Java多线程回答整理
1.说说volatile关键字
答:一个变量被volatile修饰之后,那么就具备了两层语义:1.保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,这新值对其他线程来说是立即可见的。2.禁止进行指令重排序,一定程度上保证了有序性。
实现原理是:《深入理解Java虚拟机》:“观察加入volatile关键字和没有加入volatile关键字时所生成的汇编代码发现,加入volatile关键字时,会多出一个lock前缀指令”。lock前缀指令实际上相当于一个内存屏障(也称内存栅栏),内存屏障会提供3个功能:
1)它确保指令重排序时不会把其后面的指令排到内存屏障之前的位置,也不会把前面的指令排到内存屏障的后面;即在执行到内存屏障这句指令时,在它前面的操作已经全部完成;
2)它会强制将对缓存的修改操作立即写入主存;
3)如果是写操作,它会导致其他CPU中对应的缓存行无效。
补充:
1.背景:缓存一致性问题
当程序在运行过程中,会将运算需要的数据从主存复制一份到CPU的高速缓存当中,那么CPU进行计算时就可以直接从它的高速缓存读取数据和向其中写入数据,当运算结束之后,再将高速缓存中的数据刷新到主存当中。但这样在多线程程序中就会有问题(单核CPU和多核CPU都存在该问题)。
2.通常解决缓存一致性问题的方法:总线加锁和缓存一致性协议

缓存一致性协议的核心的思想是:当CPU写数据时,如果发现操作的变量是共享变量,即在其他CPU中也存在该变量的副本,会发出信号通知其他CPU将该变量的缓存行置为无效状态,因此当其他CPU需要读取这个变量时,发现自己缓存中缓存该变量的缓存行是无效的,那么它就会从内存重新读取。
3.并发编程中的三个概念:原子性、可见性、有序性
原子性:操作的过程不会被打断。
可见性:当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值。
有序性:即程序执行的顺序按照代码的先后顺序执行。(JVM可能进行指令重排序,重排序不会影响单个线程的执行结果,但是可能影响多线程的结果)
//线程1:
context = loadContext(); //语句1
inited = true; //语句2
//线程2:
while(!inited ){
sleep()
}
doSomethingwithconfig(context);上面代码中,由于语句1和语句2没有数据依赖性,因此可能会被重排序。假如发生了重排序,在线程1执行过程中先执行语句2,而此是线程2会以为初始化工作已经完成,那么就会跳出while循环,去执行doSomethingwithconfig(context)方法,而此时context并没有被初始化,就会导致程序出错。
4.Java内存模型中的原子性、可见性和有序性
Java内存模型规定所有的变量都是存在主存当中(类似于前面说的物理内存),每个线程都有自己的工作内存(类似于前面的高速缓存)。线程对变量的所有操作都必须在工作内存中进行,而不能直接对主存进行操作。并且每个线程不能访问其他线程的工作内存。
Java中的原子性:在Java中,对基本数据类型的变量的读取和赋值操作是原子性操作
Java中的可见性:Java提供了volatile关键字来保证可见性。当一个共享变量被volatile修饰时,它会保证修改的值会立即被更新到主存,当有其他线程需要读取时,它会去内存中读取新值。而普通的共享变量不能保证可见性。另外,通过synchronized和Lock也能够保证可见性,synchronized和Lock能保证同一时刻只有一个线程获取锁然后执行同步代码,并且在释放锁之前会将对变量的修改刷新到主存当中。因此可以保证可见性。
Java中的有序性:可以通过volatile关键字来保证一定的“有序性”。另外可以通过synchronized和Lock来保证有序性。Java内存模型具备一些先天的“有序性”,即不需要通过任何手段就能够得到保证的有序性,这个通常也称为 happens-before 原则(共8条规则)。
5.两个案例
//线程1
boolean volatile stop = false;
while(!stop){
doSomething();
}
//线程2
stop = true;上面代码中,只要加了volatile关键字,第一:使用volatile关键字会强制将修改的值立即写入主存;第二:使用volatile关键字的话,当线程2进行修改时,会导致线程1的工作内存中缓存变量stop的缓存行无效(反映到硬件层的话,就是CPU的L1或者L2缓存中对应的缓存行无效);第三:由于线程1的工作内存中缓存变量stop的缓存行无效,所以线程1再次读取变量stop的值时会去主存读取。那么在线程2修改stop值时(当然这里包括2个操作,修改线程2工作内存中的值,然后将修改后的值写入内存),会使得线程1的工作内存中缓存变量stop的缓存行无效,然后线程1读取时,发现自己的缓存行无效,它会等待缓存行对应的主存地址被更新之后,然后去对应的主存读取最新的值。
public class Test {
public volatile int inc = 0;
public void increase() {
inc++;
}
public static void main(String[] args) {
final Test test = new Test();
for(int i=0;i<10;i++){
new Thread(){
public void run() {
for(int j=0;j<1000;j++)
test.increase();
};
}.start();
}
while(Thread.activeCount()>1) //保证前面的线程都执行完
Thread.yield();
System.out.println(test.inc);
}
}上面这段代码,虽然加了volatile关键字,但是事实上运行它会发现每次运行结果都不一致,都是一个小于10000的数字。原因是自增操作不是原子性的,它包括读取变量的原始值、进行加1操作、写入工作内存。volatile只能保证读取时是最新的值,如果一个线程读取完原始值之后,还未进行加1操作,其他线程读取了原始值并执行了加1操作,该线程将无法知道,因为值已经读取,在执行加1操作时使用最初读到的值进行加1,所以导致出错。
可以把上述代码修改为以下三种形式:
public class Test {
public int inc = 0;
public synchronized void increase() {
inc++;
}
public static void main(String[] args) {
final Test test = new Test();
for(int i=0;i<10;i++){
new Thread(){
public void run() {
for(int j=0;j<1000;j++)
test.increase();
};
}.start();
}
while(Thread.activeCount()>1) //保证前面的线程都执行完
Thread.yield();
System.out.println(test.inc);
}
}public class Test {
public int inc = 0;
Lock lock = new ReentrantLock();
public void increase() {
lock.lock();
try {
inc++;
} finally{
lock.unlock();
}
}
public static void main(String[] args) {
final Test test = new Test();
for(int i=0;i<10;i++){
new Thread(){
public void run() {
for(int j=0;j<1000;j++)
test.increase();
};
}.start();
}
while(Thread.activeCount()>1) //保证前面的线程都执行完
Thread.yield();
System.out.println(test.inc);
}
}public class Test {
public AtomicInteger inc = new AtomicInteger();
public void increase() {
inc.getAndIncrement();
}
public static void main(String[] args) {
final Test test = new Test();
for(int i=0;i<10;i++){
new Thread(){
public void run() {
for(int j=0;j<1000;j++)
test.increase();
};
}.start();
}
while(Thread.activeCount()>1) //保证前面的线程都执行完
Thread.yield();
System.out.println(test.inc);
}
}6.使用volatile关键字的场景
synchronized关键字是防止多个线程同时执行一段代码,那么就会很影响程序执行效率,而volatile关键字在某些情况下性能要优于synchronized,但是要注意volatile关键字是无法替代synchronized关键字的,因为volatile关键字无法保证操作的原子性。通常来说,使用volatile必须具备以下2个条件:
1)对变量的写操作不依赖于当前值
2)该变量没有包含在具有其他变量的不变式中
实际上,这些条件表明,可以被写入 volatile 变量的这些有效值独立于任何程序的状态,包括变量的当前状态。
事实上,我的理解就是上面的2个条件需要保证操作是原子性操作,才能保证使用volatile关键字的程序在并发时能够正确执行。
下面列举几个Java中使用volatile的几个场景。
1)状态标记量
volatile boolean flag = false;
while(!flag){
doSomething();
}
public void setFlag() {
flag = true;
}volatile boolean inited = false;
//线程1:
context = loadContext();
inited = true;
//线程2:
while(!inited ){
sleep()
}
doSomethingwithconfig(context);2)double check
class Singleton{
private volatile static Singleton instance = null;
private Singleton() {
}
public static Singleton getInstance() {
if(instance==null) {
synchronized (Singleton.class) {
if(instance==null)
instance = new Singleton();
}
}
return instance;
}
}2.可重入锁与不可重入锁?
答:所谓可重入锁,指的是以线程为单位,当一个线程获取对象锁之后,这个线程可以再次获取本对象上的锁,而其他的线程是不可以的。不可重入锁即当一个线程获取对象锁之后,释放前不可以再次获得,再次获取将导致死锁。synchronized 和 ReentrantLock 都是可重入锁。可重入锁的意义在于防止死锁。
可重入锁实现原理:每个锁关联一个请求计数器和一个占有它的线程。当计数为0时,认为锁是未被占有的;线程请求一个未被占有的锁时,JVM将记录锁的占有者,并且将请求计数器置为1 。如果同一个线程再次请求这个锁,计数将递增;每次占用线程退出同步块,计数器值将递减。直到计数器为0,锁被释放。
补充:
1.关于父类和子类的锁的重入
子类覆写了父类的synchonized方法,然后调用父类中的方法,此时如果没有重入的锁,那么这段代码将产生死锁。
2.设计一个不可重入锁
public class Lock{
private boolean isLocked = false;
public synchronized void lock() throws InterruptedException{
while(isLocked){
wait();
}
isLocked = true;
}
public synchronized void unlock(){
isLocked = false;
notify();
}
}不可重入锁使用时容易导致死锁,如:
public class Count{
Lock lock = new Lock();
public void print(){
lock.lock();
doAdd();
lock.unlock();
}
public void doAdd(){
lock.lock();
//do something
lock.unlock();
}
}3.设计一个可重入锁
public class Lock{
boolean isLocked = false;
Thread lockedBy = null;
int lockedCount = 0;
public synchronized void lock()
throws InterruptedException{
Thread thread = Thread.currentThread();
while(isLocked && lockedBy != thread){
wait();
}
isLocked = true;
lockedCount++;
lockedBy = thread;
}
public synchronized void unlock(){
if(Thread.currentThread() == this.lockedBy){
lockedCount--;
if(lockedCount == 0){
isLocked = false;
notify();
}
}
}
}3.公平锁和非公平锁?
答:公平锁:线程获取锁的顺序和调用lock的顺序一样,FIFO;
非公平锁:唤起等待队列中最前面的线程之前,其他先到的线程可以插队,所以顺序相对随机。
补充:
1.synchronized是非公平锁。
2.ReentrantLock公平和非公平都可以,模式是非公平锁。
//默认
public ReentrantLock() {
sync = new NonfairSync();
}
//传入true or false
public ReentrantLock(boolean fair) {
sync = fair ? new FairSync() : new NonfairSync();
}4.乐观锁和悲观锁?
答:
悲观锁:这是一种对数据的修改持有悲观态度的并发控制方式。总是假设最坏的情况,每次读取数据的时候都默认其他线程会更改数据,因此需要进行加锁操作,当其他线程想要访问数据时,都需要阻塞挂起。
乐观锁:乐观锁是相对悲观锁而言的,乐观锁假设数据一般情况不会造成冲突,所以在数据进行提交更新的时候,才会正式对数据的冲突与否进行检测,如果冲突,则返回给用户异常信息,让用户决定如何去做。乐观锁适用于读多写少的场景,这样可以提高程序的吞吐量。乐观锁的核心算法是CAS(CompareandSwap,比较并交换)。
synchronized和ReentrantLock都是悲观锁。
补充:
1.悲观锁实现
1)传统的关系型数据库使用这种锁机制,比如行锁、表锁、读锁、写锁等,都是在操作之前先上锁。
2)Java 里面的同步 synchronized 关键字的实现。
2.乐观锁实现
1)CAS 实现:Java 中java.util.concurrent.atomic包下面的原子变量使用了乐观锁的一种 CAS 实现方式。
2)版本号控制:一般是在数据表中加上一个数据版本号 version 字段,表示数据被修改的次数。当数据被修改时,version 值会 +1。当线程 A 要更新数据时,在读取数据的同时也会读取 version 值,在提交更新时,若刚才读取到的 version 值与当前数据库中的 version 值相等时才更新,否则重试更新操作,直到更新成功。
3.悲观锁主要分为共享锁和排他锁:
共享锁【shared locks】又称为读锁,简称 S 锁。顾名思义,共享锁就是多个事务对于同一数据可以共享一把锁,都能访问到数据,但是只能读不能修改。
排他锁【exclusive locks】又称为写锁,简称 X 锁。顾名思义,排他锁就是不能与其他锁并存,如果一个事务获取了一个数据行的排他锁,其他事务就不能再获取该行的其他锁,包括共享锁和排他锁。获取排他锁的事务可以对数据行读取和修改。
5.ReentrantLock和synchronized的区别?

相比Synchronized,ReentrantLock类提供了一些高级功能,主要有以下3项:
1.等待可中断,持有锁的线程长期不释放的时候,正在等待的线程可以选择放弃等待,这相当于Synchronized来说可以避免出现死锁的情况。通过lock.lockInterruptibly()来实现这个机制。
2.公平锁,多个线程等待同一个锁时,必须按照申请锁的时间顺序获得锁,Synchronized锁非公平锁,ReentrantLock默认的构造函数是创建的非公平锁,可以通过参数true设为公平锁,但公平锁表现的性能不是很好。
3.锁绑定多个条件,一个ReentrantLock对象可以同时绑定对个对象。ReenTrantLock提供了一个Condition(条件)类,用来实现分组唤醒需要唤醒的线程们,而不是像synchronized要么随机唤醒一个线程要么唤醒全部线程。
补充:
性能区别:
在Synchronized优化以前,synchronized的性能是比ReenTrantLock差很多的,但是自从Synchronized引入了偏向锁,轻量级锁(自旋锁)后,两者的性能就差不多了,在两种方法都可用的情况下,官方甚至建议使用synchronized,其实synchronized的优化我感觉就借鉴了ReenTrantLock中的CAS技术。都是试图在用户态就把加锁问题解决,避免进入内核态的线程阻塞。
6.Executors有哪几种创建线程池的方式?有什么区别?
答:1)ExecutorService newCachedThreadPool():创建一个可缓存的线程池;其中核心线程数量为0,最大线程数量是Integer.MAX_VALUE(2的31次方减1),线程队列是SynchronousQueue,超时时间为60s,当线程空闲时间达到60s将被回收;每当提交线程的时候,如果线程池中有空闲线程,那就由它执行新任务,如果没有就新创建线程执行任务
2)ExecutorService newFixedThreadPool(int nThreads):创建一个指定容量的线程池;其中核心线程数量和最大线程数量相同,线程队列是LinkedBlockingQueue,队列容量是Integer.MAX_VALUE,超时时间为0s,说明即使线程是空闲的,也不会被回收,这样线程池就能更快的响应请求;其次如果核心线程都在执行任务,其余任务只能等待,直到有核心线程空闲
3)ExecutorService newSingleThreadExecutor():创建一个只有一个线程的线程池;其中核心线程数量和最大线程数量都是1,线程队列是LinkedBlockingQueue,队列容量是Integer.MAX_VALUE,超时时间为0;这种线程永远只有一个线程在工作
4)ScheduledExecutorService newScheduledThreadPool(int corePoolSize):创建一个具有定时定期执行任务功能的线程池;核心线程数由我们指定,最大线程数是Integer.MAX_VALUE,超时时间10ms,线程队列DelayedWorkQueue;可以看到它返回一个接口类ScheduledExecutorService,实现类是ScheduledThreadPoolExecutor(继承ThreadPoolExecutor),它提供我们延迟启动任务和定时执行任务的方法。

7.Executors和ThreadPoolExecutor是什么关系?
答:Executors类只是官方为了开发者方便对线程池进行了下封装,4种创建线程池的方式最终都是调用ThreadPoolExecutor的构造方法来实现。
Android中关于线程的API其实Java的,老祖宗是Executor这样一个接口,提供了一个执行线程的方法execute(Runnable command);还有另外一个接口ExecutorService继承自Executor,扩展了它的能力。不能总是接口啊,总要有一个人来实现这些盖世武功吧,没错,就是ThreadPoolExecutor这孙子了(其实它还有一个兄弟叫ForkJoinPool,也实现了这些功能)。
8.ThreadPoolExecutor线程池运行逻辑?
答:当我们通过execute方法提交一个线程后,它的去向如下几种(这里排除核心线程数为0的情况)
1)当线程池中正在执行的线程数量没有超过核心线程数量时,会立马新建一个核心线程执行任务
2)当线程池中正在执行的线程数量达到了核心线程数量,但是线程队列workQueue没有满,那提交的任务会保存在队列中
3)当线程池中正在执行的线程数量已经达到了核心线程数量,且线程队列workQueue已满,此时新建一个非核心线程执行任务
4)当线程池中正在执行的线程数量已经达到了最大线程数量,且线程队列workQueue已满,此时再提交任务将会拒绝执行,如果开发者不做处理,将抛出异常

9.synchronized是重量级锁吗?
答:在JDK1.5之前synchronized是一个重量级锁,相对于j.u.c.Lock,它会显得那么笨重,以至于我们认为它不是那么的高效而慢慢摒弃它。不过,随着Javs SE 1.6对synchronized进行的各种优化后,synchronized并不会显得那么重了。
10.synchronized原理分析?
答:任何一个对象都有一个Monitor与之关联,当且一个Monitor被持有后,它将处于锁定状态。Synchronized在JVM里的实现都是 基于进入和退出Monitor对象来实现方法同步和代码块同步,虽然具体实现细节不一样,但是都可以通过成对的MonitorEnter和MonitorExit指令来实现。
- MonitorEnter指令:插入在同步代码块的开始位置,当代码执行到该指令时,将会尝试获取该对象Monitor的所有权,即尝试获得该对象的锁;
- MonitorExit指令:插入在方法结束处和异常处,JVM保证每个MonitorEnter必须有对应的MonitorExit;
补充:
1.原理分析
package com.paddx.test.concurrent;
public class SynchronizedDemo {
public void method() {
synchronized (this) {
System.out.println("Method 1 start");
}
}
}上面代码的反编译结果:

1.monitorenter:每个对象都是一个监视器锁(monitor)。当monitor被占用时就会处于锁定状态,线程执行monitorenter指令时尝试获取monitor的所有权,过程如下:
- 如果monitor的进入数为0,则该线程进入monitor,然后将进入数设置为1,该线程即为monitor的所有者;
- 如果线程已经占有该monitor,只是重新进入,则进入monitor的进入数加1;
- 如果其他线程已经占用了monitor,则该线程进入阻塞状态,直到monitor的进入数为0,再重新尝试获取monitor的所有权;
2.monitorexit:执行monitorexit的线程必须是objectref所对应的monitor的所有者。指令执行时,monitor的进入数减1,如果减1后进入数为0,那线程退出monitor,不再是这个monitor的所有者。其他被这个monitor阻塞的线程可以尝试去获取这个 monitor 的所有权。monitorexit指令出现了两次,第1次为同步正常退出释放锁;第2次为发生异常退出释放锁;
通过上面两段描述,我们应该能很清楚的看出Synchronized的实现原理,Synchronized的语义底层是通过一个monitor的对象来完成,其实wait/notify等方法也依赖于monitor对象,这就是为什么只有在同步的块或者方法中才能调用wait/notify等方法,否则会抛出java.lang.IllegalMonitorStateException的异常的原因。
再看一下同步方法:
public class SynchronizedMethod {
public synchronized void method() {
System.out.println("Hello World!");
}
}编译后的结果:

从编译的结果来看,方法的同步并没有通过指令 monitorenter 和 monitorexit 来完成(理论上其实也可以通过这两条指令来实现),不过相对于普通方法,其常量池中多了 ACC_SYNCHRONIZED 标示符。JVM就是根据该标示符来实现方法的同步的:
当方法调用时,调用指令将会检查方法的 ACC_SYNCHRONIZED 访问标志是否被设置,如果设置了,执行线程将先获取monitor,获取成功之后才能执行方法体,方法执行完后再释放monitor。在方法执行期间,其他任何线程都无法再获得同一个monitor对象。
两种同步方式本质上没有区别,只是方法的同步是一种隐式的方式来实现,无需通过字节码来完成。两个指令的执行是JVM通过调用操作系统的互斥原语mutex来实现,被阻塞的线程会被挂起、等待重新调度,会导致“用户态和内核态”两个态之间来回切换,对性能有较大影响。
2.数据同步需要依赖锁,那锁的同步又依赖谁?
synchronized给出的答案是在软件层面依赖JVM,而j.u.c.Lock给出的答案是在硬件层面依赖特殊的CPU指令。
3.sychronized使用的锁存在哪里?
Synchronized用的锁存在Java对象头里的。
4.由于字符串常量池的原因,在大多数情况下,同步synchronized代码块 都不使用 String 作为锁对象。
5.class锁(类锁)
特别地,每个类也会有一个锁,静态的 synchronized方法 就是以Class对象作为锁。另外,它可以用来控制对 static 数据成员 (static 数据成员不专属于任何一个对象,是类成员) 的并发访问。并且,如果一个线程执行一个对象的非static synchronized 方法,另外一个线程需要执行这个对象所属类的 static synchronized 方法,也不会发生互斥现象。因为访问 static synchronized 方法占用的是类锁,而访问非 static synchronized 方法占用的是对象锁,所以不存在互斥现象。
6.什么是monitor?
可以把它理解为 一个同步工具,也可以描述为 一种同步机制,它通常被 描述为一个对象。
与一切皆对象一样,所有的Java对象是天生的Monitor,每一个Java对象都有成为Monitor的潜质,因为在Java的设计中 ,每一个Java对象自打娘胎里出来就带了一把看不见的锁,它叫做内部锁或者Monitor锁。
也就是通常说Synchronized的对象锁,MarkWord锁标识位为10,其中指针指向的是Monitor对象的起始地址。在Java虚拟机(HotSpot)中,Monitor是由ObjectMonitor实现的(位于HotSpot虚拟机源码ObjectMonitor.hpp文件,C++实现的)。
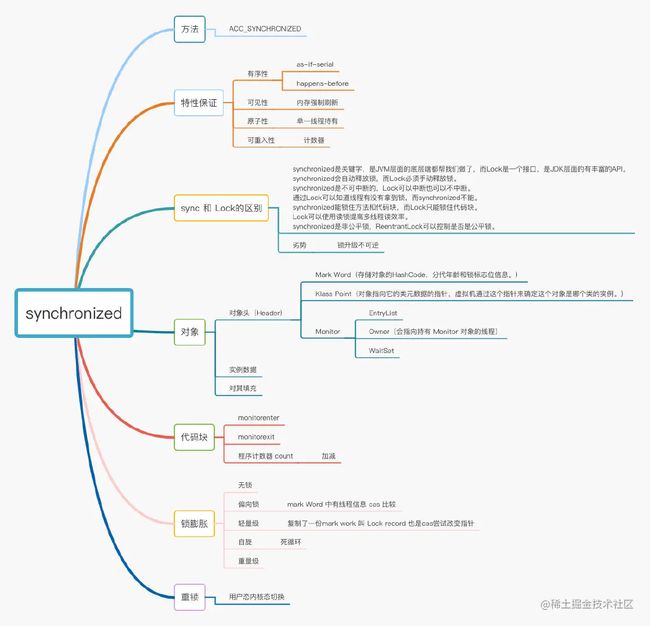
11.Java对象头?
答:Hotspot虚拟机的对象头主要包括两部分数据:Mark Word(标记字段)、Class Pointer(类型指针)。其中 Class Pointer是对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例,Mark Word用于存储对象自身的运行时数据,如:哈希码(HashCode)、GC分代年龄、锁状态标志、线程持有的锁、偏向线程 ID、偏向时间戳等。它是实现轻量级锁和偏向锁的关键。

补充:
1.Java对象结构?


- 实例数据:存放类的属性数据信息,包括父类的属性信息;
- 对齐填充:由于虚拟机要求 对象起始地址必须是8字节的整数倍。填充数据不是必须存在的,仅仅是为了字节对齐;
-
对象头:Java对象头一般占有2个机器码(在32位虚拟机中,1个机器码等于4字节,也就是32bit,在64位虚拟机中,1个机器码是8个字节,也就是64bit),但是 如果对象是数组类型,则需要3个机器码,因为JVM虚拟机可以通过Java对象的元数据信息确定Java对象的大小,但是无法从数组的元数据来确认数组的大小,所以用一块来记录数组长度。
2.对象头中Mark Word与线程中Lock Record
答:在线程进入同步代码块的时候,如果此同步对象没有被锁定,即它的锁标志位是01,则虚拟机首先在当前线程的栈中创建我们称之为“锁记录(Lock Record)”的空间,用于存储锁对象的Mark Word的拷贝,官方把这个拷贝称为Displaced Mark Word。整个Mark Word及其拷贝至关重要。
Lock Record是线程私有的数据结构,每一个线程都有一个可用Lock Record列表,同时还有一个全局的可用列表。每一个被锁住的对象Mark Word都会和一个Lock Record关联(对象头的MarkWord中的Lock Word指向Lock Record的起始地址),同时Lock Record中有一个Owner字段存放拥有该锁的线程的唯一标识(或者object mark word),表示该锁被这个线程占用。
12.Java对锁的优化?
答:从JDK5引入了现代操作系统新增加的CAS原子操作( JDK5中并没有对synchronized关键字做优化,而是体现在J.U.C中,所以在该版本concurrent包有更好的性能 ),从JDK6开始,就对synchronized的实现机制进行了较大调整,包括使用JDK5引进的CAS自旋之外,还增加了自适应的CAS自旋、锁消除、锁粗化、偏向锁、轻量级锁这些优化策略。由于此关键字的优化使得性能极大提高,同时语义清晰、操作简单、无需手动关闭,所以推荐在允许的情况下尽量使用此关键字,同时在性能上此关键字还有优化的空间。
锁主要存在四种状态,依次是:无锁状态、偏向锁状态、轻量级锁状态、重量级锁状态,锁可以从偏向锁升级到轻量级锁,再升级的重量级锁。但是锁的升级是单向的,也就是说只能从低到高升级,不会出现锁的降级。在 JDK 1.6 中默认是开启偏向锁和轻量级锁的,可以通过-XX:-UseBiasedLocking来禁用偏向锁。
补充:
背景:
java的线程是映射到操作系统原生线程之上的,如果要阻塞或唤醒一个线程就需要操作系统介入,需要在户态与核心态之间切换,这种切换会消耗大量的系统资源,因为用户态与内核态都有各自专用的内存空间,专用的寄存器等,用户态切换至内核态需要传递给许多变量、参数给内核,内核也需要保护好用户态在切换时的一些寄存器值、变量等,以便内核态调用结束后切换回用户态继续工作。
因为需要限制不同的程序之间的访问能力, 防止他们获取别的程序的内存数据, 或者获取外围设备的数据, 并发送到网络, CPU划分出两个权限等级 :用户态 和 内核态
内核态:CPU可以访问内存所有数据, 包括外围设备, 例如硬盘, 网卡. CPU也可以将自己从一个程序切换到另一个程序
用户态:只能受限的访问内存, 且不允许访问外围设备. 占用CPU的能力被剥夺, CPU资源可以被其他程序获取
所有用户程序都是运行在用户态的, 但是有时候程序确实需要做一些内核态的事情, 例如从硬盘读取数据, 或者从键盘获取输入等.,而唯一可以做这些事情的就是操作系统, 所以此时程序就需要先操作系统请求以程序的名义来执行这些操作(比如java的I/O操作底层都是通过native方法来调用操作系统)。这时需要一个这样的机制: 用户态程序切换到内核态, 但是不能控制在内核态中执行的指令。这种机制叫系统调用, 在CPU中的实现称之为陷阱指令(Trap Instruction)。参考详情
synchronized会导致争用不到锁的线程进入阻塞状态,所以说它是java语言中一个重量级的同步操纵,被称为重量级锁,为了缓解上述性能问题,JVM从1.5开始,引入了轻量锁与偏向锁,默认启用了自旋锁,他们都属于乐观锁。所以明确java线程切换的代价,是理解java中各种锁的优缺点的基础之一。
同时我们还必须注意到的是在Java早期版本中,synchronized属于重量级锁,效率低下,因为监视器锁(monitor)是依赖于底层的操作系统的Mutex Lock来实现的,挂起线程和恢复线程都需要转入内核态去完成,这个状态之间的转换需要相对比较长的时间,时间成本相对较高,这也是为什么早期的synchronized效率低的原因。庆幸的是在Java 6之后Java官方对从JVM层面对synchronized较大优化,所以现在的synchronized锁效率也优化得很不错了,Java 6之后,为了减少获得锁和释放锁所带来的性能消耗,引入了轻量级锁和偏向锁,接下来我们将简单了解一下Java官方在JVM层面对synchronized锁的优化。
13.锁优化之自旋锁?
答:线程的阻塞和唤醒需要CPU从用户态转为核心态,频繁的阻塞和唤醒对CPU来说是一件负担很重的工作,势必会给系统的并发性能带来很大的压力。同时我们发现在许多应用上面,对象锁的锁状态只会持续很短一段时间,为了这一段很短的时间频繁地阻塞和唤醒线程是非常不值得的。所以引入自旋锁,所谓自旋锁,就是指当一个线程尝试获取某个锁时,如果该锁已被其他线程占用,就一直循环检测锁是否被释放,而不是进入线程挂起或睡眠状态。自旋锁适用于锁保护的临界区很小的情况,临界区很小的话,锁占用的时间就很短。自旋等待不能替代阻塞,虽然它可以避免线程切换带来的开销,但是它占用了CPU处理器的时间。如果持有锁的线程很快就释放了锁,那么自旋的效率就非常好,反之,自旋的线程就会白白消耗掉处理的资源,它不会做任何有意义的工作,典型的占着茅坑不拉屎,这样反而会带来性能上的浪费。所以说,自旋等待的时间(自旋的次数)必须要有一个限度,如果自旋超过了定义的时间仍然没有获取到锁,则应该被挂起。
补充:
适应性自旋锁?
JDK 1.6引入了更加聪明的自旋锁,即自适应自旋锁。所谓自适应就意味着自旋的次数不再是固定的,它是由前一次在同一个锁上的自旋时间及锁的拥有者的状态来决定。
线程如果自旋成功了,那么下次自旋的次数会更加多,因为虚拟机认为既然上次成功了,那么此次自旋也很有可能会再次成功,那么它就会允许自旋等待持续的次数更多。反之,如果对于某个锁,很少有自旋能够成功,那么在以后要或者这个锁的时候自旋的次数会减少甚至省略掉自旋过程,以免浪费处理器资源。
14.锁优化之锁消除?
答:为了保证数据的完整性,在进行操作时需要对这部分操作进行同步控制,但是在有些情况下,JVM检测到不可能存在共享数据竞争,这是JVM会对这些同步锁进行锁消除。
15.锁优化之锁粗化?
答:在使用同步锁的时候,需要让同步块的作用范围尽可能小—仅在共享数据的实际作用域中才进行同步,这样做的目的是为了使需要同步的操作数量尽可能缩小,如果存在锁竞争,那么等待锁的线程也能尽快拿到锁。在大多数的情况下,上述观点是正确的。但是如果一系列的连续加锁解锁操作,可能会导致不必要的性能损耗,所以引入锁粗话的概念。锁粗话概念比较好理解,就是将多个连续的加锁、解锁操作连接在一起,扩展成一个范围更大的锁。
补充:
实例:vector每次add的时候都需要加锁操作,JVM检测到对同一个对象(vector)连续加锁、解锁操作,会合并一个更大范围的加锁、解锁操作,即加锁解锁操作会移到for循环之外。
15.锁优化之偏向锁?
答:偏向锁是JDK6中的重要引进,因为HotSpot作者经过研究实践发现,在大多数情况下,锁不仅不存在多线程竞争,而且总是由同一线程多次获得,为了让线程获得锁的代价更低,引进了偏向锁。
偏向锁是在单线程执行代码块时使用的机制,如果在多线程并发的环境下(即线程A尚未执行完同步代码块,线程B发起了申请锁的申请),则一定会转化为轻量级锁或者重量级锁。
在JDK5中偏向锁默认是关闭的,而到了JDK6中偏向锁已经默认开启。如果并发数较大同时同步代码块执行时间较长,则被多个线程同时访问的概率就很大,就可以使用参数-XX:-UseBiasedLocking来禁止偏向锁(但这是个JVM参数,不能针对某个对象锁来单独设置)。
引入偏向锁主要目的是:为了在没有多线程竞争的情况下尽量减少不必要的轻量级锁执行路径。因为轻量级锁的加锁解锁操作是需要依赖多次CAS原子指令的,而偏向锁只需要在置换ThreadID的时候依赖一次CAS原子指令(由于一旦出现多线程竞争的情况就必须撤销偏向锁,所以偏向锁的撤销操作的性能损耗也必须小于节省下来的CAS原子指令的性能消耗)。
轻量级锁是为了在线程交替执行同步块时提高性能,而偏向锁则是在只有一个线程执行同步块时进一步提高性能。
16.锁优化之轻量级锁?
答:引入轻量级锁的主要目的是 在没有多线程竞争的前提下,减少传统的重量级锁使用操作系统互斥量产生的性能消耗。当关闭偏向锁功能或者多个线程竞争偏向锁导致偏向锁升级为轻量级锁。
对于轻量级锁,其性能提升的依据是 “对于绝大部分的锁,在整个生命周期内都是不会存在竞争的”,如果打破这个依据则除了互斥的开销外,还有额外的CAS操作,因此在有多线程竞争的情况下,轻量级锁比重量级锁更慢。
“轻量级”是相对于使用操作系统互斥量来实现的传统锁而言的。但是,首先需要强调一点的是,轻量级锁并不是用来代替重量级锁的,它的本意是在没有多线程竞争的前提下,减少传统的重量级锁使用产生的性能消耗。
轻量级锁所适应的场景是线程交替执行同步块的情况,如果存在同一时间访问同一锁的情况,必然就会导致轻量级锁膨胀为重量级锁。
17.重量级锁?
答:Synchronized是通过对象内部的一个叫做 监视器锁(Monitor)来实现的。但是监视器锁本质又是依赖于底层的操作系统的Mutex Lock来实现的。而操作系统实现线程之间的切换这就需要从用户态转换到核心态,这个成本非常高,状态之间的转换需要相对比较长的时间,这就是为什么Synchronized效率低的原因。因此,这种依赖于操作系统Mutex Lock所实现的锁我们称之为 “重量级锁”。
18.锁优化之偏向锁、轻量级锁、重量级锁之间的转换?

19.锁优化之锁的优劣?
答:各种锁并不是相互代替的,而是在不同场景下的不同选择,绝对不是说重量级锁就是不合适的。每种锁是只能升级,不能降级,即由偏向锁->轻量级锁->重量级锁,而这个过程就是开销逐渐加大的过程。
- 如果是单线程使用,那偏向锁毫无疑问代价最小,并且它就能解决问题,连CAS都不用做,仅仅在内存中比较下对象头就可以了;
- 如果出现了其他线程竞争,则偏向锁就会升级为轻量级锁;
- 如果其他线程通过一定次数的CAS尝试没有成功,则进入重量级锁;
在第3种情况下进入同步代码块就 要做偏向锁建立、偏向锁撤销、轻量级锁建立、升级到重量级锁,最终还是得靠重量级锁来解决问题,那这样的代价就比直接用重量级锁要大不少了。所以使用哪种技术,一定要看其所处的环境及场景,在绝大多数的情况下,偏向锁是有效的,这是基于HotSpot作者发现的“大多数锁只会由同一线程并发申请”的经验规律。

20.CAS操作原理?
答:CAS(Compare And Swap)操作是一种乐观锁。每次不加锁而是假设没有冲突而去完成某项操作,如果因为冲突失败就重试,直到成功为止。CAS机制当中使用了3个基本操作数:内存地址V,旧的预期值A,要修改的新值B。更新一个变量的时候,只有当变量的预期值A和内存地址V当中的实际值相同时,才会将内存地址V对应的值修改为B,否则重新地址种实际的值作为预期值A,并重新计算出新值并再次尝试更新。
补充:
原子操作类,即java.util.concurrent.atomic包下,一系列以Atomic开头的包装类。例如AtomicBoolean,AtomicInteger,AtomicLong等,就是使用CAS操作来实现同步。
21.CAS操作的缺点?
答:1.CPU开销较大
在并发量比较高的情况下,如果许多线程反复尝试更新某一个变量,却又一直更新不成功,循环往复的进行计算和尝试更新,会给CPU带来很大的压力。
2.不能保证代码块的原子性
CAS机制所保证的只是一个变量的原子性操作,而不能保证整个代码块的原子性。比如需要保证3个变量共同进行原子性的更新,就不得不使用Synchronized了。
22.3种经典的实现生产者消费者的方式
1.wait/notifyAll实现生产者-消费者
public class ProductorConsumer {
public static void main(String[] args) {
LinkedList linkedList = new LinkedList();
ExecutorService service = Executors.newFixedThreadPool(15);
for (int i = 0; i < 5; i++) {
service.submit(new Productor(linkedList, 8));
}
for (int i = 0; i < 10; i++) {
service.submit(new Consumer(linkedList));
}
}
static class Productor implements Runnable {
private List list;
private int maxLength;
public Productor(List list, int maxLength) {
this.list = list;
this.maxLength = maxLength;
}
@Override
public void run() {
while (true) {
synchronized (list) {
try {
while (list.size() == maxLength) {
System.out.println("生产者" + Thread.currentThread().getName() + " list以达到最大容量,进行wait");
list.wait();
System.out.println("生产者" + Thread.currentThread().getName() + " 退出wait");
}
Random random = new Random();
int i = random.nextInt();
System.out.println("生产者" + Thread.currentThread().getName() + " 生产数据" + i);
list.add(i);
list.notifyAll();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
}
static class Consumer implements Runnable {
private List list;
public Consumer(List list) {
this.list = list;
}
@Override
public void run() {
while (true) {
synchronized (list) {
try {
while (list.isEmpty()) {
System.out.println("消费者" + Thread.currentThread().getName() + " list为空,进行wait");
list.wait();
System.out.println("消费者" + Thread.currentThread().getName() + " 退出wait");
}
Integer element = list.remove(0);
System.out.println("消费者" + Thread.currentThread().getName() + " 消费数据:" + element);
list.notifyAll();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
}
}
输出结果:
生产者pool-1-thread-1 生产数据-232820990
生产者pool-1-thread-1 生产数据1432164130
生产者pool-1-thread-1 生产数据1057090222
生产者pool-1-thread-1 生产数据1201395916
生产者pool-1-thread-1 生产数据482766516
生产者pool-1-thread-1 list以达到最大容量,进行wait
消费者pool-1-thread-15 退出wait
消费者pool-1-thread-15 消费数据:1237535349
消费者pool-1-thread-15 消费数据:-1617438932
消费者pool-1-thread-15 消费数据:-535396055
消费者pool-1-thread-15 消费数据:-232820990
消费者pool-1-thread-15 消费数据:1432164130
消费者pool-1-thread-15 消费数据:1057090222
消费者pool-1-thread-15 消费数据:1201395916
消费者pool-1-thread-15 消费数据:482766516
消费者pool-1-thread-15 list为空,进行wait
生产者pool-1-thread-5 退出wait
生产者pool-1-thread-5 生产数据1442969724
生产者pool-1-thread-5 生产数据1177554422
生产者pool-1-thread-5 生产数据-133137235
生产者pool-1-thread-5 生产数据324882560
生产者pool-1-thread-5 生产数据2065211573
生产者pool-1-thread-5 生产数据253569900
生产者pool-1-thread-5 生产数据571277922
生产者pool-1-thread-5 生产数据1622323863
生产者pool-1-thread-5 list以达到最大容量,进行wait
消费者pool-1-thread-10 退出wait 注意:
这里判断阻塞时while (list.size() == maxLength)和while (list.isEmpty())为什么要用while?能不能用if?
为了防止等待条件发生变化。需要在wait结束时重新判断等待条件,如果不判断的话,可能导致程序出错,所以不能用if。例如有多个消费者在wait,当生产者生产完毕后调用notifyAll,消费者A执行了remove,list又成了空,如果消费者B退出wait之后不再次判断等待条件,直接执行remove,程序将出错。
这里为什么要用notifyAll()?能不能用notify()?为什么?
为了防止“假死”状态,如果是多消费者和多生产者情况,如果使用notify方法可能会出现“假死”的情况,即唤醒的是同类线程。原因分析:假设当前多个生产者线程会调用wait方法阻塞等待,当其中的生产者线程获取到对象锁之后使用notify通知处于WAITTING状态的线程,如果唤醒的仍然是生产者线程,就会造成所有的生产者线程都处于等待状态。解决办法:将notify方法替换成notifyAll方法,如果使用的是lock的话,就将signal方法替换成signalAll方法。
所以,使用wait和notifyAll实现生产者消费者时基本的使用范式如下:
// The standard idiom for calling the wait method in Java
synchronized (sharedObject) {
while (condition) {
sharedObject.wait();
// (Releases lock, and reacquires on wakeup)
}
// do action based upon condition e.g. take or put into queue
}2.使用Lock中Condition的await/signalAll实现生产者-消费者
public class ProductorConsumer {
private static ReentrantLock lock = new ReentrantLock();
private static Condition full = lock.newCondition();
private static Condition empty = lock.newCondition();
public static void main(String[] args) {
LinkedList linkedList = new LinkedList();
ExecutorService service = Executors.newFixedThreadPool(15);
for (int i = 0; i < 5; i++) {
service.submit(new Productor(linkedList, 8, lock));
}
for (int i = 0; i < 10; i++) {
service.submit(new Consumer(linkedList, lock));
}
}
static class Productor implements Runnable {
private List list;
private int maxLength;
private Lock lock;
public Productor(List list, int maxLength, Lock lock) {
this.list = list;
this.maxLength = maxLength;
this.lock = lock;
}
@Override
public void run() {
while (true) {
lock.lock();
try {
while (list.size() == maxLength) {
System.out.println("生产者" + Thread.currentThread().getName() + " list以达到最大容量,进行wait");
full.await();
System.out.println("生产者" + Thread.currentThread().getName() + " 退出wait");
}
Random random = new Random();
int i = random.nextInt();
System.out.println("生产者" + Thread.currentThread().getName() + " 生产数据" + i);
list.add(i);
empty.signalAll();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
}
}
static class Consumer implements Runnable {
private List list;
private Lock lock;
public Consumer(List list, Lock lock) {
this.list = list;
this.lock = lock;
}
@Override
public void run() {
while (true) {
lock.lock();
try {
while (list.isEmpty()) {
System.out.println("消费者" + Thread.currentThread().getName() + " list为空,进行wait");
empty.await();
System.out.println("消费者" + Thread.currentThread().getName() + " 退出wait");
}
Integer element = list.remove(0);
System.out.println("消费者" + Thread.currentThread().getName() + " 消费数据:" + element);
full.signalAll();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
}
}
}
输出结果:
消费者pool-1-thread-9 消费数据:1146627506
消费者pool-1-thread-9 消费数据:1508001019
消费者pool-1-thread-9 消费数据:-600080565
消费者pool-1-thread-9 消费数据:-1000305429
消费者pool-1-thread-9 消费数据:-1270658620
消费者pool-1-thread-9 消费数据:1961046169
消费者pool-1-thread-9 消费数据:-307680655
消费者pool-1-thread-9 list为空,进行wait
消费者pool-1-thread-13 退出wait
消费者pool-1-thread-13 list为空,进行wait
消费者pool-1-thread-10 退出wait
生产者pool-1-thread-5 退出wait
生产者pool-1-thread-5 生产数据-892558288
生产者pool-1-thread-5 生产数据-1917220008
生产者pool-1-thread-5 生产数据2146351766
生产者pool-1-thread-5 生产数据452445380
生产者pool-1-thread-5 生产数据1695168334
生产者pool-1-thread-5 生产数据1979746693
生产者pool-1-thread-5 生产数据-1905436249
生产者pool-1-thread-5 生产数据-101410137
生产者pool-1-thread-5 list以达到最大容量,进行wait
生产者pool-1-thread-1 退出wait
生产者pool-1-thread-1 list以达到最大容量,进行wait
生产者pool-1-thread-4 退出wait
生产者pool-1-thread-4 list以达到最大容量,进行wait
生产者pool-1-thread-2 退出wait
生产者pool-1-thread-2 list以达到最大容量,进行wait
生产者pool-1-thread-3 退出wait
生产者pool-1-thread-3 list以达到最大容量,进行wait
消费者pool-1-thread-9 退出wait
消费者pool-1-thread-9 消费数据:-892558288 3.使用BlockingQueue实现生产者-消费者
public class ProductorConsumer {
private static LinkedBlockingQueue queue = new LinkedBlockingQueue<>();
public static void main(String[] args) {
ExecutorService service = Executors.newFixedThreadPool(15);
for (int i = 0; i < 5; i++) {
service.submit(new Productor(queue));
}
for (int i = 0; i < 10; i++) {
service.submit(new Consumer(queue));
}
}
static class Productor implements Runnable {
private BlockingQueue queue;
public Productor(BlockingQueue queue) {
this.queue = queue;
}
@Override
public void run() {
try {
while (true) {
Random random = new Random();
int i = random.nextInt();
System.out.println("生产者" + Thread.currentThread().getName() + "生产数据" + i);
queue.put(i);
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
static class Consumer implements Runnable {
private BlockingQueue queue;
public Consumer(BlockingQueue queue) {
this.queue = queue;
}
@Override
public void run() {
try {
while (true) {
Integer element = (Integer) queue.take();
System.out.println("消费者" + Thread.currentThread().getName() + "正在消费数据" + element);
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
输出结果:
消费者pool-1-thread-7正在消费数据1520577501
生产者pool-1-thread-4生产数据-127809610
消费者pool-1-thread-8正在消费数据504316513
生产者pool-1-thread-2生产数据1994678907
消费者pool-1-thread-11正在消费数据1967302829
生产者pool-1-thread-1生产数据369331507
消费者pool-1-thread-9正在消费数据1994678907
生产者pool-1-thread-2生产数据-919544017
消费者pool-1-thread-12正在消费数据-127809610
生产者pool-1-thread-4生产数据1475197572
消费者pool-1-thread-14正在消费数据-893487914
生产者pool-1-thread-3生产数据906921688
消费者pool-1-thread-6正在消费数据-1292015016
生产者pool-1-thread-5生产数据-652105379
生产者pool-1-thread-5生产数据-1622505717
生产者pool-1-thread-3生产数据-1350268764
消费者pool-1-thread-7正在消费数据906921688
生产者pool-1-thread-4生产数据2091628867
消费者pool-1-thread-13正在消费数据1475197572
消费者pool-1-thread-15正在消费数据-919544017
生产者pool-1-thread-2生产数据564860122
生产者pool-1-thread-2生产数据822954707
消费者pool-1-thread-14正在消费数据564860122
消费者pool-1-thread-10正在消费数据369331507
生产者pool-1-thread-1生产数据-245820912
消费者pool-1-thread-6正在消费数据822954707
生产者pool-1-thread-2生产数据1724595968
生产者pool-1-thread-2生产数据-1151855115
消费者pool-1-thread-12正在消费数据2091628867
生产者pool-1-thread-4生产数据-1774364499
生产者pool-1-thread-4生产数据2006106757
消费者pool-1-thread-14正在消费数据-1774364499
生产者pool-1-thread-3生产数据-1070853639
消费者pool-1-thread-9正在消费数据-1350268764
消费者pool-1-thread-11正在消费数据-1622505717
生产者pool-1-thread-5生产数据355412953 利用了BlockingQueue插入和获取数据附加阻塞操作的特性。
22.可中断锁与不可中断锁?
答:可中断锁是指线程尝试获取锁的过程中,是否可以响应中断。synchronized是不可中断锁,而ReentrantLock则提供了中断功能。
注意这里说的是否可以中断不是指获取到锁之后的执行过程是否可以中断,而是指等待锁的过程是否可以中断!
23.线程中断与synchronized?
答:中断两种情况,一种是当线程处于阻塞状态或者试图执行一个阻塞操作时,我们可以使用实例方法interrupt()进行线程中断,执行中断操作后将会抛出interruptException异常(该异常必须捕捉无法向外抛出)并将中断状态复位,另外一种是当线程处于运行状态时,我们也可调用实例方法interrupt()进行线程中断,但同时必须手动判断中断状态,并编写中断线程的代码(其实就是结束run方法体的代码)。
有时我们在编码时可能需要兼顾以上两种情况,那么就可以如下编写:
public void run(){
try {
//判断当前线程是否已中断,注意interrupted方法是静态的,执行后会对中断状态进行复位
while (!Thread.interrupted()) {
TimeUnit.SECONDS.sleep(2);
}
} catch (InterruptedException e) {
}
}注意:线程的中断操作对于正在等待获取的锁对象的synchronized方法或者代码块并不起作用,也就是对于synchronized来说,如果一个线程在等待锁,那么结果只有两种,要么它获得这把锁继续执行,要么它就保存等待,即使调用中断线程的方法,也不会生效。
24.为什么notify/notifyAll和wait这3个方法必须放在synchronized代码块或者synchronized方法中?
答:在使用这3个方法时,必须处于synchronized代码块或者synchronized方法中,否则就会抛出IllegalMonitorStateException异常,这是因为调用这几个方法前必须拿到当前对象的监视器monitor对象,也就是说notify/notifyAll和wait方法依赖于monitor对象,在前面的分析中,我们知道monitor 存在于对象头的Mark Word 中(存储monitor引用指针),而synchronized关键字可以获取 monitor ,这也就是为什么notify/notifyAll和wait方法必须在synchronized代码块或者synchronized方法调用的原因。
补充:
需要特别理解的一点是,与sleep方法不同的是wait方法调用完成后,线程将被暂停,但wait方法将会释放当前持有的监视器锁(monitor),直到有线程调用notify/notifyAll方法后方能继续执行,而sleep方法只让线程休眠并不释放锁。同时notify/notifyAll方法调用后,并不会马上释放监视器锁,而是在相应的synchronized(){}/synchronized方法执行结束后才自动释放锁。
25.HashMap在多线程环境下存在线程安全问题,那你一般都是怎么处理这种情况的?
答:一般会使用以下几种方式替代:
- 使用Collections.synchronizedMap(Map)创建线程安全的map集合;
- Hashtable
- ConcurrentHashMap
其中,ConcurrentHashMap,他的性能和效率明显高于前两者。
26.Executors线程池中的一个线程异常了,线程池会怎么处理这个线程?
答:当一个线程池里面的线程异常后:
1.当执行方式是execute时,可以看到堆栈异常的输出。
2.当执行方式是submit时,堆栈异常没有输出。但是调用Future.get()方法时,可以捕获到异常。
3.不会影响线程池里面其他线程的正常执行。
4.线程池会把这个线程移除掉,并创建一个新的线程放到线程池中。
27.线程池的优势?
答:
(1)、降低系统资源消耗,通过重用已存在的线程,降低线程创建和销毁造成的消耗;
(2)、提高系统响应速度,当有任务到达时,通过复用已存在的线程,无需等待新线程的创建便能立即执行;
(3)方便线程并发数的管控,防止OOM。因为线程若是无限制的创建,可能会导致内存占用过多而产生OOM,并且会造成cpu过度切换(cpu切换线程是有时间成本的(需要保持当前执行线程的现场,并恢复要执行线程的现场))。
(4)提供更强大的功能,延时定时线程池。
28.Java线程池的主要参数?
答:
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
} 1、corePoolSize(线程池核心线程数):当向线程池提交一个任务时,若线程池已创建的线程数小于corePoolSize,即便此时存在空闲线程,也会通过创建一个新线程来执行该任务,直到已创建的线程数大于或等于corePoolSize时,(除了利用提交新任务来创建和启动线程(按需构造),也可以通过 prestartCoreThread() 或 prestartAllCoreThreads() 方法来提前启动线程池中的核心线程。)
2、maximumPoolSize(线程池最大大小):线程池所允许的最大线程个数。当队列满了,且已创建的线程数小于maximumPoolSize,则线程池会创建新的线程来执行任务。另外,对于无界队列,可忽略该参数。
3、keepAliveTime(线程存活保持时间)当线程池中线程数大于核心线程数时,线程的空闲时间如果超过线程存活时间,那么这个线程就会被销毁,直到线程池中的线程数小于等于核心线程数。
4、workQueue(任务队列):用于传输和保存等待执行任务的阻塞队列。
5、threadFactory(线程工厂):用于创建新线程。threadFactory创建的线程也是采用new Thread()方式,threadFactory创建的线程名都具有统一的风格:pool-m-thread-n(m为线程池的编号,n为线程池内的线程编号)。
5、handler(线程饱和策略):当线程池和队列都满了,再加入线程会执行此策略。
29.线程池为什么要使用任务队列?
答:1、因为线程若是无限制的创建,可能会导致内存占用过多而产生OOM,并且会造成cpu过度切换。
2、创建线程的消耗较高。
30.线程池中的任务队列为什么要使用阻塞队列?
答:阻塞队列可以保证任务队列中没有任务时阻塞获取任务的线程,使得线程进入wait状态,释放cpu资源。当队列中有任务时才唤醒对应线程从队列中取出消息进行执行。使得在线程不至于一直占用cpu资源。
31.如何配置线程池?
答:
CPU密集型任务
尽量使用较小的线程池,一般为CPU核心数+1。 因为CPU密集型任务使得CPU使用率很高,若开过多的线程数,会造成CPU过度切换。
IO密集型任务
可以使用稍大的线程池,一般为2*CPU核心数。 IO密集型任务CPU使用率并不高,因此可以让CPU在等待IO的时候有其他线程去处理别的任务,充分利用CPU时间。