《深度探索c++对象模型》第四章笔记
非原创,在学习
4 Function语意学( The Semantics of Function )
假如有一个Point3d的指针和对象:
Point3d obj;
Point3d* ptr = &obj;这样做
obj.normalize();
ptr->normalize();时,会发生什么事?其中的Point3d::normalize()定义如下:
Point3d
Point3d::normalize() const
{
// magnitude是一个函数,magnitude (Read Only)返回向量的长度,
// 也就是点P(x,y,z)到原点(0,0,0)的距离
register float mag = magnitude();
Point3d normal;
normal._x = _x / mag;
normal._y = _y / mag;
normal._z = _z / mag;
return normal;
}其中Point3d::magnitude ()又定义如下:
float Point3d::magnitude() const
{
return sqrt(_x * _x + _y * _y + _z * _z);
}答案是:不知道!C++支持三种类型的 member functions: static、nonstatic和virtual,每一种类型被调用的方式都不相同。其间差异正是下一节的主题。不过,我们虽然不能够确定normalize()和magnitude()两函数是否为virtual或nonvirtual,但可以确定它一定不是 static,原因有二:(1)它直接存取nonstatic数据;(2)它被声明为const。是的,static mermber functions不可能做到这两点。
4.1 Member 的各种调用方式
virtual函数是20世纪80年代中期被加进来的;
Static member functions是最后被引人的一种函数类型。它们在1987年的Usenix C++研讨会的厂商研习营(Implementor's Workshop)中被正式提议加人C++中,并由 cfront 2.0实现出来.
Nonstatic Member Functions(非静态成员函数)
C++的设计准则之一就是:nonstatic member function至少必须和一般的nonmember function 有相同的效率。也就是说,如果我们要在以下两个函数之间作选择:
float magnitude3d(const Point3d* _this) { }
float Point3d::magnitude3d() const { }那么选择member function不应该带来什么额外负担。这是因为编译器内部已将“member函数实体”转换为对等的“nonmember函数实体”。
举例:
float magnitude3d(const Point3d* _this) {
return sqrt(_this->_x * _this->_x +
_this->_y * _this->_y +
_this->_z * _this->_z);
}乍见之下似乎nonmember function比较没有效率,它间接地经由参数取用坐标成员,而member function 却是直接取用坐标成员.然而实际上 member function被内化为nonmember的形式。下面就是转化步骤:
1 改写函数的signature以安插一个额外的参数到member function中,用以提供一个存取管道,是class object得以调用该函数,该额外参数被称为this指针:
// non-const nonstatic member之增长过程
Point3d
Point3d::magnitude(Point3d* const this)如果member function是const,则变成:
// const nonstatic member之扩张过程
Point3d
Point3d::magnitude(const Point3d* const this)就是加形参:
(1)如果是普通(非静态、非const)成员函数,加Point3d* const this这个参数
(2)如果是const成员函数,加const Point3d* const this这个参数
2 将每一个“对nonstatic data member的存取操作”改为经由this指针来存取:
{
return sqrt(_this->_x * _this->_x +
_this->_y * _this->_y +
_this->_z * _this->_z);
}3.将member function重新写成一个外部函数.对函数名称进行“mangling”处理,使它在程序中成为独一无二的语汇:
Name Mangling 是一种在编译过程中,将函数、变量的名称重新改编的机制
extern magnitude__7Point3dFv(
register Point3d *const this);现在这个函数已经被转换好了,而其每一个调用操作也都必须转换。于是:
obj.magnitude();变成了
magnitude__7Point3dFv(&obj);而
ptr->magnitude();变成了
magnitude__7Point3dFv(ptr);本章一开始所提及的normalize()函数会被转化为下面的形式,其中假设已经声明有一个Point3d copy constructor,而named returned value (NRV)的优化也已施行:
// C++伪码
void
normalize__7Point3dFv(register const Point3d* const this,
Point3d& _result)
{
// magnitude是一个函数,magnitude (Read Only)返回向量的长度,
// 也就是点P(x,y,z)到原点(0,0,0)的距离
register float mag = this->magnitude();
_result.Point3d Point3d();
_result._x = this->_x / mag;
_result._y = this->_y / mag;
_result._z = this->_z / mag;
return ;
}一个比较有效率的做法是直接建构“normal”值,像这样:
Point3d
Point3d::normalize() const
{
register float mag = magnitude();
return Point3d(_x / mag, _y / mag, _z / mag);
}它会被转化为以下的码(我再一次假设Point3d的copy constructor已经声明好了,而NRV的优化也已实施):
// C++伪码
void
normalize__7Point3dFv (register const Point3d* const this,
Point3d& _result)
{
register float mag = this->magnitude();
// _result用以取代返回值
_result.Point3d::Point3d(this->_x / mag, this->_y / mag, this->_z / mag);
return;
}这可以节省default constructor初始化所引起的额外负担。
名称的特殊处理( Name Mangling )
由于member functions可以被重载化 ( overloaded),所以需要更广泛的mangling手法,以提供绝对独一无二的名称。
为了让它们独一无二,唯有再加上它们的参数链表(可以从函数原型中参考得到)。如果把参数类型也编码进去,就一定可以制造出独一无二的结果,使我们的两个x()函数有良好的转换。
Virtual Member Functions(虚拟成员函数)
如果normalize()是一个virtualmember function,那么以下的调用:
ptr->normalize();将会被内部转化为:
(*ptr->vptr[1])(ptr);其中:
- vptr表示由编译器产生的指针,指向 virtual table.它被安插在每一个“声明有(或继承自)一个或多个virtual functions”的class object中。事实上其名称也会被“mangled”,因为在一个复杂的 class 派生体系中可能存在有多个vptrs.
- 1是virtual table slot的索引值,关联到normalize()函数
- 第二个ptr表示this指针.
类似的道理,如果magnitude()也是一个virtual function,它在normalize()之中的调用操作将被转换如下:
// register float mag = magnitude();
register float mag = (*this->vptr[2])(this);此时,由于Point3d::magnitude()是在 Point3d:.normalize()中被调用,而后者已经由虚拟机制而决议((resolved)妥当,所以明确地调用“Point3d实体”会比较有效率,并因此压制由于虚拟机制而产生的不必要的重复调用操作:
// 明确的调用操作会压制虚拟机机制
register float mag = Point3d::magnitude();如果magnitude(声明为inline函数会更有效率。使用class scope operator明确调用一个virtual function,其决议(resolved)方式会和nonstatic member function一样:
register float mag = magnitude__7Point3dFv(this);对于以下调用:
// Point3d obj;
obj.normalize();如果编译器把它转换为:
(*obj.vptr[1])(&obj);虽然语意正确,却没有必要。请回忆那些并不支持多态( polymorphism)的对象( 1.3节)。所以上述经由obj 调用的函数实体只可以是 Point3d::normalize() ,“经由一个 class object调用一-个virtual function”,这种操作应该总是被编译器像对待一般的nonstatic member function 一样地加以决议(resolved) :
normalize__7Point3dFv(&obj);这项优化工程的另一利益是,virtual function的一个inline函数实体可以被扩展( expanded)开来,因而提供极大的效率利益。
Static Member Functions(静态成员函数)
如果 Point3d::normalize()是一个static member function,以下两个调用操作:
obj.normalize();
ptr->normalize();将被转换为一般的nonmember函数调用,像这样:
// obj.normalize();
normalize()__7Point3dSFv();
// ptr->normalize();
normalize()__7Point3dSFv();在C++引入static member funtions之前,很少看到下面这种写法:
((Point3d*)0)->object_count();其中的object_count()只是简单回传_object_count这个static data member。
在引人static member functions之前,C++语言要求所有的 member functions都必须经由该class 的object来调用。而实际上,只有当一个或多个nonstaticdata members在 member function中被直接存取时,才需要class object。Class object提供了this指针给这种形式的函数调用使用。这个this指针把在member function中存取的 nonstatic class members”绑定于“object内对应的members”之上,如果没有任何一个members被直接存取,事实上就不需要this指针,因此也就没有必要通过一个class object来调用一个member function。不过C++语言到当前为止并不能够识别这种情况。
这么一来就在存取static data members时产生了一些不规则性。如果class的设计者把static data member声明为nonpublic(这一直被视为是一种好的习惯),那么他就必须提供一个或多个member functions来存取该member。因此,虽然你可以不靠class object来存取一个static member,但其存取函数却得绑定于一个class object之上。
至于语言层面上的解决之道,是由 cfront 2.0所引入的static member functions。Static member functions的主要特性就是它没有this指针。以下的次要特性统统根源于其主要特性:
- 它不能够直接存取其class 中的nonstatic members.
- 它不能够被声明为const、 volatile或virtual。
- 它不需要经由class object才被调用——虽然大部分时候它是这样被调用的!
如果取一个static member function的地址,获得的将是其在内存中的位置,也就是其地址。由于static member function没有this指针,所以其地址的类型并不是一个“指向 class member function的指针”,而是一个“nonmember函数指针”。也就是说:
&Point3d::object_count();会得到一个数值,类型是:
unsigned int(*)();而不是:
unsigned int(Point3d::*)();Static member function由于缺乏this指针,因此差不多等同于nonmember function。它提供了一个意想不到的好处:成为一个callback 函数,使我们得以将C++和 C-based x Window 系统结合(请看[YOUNG95]中的讨论).它们也可以成功地应用在线程(( threads)函数身上(请看[SCHMIDT94a]) 。
4.2 Virtual Member Functions(虚拟成员函数)
前面已经看过了virtual function 的一般实现模型:每一个class有一个virtual table,内含该class之中有作用的 virtual function 的地址,然后每个object有一个vptr,指向 virtual table的所在。在这一节中,将细部上探究这个模型。
为了支持virtual function机制,必须首先能够对于多态对象有某种形式的“执行期类型判断法(runtime type resolution) ”。也就是说,以下的调用操作将需要ptr在执行期的某些相关信息,
ptr->z();或许最直接了当但是成本最高的解决方法就是把必要的信息加在 ptr身上。在这样的策略之下,一个指针(或是一个reference)含有两项信息:
- 它所参考到的对象的地址(也就是当前它所含有的东西)﹔
- 对象类型的某种编码,或是某个结构(内含某些信息﹐用以正确决议出z()函数实例)的地址。
这个方法带来两个问题,第一,它明显增加了空间负担,即使程序并不使用多态( polymorphism) ;第二,它打断了与C程序间的链接兼容性。
如果这份额外信息不能够和指针放在一起,下一个可以考虑的地方就是把它放在对象本身。但是哪一个对象真正需要这些信息呢?我们应该把这些信息放进可能被继承的每一个聚合体身上吗?或许吧!但请考虑一下这样的C struct声明:
struct data { int m, d, y; };严格地说,这符合上述规范。然而事实上它并不需要那些信息。加上那些信息将使C struct 膨胀并且打破链接兼容性,却没有带来任何明显的补偿利益.
“好吧,”你说,“只有面对那些明确使用了 class关键词的声明,才应该加上额外的执行期信息.”这么做就可以保留语言的兼容性了,不过仍然不是一个够聪明的政策。举个例子,下面的class符合新规范:
class date { public: int n, d, y; };但实际上它并不需要那份信息。下面的class声明虽然不符合新规范,却需要那份信息:
struct geom { public: virtual ~geom(); };在C++中,多态( polymorphism)表示“以一个public base class的指针(或reference),寻址出一个derived class object”的意思。例如下面的声明:
Point* ptr;我们可以指定ptr以寻址出一个Point2d对象:
ptr = new Point2d;
ptr = new Point3d;ptr的多态机能主要扮演一个输送机制( transport mechanism)的角色,经由它,我们可以在程序的任何地方采用一组public derived 类型。这种多态形式被称为是消极的( passive),可以在编译时期完成——virtual base class的情况除外。
当被指出的对象真正被使用时,多态也就变成积极的 ( active)了.下面对于virtual function的调用,就是一例:
// 积极多态的常见例子
ptr->z();在runtime type identification (RTTI)性质于1993年被引入C++语言之前,C++对“积极多态( active polymorphism)”的唯一支持,就是对于virtual functioncall 的决议(resolution)操作。有了RTTI,就能够在执行期查询一个多态的pointer或多态的reference 了 (RTTI将在本书7.3节讨论)。
// 积极多态的第二个例子
if (Point3d* p3d = dynamic_cast(ptr)) {
return p3d->_z;
} 所以,问题已经被区分出来,那就是:欲鉴定哪些classes展现多态特性,我们需要额外的执行期信息。一如我所说,关键词class和struct并不能够帮助我们.由于没有导入如polymorphic 之类的新关键词,因此识别一个class是否支持多态,唯一适当的方法就是看看它是否有任何virtual function。只要 class 拥有一个virtual function,它就需要这份额外的执行期信息。
下一个明显的问题是,什么样的额外信息是我们需要存储起来的?也就是说,如果我有这样的调用:
ptr->z();其中z()是一个virtual function,那么什么信息才能让我们在执行期调用正确的z()实体?需要知道:
- ptr所指对象的真实类型。这可使我们选择正确的 z()实体;
- z()实体位置,以便我能够调用它。
在实现上,首先我可以在每一个多态的 class object身上增加两个members:
1.一个字符串或数字,表示class 的类型;
2.一个指针,指向某表格,表格中带有程序的 virtual functions的执行期地址。
表格中的 virtual functions地址如何被建构起来?在C++中,virtual functions(可经由其 class object被调用)可以在编译时期获知,此外,这一组地址是固定不变的,执行期不可能新增或替换之。由于程序执行时,表格的大小和内容都不会改变,所以其建构和存取皆可以由编译器完全掌握,不需要执行期的任何介入。
然而,执行期备妥那些函数地址,只是解答的一半而已。另一半解答是找到那些地址。以下两个步骤可以完成这项任务:
1.为了找到表格,每一个class object被安插上一个由编译器内部产生的指针,指向该表格。
2.为了找到函数地址,每一个virtual function被指派一个表格索引值。
一个class 只会有一个virtual table。每一个table内含其对应的 class object中所有active virtual functions函数实体的地址。这些active virtual functions包括
- 这个class所定义的函数实体。它会改写( overriding) 一个可能存在的base class virtual function函数实体。
- 继承自 base class的函数实体。这是在derived class决定不改写virtualfunction时才会出现的情况。
- 一个pure_virtual_called()函数实体﹐它既可以扮演pure virtual function的空间保卫者角色,也可以当做执行期异常处理函数(有时候会用到)
每一个virtual function都被指派一个固定的索引值,这个索引在整个继承体系中保持与特定的 virtual function的关联。例如在我们的Point class体系中:
class Point {
public:
virtual ~Point();
virtual Point& mult(float) = 0;
// 其它操作...
float x() const { return x; }
virtual float y() const { return 0; }
virtual float z() const { return 0; }
// ...
protected:
Point(float x = 0.0);
float _x;
};virtual destrtcior被赋值slot 1,而mult()被赋值slot 2。此例并没有mult()的函数定义(泽注:因为它是一个 pure virtual function),所以 pure_virtual_called()的函数地址会被放在 slot 2中。如果该函数意外地被调用,通常的操作是结束掉这个程序。y()被赋值 slot 3 而z()被赋值 slot 4。x()的 slot是多少?答案是没有,因为x()并非virtual function。图4.1表示 Point的内存布局和其virtual table.
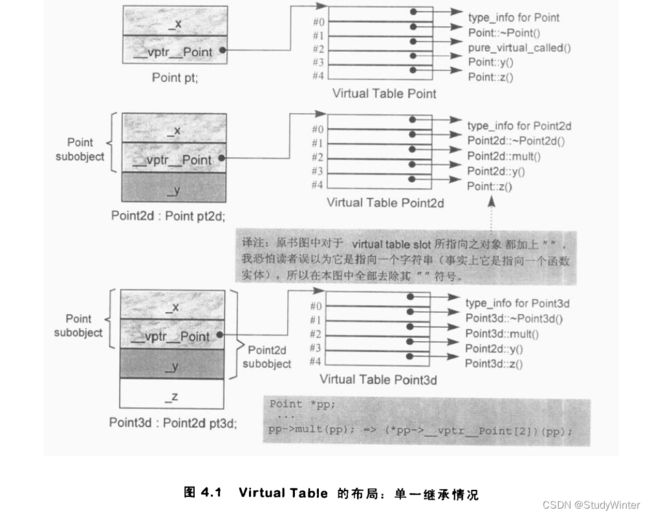
当一个class派生自Point时,会发生什么事?例如class Point2d:
class Point2d : public Point {
public:
Point2d(float x = 0.0, float y = 0.0)
: Point(x), _y(y) { }
~Point2d();
// 改写Base class virtual functions
Point2d& mult(float);
float y() const { return _y; }
// 其它操作
protected:
float _y;
};一共有三种可能性:
- 它可以继承 base class所声明的virtual functions的函数实体.正确地说,是该函数实体的地址会被拷贝到derived class 的virtual table 相对应的 slot 之中.
- 它可以使用自己的函数实体。这表示它自己的函数实体地址必须放在对应的slot之中.
- 它可以加人一个新的 virtual function。这时候virtual table 的尺寸会增大一个slot,而新的函数实体地址会被放进该slot之中.
Point2d 的virtual table 在 slot 1中指出 destructor,而在 slot 2中指出mult()取代pure virtual function).它自己的y()函数实体地址放在 siot 3,继承自Point 的 z()函数实体地址则放在slot 4.
类似的情况,Point3d派生自Point2d ,如下:
class Point3d : public Point2d {
public:
Point3d(float x = 0.0, float y = 0.0, float z = 0.0)
: Point2d(x, y), _z(z) {}
~Point3d();
// 改写base class virtual functions
Point3d& mult(float);
float z() const { return _z; }
// 其它操作...
protected:
float _z;
};其virtual table中的 slot 1放置Point3d 的destructor ,slot 2放置Point3d:mult()函数地址。 slot 3放置继承自Point2d 的 y()函数地址,slot 4放置自己的z()函数地址。
如果有这样的案例
ptr->z();那么,我如何有足够的知识在编译时期设定virtual function的调用呢?
- 一般而言,我并不知道ptr所指对象的真正类型。然而我知道,经由 ptr可以存取到该对象的virtual table.
- 虽然我不知道哪一个 z()函数实体会被调用,但我知道每一个 z()函数地址都被放在slot 4
这些信息使得编译器衍以将该调用转化为:
(*ptr=>vptr[4])(ptr);在这个转化中,vptr表示编译器所安的指针,指向 virtual table; 4表示z()被赋值的slot编号(关联到Point体系的 virtual table).唯一一个在执行期才能知道的东西是: slot 4所指的到底是哪一个z(函数实体?
在一个单一继承体系中,virtual function机制的行为十分良好,不但有效率而且很容易塑造出模型来。但是在多重继承和虚拟继承之中,对virtual functions的支持就没有那么美好了。
多重继承下的 Virtual Functions
在多重继承中支持virtual functions,其复杂度围绕在第二个及后继的 base classes身上,以及“必须在执行期调整this指针”这一点。以下面的 class 体系为例:
namespace Test15
{
class Base1
{
public:
Base1();
virtual ~Base1();
virtual void speakClearly();
virtual Base1 *clone() const;
protected:
float data_base1;
};
class Base2
{
public:
Base2();
virtual ~Base2();
virtual void mumble();
virtual Base2 *clone() const;
protected:
float data_base2;
};
class Derived : public Base1, public Base2
{
public:
Derived();
virtual ~Derived();
virtual Derived *clone() const;
protected:
float data_Derived;
};
}
我的编译环境是vs code + gcc version 8.1.0 (x86_64-win32-seh-rev0, Built by MinGW-W64 project)
可以编译成功

有三个问题需要解决,以此例而言分别是(1) virtual destructor,(2)被继承下来Base2::mumble(),(3)一组clone()函数实体。依次解决每一个问题。
首先,把一个从 heap中配置而得的Derived对象的地址,指定给一个Base2指针:
Base2 *pbase2 = new Derived;新的Derived 对象的地址必须调整,以指向其Base2 subobject。编译时期会产生以下的码:
Derived* temp = new Derived;
Base2* pbase2 = temp ? temp + sizeof(Base1) : 0;如果没有这样的调整,指针的任何“非多态运用”(像下面那样)都将失败:
// 即使pbase2被指向一个Derived对象,这也没有问题
pbase2->data_Base2;当程序员要删除pbase2所指的对象时:
// 必须首先调用正确的virtual destructor函数实体
// 然后实施delete运算符
// pbase2可能需要调整,以指出完整对象的起始点
delete pbase2;指针必须被再一次调整,以求再一次指向 Derived对象的起始处(推测它还指向Derived对象)。然而上述的 offset加法却不能够在编译时期直接设定,因为pbase2所指的真正对象只有在执行期才能确定。
一般规则是,经由指向“第二或后继之base class”的指针(或reference)来调用derived class virtual function。
Base2* pbase = new Derived;
// ...
delete pbase2;该调用操作所连带的“必要的 this指针调整”操作,必须在执行期完成。也就是说,offset的大小,以及把offset加到this 指针上头的那一小段程序代码.必须由编译器在某个地方插入。问题是,在哪个地方?
Bjarne原先实施于cfront编译器中的方法是将virtual table加大,使它容纳此处所需的this指针,调整相关事物。每一个virtual table slot,不再只是一个指针,而是一个聚合体,内含可能的 offset以及地址。于是virtual function的调用操作由:
(*pbase2->vptr[1])(pbase2);改为
(*pbase2->vptr[1].faddr)
(pbase2 + pbase2->vptr[1].offset);其中faddr 内含virtual function 地址,offset内含this指针调整值。
这个做法的缺点是,它相当于连带处罚了所有的 virtual function调用操作.不管它们是否需要offset的调整。我所谓的处罚,包括offset的额外存取及其加法,以及每一个virtual table slot的大小改变。
比较有效率的解决方法是利用所谓的thunk.Thunk技术初次引进到编译器技术中,我相信是为了支持ALGOL独一无二的pass-by-name语意。所谓thunk 是一小段assembly码,用来(1)以适当的offset值调整this指针,(2)跳到 virtual function去。例如,经由一个 Base2指针调用Derived destructor,其相关的thunk可能看起来是这个样子:
// 虚拟C++码
pbase2_dtor_thunk:
this += sizeof(base1);
Derived::~Derived(this);Thunk技术允许virtual table slot继续内含一个简单的指针,因此多重继承不需要任何空间上的额外负担。Slots 中的地址可以直接指向virtual function,也可以指向一个相关的 thunk (如果需要调整this指针的话)。于是,对于那些不需要调整this 指针的virtual function而言,也就不需承载效率上的额外负担。
调整 this 指针的第二个额外负担就是,由于两种不同的可能:(1)经由derived class(或第一个base class)调用, (2)经由第二个(或其后继) base class调用,同一函数在 virtual table中可能需要多笔对应的 slots。例如:
Base1* pbase1 = new Derived;
Base2* pbase2 = new Derived;
delete pbase1;
delete pbase2;虽然两个delete 操作导致相同的 Derived destructor,但它们需要两个不同的virtual table slots:
1. pbase1不需要调整this 指针(因为 Basel是最左端 base class 之故,它已经指向Derived对象的起始处)。其virtual table slot需放置真正的 destructor地址。
2. pbase2需要调整this指针。其virtual table slot需要相关的thunk地址。
在多重继承之下,一个derived class内含n-1个额外的 virtual tables,n表示其上一层 base classes的数目(因此,单一继承将不会有额外的virtual tables对于本例之 Derived 而言,会有两个virtual tables被编译器产生出来:
1.一个主要实体,与Basel(最左端base class)共享。
2.一个次要实体,与Base2(第二个base class)有关。
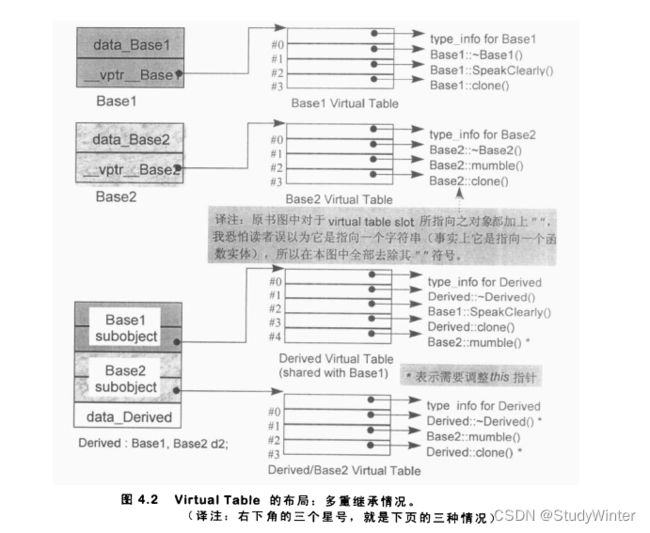
用以支持“一个class拥有多个virtual tables”的传统方法是,将每一个tables以外部对象的形式产生出来,并给予独一无二的名称。例如,Derived 所关联的两个tables可能有这样的名称:
vtbl_Derived; // 主要表格
vtbl_Base2_Derived; // 次要表格于是当将一个Derived对象地址指定给一个Basel 指针或Derived指针时,被处理的 virtual table是主要表格vtbl_Derived。而当你将一个Derived对象地址指定给一个Base2指针时,被处理的virtual table 是次要表格vtbl_Base2_Derived.
有三种情况,第二或后继的 base class会影响对virtualfunctions的支持。
第一种情况是,通过一个“指向第二个base class”的指针,调用derived class virtual function。例如:
Base2* ptr = new Derived;
// 调用Derived::~Derived
// ptr必须被向后调整sizeof(Base1)个bytes
delete ptr;第二种情况是第一种情况的变化,通过一个“指向derived class”的指针,调用第二个base class 中一个继承而来的 virtual function。在此情况下, derived class指针必须再次调整,以指向第二个base subobject。例如
Derived* pder = new Derived;
// 调用Base2::mumble()
// pter必须被向前调整sizeof(Base1)个bytes
pder->mumble();第三种情况发生于一个语言扩充性质之下:允许一个virtual function的返回值类型有所变化,可能是base type ,也可能是 publicly derived type。这一点可以通过Derived :clone()函数实体来说明。clone函数的 Derived 版本传回一个Derived class指针,默默地改写了它的两个base class函数实体。当我们通过“指向第二个 base class”的指针来调用clone()时,this 指针的 offset问题于是诞生:
Base2* pb1 = new Derived;
// 调用Derived* Derived::clone()
// 返回值必须被调整以指向Base2 subobject
Base2* pb2 = pb1->clone();当进行pb1->clone(时,pbl会被调整指向Derived对象的起始地址,于是clone()的 Derived版会被调用;它会传回一个指针,指向一个新的 Derived 对象﹔该对象的地址在被指定给pb2之前,必须先经过调整,以指向 Base2 subobject。
虚拟继承下的Virtual Functions
考虑下面的virtual base class派生体系,从Point2d 派生出Point3d:
class Point2d {
public:
Point2d(float x = 0.0, float y = 0.0);
virtual ~Point2d();
virtual void mumble();
virtual float getZ();
// ...
protected:
float _x, _y;
};
class Point3d : public virtual Point3d {
public:
Point3d(float x = 0.0, float y = 0.0, float z = 0.0);
~Point3d();
float getZ();
protected:
float _z;
};
虽然Point3d有唯一一个(同时也是最左边的) base class,也就是Point2d,但Point3d和 Point2d 的起始部分并不像“非虚拟的单一继承”情况那样一致。这种情况显示于图4.3.由于Point2d和 Point3d 的对象不再相符,两者之间的转换也就需要调整 this 指针。至于在虚拟继承的情况下要消除thunks,一般而言已经被证明是一项高难度技术。
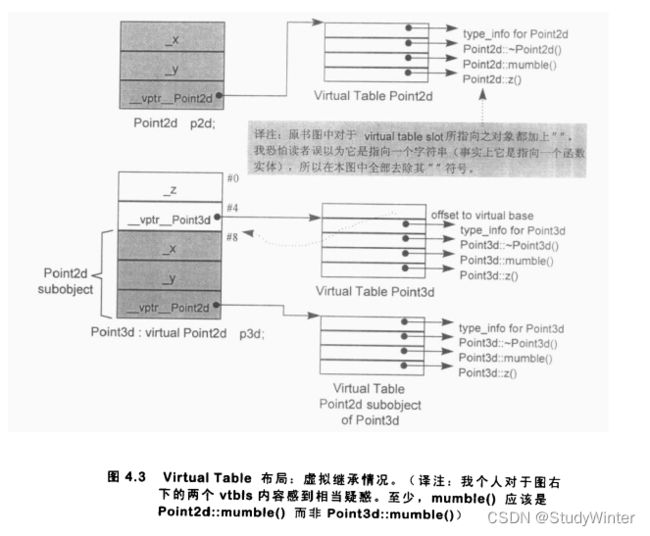
不要在一个virtual base class中声明nonstatic data members。
4.3函数的效能
这里通过一些函数的形式测性能。
结论:nonmember或static member或nonstatic member函数都被转化为完全相同的形式。
4.4指向Member Function 的指针(Pointer-to-Member Functions)
在第三章中已经看到了,取一个nonstatic data member的地址,得到的结果是该member 在 class布局中的bytes位置(再加1),它需要被绑定于某个class object的地址上,才能够被存取。
取一个nonstatic member function的地址,如果该函数是nonvirtual,则得到的结果是它在内存中真正的地址。然而这个值也是不完全的,它也需要被绑定于某个class object的地址上,才能够通过它调用该函数。所有的nonstatic memberfunctions都需要对象的地址(以参数this指出)。
回顾一下,一个指向member function的指针,其声明语法如下:
double // 返回值
(Point::* // 类型
pmf) // 指针名字
(); // 形参为空然后我们可以这样定义并初始化该指针:
double (Point::*coord)() = &Point::x;也可以这样指定其值:
coord = &Point::y;想调用它,可以这么做:
(origin.*coord)();或
(ptr->*coord)();这些操作会被编译器转换为:
// 虚拟C++码
(coord)(&origin);和
// 虚拟C++码
(coord)(ptr);指向member function的指针的声明语法,以及指向“member selection运算符”的指针,其作用是作为this指针的空间保留者.这也就是为什么static memberfunctions(没有this指针)的类型是“函数指针”,而不是“指向member function之指针”的原因。
使用一个“member function指针”,如果并不用于virtual function、多重继承、virtual base class等情况的话,并不会比使用-个“nonmember function指针”的成本更高.上述三种情况对于“member function指针”的类型以及调用都太过复杂.事实上,对于那些没有 virtual functions或virtual base class,或multiple baseclasses的 classes而言,编译器可以为它们提供相同的效率。下一节要讨论为什么virtual functions 的出现,会使得“member function指针”更复杂化。
支持“指向Virtual Member Functions”之指针
注意下面的程序片段
float(Point::*pmf)() = &Point::z;
Point* ptr = new Point3d;pmf,一个指向member function的指针,被设值为Point::z()(一个virtual function)的地址。ptr则被指定以一个Point3d对象。如果我们直接经由ptr调用z():
ptr->z();则被调用的是Point3d::z(0。但如果我们从pmf间接调用z()呢?
(ptr->*pmf)();仍然是Point3d::z()被调用吗?也就是说,虚拟机制仍然能够在使用“指向member function之指针”的情况下运行吗?答案是yes,问题是如何实现呢?
在前一小节中,我们看到了,对一个nonstatic member function取其地址,将获得该函数在内存中的地址。然而面对一个virtual function,其地址在编译时期是未知的,所能知道的仅是virtual function在其相关之virtual table中的索引值.也就是说,对一个virtual member function取其地址,所能获得的只是一个索引值。
例如,假设我们有以下的 Point声明:
class Point
{
public:
virtual ~Point();
float getX();
float getY();
virtual float getZ();
// ...
};然后取destructor的地址:
&Point::~Point;得到的结果是1,取getX()或者getY()的地址:
&Point::getX();
&Point::getY();得到的则是函数在内存中的地址,因为它们不是 virtual。取z()的地址:
&Point::getZ();得到的结果是2。测试:

通过pmf来调用z(),会被内部转化为一个编译时期的式子,一般形式如下:
(*ptr->vptr[(int)pmf])(ptr);对一个“指向member function 的指针”评估求值 ( evaluated),会因为该值有两种意义而复杂化;其调用操作也将有别于常规调用操作.pmf的内部定义也就是:
float (Point::*pmf)();必须允许该函数能够寻址出nonvirtual x()和virtual z()两个memberfunctions,而那两个函数有着相同的原型:
// 二者都可以被指定给pmf
float Point::getX() { return _x; }
float Point::getZ() { return 0; }只不过其中一个代表内存地址,另一个代表virtual table 中的索引值。因此,编译器必须定义 pmf使它能够(1)含有两种数值,(2)更重要的是其数值可以被区别代表内存地址还是Virtual table中的索引值。
在多重继承之下,指向Member Functions的指针
为了让指向member functions的指针也能够支持多重继承和虚拟继承,Stroustrup设计了下面一个结构体( [LIPP88]中有其原始内容):
// 一般结构,用以支持
// 在多重继承之下指向member functions的指针
struct _mptr
{
int delta;
int index;
union {
ptrtofunc faddr;
int v_offset;
};
};它们要表现什么呢? index和 faddr分别(不同时)带有virtual table索引和nonvirtual member function地址(为了方便,当index 不指向virtual table 时﹒会被设为-1)。在该模型之下,像这样的调用操作:
(ptr->*pmf)();会变成:
(pmf.index < 0)
? // non-virtual invocation
(*pmf.faddr)(ptr)
: // virtual invocation
(*ptr->vptr[pmf.index](ptr));这种方法所受到的批评是,每一个调用操作都得付出上述成本,检查其是否为virtual或nonvirtual. Microsoft把这项检查拿掉,导人一个它所谓的 vcallthunk.在此策略之下, faddr被指定的要不就是真正的member function地址(如果函数是nonvirtual话》,要不就是vcall thunk 的地址.于是virtual或nonvirtual函数的调用操作透明化,vcall thunk 会选出并调用相关virtual table中的适当slot
这个结构体的另一个副作用就是,当传递一个不变值的指针给memberfunction时,它需要产生一个临时性对象。
“指向Member Functions之指针”的效率
在下面一组测试中,cross_product()函数经由以下方式调用:
- 一个指向nonmember function的指针;
- 一个指向class member function的指针;
- 一个指向virtual member function的指针;
- 多重继承下的nonvirtual 及virtual member function call;
- 虚拟继承下的nonvirtual及virtual member function call.

4.5 Inline Functions
下面是Point class的一个加法运算符的可能实现内容:
class Point {
// 友元重载加法运算符
friend Point
operator+(const Point&, const Point&);
};
Point
operator+(const Point& lhs, const Point& rhs)
{
Point new_pt;
new_pt._x = lhs._x + rhs._x;
new_pt._y = lhs._y + rhs._y;
return new_pt;
}理论上,一个比较“干净”的做法是使用inline函数来完成set 和 get函数:
new_pt._x (lhs.getX() + rhs.getX());由于我们受限只能在上述两个函数中对_x直接存取,因此也就将稍后可能发生的data members 的改变(例如在继承体系中上移或下移)所带来的冲击最小化了.如果把这些存取函数声明为inline,我们就可以继续保持直接存取members的那种高效率—虽然我们亦兼顾了函数的封装性。此外,加法运算符不再需要被声明为Point的一个friend.
然而,实际上我们并不能够强迫将任何函数都变成inline ——虽然cfront客户一度曾经发出一封权限极高的修改需求,要求我们加上一个must_inline 关键词。关键词inline(或class declaration中的member function或friend function的定义)只是一项请求。如果这项请求被接受,编译器就必须认为它可以用一个表达式( expression)合理地将这个函数扩展开来。
一般而言,处理一个inline函数,有两个阶段:
1.分析函数定义,以决定函数的“intrinsic inline ability”(本质的inline能力)。“intrinsic”(本质的、固有的)一词在这里意指“与编译器相关”。
2.真正的 inline函数扩展操作是在调用的那一点上.这会带来参数的求值操作( evaluation)以及临时性对象的管理。
形式参数(Formal Arguments )
一般而言,面对“会带来副作用的实际参数”,通常都需要引入临时性对象.换句话说,如果实际参数是一个常量表达式( constant expression ) ,我们可以在替换之前先完成其求值操作(evaluations):后继的inline替换,就可以把常量直接“绑”上去。如果既不是个常量表达式,也不是个带有副作用的表达式,那么就直接代换之。
举个例子
inline int
min(int i, int j)
{
return i < j ? i : j;
}下面是三个调用操作
inline int
bar()
{
int minVal;
int val1 = 1024;
int val2 = 2048;
// (1) minVal = min(val1, val2);
// (2) minVal = min(1024, 2048);
// (3) minVal = min(foo(), bar() + 1);
return minVal;
}标示为(1)的那一行会被扩展为:
// (1) 参数直接代换
minVal = val1 < val2 ? val1 : val2;标记为(2)的那一行直接拥抱常量:
// (2)代换之后,直接使用常量
minVal = 1024;标示为(3)的那一行则引发参数的副作用。它需要导人一个临时对象,以避免重复求值( multiple evaluations) :
// (3)有副作用,所以导入临时对象
int t1;
int t2;
minVal =
(t1 = foo()), (t2 = bar() + 1),
t1 < t2 ? t1 : t2;局部变量(Local Variables )
如果我们轻微地改变定义,在 inline定义中加入一个局部变量,会怎样:
inline int
min(int i, int j)
{
int minVal = i < j ? i : j;
return minVal;
}这个局部变量需要什么额外的支持或处理吗?如果我们有以下的调用操作:
{
int localVar;
int minVal;
// ...
minVal = min(val1, val2);
}inline被扩展开来后,为了维护其局部变量,可能会成为这个样子(理论上这个例子中的局部变量可以被优化,其值可以直接在minval中计算):
{
int localVar;
int minVal;
// 将inline函数的局部变量处以"mangling"操作
int _min_lv_minval;
minVal =
(_min_lv_minval =
val1 < val2 ? val1 : val2),
_min_lv_minval;
}一般而言,inline函数中的每一个局部变量都必须被放在函数调用的一个封闭区段中,拥有一个独一无二的名称。如果inline函数以单一表达式( expression)扩展多次,那么每次扩展都需要自己的一组局部变量。如果inline函数以分离的多个式子( discrete statements)被扩展多次,那么只需一组局部变量,就可以重复使用(译注:因为它们被放在一个封闭区段中,有自己的scope) .
inline函数中的局部变量,再加上有副作用的参数,可能会导致大量临时性对象的产生。特别是如果它以单一表达式( expression)被扩展多次的话。例如,下面的调用操作:
minval = min(val1, val2) + min(foo(), foo() + 1);可能被扩展为
// 为局部变量产生临时变量
int _min_lv_minval_00;
int _min_lv_minval_01;
// 为放置副作用值而产生临时变量
int t1;
int t2;
minval =
((_min_lv_minval_00) =
val1 < val2 ? val1 : val2),
_min_lv_minval_00
+
((_min_lv_minval_01 = (t1 = foo()),
(t2 = foo() + 1),
t1 < t2 ? t1 : t2),
_min_lv_minval_01);