【yolov8+人/车流量统计】yolov8案例的追踪case,业务化可以变成计数,bz=4,同时追踪4路摄像头,只用一个检测模型
文章目录
- 前言
- 修改点
-
- Preprocess
- Inference
- 另一种方法,work了。
-
- 一个难点,它走到了这里
- 基于Yolov5-Deepsort的多图片输入detector修改
- 业务化修改
- 总结
前言
之前写个yolov8的一个试用版,【深度学习】Yolov8追踪从0到1, 这要是做计数啥的,简单的一批,一套工程化的代码,给自己挖了个坑,说要实现一个基于yolov8的人/车流量统计.
现在要改进,想要做成能够处理多摄像头的,也就是多个摄像头共享一个算法来处理计数。
修改点
先修改最重要的点,前处理、推理和后处理,主要是吧原来单图片,修改成多图片的入参。yolov官方工程的track.py 注释的很清楚。Preprocess/Inference/Postprocess.

改造的整体思路是要搞清楚:
- 原输入是什么
- 原输出是什么
- 期望输入是什么
- 期望输入套到原方法是否工作良好
- 期望输出是什么
Preprocess
看150行
im0s 一个list,[array([[[125, 118, 1…ype=uint8)]
看一眼它的形状:HWC
im0s[0].shape
(1080, 1920, 3)
其输出im
im.shape
torch.Size([1, 3, 384, 640])
它的作用是将list的array 转成 torch.Tensor对象,并且转成BCHW的形状,注意这里应该是resize了,将最长边1920–>640,而短边等比例缩放到了384;
正常应该缩放到360,但不知道为啥它输出了384.(待定??)
经测试,im0s 输入修改成 [array([[[125, 118, 1…ype=uint8),array([[[125, 118, 1…ype=uint8)] 输出为:torch.Size([2, 3, 384, 640]) 满足预期。
Inference
来到了154行
input: im
im.shape
torch.Size([1, 3, 384, 640])
output:preds

preds[0]
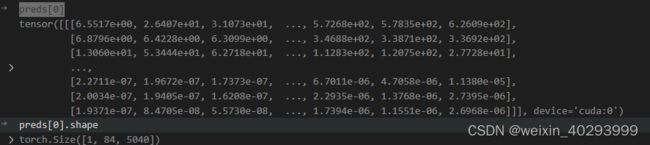
对于yolov8的结构和输出解析看这里ref:https://zhuanlan.zhihu.com/p/598566644
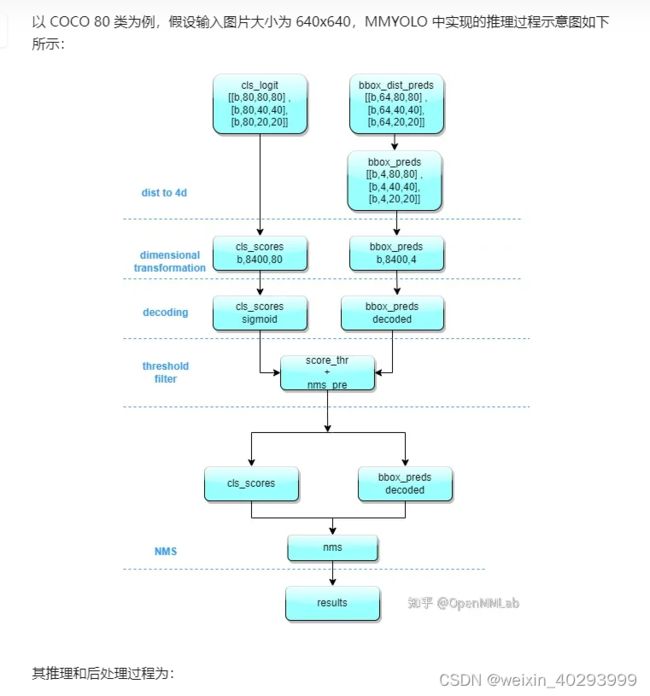
preds[0]是一个tensor, 第一维度是 bz,第二维度是 80类和矩形框位置,第三维度未知(todo)应该是融合后的特征,正常来说若输入图片是640640 则是8400=(8080 + 40*40 + 20 *20),这个知乎的解读也不一定对,起码和我打印的结果不一致。
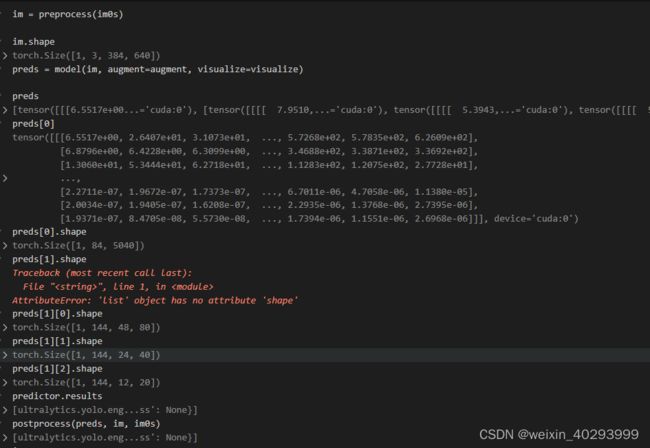
bz = 1 是可以跑出来的。
bz = 2 的时候,前两步没问题,到第三步就出问题了,跑不出来。
因为vscode 无法debug到python 环境路径的拓展包里:需要debug到/home/jianming_ge/miniconda/envs/xxx/lib/python3.9/site-packages/ultralytics/yolo/engine/model.py这里。
所以这个方法凉了。
另一种方法,work了。
ref:https://docs.ultralytics.com/modes/track/#multithreaded-tracking
这是yolov8 官方的case,藏的很深。我是三连跳找到的。
https://github.com/ultralytics/ultralytics/blob/main/examples/tutorial.ipynb—>
https://docs.ultralytics.com/tasks/ -->
https://docs.ultralytics.com/modes/track/#multithreaded-tracking
import threading
import cv2
from ultralytics import YOLO
def run_tracker_in_thread(filename, model):
video = cv2.VideoCapture(filename)
frames = int(video.get(cv2.CAP_PROP_FRAME_COUNT))
for _ in range(frames):
ret, frame = video.read()
if ret:
results = model.track(source=frame, persist=True)
res_plotted = results[0].plot()
cv2.imshow('p', res_plotted)
if cv2.waitKey(1) == ord('q'):
break
# Load the models
model1 = YOLO('yolov8n.pt')
model2 = YOLO('yolov8n-seg.pt')
# Define the video files for the trackers
video_file1 = 'path/to/video1.mp4'
video_file2 = 'path/to/video2.mp4'
# Create the tracker threads
tracker_thread1 = threading.Thread(target=run_tracker_in_thread, args=(video_file1, model1), daemon=True)
tracker_thread2 = threading.Thread(target=run_tracker_in_thread, args=(video_file2, model2), daemon=True)
# Start the tracker threads
tracker_thread1.start()
tracker_thread2.start()
# Wait for the tracker threads to finish
tracker_thread1.join()
tracker_thread2.join()
# Clean up and close windows
cv2.destroyAllWindows()
案例代码中model1 和 model2 用的模型不一样,一个检测,一个分割。其实两个也可以用检测。-----------这里有问题, todo
这是解决了追踪的问题,计数其实是对追踪的业务化。我另外的blog文章已经说明了。
这里还需要注意一点:
model1 = YOLO('yolov8n.pt')
model2 = YOLO('yolov8n-seg.pt')
这个方式若当前路径权重文件不存在,会把权重下载到当前目录,也可以指定路径,比如:
这个记录是在yolov5 vs yolov8的训练那篇文章的案例的代码。
from ultralytics import YOLO
model = YOLO('./yolov8m.pt')
model.train(data='data/firesmoke.yaml', epochs=500, imgsz=640, device=[0,1],save_period=20,workers=8,batch=24)

即使我用两个视频源做输入,跑了两个模型,可以看到所占的显存也不多。
一个分割,一个检测的模型,看起来还不错,用的是
发现问题:

这种方式其实是启动了多个model算法, 公用model1会出错,所以不是一个理想的方案。报错我也贴一下:
理想的方案应该是,比如四个摄像头,bz=4来实现目标检测/分割只用一个模型,追踪各走各的,才是一个好方案! todo。
一个难点,它走到了这里
里面用了太多的设计模式,所以,我在git上又找了一家。
ref:https://github.com/Sharpiless/Yolov5-Deepsort/tree/main
基于Yolov5-Deepsort的多图片输入detector修改
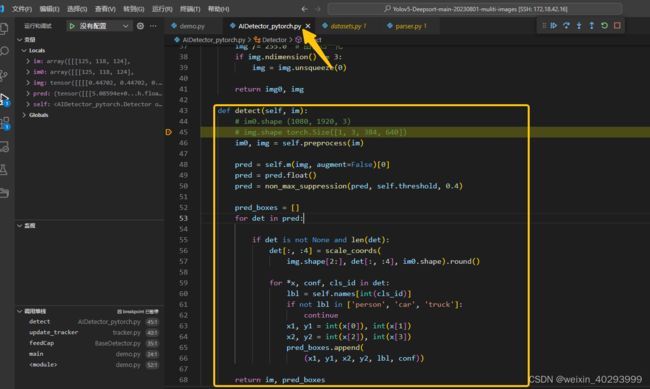
它的detect部分在这里,这是一个单图片的输入, debug 一份看如何修改。注释要好好读,是我debug的过程中的记录。
def detect(self, im):
im0, img = self.preprocess(im)
# 前处理的输出形状:img0 是袁术图片, img 是归一化 并且转成 b c h w 的tensor 其中 b=1
# im0.shape (1080, 1920, 3)
# img.shape torch.Size([1, 3, 384, 640])
pred = self.m(img, augment=False)[0]
pred = pred.float()
pred = non_max_suppression(pred, self.threshold, 0.4)
pred_boxes = []
for det in pred:
if det is not None and len(det):
det[:, :4] = scale_coords(
img.shape[2:], det[:, :4], im0.shape).round()
for *x, conf, cls_id in det:
lbl = self.names[int(cls_id)]
if not lbl in ['person', 'car', 'truck']:
continue
x1, y1 = int(x[0]), int(x[1])
x2, y2 = int(x[2]), int(x[3])
pred_boxes.append(
(x1, y1, x2, y2, lbl, conf))
return im, pred_boxes
pred = self.m(img, augment=False)
pred 是个元组
(tensor([[[5.08594e+0...h.float16), [tensor([[[[[ 2.72461...h.float16), tensor([[[[[-7.69043...h.float16), tensor([[[[[ 1.56860...h.float16)])
原代码中实际返回的是
pred[0]
我们看看它的形状:
pred[0].shape
torch.Size([1, 15120, 85])
pred[1] 是一个list,包含三个tensor,应该是三个header头的输出
pred[1]
[tensor([[[[[ 2.72461...h.float16), tensor([[[[[-7.69043...h.float16), tensor([[[[[ 1.56860...h.float16)]
pred[1][0].shape
torch.Size([1, 3, 48, 80, 85])
3*48*80
11520
len(pred[1])
3
pred[1][1].shape
torch.Size([1, 3, 24, 40, 85])
pred[1][2].shape
torch.Size([1, 3, 12, 20, 85])
# 破案了, pred[0] 的 15120 就是 三个tensor的特征的展平堆叠
(48 * 80 + 24*40 + 12*20) * 3
15120
改动点就明晰了,需要一个比如bz=4图片的检测的结果,然后分别将bboxes 循环或者多线程的方式运行42行往下的结果
知道了如何玩,就开始改造把!
业务化修改
四路摄像头,成功!!
这里面的改造遇到了很多坑点,一言难尽啊。

显卡使用了6k+,不是很美丽,但是比四路单独四个模型要好很多了。
一路是:

原因是一个deepsort模型占了 1750MB, 几路摄像头就是几个1750,这是后面的优化方向。
入口文件:multi_inputs2.py
from collections.abc import Callable, Iterable, Mapping
from typing import Any
import cv2
import threading
from queue import Queue
from ultralytics import YOLO
import imutils
import cv2
import os
from tracker import update_tracker_multi
# Load a model
yolov8_model = YOLO('yolov8m.pt')
# yolov8_model = None
class ReadCameraThread(threading.Thread):
"""
线程1:抽帧
"""
def __init__(self, video_queue, video_queue_flag):
super().__init__()
threading.Thread.__init__(self)
self.video_queue = video_queue
self.video_queue_flag = video_queue_flag
self.running = True
self.dim_size = (640, 640)
self.cap0 = cv2.VideoCapture("/home/jianming_ge/workplace/zhongwaiyun/Yolov5-Deepsort-main-20230801-muliti-images/test_video/test0.mp4")
self.cap1 = cv2.VideoCapture("/home/jianming_ge/workplace/zhongwaiyun/Yolov5-Deepsort-main-20230801-muliti-images/test_video/test1.mp4")
self.cap2 = cv2.VideoCapture("/home/jianming_ge/workplace/zhongwaiyun/Yolov5-Deepsort-main-20230801-muliti-images/test_video/test2.mp4")
self.cap3 = cv2.VideoCapture("/home/jianming_ge/workplace/zhongwaiyun/Yolov5-Deepsort-main-20230801-muliti-images/test_person.mp4")
def run(self):
if not self.cap0.isOpened() and not self.cap1.isOpened() and not self.cap2.isOpened() and not self.cap3.isOpened():
print("未检测到摄像头")
exit(0)
while True:
print("can work??",self.cap0.isOpened() and self.cap1.isOpened() and self.cap2.isOpened() and self.cap3.isOpened())
if self.cap0.isOpened() and self.cap1.isOpened() and self.cap2.isOpened() and self.cap3.isOpened():
# ret,frame = self.read_capture.read()
ret0, frame0 = self.cap0.read()
ret1, frame1 = self.cap1.read()
ret2, frame2 = self.cap2.read()
ret3, frame3 = self.cap3.read()
frame0 = cv2.resize(frame0, self.dim_size, interpolation=cv2.INTER_AREA)
frame1 = cv2.resize(frame1, self.dim_size, interpolation=cv2.INTER_AREA)
frame2 = cv2.resize(frame2, self.dim_size, interpolation=cv2.INTER_AREA)
frame3 = cv2.resize(frame3, self.dim_size, interpolation=cv2.INTER_AREA)
self.video_queue.put([frame0,frame1,frame2,frame3])
# self.video_queue.put(frame1)
# self.video_queue.put(frame2)
# self.video_queue.put(frame3)
self.video_queue_flag.put(True)
print("put")
else:
print("i am cannot put")
def stop_read_camera(self):
self.running = False
class StreamingOnlineRecognize:
def __init__(self) -> None:
self.video_queue = Queue(maxsize=1)
self.video_queue_flag = Queue(maxsize=1)
self.video_stream_in = ReadCameraThread(self.video_queue,self.video_queue_flag)
self.video_stream_in.start()
self.faceTracker0 = dict()
self.faceTracker1 = dict()
self.faceTracker2 = dict()
self.faceTracker3 = dict()
# self.retDict0 = {
# 'frame': None,
# 'faces': None,
# 'list_of_ids': None,
# 'face_bboxes': []
# }
# self.retDict1 = {
# 'frame': None,
# 'faces': None,
# 'list_of_ids': None,
# 'face_bboxes': []
# }
# self.retDict2 = {
# 'frame': None,
# 'faces': None,
# 'list_of_ids': None,
# 'face_bboxes': []
# }
# self.retDict3 = {
# 'frame': None,
# 'faces': None,
# 'list_of_ids': None,
# 'face_bboxes': []
# }
def start(self,yolov8_model):
"""
主线程用来做:
1.检测
2.deepsort
3.合并视频并显示出来
"""
self._running = True
while self._running:
if self.video_queue.full():
# get 是已put的顺序,遵守先进先出的逻辑
print("i am get")
cv2_img_list = self.video_queue.get()
# frame1 = self.video_queue.get()
# frame2 = self.video_queue.get()
# frame3 = self.video_queue.get()
# cv2_img_list = [frame0, frame1, frame2, frame3]
results = yolov8_model(cv2_img_list)
# # print(results)
all_result = []
for result in results:
pred_boxes = []
for data in result.boxes.data:
if int(data[5]) in [0,2,5]: #class id # person, car, bus
x1,y1,x2,y2,conf,class_id = int(data[0]),int(data[1]),int(data[2]),int(data[3]),float(data[4]),int(data[5])
cls_name = result.names[class_id] # person
pred_boxes.append(
(x1, y1, x2, y2, cls_name, conf))
all_result.append(pred_boxes)
frame0,frame1,frame2,frame3 = cv2_img_list
im0, faces0, face_bboxes0,self.faceTracker0 = update_tracker_multi(all_result[0],self.faceTracker0,frame0,0)
im1, faces1, face_bboxes1,self.faceTracker1 = update_tracker_multi(all_result[1],self.faceTracker1,frame1,1)
im2, faces2, face_bboxes2,self.faceTracker2 = update_tracker_multi(all_result[2],self.faceTracker2,frame2,2)
im3, faces3, face_bboxes3,self.faceTracker3 = update_tracker_multi(all_result[3],self.faceTracker3,frame3,3)
print("--==---",self.faceTracker3)
# im0,im1,im2,im3 = cv2_img_list
hframe0 = cv2.hconcat((im0, im1))
hframe1 = cv2.hconcat((im2, im3))
frame = cv2.vconcat((hframe0, hframe1))
print("-=---",len(frame))
if frame is not None:
cv2.imshow('test', frame)
cv2.waitKey(1)
if self.video_queue_flag.full():
flag = self.video_queue_flag.get()
print("flag:",flag)
if (flag == False):
break
# cv2.destroyAllWindows()
self.video_stream_in.join()
if __name__ == "__main__":
streaming_online_recognize = StreamingOnlineRecognize()
streaming_online_recognize.start(yolov8_model)
tracker.py deepsort的模型文件
from deep_sort.utils.parser import get_config
from deep_sort.deep_sort import DeepSort
import torch
import cv2
palette = (2 ** 11 - 1, 2 ** 15 - 1, 2 ** 20 - 1)
cfg = get_config()
cfg.merge_from_file("deep_sort/configs/deep_sort.yaml")
deepsort = DeepSort(cfg.DEEPSORT.REID_CKPT,
max_dist=cfg.DEEPSORT.MAX_DIST, min_confidence=cfg.DEEPSORT.MIN_CONFIDENCE,
nms_max_overlap=cfg.DEEPSORT.NMS_MAX_OVERLAP, max_iou_distance=cfg.DEEPSORT.MAX_IOU_DISTANCE,
max_age=cfg.DEEPSORT.MAX_AGE, n_init=cfg.DEEPSORT.N_INIT, nn_budget=cfg.DEEPSORT.NN_BUDGET,
use_cuda=True)
import time
time.sleep(20)
deepsort_list = [
DeepSort(cfg.DEEPSORT.REID_CKPT,
max_dist=cfg.DEEPSORT.MAX_DIST, min_confidence=cfg.DEEPSORT.MIN_CONFIDENCE,
nms_max_overlap=cfg.DEEPSORT.NMS_MAX_OVERLAP, max_iou_distance=cfg.DEEPSORT.MAX_IOU_DISTANCE,
max_age=cfg.DEEPSORT.MAX_AGE, n_init=cfg.DEEPSORT.N_INIT, nn_budget=cfg.DEEPSORT.NN_BUDGET,
use_cuda=True),
DeepSort(cfg.DEEPSORT.REID_CKPT,
max_dist=cfg.DEEPSORT.MAX_DIST, min_confidence=cfg.DEEPSORT.MIN_CONFIDENCE,
nms_max_overlap=cfg.DEEPSORT.NMS_MAX_OVERLAP, max_iou_distance=cfg.DEEPSORT.MAX_IOU_DISTANCE,
max_age=cfg.DEEPSORT.MAX_AGE, n_init=cfg.DEEPSORT.N_INIT, nn_budget=cfg.DEEPSORT.NN_BUDGET,
use_cuda=True),
DeepSort(cfg.DEEPSORT.REID_CKPT,
max_dist=cfg.DEEPSORT.MAX_DIST, min_confidence=cfg.DEEPSORT.MIN_CONFIDENCE,
nms_max_overlap=cfg.DEEPSORT.NMS_MAX_OVERLAP, max_iou_distance=cfg.DEEPSORT.MAX_IOU_DISTANCE,
max_age=cfg.DEEPSORT.MAX_AGE, n_init=cfg.DEEPSORT.N_INIT, nn_budget=cfg.DEEPSORT.NN_BUDGET,
use_cuda=True),
DeepSort(cfg.DEEPSORT.REID_CKPT,
max_dist=cfg.DEEPSORT.MAX_DIST, min_confidence=cfg.DEEPSORT.MIN_CONFIDENCE,
nms_max_overlap=cfg.DEEPSORT.NMS_MAX_OVERLAP, max_iou_distance=cfg.DEEPSORT.MAX_IOU_DISTANCE,
max_age=cfg.DEEPSORT.MAX_AGE, n_init=cfg.DEEPSORT.N_INIT, nn_budget=cfg.DEEPSORT.NN_BUDGET,
use_cuda=True)
]
def plot_bboxes(image, bboxes, line_thickness=None):
# Plots one bounding box on image img
tl = line_thickness or round(
0.002 * (image.shape[0] + image.shape[1]) / 2) + 1 # line/font thickness
for (x1, y1, x2, y2, cls_id, pos_id) in bboxes:
if cls_id in ['person']:
color = (0, 0, 255)
else:
color = (0, 255, 0)
c1, c2 = (x1, y1), (x2, y2)
cv2.rectangle(image, c1, c2, color, thickness=tl, lineType=cv2.LINE_AA)
tf = max(tl - 1, 1) # font thickness
t_size = cv2.getTextSize(cls_id, 0, fontScale=tl / 3, thickness=tf)[0]
c2 = c1[0] + t_size[0], c1[1] - t_size[1] - 3
cv2.rectangle(image, c1, c2, color, -1, cv2.LINE_AA) # filled
cv2.putText(image, '{} ID-{}'.format(cls_id, pos_id), (c1[0], c1[1] - 2), 0, tl / 3,
[225, 255, 255], thickness=tf, lineType=cv2.LINE_AA)
return image
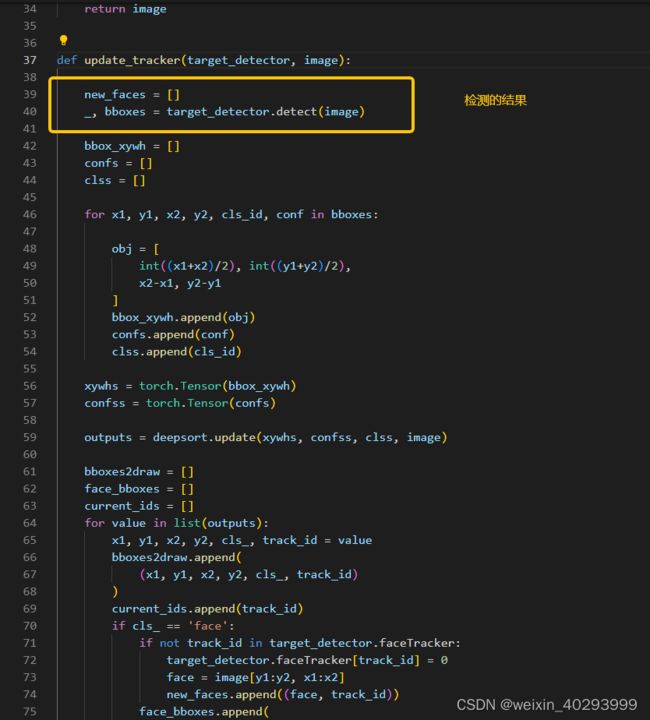
def update_tracker(target_detector, image):
new_faces = []
_, bboxes = target_detector.detect(image)
bbox_xywh = []
confs = []
clss = []
for x1, y1, x2, y2, cls_id, conf in bboxes:
obj = [
int((x1+x2)/2), int((y1+y2)/2),
x2-x1, y2-y1
]
bbox_xywh.append(obj)
confs.append(conf)
clss.append(cls_id)
xywhs = torch.Tensor(bbox_xywh)
confss = torch.Tensor(confs)
outputs = deepsort.update(xywhs, confss, clss, image)
bboxes2draw = []
face_bboxes = []
current_ids = []
for value in list(outputs):
x1, y1, x2, y2, cls_, track_id = value
bboxes2draw.append(
(x1, y1, x2, y2, cls_, track_id)
)
current_ids.append(track_id)
if cls_ == 'face':
if not track_id in target_detector.faceTracker:
target_detector.faceTracker[track_id] = 0
face = image[y1:y2, x1:x2]
new_faces.append((face, track_id))
face_bboxes.append(
(x1, y1, x2, y2)
)
ids2delete = []
for history_id in target_detector.faceTracker:
if not history_id in current_ids:
target_detector.faceTracker[history_id] -= 1
if target_detector.faceTracker[history_id] < -5:
ids2delete.append(history_id)
for ids in ids2delete:
target_detector.faceTracker.pop(ids)
print('-[INFO] Delete track id:', ids)
image = plot_bboxes(image, bboxes2draw)
return image, new_faces, face_bboxes
def update_tracker_multi(bboxes,faceTracker,image,i):
new_faces = []
bbox_xywh = []
confs = []
clss = []
for x1, y1, x2, y2, cls_id, conf in bboxes:
obj = [
int((x1+x2)/2), int((y1+y2)/2),
x2-x1, y2-y1
]
bbox_xywh.append(obj)
confs.append(conf)
clss.append(cls_id)
xywhs = torch.Tensor(bbox_xywh)
confss = torch.Tensor(confs)
outputs = deepsort_list[i].update(xywhs, confss, clss, image)
bboxes2draw = []
face_bboxes = []
current_ids = []
for value in list(outputs):
x1, y1, x2, y2, cls_, track_id = value
bboxes2draw.append(
(x1, y1, x2, y2, cls_, track_id)
)
current_ids.append(track_id)
if cls_ == 'face':
if not track_id in faceTracker:
faceTracker[track_id] = 0
face = image[y1:y2, x1:x2]
new_faces.append((face, track_id))
face_bboxes.append(
(x1, y1, x2, y2)
)
ids2delete = []
for history_id in faceTracker:
if not history_id in current_ids:
faceTracker[history_id] -= 1
if faceTracker[history_id] < -5:
ids2delete.append(history_id)
for ids in ids2delete:
faceTracker.pop(ids)
print('-[INFO] Delete track id:', ids)
image = plot_bboxes(image, bboxes2draw)
return image, new_faces, face_bboxes,faceTracker
总结
参考:
git:https://github.com/MuhammadMoinFaisal/YOLOv8-DeepSORT-Object-Tracking
git:https://docs.ultralytics.com/modes/track/#multithreaded-tracking
blog:https://blog.csdn.net/liuxuan19901010/article/details/130555216