可生成可视化的查询计划。
show warnning
在我们使用EXPLAIN语句查看了某个查询的执行计划后,紧接着还可以使用SHOW WARNINGS语句查看与这个查询的执行计划有关的一些扩展信息,比如这样:
SHOW WARNINGS;

- 原来的SQL语句,本来是左外连接的,查询优化器帮我们改写成了内连接
EXPLAIN SELECT s1.key1, s2.key1 FROM s1 LEFT JOIN s2 ON s1.key1 = s2.key1 WHERE s2.common_field IS NOT NULL;
使用SHOW WARNINGS;查看查询优化器帮我们生成的SQL语句
+-------+------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Note | 1003 | /* select#1 */ select `atguigudb1`.`s1`.`key1` AS `key1`,`atguigudb1`.`s2`.`key1` AS `key1` from `atguigudb1`.`s1` join `atguigudb1`.`s2` where ((`atguigudb1`.`s1`.`key1` = `atguigudb1`.`s2`.`key1`) and (`atguigudb1`.`s2`.`common_field` is not null)) |
+-------+------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
- 原来的sql语句
EXPLAIN SELECT * FROM s1 WHERE key1 IN (SELECT key2 FROM s2 WHERE common_field = 'a');
使用SHOW WARNINGS;之后的查询优化器帮我们优化的SQL语句,帮我们把子查询转换成了连接查询
select `atguigudb1`.`s1`.`id` AS `id`,`atguigudb1`.`s1`.`key1` AS `key1`,`atguigudb1`.`s1`.`key2` AS `key2`,`atguigudb1`.`s1`.`key3` AS `key3`,`atguigudb1`.`s1`.`key_part1` AS `key_part1`,`atguigudb1`.`s1`.`key_part2` AS `key_part2`,`atguigudb1`.`s1`.`key_part3` AS `key_part3`,`atguigudb1`.`s1`.`common_field` AS `common_field` from `atguigudb1`.`s2` join `atguigudb1`.`s1` where ((`atguigudb1`.`s2`.`common_field` = 'a') and (cast(`atguigudb1`.`s1`.`key1` as double) = cast(`atguigudb1`.`s2`.`key2` as double)))
分析优化器执行计划:trace
OPTIMIZER_TRACE是MySQL 5.6引入的一项跟踪功能,它可以跟踪优化器做出的各种决策(比如访问表的方法、各种开销计算、各种转换等),并将跟踪结果记录到INFORMATION_SCHEMA.OPTIMIZER_TRACE表中。
此功能默认关闭。开启trace,并设置格式为JSON,同时设置trace最大能够使用的内存大小,避免解析过程中因为默认内存过小而不能够完整展示。
# 开启OPTIMIZER_TRACE功能
SET optimizer_trace="enabled=on",end_markers_in_json=on;
# 设置最大内存大小
set optimizer_trace_max_mem_size=1000000;
开启后,可分析如下语句:
- SELECT
- INSERT
- REPLACE
- UPDATE
- DELETE
- EXPLAIN
- SET
- DECLARE
- CASE
- IF
- RETURN
- CALL
测试:执行如下SQL语句
select * from student where id < 10;
最后, 查询 information_schema.optimizer_trace 就可以知道MySQL是如何执行SQL的 :
select * from information_schema.optimizer_trace\G
*************************** 1. row ***************************
//第1部分:查询语句
QUERY: select * from student where id < 10
//第2部分:QUERY字段对应语句的跟踪信息
TRACE: {
"steps": [
{
"join_preparation": { //预备工作
"select#": 1,
"steps": [
{
"expanded_query": "/* select#1 */ select `student`.`id` AS `id`,`student`.`stuno` AS `stuno`,`student`.`name` AS `name`,`student`.`age` AS `age`,`student`.`classId` AS `classId` from `student` where (`student`.`id` < 10)"
}
] /* steps */
} /* join_preparation */
},
{
"join_optimization": { //进行优化
"select#": 1,
"steps": [
{
"condition_processing": {
"condition": "WHERE",//条件处理
"original_condition": "(`student`.`id` < 10)",
"steps": [
{
"transformation": "equality_propagation",
"resulting_condition": "(`student`.`id` < 10)"
},
{
"transformation": "constant_propagation",
"resulting_condition": "(`student`.`id` < 10)"
},
{
"transformation": "trivial_condition_removal",
"resulting_condition": "(`student`.`id` < 10)"
}
] /* steps */
} /* condition_processing */
},
{
"substitute_generated_columns": { //替换生成的列
} /* substitute_generated_columns */
},
{
"table_dependencies": [ //表的依赖关系
{
"table": "`student`",
"row_may_be_null": false,
"map_bit": 0,
"depends_on_map_bits": [
] /* depends_on_map_bits */
}
] /* table_dependencies */
},
{
"ref_optimizer_key_uses": [ //使用键
] /* ref_optimizer_key_uses */
},
{
"rows_estimation": [ //行判断
{
"table": "`student`",
"range_analysis": {
"table_scan": {
"rows": 3759924,
"cost": 385340
} /* table_scan */, //扫描表
"potential_range_indexes": [ //潜在的范围索引
{
"index": "PRIMARY",
"usable": true,
"key_parts": [
"id"
] /* key_parts */
}
] /* potential_range_indexes */,
"setup_range_conditions": [ //设置范围条件
] /* setup_range_conditions */,
"group_index_range": {
"chosen": false,
"cause": "not_group_by_or_distinct"
} /* group_index_range */,
"skip_scan_range": {
"potential_skip_scan_indexes": [
{
"index": "PRIMARY",
"usable": false,
"cause": "query_references_nonkey_column"
}
] /* potential_skip_scan_indexes */
} /* skip_scan_range */,
"analyzing_range_alternatives": { //分析范围选项
"range_scan_alternatives": [
{
"index": "PRIMARY",
"ranges": [
"id < 10"
] /* ranges */,
"index_dives_for_eq_ranges": true,
"rowid_ordered": true,
"using_mrr": false,
"index_only": false,
"in_memory": 0.158185,
"rows": 9,
"cost": 1.80013,
"chosen": true
}
] /* range_scan_alternatives */,
"analyzing_roworder_intersect": {
"usable": false,
"cause": "too_few_roworder_scans"
} /* analyzing_roworder_intersect */
} /* analyzing_range_alternatives */,
"chosen_range_access_summary": { //选择范围访问摘要
"range_access_plan": {
"type": "range_scan",
"index": "PRIMARY",
"rows": 9,
"ranges": [
"id < 10"
] /* ranges */
} /* range_access_plan */,
"rows_for_plan": 9,
"cost_for_plan": 1.80013,
"chosen": true
} /* chosen_range_access_summary */
} /* range_analysis */
}
] /* rows_estimation */
},
{
"considered_execution_plans": [ //考虑执行计划
{
"plan_prefix": [
] /* plan_prefix */,
"table": "`student`",
"best_access_path": { //最佳访问路径
"considered_access_paths": [
{
"rows_to_scan": 9,
"access_type": "range",
"range_details": {
"used_index": "PRIMARY"
} /* range_details */,
"resulting_rows": 9,
"cost": 2.70013,
"chosen": true
}
] /* considered_access_paths */
} /* best_access_path */,
"condition_filtering_pct": 100, //行过滤百分比
"rows_for_plan": 9,
"cost_for_plan": 2.70013,
"chosen": true
}
] /* considered_execution_plans */
},
{
"attaching_conditions_to_tables": { //将条件附加到表上
"original_condition": "(`student`.`id` < 10)",
"attached_conditions_computation": [
] /* attached_conditions_computation */,
"attached_conditions_summary": [ //附加条件概要
{
"table": "`student`",
"attached": "(`student`.`id` < 10)"
}
] /* attached_conditions_summary */
} /* attaching_conditions_to_tables */
},
{
"finalizing_table_conditions": [
{
"table": "`student`",
"original_table_condition": "(`student`.`id` < 10)",
"final_table_condition ": "(`student`.`id` < 10)"
}
] /* finalizing_table_conditions */
},
{
"refine_plan": [ //精简计划
{
"table": "`student`"
}
] /* refine_plan */
}
] /* steps */
} /* join_optimization */
},
{
"join_execution": { //执行
"select#": 1,
"steps": [
] /* steps */
} /* join_execution */
}
] /* steps */
}
//第3部分:跟踪信息过长时,被截断的跟踪信息的字节数。
MISSING_BYTES_BEYOND_MAX_MEM_SIZE: 0 //丢失的超出最大容量的字节
//第4部分:执行跟踪语句的用户是否有查看对象的权限。当不具有权限时,该列信息为1且TRACE字段为空,一般在调用带有SQL SECURITY DEFINER的视图或者是存储过程的情况下,会出现此问题。
INSUFFICIENT_PRIVILEGES: 0 //缺失权限
1 row in set (0.00 sec)
MySQL监控分析视图——sys schema
Sys schema视图摘要
- 主机相关:以host_summary开头,主要汇总了IO延迟的信息。
- Innodb相关:以innodb开头,汇总了innodb buffer信息和事务等待innodb锁的信息。
- I/o相关:以io开头,汇总了等待I/O、I/O使用量情况。
- 内存使用情况:以memory开头,从主机、线程、事件等角度展示内存的使用情况
- 连接与会话信息:processlist和session相关视图,总结了会话相关信息。
- 表相关:以schema_table开头的视图,展示了表的统计信息。
- 索引信息:统计了索引的使用情况,包含冗余索引和未使用的索引情况。
- 语句相关:以statement开头,包含执行全表扫描、使用临时表、排序等的语句信息。
- 用户相关:以user开头的视图,统计了用户使用的文件I/O、执行语句统计信息。
- 等待事件相关信息:以wait开头,展示等待事件的延迟情况。
Sys schema视图使用场景
索引相关
#1. 查询冗余索引
select * from sys.schema_redundant_indexes;
#2. 查询未使用过的索引
select * from sys.schema_unused_indexes;
#3. 查询索引的使用情况
select index_name,rows_selected,rows_inserted,rows_updated,rows_deleted
from sys.schema_index_statistics where table_schema='dbname' ;
表相关
# 1. 查询表的访问量
select table_schema,table_name,sum(io_read_requests+io_write_requests) as io from
sys.schema_table_statistics group by table_schema,table_name order by io desc;
# 2. 查询占用bufferpool较多的表
select object_schema,object_name,allocated,data
from sys.innodb_buffer_stats_by_table order by allocated limit 10;
# 3. 查看表的全表扫描情况
select * from sys.statements_with_full_table_scans where db='dbname';
语句相关
#1. 监控SQL执行的频率
select db,exec_count,query from sys.statement_analysis
order by exec_count desc;
#2. 监控使用了排序的SQL
select db,exec_count,first_seen,last_seen,query
from sys.statements_with_sorting limit 1;
#3. 监控使用了临时表或者磁盘临时表的SQL
select db,exec_count,tmp_tables,tmp_disk_tables,query
from sys.statement_analysis where tmp_tables>0 or tmp_disk_tables >0
order by (tmp_tables+tmp_disk_tables) desc;
IO相关
#1. 查看消耗磁盘IO的文件
select file,avg_read,avg_write,avg_read+avg_write as avg_io
from sys.io_global_by_file_by_bytes order by avg_read limit 10;
Innodb 相关
#1. 行锁阻塞情况
select * from sys.innodb_lock_waits;
风险提示:
通过sys库去查询时,MySQL会消耗大量资源去收集相关信息,严重的可能会导致业务请求被阻塞,从而引起故障。建议生产上不要频繁的去查询sys或者performance_schema、information_schema来完成监控、巡检等工作。