SQL必备基础知识
青铜
1、数据库技术的根本目标是:数据共享
2、在SQL语言中,子查询是嵌入到另一个查询语句之中的查询语句。
3、主键约束是确保表中每一行记录是唯一的,一个表只能设置一个主键,主键的值不能重复但能为空(null)。
4、数据库中事务的四大特性(ACID):Atomic(原子性)、Consistency(一致性)、Isolation(隔离性)和Durability(持久性)。
白银
1、防止 SQL 注入的方式
(1)开启配置文件中的 magic_quotes_gpc 和 magic_quotes_runtime 设置;
(2)执行 sql 语句时使用addslashes 进行 sql 语句转换;
(3)Sql 语句书写尽量不要省略双引号和单引号;
(4)过滤掉 sql 语句中的一些关键词:update、insert、delete、select、 * ;
(5) 提高数据库表和字段的命名技巧,对一些重要的字段根据程序的特点命名,取不易被猜到的;
(6)PHP 配置文件中设置 reGISter_globals 为 off,关闭全局变量注册;
(7) 控制错误信息,不要在浏览器上输出错误信息,将错误信息写到日志文件中;
(8)可以使用 waf 防护系统进行防护;
2、NOW()和CURRENT_DATE()的区别
(1)NOW()命令用于显示当前年份,月份,日期,小时,分钟和秒;
(2)CURRENT_DATE()仅显示当前年份,月份和日期;
3、表约束包括列约束(表约束+NOTNULL)和表约束(PRIMARYKEY、foreignkey、check、UNIQUE)。
4、在缺省模式下,MYSQL是autocommit模式的,所有的数据库更新操作都会即时提交,所以在缺省情况下,mysql是不支持事务的。
5、数据库中db、dbms和dbs三者之间的关系
DBS包括DB和DBMS;数据库系统DBS是一个通称,包括数据库DB、数据库管理系统DBMS、数据库管理人员DBA等的统称,是最大的范畴。
6、ER图是数据库设计的什么阶段(第二)
数据库设计通常分为6个阶段:
(1)需求分析:分析用户的需求,包括数据、功能和性能需求;
(2)概念结构设计:主要采用ER模型进行设计,包括画ER图;
(3)逻辑结构设计:通过将ER图转换成表,实现从ER模型到关系模型的转换;
(4)数据库物理设计:主要是为所设计的数据库选择合适的存储结构和存取路径;
(5)数据库的实施:包括编程、测试和试运行;
(6)数据库运行与维护:系统的运行与数据库的日常维护。
7、Sql中的like用法
(1)%:包含零个或多个字符的任意字符串;
(2)_(下划线):任何单个字符;
(3)查找 emp表中所有电话号码phone_no的以1或3开头,第三位为0的电话号码的SQL语句:SELECT phone_no FROM emp WHERE phone_no LIKE ‘[1,3]_0%’
8、视图的作用
(1)视图能够简化用户的操作;
(2)视图使用户能以多种角度看待同一数据;
(3)视图对重构数据库提供了一定程度的逻辑独立性;
(4)视图能够对机密数据提供安全保护;
(5)适当的利用视图可以更清晰的表达查询;
9、主键和候选键的区别:
(1)主键也是候选键;
(2)按照惯例,候选键可被指定为主键,并且可以用于任何外键引用;
(3)表格的每一行都由主键唯一标识,一个表只有一个主键;
10、关系型数据库和非关系型数据库对比:
(1)关系型数据库包括:Oracle、DB2、Microsoft SQL Server、Microsoft Access、MYSQL等;
(2)非关系型数据库包括:mongodb、cassandra、redis、hbase、neo4j;
(3)使用场景:关系型数据库适用于关系特别复杂的数据库查询场景;
(4)"事务"特性:关系型数据库对事务支持的非常完善,二非关系型数据库则不支持;
(5)成本:Nosql数据库简单易部署,基本都是开源软件,不需要像使用Oracle那样花费大量成本购买使用,相比关系型数据库价格便宜。
(6)查询速度:Nosql数据库将数据存储于缓存之中,而且不需要经过SQL层的解析,关系型数据库将数据存储在硬盘中,自然查询速度远不及Nosql数据库。
(7)存储数据的格式:Nosql的存储格式是key,value形式、文档形式、图片形式等等,所以可以存储基础类型以及对象或者是集合等各种格式,而数据库则只支持基础类型。
(8)扩展性:关系型数据库有类似join这样的多表查询机制的限制导致扩展很艰难。Nosql基于键值对,数据之间没有耦合性,所以非常容易水平扩展。
(9)持久存储:Nosql不使用于持久存储,海量数据的持久存储,还是需要关系型数据库
(10)数据一致性:非关系型数据库一般强调的是数据最终一致性,不像关系型数据库一样强调数据的强一致性,从非关系型数据库中读到的有可能还是处于一个中间态的数据。
11、关系型数据库不擅长的处理:
(1)大量数据的写入处理;
(2)为有数据更新的表做索引或表结构(schema)变更;
(3)字段不固定时应用;
(4)对简单查询需要快速返回结果的处理;
12、非关系型数据库可以分为键值(Key-Value)存储数据库、 列存储(Column-oriented)数据库、 面向文档(Document-Oriented)数据库和图形(Graph)数据库。
黄金级
1、列的字符串类型可以是SET、BLOB、ENUM、CHAR、TEXT。
2、SQL标准定义的四个隔离级别
(1)未提交读(Read uncommitted)
(2)提交读(Read committed)
(3)可重复读(Repeatable read)
(4)可串行化(Serializable)
3、锁的优化策略包括
(1)读写分离 ;
(2)分段加锁 ;
(3)减少锁持有的时间 ;
(4)多个线程尽量以相同的顺序去获取资源 ;
(5)不能将锁的粒度过于细化,不然可能会出现线程的加锁和释放次数过多,反而效率不如一次加一把大锁;
4、数据库常见故障:事务故障、系统故障、介质故障。
5、SQL语句中,关于 drop、truncate和delete的用法:
(1)delete删除表的部分或者所有数据。delete from table_name [where...] [order by...] [limit...],delete语句执行删除的过程是每次从表中删除一行,并且同时将该行的删除操作作为事务记录在日志中保存 以便进行进行回滚操作;
(2)truncate删除表中所有数据,不能加where条件,truncate [table] table_name,释放空间但不删除定义(保留表的数据结构);
(3)drop 和前两个命令只删除表的行数据不同,drop 会把整张表的行数据和表结构一起删除掉DROP [TEMPORARY] TABLE [IF EXISTS] tbl_name [,tbl_name];
三者的区别:
(1)delete 可以恢复删除的数据,而 truncate 和 drop 不能恢复删除的数据;
(2)执行速度:drop > truncate > delete;
(3)drop 是删除整张表,包含行数据和字段、索引等数据,而 truncate 和 drop 只删除了行数据;
(6)delete 可以使用 where 表达式添加查询条件,而 truncate 和 drop 不能添加 where 查询条件 ;
(7)在 InnoDB 引擎中,truncate 可以重置自增列,而 delete 不能重置自增列;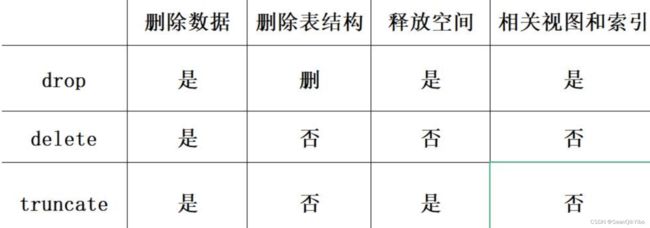
6、MySQL中的3种锁:
锁是计算机协调多个进程或纯线程并发访问某一资源的机制,MySQL的锁机制相比于其他数据库更简单,其最显著的特点是不同的存储引擎支持不同的锁机制。比如,MyISAM和MEMORY存储引擎采用的是表级锁(table-level locking)。InnoDB存储引擎既支持行级锁(row-level locking),也支持表级锁,但默认情况下是采用行级锁。
(1)表级锁:开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低;
(2)行级锁:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高;
(3)页面锁:开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般;
7、数据库中的varchar(50)与char(50)区别:varchar为可变的,char为不可变。当这两个字段同时存入“teacher”时,实际占用字节分别为7,50。
8、如果一个表有一列定义为TIMESTAMP,每当行被更改时,时间戳字段将获取当前时间戳。
9、能够赋予用户teacher查询数据库Score中所有表数据权限的是grant select on Score.* to teacher。
10、事务有关的描述;
(1)事务就是被绑定在一起作为一个逻辑工作单元的SQL语句分组;
(2)如果任何一个语句操作失败那么整个操作就被失败,以后操作就会回滚到操作前状态,或者是上有个节点;
(3)为了确保要么执行,要么不执行,就可以使用事务;
(4)要将有组语句作为事务考虑,就需要通过ACID测试,即原子性,一致性,隔离性和持久性;
11、范式
对于数据库中关系的不同的规范化程度可以使用“范式”来衡量,称为“NF”。目前关系数据库有六种范式,满足最低要求的范式是第一范式(1NF),一般数据库只需满足第三范式(3NF)就行了。
(1)第一范式(1NF):数据库表的每一列都是不可分割的基本数据项,同一列中不能有多个值或者重复的值,不满足第一范式(1NF)的数据库就不是关系数据库;
(2)第二范式(2NF):确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言);第二范式就是非主属性部分依赖于主关键字;
(3)第三范式(3NF):要求一个数据库表中不包含已在其它表中已包含的非主关键字信息。第三范式就是属性不依赖于其它非主属性;
12、关于NULL的说法:
(1)NULL不表示“”(空字符串);
(2)NULL这个值表示UNKNOWN(未知) ;
(3)对NULL这个值的任何比较都会产生一个NULL值;
(4)使用IS NULL来进行NULL判断 ;
13、以下设置了索引但无法使用:
(1)以“%”开头的 LIKE 语句,模糊匹配 ;
(2)OR 语句前后没有同时使用索引 ;
(3)数据类型出现隐式转化(如 varchar 不加单引号的话可能会自动转换为 int 型);
14、视图是一种虚拟的表,具有和物理表相同的功能;游标是对查询出来的结果集作为一个单元来有效处理。
15、主键、外键、索引
(1)主键primary key ,是由表中的一个或者多个字段构成,主键不能重复,不能为空。主键本身也是一种索引,使用主键,数据库会自动创建主键索引。每个数据表中只有一个主键。 ;
(2)外键foreign key ,是用来与其他表建立联系的,使数据保持一致性和完整性。建立外键的列必须与主键字段类型相同,只有他表的主键才能作为本表的外键。一个表可以有多个外键,外键数据可以重复,也可以为空。使用外键,数据库会自动创建外键索引 ;
(3)索引index ,唯一索引可以保证数据记录的唯一性,可以有多个,单一索引是建立在一列上的索引,复合索引是建立在两个或多个列上的索引,索引可以提高查询的效率,但会降低增删查改操作的效率。对于dml操作比较频繁的表,索引的个数不宜太多;
16、主键索引和唯一索引的区别
(1)主键一定会创建一个唯一索引,但是有唯一索引的列不一定是主键;
(2)主键不允许为空值,唯一索引列允许空值;
(3)一个表只能有一个主键,但是可以有多个唯一索引;
(4)主键可以被其他表引用为外键,唯一索引列不可以;
(5)主键是一种约束,而唯一索引是一种索引,是表的冗余数据结构,两者有本质的差别;
17、mybatis中#{}和${}的区别
(1)#{}是占位符,可以防止SQL注入的风险(语句的拼接);
(2)${}是sql拼接符号,$无法防止Sql注入,一般用于传入数据库对象,例如传入表名;
(3)一般能用#的就别用$。MyBatis排序时使用order by 动态参数时需要注意,用$而不是#;
18、优化MySQL的方法:
(1)建立索引;
(2)优化查询语句;
(3)选取最适用的字段属性,尽可能减少定义字段宽度,尽量把字段设置NOT NULL;
(4)数据库表结构的优化;
(5)系统配置的优化;
19、SQL注入漏洞产生的原因?如何防止
程序开发过程中不注意规范书写sql语句和对特殊字符进行过滤,导致客户端可以通过全局变量POST和GET提交一些sql语句正常执行
(1)采用预编译语句集,它内置了处理SQL注入的能力,只要使用它的setString方法传值即可;
(2)采用正则表达式将包含有 单引号('),分号(;) 和 注释符号(--)的语句给替换掉来防止SQL注入;
20、sql注入的主要特点和危害
变种极多,攻击简单,危害极大
(1)未经授权操作数据库的数据;
(2)恶意纂改网页;
(3)私自添加系统账号或者是数据库使用者账号;
21、union 与union all的区别
(1)union 在进行表链接后会筛选掉重复的记录,所以在表链接后会对所产生的结果集进行排 序运算,删除重复的记录再返回结果;
(2)union all 则会显示重复结果,只是简单的两个结果合并并返回.所以效率比union高,在保证没有重复数据的情况下用union all;
22、数据库中的乐观锁和悲观锁根据不同类型可以对数据设置不同的锁权限
(1)悲观锁 :假定会发生并发冲突,屏蔽任何违反数据完整的操作;
(2)乐观锁 :假定不会发生冲突,只有在提交操作时检查是否违反数据的完整性;