使用 GitHub Copilot 进行 Prompt Engineering 的初学者指南(译)
文章目录
-
- 什么是 GitHub Copilot ?
- GitHub Copilot 可以自己编码吗?
- GitHub Copilot 的底层是如何工作的?
- 什么是 prompt engineering?
-
- 这是 prompt engineering 的另一个例子
- 使用 GitHub Copilot 进行 prompt engineering 的最佳实践
-
- 提供高级上下文,然后提供更详细的说明
-
- 以下是使用上述技术让 p5.js 建造房屋的示例:
- 提供具体细节
- 提供例子
-
- 零样本学习
- 单样本学习
- 少样本学习
- 不提供示例
- 提供示例
- 附加建议
-
- 迭代你的提示
- 在 IDE 中保持相关文件打开的选项卡
- 给你的 AI 助手一个身份
- 使用可预测模式
- 对描述其用途的变量和函数使用一致的、特定的命名约束
-
- 使用良好的编码实践
- 超越你的编译器
- 开始使用 GitHub Copilot 练习 prompt engineering
- 让我们保持共同学习
- 参考资料
当我开始使用 GitHub Copilot 和其他生成式的 AI tools。我感觉到沮丧,因为我没有收到预期的结果。人们是如何感觉这些工具如此成功的?为什么 AI 工具没有按照我的意愿行事?例如,我让 GitHub Copilot 为我去解决 LeetCode 问题。GitHub Copilot 图标会旋转一表示它正在思考,然后我会收到不一致的建议或跟没本没有建议。我很生气,但是事实证明——我错了!经过更多实验,我提升了跟 GitHub Copilot 的沟通方法,通过以注释和代码的的形式提供上下文、例子和清晰的指令。后来我才知道,这种做法叫做 prompt engineering。在这篇博文中,将讨论充分利用 GitHub Copilot 的重要技巧。
首先,让我们从不熟悉 GitHub Copilot 或 prompt engineering 的人的基础知识开始。
什么是 GitHub Copilot ?
GitHub Copilot 是一个 AI 结对开发工程师被 GitHub 开发并且 GitHub Copilot 由 OpenAI Codex 提供支持,OpenAI CodeX 是 OpenAI 创建生成式预训练语言模型。它根据注释和代码的上下文提供上下文话的代码建议。要使用它,可以在以下 IDEs 安装 Github Copilot 插件:
-
Visual Studio
-
Visual Studio Code
-
Neovim
-
JetBrains IDEs (IntelliJ, PyCharm, WebStorm, etc)
GitHub Copilot 可以自己编码吗?
在 GitHub,使用术语「AI 结对开发程序员」、「AI 助手」和 「Copilot」因为没有开发人员,这个工具就无法工作!事实上,人工智能系统只能执行开发人员编程执行的任务,它们不具备自由意志或独立决策的能力。在这种情况下,GitHub Copilot 利用代码中的上下文和编写的注释来立刻建议代码!借助 GitHub Copilot,可以将注释转换为代码、自动填充重复的代码并显示可选建议。
GitHub Copilot 的底层是如何工作的?
在底层,GitHub Copilot 从注释和代码中抽取上下文,生成逐行建议和整个函数。OpenAI CodeX 是一种机器学习模型,可以将自然语言转换为代码,为 GitHub Copilot 提供支持。
什么是 prompt engineering?
Prompt engineering 是给 AI 模型提供特定指令去产生想要结果的一种实践。提示是可以触发 AI 模型响应的一系列文本或一行代码。可以将这个概念比作收到论文提示。可能会收到一个提示,要求写一篇关于克服挑战的经历的文章,或者写一本经典书籍,例如《了不起的盖茨比》。因此,可以根据所学内容对提示做出响应。大型语言模型或 LLM 的表现与此类似。
这是 prompt engineering 的另一个例子
当学习编程时,我曾参加过一项活动,向机器人指示如何制作三明治。这是一项有趣儿愚蠢的活动,它教会我:
-
计算机只能做你告诉他们做的事情
-
你的指示需要非常具体
-
它们更擅长一步一步接受订单
-
算法只是一系列指令
例如,如果告诉机器人去制作三明治,我需要告诉它:
-
打开面包袋
-
从袋子中取出两片面包
-
将面包并排放在柜台上
-
用黄油刀将花生酱涂在一片面包上
-
等等
如果没有这些明确的指令,机器人可能会做一些愚蠢的事情,例如在两片面包上涂花生酱,或者它可能根本不做任何事情。机器人不知道三明治是什么,也不知道如何制作三明治。它只知道遵循指示。
与此类似,GitHub Copilot 需要清晰的分步说明来生成最有帮助的代码。
接下来,让我们讨论 prompt engineering 的最佳实践,以便向 GitHub Copilot 提供清晰的指令并生成想要的结果。
使用 GitHub Copilot 进行 prompt engineering 的最佳实践
提供高级上下文,然后提供更详细的说明
对我来说最好的技巧是在文件顶部的注释中提供高级上下文,然后以注释和代码的形式提供更详细的说明。
例如,如果构建一个待办事项的应用程序。在顶部,我会注释写到:「使用 Next.js 构建一个待办事项应用程序,允许用户添加、编辑和删除待办事项」。然后在下面几行中,将会编写一条注释来创建:
-
待办事项组件列表,让 GitHub Copilot 在评论下方生成该组件。
-
按钮组件,让 GitHub Copilot 在评论下方生成该组件。
-
输入组件,让 GitHub Copilot 在评论下方生成该组件。
-
添加函数,让 GitHub Copilot 在评论下方生成该函数。
-
编辑函数,让 GitHub Copilot 在评论下方生成该函数。
-
删除函数,让 GitHub Copilot 在评论下方生成该函数。
-
等等
以下是使用上述技术让 p5.js 建造房屋的示例:
在下面的 GIF 中,在顶部写了一条注释,概括性描述了希望 p5.js 绘制的内容。我想画一座白色的房子,有棕色的屋顶、红色的门和红色的烟囱。然后,为房子的每个元素编写注释,然后让 GitHub Copilot 为每个元素生成代码。
提供具体细节
当你提供具体详细信息时,GitHub Copilot 将可以生成更准确的代码建议。例如如果你想要 GitHub Copilot 从 API 查询数据,需要告诉它你想要查询的数据类型、如何处理数据和希望访问的 API endpoint。
这是一个没有指定具体信息的注释,GitHub Copilot 不太可能生成有用的建议:
// Get data from API
function getData() {
//code goes here
}
在上面的例子中,GitHub Copilot 除了函数名以及左右括号之外,没有产生任何内容。
这是一个指定具体信息的注释,GitHub Copilot 更有可能生成有用的建议:
// Pass in user ids and retrieve user data from jsonplaceholder.typicode.com API, then return it as a JSON object
async function getUserData(userId) {
const response = await fetch(`https://jsonplaceholder.typicode.com/users/${userId}`);
const data = await response.json();
return data;
}
提供例子
除了告诉 GitHub Copilot 想要它做什么之外,还可以提供你喜欢的编码风格的例子来向其展示希望它做什么。虽然 GitHub Copilot 使用的 AI 模型已经接受过大量数据的训练,但向 GitHub Copilot 提供示例可以帮助其理解特定代码片段的上下文和约束。向人工智能模型展示希望它们做什么的示例是机器学习中的常见做法。
以下是工程师用来训练人工智能模型的一些方法:
-
零样本学习(Zero-shot learning)
-
单样本学习(One-shot learning)
-
少样本学习(Few-shot learning)
我要求 ChatGPT 像我 5 岁的时候一样想我解释这些方法之间的区别,以下是它给我的内容:
零样本学习
这就像当你看到一个以前从未见过的新玩具,但你知道它是什么,因为它看起来像你见过的其他玩具。例如,如果你见过许多不同种类的毛绒动物,即使你以前从未见过这种动物,你也能够认出一种新的动物。类似的,计算机可以通过使用它对相似事物的了解来对新事物做出有根据的猜测,从而学习识别新事物。
单样本学习
这就像当你第一次看到一个新玩具,你的爸爸和妈妈告诉你玩具叫什么和用途。只要听过一次,你就可以记住它是什么,并且下次看到它时就能认出它。计算机可以学习和识别新事物用同样的方式通过仅展示几个例子并从中学习。
少样本学习
少样本学习就像通过只看几个例子来学习做新事情一样。例如,假设说你想学习如何画一只猫,但你之前只看过几张猫的图片。通过几次学习,即使你以前没有见过很多猫,你仍然可以学习如何画猫。它就像是一种魔力,可以帮助你快速学习新事物,即使你没有很多可供学习的例子。
以下是向 GitHub Copilot 提供示例和不提供示例时,它的回答。
不提供示例
# Create a list of the first 10 prime numbers
primes = []
for num in range(2, 30):
if all(num % i != 0 for i in range(2, num)):
primes.append(num)
print(primes)
在上面的代码片段中,Github Copilot 将准确返回前 10 个数字,但效率低,因为它将循环遍历 2 到 30 之间的所有 29 个数字。通过提供希望 GitHub Copilot 执行的操作的具体示例,可以获得更有效的结果。
提供示例
# Create a list of the first 10 prime numbers
# Example: [2, 3, 5, 7, 11, 13, 17, 19, 23, 29]
primes = []
for num in range(2, 30):
if all(num % i != 0 for i in range(2, num)):
primes.append(num)
if len(primes) == 10:
break
print(primes)
在上面的代码片段中,GitHub Copilot 将返回前 10 个素数并在找到全部 10 个时停止。目标是获得准确但快速的结果,在将其推向正确的方向后,GitHub Copilot 成功实现了这一目标。
附加建议
迭代你的提示
如果初始提示返回了所需的响应,可以删除生成的代码建议,使用更多详细信息和示例编辑评论,然后重试。对于你和 GitHub Copilot 来说,这是一个学习过程。使用它的次数越多,与 GitHub Copilot 沟通的就越顺畅。
在 IDE 中保持相关文件打开的选项卡
目前,GitHub Copilot 无法获取整个代码库的上下文。然而,它可以读取当前的文件以及在 IDE 中打开的任何文件。我发现保留希望 GitHub Copilot 引用的相关文件的选项卡是很有帮助的。例如,当我写一个依赖其他文件变量的函数,我将在 IDE 中保持该文件打开。这将有助于 GitHub Copilot 提供更准确的建议。
给你的 AI 助手一个身份
我从 BitRise 的开发者倡导者 Leilah Simone 收到建议。我尚未使用 GitHub Copilot 尝试此建议,但是这是有用的建议。它有助于控制用户收到的响应类型。在 Leila 的案例中,她要求 ChatGPT 表现的像一名高级的 IOS 工程师。她说:「这帮助她减少了语法和 linting 的问题」。
使用可预测模式
正如我们在上述许多种例子中看到的,GitHub Copilot 将遵循代码中的模式。AI 爱好者和开发者 YK aka CS Dojo ,分享了他如何利用这一点来发挥自己的优势:
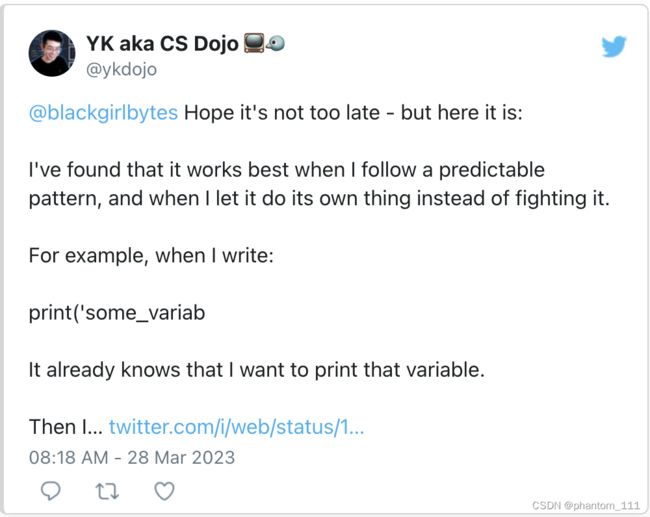
对描述其用途的变量和函数使用一致的、特定的命名约束
声明变量或函数时,使用指定用于变量用途的名称。这将帮助 GitHub Copilot 了解变量的上下文并生成更多相关建议。例如,不要使用「value」等通用变量名称,而应使用「input_string」或 「output_file」。
GitHub Copilot 还将使用在代码中使用的命名约定。例如,如果使用驼峰式命名变量,GitHub Copilot 将建议驼峰式命名变量。如果你使用 snake_case 作为变量,GitHub Copilot 将建议 snake_case 变量。
使用良好的编码实践
虽然 GitHub Copilot 可以作为生成代码建议的强大工具,但请务必注意,它并不能取代你自己的编程技能和专业知识。人工智能模型的好坏取决于它们所训练的数据,因此,重要的是使用这些工具作为辅助工具,而不是完全依赖它们。我鼓励 GitHub Copilot 的每个用户:
-
review 代码
-
运行单元测试、集成测试和任何其他形式的测试代码
-
手动测试代码以确保其按预期工作
-
并使用良好的编码实践,因为 GitHub Copilot 将遵循你的编码风格和模式作为其建议的指南
超越你的编译器
当前,GitHub Copilot 是最流行的 IDE 中的提供的扩展插件。还有 GitHub Copilot Labs,这是一个可通过 GitHub Copilot 访问的单独实验性扩展。Copilot Labs 可以帮助翻译、调试、测试、记录和重构代码。此外,还退出了 Copilot X,这是一套可以提高 IDE 之外的开发人员工作效率的功能。Copilot X 包括:
- Copilot for Docs - 使开发人员免于搜寻大量的文档。
- Copilot for Pull Requests - 帮助编写更好的 PR 描述并帮助团队更好的快速审查和合并 PR
- Copilot Chat - 在编辑器中通过 GitHub Copilot 聊天获得类似的 ChatGPT 的体验
- Copilot for CLI - 帮助记住 Shell 命令和标志,以编更快地在终端运行命令
- Copilot Voice - 编写和编辑代码、浏览代码库以及用语音控制 Visual Studio Code
Copilot X 功能/产品目前处于技术预览阶段。如果想要使用上述功能之一,可以在 https://github.com/features/preview/copilot-x 上注册等待名单。
开始使用 GitHub Copilot 练习 prompt engineering
了解如何最佳使用 GitHub 的最佳方法就是开始使用它,可以在此处注册访问 GitHub Copilot https://github.com/features/copilot
如果你是企业领导者并且希望让团队访问 GitHub Copilot,可以在此处注册 GitHub Copilot https://github.com/github-copilot/business_signup/choose_business_type
让我们保持共同学习
感谢阅读本篇博文。我很想听听你的消息!我还在学习更多关于人工智能、GitHub Copilot、和 prompt engineering 的知识。如果是是 GitHub Copilot 的粉丝并且已经学会如何使用它来改进开发人员工作流程,可以在下面的评论中分享一些你的技巧。
另外,可以查看以下更多的资源了解有关 prompt engineering 的更多信息
-
How to get Codex to produce the code you want
-
Prompt Design from OpenAI
-
Prompt Engineering 101: Introduction to Codex
-
Prompt Engineering Guide by Elvis Saravia
参考资料
- A Beginner’s Guide to Prompt Engineering with GitHub Copilot - DEV Community