从零实现深度学习框架——Transformer从菜鸟到高手(一)
引言
本文为[从零实现深度学习框架]系列文章内部限免文章,更多限免文章见 专栏目录。
本着“凡我不能创造的,我就不能理解”的思想,系列文章会基于纯Python和NumPy从零创建自己的类PyTorch深度学习框架。
Transformer是继MLP、RNN、CNN之后的第四大特征提取器,也是第四大基础模型。像BERT、GPT和ChatGPT底层都是基于Transformer Block实现的。
为了更好的理解它,我们需要知道它的实现细节,本文开始我们来剖析它的原理与实现细节,并通过我们的框架来实现。
Transformer是论文Attention Is All You Need提出来的,博主也尝试翻译了一下这篇神作,需要的见参考目录。这篇论文非常短,其中涉及到很多细节并没有展开,博主想做的事情是,将这篇论文读厚,期望读完这些文章之后,大家对Transformer的理论和实现中的各种细节有一个清晰的认识,让大家变成Transformer高手。
本文的目标是理解多头注意力的理论和实现。
Transformer架构

这是论文中的原图,基本上介绍Transformer都会引入这个图片,因为它高度概括了Transformer的设计,不过隐藏在其中的细节还需要继续深入了解。
它也是一个encoder-decoder架构,左边是encoder,右边是decoder。我们先来看下它们内部的构件(从下到上)。
- Encoder
- Input Embedding:输入嵌入层
- Positional Encoding:位置编码
- Encoder Transformer Block:由于Encoder和Decoder的Block不同,这里区分来展开。
- Multi-Head Attention:多头注意力
- Add: 残差连接
- (Layer) Norm:层归一化
- (Position-wise) Feed Forward:位置级前馈网络
- 上面是一个Block包含的内容,由于设计成了输入和输出的维度一致,因此可以堆叠N个。
- Decoder
- Output Embedding:输出嵌入层
- Positional Encoding:位置编码
- Decoder Transformer Block
- Masked Multi-Head Attention:掩码多头注意力
- Add: 残差连接
- (Layer) Norm:层归一化
- Multi-Head Attention:多头注意力
- (Position-wise) Feed Forward:位置级前馈网络
- 上面是一个Block包含的内容,由于设计成了输入和输出的维度一致,因此可以堆叠N个。
- Linear:线性映射层
- Softmax:输出概率
以上就是从这个架构图能看出来的内容,背后还隐藏了如何训练、如何设计输入的格式、Dropout的使用等。我们在这篇文章中都能看到。
我们下面会了解每个组件的细节,先从Encoder开始。
Encoder
如上所示,Encoder由很多Transformer Block(或者说Encoder Layer)堆叠而成,每个Encoder Layer接收一个嵌入序列并经过下面的子层:
- 多头注意力层
- 位置级前馈网络
每个Encoder Layer的输出嵌入形状和输入一样,这样它们可以堆叠起来。堆叠Encoder的目的是得到具有上下文信息的输入表示,或者说提取表达能力丰富的特征。由于Encoder Layer可以看到完整的输入,再加上多头注意力机制,输入的每个位置都可以看到所有的其他位置,与其他位置进行交互(注意力计算),每个位置都可以得到具有多个方面上下文信息的表示。比如"这个苹果很好吃"中的"苹果"会得到一个类似可以吃的水果信息;而"苹果挤牙膏式推出新功能可能留不住一部分用户"中的"苹果"会得到一个类似公司的信息。相比每个token得到的嵌入都是一样的静态Word2vec来说,Transformer可以得到与上下文相关的动态嵌入表示。
其中的每个子层都使用了残差连接和层归一化,为了更高效地训练深层网络。为了吸引大家的"注意",我们先从Transformer的核心——多头注意力开始了解。
自注意力
首先回顾下注意力机制,注意力机制允许模型为序列中不同的元素分配不同的权重。而自注意力中的"自"表示输入序列中的输入相互之间的注意力,即通过某种方式计算输入序列每个位置相互之间的相关性。

对于Transformer编码器来说,给定一个输入序列 ( x 1 , ⋯ , x n ) (\pmb x_1,\cdots,\pmb x_n) (x1,⋯,xn),这里假设 x i \pmb x_i xi是输入序列中第 i i i个位置所对应的词嵌入。自注意力产生了一个新的相同长度的嵌入 ( y 1 , ⋯ , y n ) (\pmb y_1,\cdots,\pmb y_n) (y1,⋯,yn),其中每个 y i \pmb y_i yi是所有的 x j \pmb x_j xj的加权和(包括 x i \pmb x_i xi本身):
y i = ∑ j α i j x j (1) \pmb y_i = \sum_j \alpha_{ij} \pmb x_j \tag 1 yi=j∑αijxj(1)
系数 α j i \alpha_{ji} αji被称为是注意力权重,且有性质 ∑ j α i j = 1 \sum_j \alpha_{ij} =1 ∑jαij=1。
缩放点积注意力
从文章注意力机制中我们知道有很多种计算注意力的方式,最高效的是点积注意力,即两个输入之间做点积。
以两个输入 x i , x j \pmb x_i,\pmb x_j xi,xj为例,它们之间的注意分数计算如下:
score ( x i , x j ) = x i ⋅ x j (2) \text{score}(\pmb x_i,\pmb x_j) = \pmb x_i \cdot \pmb x_j \tag{2} score(xi,xj)=xi⋅xj(2)
点积的结果是一个实数范围内的标量,结果越大代表两个向量越相似。这是计算两个输入之间的注意力分数,如果 x i \pmb x_i xi与所有的输入进行计算,就可以得到 n n n个注意力分数,为了转换为权重,经过Softmax归一化就可以得到权重向量 α \alpha α,其中 α i j \alpha_{ij} αij表示两个输入 i i i和 j j j之间的相关度(权重系数):
α i j = softmax ( score ( x i , x j ) ) = exp ( score ( x i , x j ) ) ∑ k = 1 n exp ( score ( x i , x k ) ) \begin{align} \alpha_{ij} &= \text{softmax}(\text{score}(\pmb x_i,\pmb x_j))\,\, \tag{3}\\ &= \frac{\exp(\text{score}(\pmb x_i,\pmb x_j))} { \sum_{k=1}^n \exp(\text{score}(\pmb x_i,\pmb x_k)) } \,\, \tag{4} \end{align} αij=softmax(score(xi,xj))=∑k=1nexp(score(xi,xk))exp(score(xi,xj))(3)(4)
得到了这些权重系数,就可以通过对所有的输入进行加权和得到输出 y i \pmb y_i yi,如公式 ( 1 ) (1) (1)所示。
这种计算注意力的方式和我们在seq2seq中遇到的不同,seq2seq是用解码器的隐状态与编码器所有时刻的输出计算,而自注意力是输入自己与自己进行计算。参与计算的只是输入本身。
但Transformer使用的是更加复杂一点的计算方式,来捕获更加丰富的信息。
在Transformer计算注意力的过程中,每个输入扮演了三种不同角色:
- Query: 与所有的输入进行比较,为当前关注的点。
- Key:作为与Query进行比较的角色,用于计算和Query之间的相关性。
- Value:用于计算当前注意力关注点的输出,根据注意力权重对不同的Value进行加权和。
为了生成这三种不同的角色,Transformer分别引入了三个权重矩阵 W Q , W K , W V W^Q,W^K,W^V WQ,WK,WV,分别将每个输入 x i \pmb x_i xi投影到不同角色query,key和value表示:
q i = x i W Q ; k i = x i W K ; v i = x i W V (5) \pmb q_i = \pmb x_iW^Q;\quad \pmb k_i = \pmb x_i W^K; \quad \pmb v_i = \pmb x_iW^V \tag{5} qi=xiWQ;ki=xiWK;vi=xiWV(5)
如果把注意力过程类比成搜索的话,那么假设在百度中输入"自然语言处理是什么",那么Query就是这个搜索的语句;Key相当于检索到的网页的标题;Value就是网页的内容。
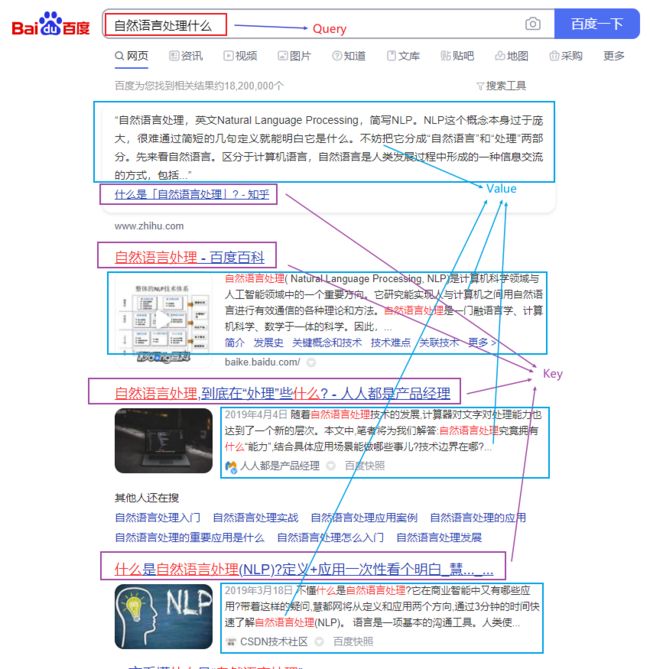
Query和Key是用于比较的,Value是用于提取特征的。通过将输入映射到不同的角色,使模型具有更强的学习能力。
由于key和query向量需要计算点积,因此它们的维度一定是一致的,记为 d k d_k dk;而value的维度可以和它们不一样,记为 d v d_v dv。假设词嵌入向量的维度为 d m o d e l d_{model} dmodel,为了方便,这里简记为 d d d。
那么我们就可以得到投影矩阵的维度, W Q ∈ R d × d k , W K ∈ R d × d k , W V ∈ R d × d v W^Q \in \Bbb R^{d \times d_k},W^K \in \Bbb R^{d \times d_k},W^V \in \Bbb R^{d \times d_v} WQ∈Rd×dk,WK∈Rd×dk,WV∈Rd×dv。
注意Transformer中的每个输入 x \pmb x x和输出 y \pmb y y的维度都是 1 × d 1 \times d 1×d,如果考虑批次和序列长度的话,完整维度是(batch_size, seq_len, embed_dim)。我们这里先考虑单个输入,即维度为 1 × d 1 \times d 1×d的 x i \pmb x_i xi。
现在我们用公式 ( 5 ) (5) (5)把所有的输入投影到key,query,value向量表示,对应的维度为 1 × d k , 1 × d k , 1 × d v 1\times d_k,1 \times d_k, 1\times d_v 1×dk,1×dk,1×dv。然后我们假设用 x i \pmb x_i xi的query向量 q i \pmb q_i qi和 x j \pmb x_j xj的key向量 k j \pmb k_j kj来计算点积,因为它们的维度都是 1 × d k 1 \times d_k 1×dk,所以可以计算点积,我们得到新的注意力分数计算函数:
score ( x i , x j ) = q i ⋅ k j (6) \text{score}(\pmb x_i,\pmb x_j) = \pmb q_i \cdot \pmb k_j \tag{6} score(xi,xj)=qi⋅kj(6)
也可以表示为 q i k j T \pmb q_i \pmb k_j^T qikjT,点积的结果是一个标量,但这个结果可能非常大(不管是正的还是负的),这会使得softmax函数值进入一个导数非常小的区域。需要对这个注意力得分进行缩放,缩放使得分布更加平滑。一种缩放的方法是把点积结果除以一个和嵌入大小相关的因子(factor)。注意这是在传递给softmax之前进行的。
Transformer的做法是除以query和key向量维度 d k d_k dk的平方根:
score ( x i , x j ) = q i ⋅ k j d k (7) \text{score}(\pmb x_i,\pmb x_j) = \frac{\pmb q_i\cdot \pmb k_j}{\sqrt{d_k}} \tag 7 score(xi,xj)=dkqi⋅kj(7)
计算权重系数 α \alpha α的过程和上面介绍的一样(公式 ( 3 ) − ( 4 ) (3)-(4) (3)−(4)),但在计算输出 y i \pmb y_i yi时的加权和变成了基于value向量 v \pmb v v:
y i = ∑ j α i j v j (8) \pmb y_i = \sum_{j} \alpha_{ij} \pmb v_j \tag{8} yi=j∑αijvj(8)
整个计算过程可以利用矩阵乘法一次计算,首先通过将具有 N N N个token的输入序列映射到一个(嵌入)矩阵 X ∈ R N × d X \in \Bbb R^{N \times d} X∈RN×d。然后让 X X X乘到key,query和value权重矩阵( W Q , W K , W V W^Q,W^K,W^V WQ,WK,WV,注意它们的维度)上,得到矩阵 Q ∈ R N × d k , K ∈ R N × d k , V ∈ R N × d v Q \in \Bbb R^{N \times d_k},K \in \Bbb R^{N \times d_k},V \in \Bbb R^{N \times d_v} Q∈RN×dk,K∈RN×dk,V∈RN×dv,其中包含所有输入的key,query和value向量:
Q = X W Q ; K = X W K ; V = X W V (9) Q=XW^Q;\quad K=XW^K;\quad V=XW^V \tag{9} Q=XWQ;K=XWK;V=XWV(9)
这样我们一次性计算出了所有的 Q , K , V Q,K,V Q,K,V,然后通过矩阵乘法 Q K T QK^T QKT得到相似度得分矩阵,形状为 N × N N \times N N×N。接着缩放这个得分矩阵,进行Softmax得到权重矩阵。最后拿权重矩阵去乘 V V V就可以得到一个形状为 N × d v N \times d_v N×dv的矩阵,这就是经过注意力之后的结果,表示每个输入的自注意力后的向量表示。
上面说了这么多,实际可以用一个公式表示:
SelfAttention ( Q , K , V ) = softmax ( Q K T d k ) V (10) \text{SelfAttention} (Q,K,V) = \text{softmax}\left(\frac{QK^T}{\sqrt {d_k}}\right) V \tag{10} SelfAttention(Q,K,V)=softmax(dkQKT)V(10)
我们前面不是说,注意力层计算的结果 y \pmb y y和输入 x \pmb x x的维度是一致的吗?但这里为什么输出的维度是 d v d_v dv,而不是词嵌入维度 d d d呢?因为Encoder Layer除了自注意力层还包含一个FF层,它就是用于将维度转换会 d v d_v dv的,我们后面再深入探讨,前面那么说是为了让大家更好地理解。所以,准确地说应该是Transformer Block的输入和输出的维度是一致的。
为了更好地理解,下面举一个例子,这个例子来自文章The Illustrated Transformer。假设输入包含两个单词"Thinking Machines"。

计算自注意力的第一步就是,为编码器层的每个输入,都创建三个向量,分别是query向量,key向量和value向量。
正如我们上面所说,每个向量都是乘上一个权重矩阵得到的,这些权重矩阵是随模型一起训练的。
进行线性映射的目的是转换向量的维度,转换成一个更小的维度。原文中是将 512 512 512维转换为 64 64 64维。
比如输入 x 1 x_1 x1乘以矩阵 W Q W^Q WQ得到query向量 q 1 q_1 q1,然后乘以 W k W^k Wk和 W V W^V WV分别得到key向量 k 1 k_1 k1和value向量 v 1 v_1 v1。
第二步 是计算注意力得分,假设我们想计算单词“Thinking”的注意力得分,我们需要对输入序列中的所有单词(包括自身)都进行某个操作。得到单词“Thinking”对于输入序列中每个单词的注意力得分,如果某个位置的得分越大,那么在生成编码时就越需要考虑这个位置。或者说注意力就是衡量 q q q和 k k k的相关性,相关性越大,那么在得到最终输出时, k k k对应的 v v v在生成输出时贡献也越大。
那么这里所说的操作是什么呢?其实很简单,就是点乘。表示两个向量在多大程度上指向同一方向。类似余弦相似度,除了没有对向量的模进行归一化。

所以如果我们计算单词“Thinking”的注意力得分,需要计算 q 1 q_1 q1对 k 1 k_1 k1和 k 2 k_2 k2的点积。如上图所示。
第三步和第四步 是进行进行缩放,然后经过softmax函数,使得每个得分都是正的,且总和为 1 1 1。
经过Softmax之后的值就可以看成是一个权重了,也称为注意力权重。决定每个单词在生成这个位置的编码时能够共享多大程度。
第五步 用每个单词的value向量乘上对应的注意力权重。这一步用于保存我们想要注意单词的信息(给定一个很大的权重),而抑制我们不关心的单词信息(给定一个很小的权重)。
第六步 累加第五步的结果,得到一个新的向量,也就是自注意力层在这个位置(这里是对于第一个单词“Thinking”来说)的输出。举一个极端的例子,假设某个单词的权重非常大,比如是 1 1 1,其他单词都是 0 0 0,那么这一步的输出就是该单词对应的value向量。

这就是计算第一个单词的自注意力输出完整过程。自注意力层的魅力在于,计算所有单词的输出可以通过矩阵运算一次完成。

我们把所有的输入编入一个矩阵 X X X,上面的例子有两个输入,所以这里的 X X X矩阵有两行。分别乘上权重矩阵 W Q , W K , W V W^Q,W^K,W^V WQ,WK,WV就得到了 Q , K , V Q,K,V Q,K,V向量矩阵。

然后除以 d k \sqrt{d_k} dk进行缩放,再经过Softmax,得到注意力权重矩阵,接着乘以value向量矩阵 V V V,就一次得到了所有单词的输出矩阵 Z Z Z。上图就是公式 ( 10 ) (10) (10)。
注意权重矩阵 W Q , W K , W V W^Q,W^K,W^V WQ,WK,WV都是可以训练的,因此通过训练,可以为每个输入单词生成不同的注意力得分,从而得到不同的输出。

根据上面的内容,我们就可以实现一个计算缩放点积注意力的函数:
def scaled_dot_product_attention(query: Tensor, key: Tensor, value: Tensor) -> Tensor:
"""
缩放点积注意力实现函数
Args:
query: [batch_size, input_len, d_k]
key: [batch_size, input_len, d_k]
value: [batch_size, input_len, d_v]
Returns:
"""
d_k = query.size(-1)
# scores [batch_size, input_len, input_len]
scores = F.bmm(query, key.permute(0, 2, 1)) / math.sqrt(d_k)
# weights [batch_size, input_len, input_len]
weights = F.softmax(scores, axis=-1)
# [batch_size, input_len, d_v]
return F.bmm(weights, value)
并且可以实现注意力层:
class Attention(nn.Module):
def __init__(self, embed_dim: int) -> None:
super().__init__()
# 定义Q,K,V映射
self.q = nn.Linear(embed_dim, embed_dim)
self.k = nn.Linear(embed_dim, embed_dim)
self.v = nn.Linear(embed_dim, embed_dim)
def forward(self, query: Tensor, key: Tensor, value: Tensor) -> Tensor:
"""
注意力的前向算法
Args:
query: 来自Encoder的嵌入向量 [batch_size, input_len, d_k]
key: 来自Encoder的嵌入向量 [batch_size, input_len, d_k]
value: 来自Encoder的嵌入向量 [batch_size, input_len, d_k]
Returns:
"""
# query, key, value [batch_size, input_len, d_k]
query, key, value = self.q(query), self.k(key), self.v(value)
# attn_outputs [batch_size, input_len, d_k]
attn_outputs = scaled_dot_product_attention(query, key, value)
return attn_outputs
注意此时我们假设 d = d k = d v d=d_k=d_v d=dk=dv,所以在初始化方法中只需要传入embed_dim。
要注意的是,在forward方法中接收三个参数,实际上对于编码器来说都是来自同一个底层嵌入层的输出。
接着通过三个线性变换映射到不同的空间,然后传入缩放点积注意力函数。
下面简单地测试:
embed_dim = 2
seq_len = 3
batch_size = 1
# 假设为嵌入层的输出
input_embeds = Tensor.randn(batch_size, seq_len, embed_dim)
attn = Attention(embed_dim=embed_dim)
# 编码器中,query、key、value来自同一个嵌入
values = attn(input_embeds, input_embeds, input_embeds)
print(values.shape)
print(values)
(1, 3, 2)
Tensor(
[[[ 0.2886 1.2668]
[ 0.2559 1.0761]
[-0.2283 -0.1046]]], requires_grad=True)
由于我们设的维度是一样的,所以这里输出的形状和输入一致。
多头注意力
上面介绍的缩放点积注意力把原始的 x \pmb x x映射到不同的空间后,去做注意力。每次映射相当于是在特定空间中去建模特定的语义交互关系,类似卷积中的多通道可以得到多个特征图,那么多个注意力可以得到多个不同方面的语义交互关系。可以让模型更好地关注到不同位置的信息,捕捉到输入序列中不同依赖关系和语义信息。有助于处理长序列、解决语义消歧、句子表示等任务,提高模型的建模能力。
对于每个头 i i i,都有它自己不同的key,query和value矩阵: W i K , W i Q , W i V W_i^K,W_i^Q,W_i^V WiK,WiQ,WiV。在多头注意力中,key和query的维度是 d k d_k dk,value嵌入的维度是 d v d_v dv,这样每个头 i i i,权重 W i Q ∈ R d × d k , W i K ∈ R d × d k , W i V ∈ R d × d v W_i^Q \in \Bbb R^{d \times d_k},W_i^K \in \Bbb R^{d \times d_k},W_i^V \in \Bbb R^{d \times d_v} WiQ∈Rd×dk,WiK∈Rd×dk,WiV∈Rd×dv,然后与压缩到 X X X中的输入相乘,得到 Q ∈ R N × d k , K ∈ R N × d k , V ∈ R N × d v Q \in \Bbb R^{N \times d_k},K \in \Bbb R^{N \times d_k},V \in \Bbb R^{N \times d_v} Q∈RN×dk,K∈RN×dk,V∈RN×dv。
得到这些多头注意力的组合以后,再把它们拼接起来,然后通过一个线性变化映射回原来的维度,保证输入和输出的维度一致。
h个头的输出是 N × d v N \times d_v N×dv的向量,接着这些输出被组合到一起压缩成原来的维度 d d d,这是拼接每个头的输出然后经过另一个线性投影 W O ∈ R h d v × d W^O \in \Bbb R^{hd_v \times d} WO∈Rhdv×d实现的,压缩到原来每个token的输出维度,或共 N × d N \times d N×d个输出:
MultiHeadAttention ( X ) = ( head 1 ⊕ head 2 ⋯ ⊕ head h ) W O (11) \text{MultiHeadAttention}(X) = (\text{head}_1 \oplus \text{head}_2 \cdots \oplus \text{head}_h) W^O \tag{11} MultiHeadAttention(X)=(head1⊕head2⋯⊕headh)WO(11)
head i = SelfAttention ( Q , K , V ) (12) \text{head}_i = \text{SelfAttention}(Q,K,V) \tag{12} headi=SelfAttention(Q,K,V)(12)
Q = X W i Q ; K = X W i K ; V = X W i V (13) Q=XW^Q_i; \,\, K=XW_i^K;\,\, V=XW_i^V \tag{13} Q=XWiQ;K=XWiK;V=XWiV(13)
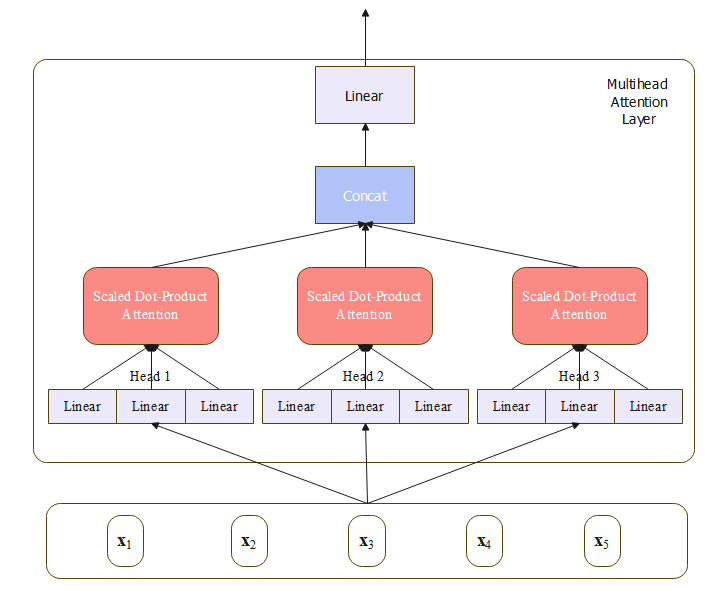
上图是一个三个头的注意力示意图,在原论文中, d = 512 d=512 d=512,有 h = 8 h=8 h=8个注意力头。每个头中的 d k = d v = d / h = 64 d_k=d_v=d/h=64 dk=dv=d/h=64,由于每个头维度的减少,总的计算量和正常维度的单头注意力差不多( 8 × 64 = 512 8 \times 64 =512 8×64=512)。
class MultiHeadAttention(nn.Module):
def __init__(self, embed_dim: int, num_heads: int) -> None:
super().__init__()
self.d_k = embed_dim // num_heads # 计算每个头的维度
self.h = num_heads
# 定义Q,K,V映射
self.q = nn.Linear(embed_dim, embed_dim)
self.k = nn.Linear(embed_dim, embed_dim)
self.v = nn.Linear(embed_dim, embed_dim)
# 输出的那个线性变换
self.linear = nn.Linear(embed_dim, embed_dim)
def forward(self, query: Tensor, key: Tensor, value: Tensor) -> Tensor:
"""
注意力的前向算法
Args:
query: 来自Encoder的嵌入向量 [batch_size, input_len, d_k]
key: 来自Encoder的嵌入向量 [batch_size, input_len, d_k]
value: 来自Encoder的嵌入向量 [batch_size, input_len, d_k]
Returns:
"""
batch_size = query.size(0)
# 线性映射后转换为形状 [batch_size, input_len, self.h, self.d_k]
# 即h个d_k维度的query,key,value embed_dim == h x d_k
# permute -> [batch_size, self.h, input_len, self.d_k]
query = self.q(query).view(batch_size, -1, self.h, self.d_k).permute(0, 2, 1, 3) # transpose(1, 2)
key = self.q(key).view(batch_size, -1, self.h, self.d_k).permute(0, 2, 1, 3)
value = self.q(value).view(batch_size, -1, self.h, self.d_k).permute(0, 2, 1, 3)
# attn_outputs [batch_size, h, input_len, d_k]
attn_outputs = scaled_dot_product_attention(query, key, value)
# 在计算时并没有将多个头分开计算,而是放在矩阵中一起运算
# 这里可以直接通过view来执行类似拼接的操作,然后应用到最后一个线性层
# permute -> [batch_size, input_len, h, d_k]
# view -> [batch_size, input_len, h * d_k]
attn_outputs = attn_outputs.permute(0, 2, 1, 3).view(batch_size, -1, self.h * self.d_k)
return self.linear(attn_outputs)
我们首先实现多头注意力,在实现细节上,可以不真正执行 h h h次多头注意力运算,而是通过矩阵运算一次进行。
但我们给scaled_dot_product_attention函数的维度发生了变化,因此也需要修改改函数的实现。原始Transformer中,d_k=d_v,这里为了简单,都注释成d_k。
def scaled_dot_product_attention(query: Tensor, key: Tensor, value: Tensor) -> Tensor:
"""
缩放点积注意力实现函数
Args:
query: [batch_size, h, input_len, d_k]
key: [batch_size, h, input_len, d_k]
value: [batch_size, h ,input_len, d_k]
Returns:
"""
d_k = query.size(-1)
# query [batch_size, h, input_len, d_k]
# key.permute -> [batch_size, h, d_k, input_len]
# 固定batch_size, self.h -> (input_len, self.d_k) x (self.d_k, input_len) = (input_len, input_len)
# -> [batch_size, self.h, input_len, input_len]
# scores [batch_size, h, input_len, input_len]
scores = F.bmm(query, key.permute(0, 1, 3, 2)) / math.sqrt(d_k)
# weights [batch_size, h, input_len, input_len]
weights = F.softmax(scores, axis=-1)
# [batch_size, h, input_len, d_k]
return F.bmm(weights, value)
为了兼容多个头,我们改了一点代码,最后输出的形状是 [batch_size, h, input_len, d_k]。
下面我们进行简单的测试:
embed_dim = 512
seq_len = 3
batch_size = 1
num_heads = 8
# 假设是Transformer Layer的输入
input_embeds = Tensor.randn(batch_size, seq_len, embed_dim)
attn = MultiHeadAttention(embed_dim=embed_dim, num_heads=num_heads)
# 编码器中,query、key、value来自同一个嵌入
values = attn(input_embeds, input_embeds, input_embeds)
print(values.shape)
(1, 3, 512)
可以看到,输入和输出的维度确实一致。
但我们的实现还有点问题,当批次内包含多个序列样本时,可能它们的长度不一,这里也是需要进行填充以对齐长度。
而实际上,没必要对填充token计算注意力,因此,我们需要增加一个表示填充的mask,如图4中所示。
def scaled_dot_product_attention(query: Tensor, key: Tensor, value: Tensor, mask: Tensor = None) -> Tensor:
"""
缩放点积注意力实现函数
Args:
query: [batch_size, h, input_len, d_k]
key: [batch_size, h, input_len, d_k]
value: [batch_size, h ,input_len, d_k]
mask: [batch_size, 1, 1, input_len]
Returns:
"""
d_k = query.size(-1)
# query [batch_size, h, input_len, d_k]
# key.permute -> [batch_size, h, d_k, input_len]
# 固定batch_size, self.h -> (input_len, self.d_k) x (self.d_k, input_len) = (input_len, input_len)
# -> [batch_size, self.h, input_len, input_len]
# scores [batch_size, h, input_len, input_len]
scores = F.bmm(query, key.permute(0, 1, 3, 2)) / math.sqrt(d_k)
# 对于源序列来说,由于批次内语句长短不一,对于短的语句,需要填充 token
if mask is not None:
# 根据mask,把填充的位置填-1e9,然后计算softmax的时候,-1e9的位置就被计算为0
scores = scores.masked_fill(mask == 0, -1e9)
# weights [batch_size, h, input_len, input_len]
weights = F.softmax(scores, axis=-1)
# [batch_size, h, input_len, d_k]
return F.bmm(weights, value)
把填充的位置填-1e9,然后计算softmax的时候,-1e9的位置就被计算为0,即在计算注意力的时候不会被考虑。
对于Encoder来说, mask的形状是[batch_size, 1, 1, input_len],为了和scores的形状匹配。
然后我们实现通过输入生成mask:
def generate_mask(src: Tensor, pad: int = 0):
"""
生成mask
Args:
src: [batch_size, input_len]
pad: 填充的id
Returns:
"""
# src_mask [batch_size, 1, 1, input_len]
src_mask = (src != pad).unsqueeze(1).unsqueeze(2)
return src_mask
最后,修改多头注意力代码,接受mask参数:
class MultiHeadAttention(nn.Module):
def __init__(self, embed_dim: int, num_heads: int) -> None:
super().__init__()
self.d_k = embed_dim // num_heads # 计算每个头的维度
self.h = num_heads
# 定义Q,K,V映射
self.q = nn.Linear(embed_dim, embed_dim)
self.k = nn.Linear(embed_dim, embed_dim)
self.v = nn.Linear(embed_dim, embed_dim)
# 输出的那个线性变换
self.linear = nn.Linear(embed_dim, embed_dim)
def forward(self, query: Tensor, key: Tensor, value: Tensor, mask: Tensor = None) -> Tensor:
"""
注意力的前向算法
Args:
query: 来自Encoder的嵌入向量 [batch_size, input_len, d_k]
key: 来自Encoder的嵌入向量 [batch_size, input_len, d_k]
value: 来自Encoder的嵌入向量 [batch_size, input_len, d_k]
mask: 来自Encoder输入的mask [batch_size, 1, 1, input_len]
Returns:
"""
batch_size = query.size(0)
# ====拆分head====
# 线性映射后转换为形状 [batch_size, input_len, self.h, self.d_k]
# 即h个d_k维度的query,key,value embed_dim == h x d_k
# permute -> [batch_size, self.h, input_len, self.d_k]
query = self.q(query).view(batch_size, -1, self.h, self.d_k).permute(0, 2, 1, 3) # transpose(1, 2)
key = self.q(key).view(batch_size, -1, self.h, self.d_k).permute(0, 2, 1, 3)
value = self.q(value).view(batch_size, -1, self.h, self.d_k).permute(0, 2, 1, 3)
# attn_outputs [batch_size, h, input_len, d_k]
attn_outputs = scaled_dot_product_attention(query, key, value, mask)
# ====合并head====
# 在计算时并没有将多个头分开计算,而是放在矩阵中一起运算
# 这里可以直接通过view来执行类似拼接的操作,然后应用到最后一个线性层
# permute -> [batch_size, input_len, h, d_k]
# view -> [batch_size, input_len, h * d_k]
attn_outputs = attn_outputs.permute(0, 2, 1, 3).view(batch_size, -1, self.h * self.d_k)
return self.linear(attn_outputs)
编码器的多头注意力快完善好了,由于模型的参数较多,为了防止过拟合,我们还可以在注意力的时候加入dropout。如何加见下节内容。
完整代码
本文最终的完整代码为:
import copy
import math
import metagrad.module as nn
from metagrad import functions as F
from metagrad import Tensor
def scaled_dot_product_attention(query: Tensor, key: Tensor, value: Tensor, mask: Tensor = None,
dropout: nn.Dropout = None) -> Tensor:
"""
缩放点积注意力实现函数
Args:
query: [batch_size, h, input_len, d_k]
key: [batch_size, h, input_len, d_k]
value: [batch_size, h ,input_len, d_k]
mask: [batch_size, 1, 1, input_len]
dropout: Dropout层
Returns:
"""
d_k = query.size(-1)
# query [batch_size, h, input_len, d_k]
# key.permute -> [batch_size, h, d_k, input_len]
# 固定batch_size, self.h -> (input_len, self.d_k) x (self.d_k, input_len) = (input_len, input_len)
# -> [batch_size, self.h, input_len, input_len]
# scores [batch_size, h, input_len, input_len]
scores = F.bmm(query, key.permute(0, 1, 3, 2)) / math.sqrt(d_k)
# 对于源序列来说,由于批次内语句长短不一,对于短的语句,需要填充 token
if mask is not None:
# 根据mask,把填充的位置填-1e9,然后计算softmax的时候,-1e9的位置就被计算为0
scores = scores.masked_fill(mask == 0, -1e9)
# weights [batch_size, h, input_len, input_len]
weights = F.softmax(scores, axis=-1)
if dropout:
weights = dropout(weights)
# [batch_size, h, input_len, d_k]
return F.bmm(weights, value)
def generate_mask(src: Tensor, pad: int = 0):
"""
生成mask
Args:
src: [batch_size, input_len]
pad: 填充的id
Returns:
"""
# src_mask [batch_size, 1, 1, input_len]
src_mask = (src != pad).unsqueeze(1).unsqueeze(2)
return src_mask
class MultiHeadAttention(nn.Module):
def __init__(self, embed_dim: int, num_heads: int, dropout: float = 0.1) -> None:
super().__init__()
self.d_k = embed_dim // num_heads # 计算每个头的维度
self.h = num_heads
# 定义Q,K,V映射
self.q = nn.Linear(embed_dim, embed_dim)
self.k = nn.Linear(embed_dim, embed_dim)
self.v = nn.Linear(embed_dim, embed_dim)
# 输出的那个线性变换
self.linear = nn.Linear(embed_dim, embed_dim)
# Dropout
if dropout:
self.dropout = nn.Dropout(p=dropout)
else:
self.dropout = None
def forward(self, query: Tensor, key: Tensor, value: Tensor, mask: Tensor = None) -> Tensor:
"""
注意力的前向算法
Args:
query: 来自Encoder的嵌入向量 [batch_size, input_len, d_k]
key: 来自Encoder的嵌入向量 [batch_size, input_len, d_k]
value: 来自Encoder的嵌入向量 [batch_size, input_len, d_k]
mask: 来自Encoder输入的mask [batch_size, 1, 1, input_len]
Returns:
"""
batch_size = query.size(0)
# ====拆分head====
# 线性映射后转换为形状 [batch_size, input_len, self.h, self.d_k]
# 即h个d_k维度的query,key,value embed_dim == h x d_k
# permute -> [batch_size, self.h, input_len, self.d_k]
query = self.q(query).view(batch_size, -1, self.h, self.d_k).permute(0, 2, 1, 3) # transpose(1, 2)
key = self.q(key).view(batch_size, -1, self.h, self.d_k).permute(0, 2, 1, 3)
value = self.q(value).view(batch_size, -1, self.h, self.d_k).permute(0, 2, 1, 3)
# attn_outputs [batch_size, h, input_len, d_k]
attn_outputs = scaled_dot_product_attention(query, key, value, mask, self.dropout)
# ====合并head====
# 在计算时并没有将多个头分开计算,而是放在矩阵中一起运算
# 这里可以直接通过view来执行类似拼接的操作,然后应用到最后一个线性层
# permute -> [batch_size, input_len, h, d_k]
# view -> [batch_size, input_len, h * d_k]
attn_outputs = attn_outputs.permute(0, 2, 1, 3).view(batch_size, -1, self.h * self.d_k)
return self.linear(attn_outputs)
import numpy as np
embed_dim = 512
vocab_size = 5000
num_heads = 8
# 第二个样本包含两个填充
input_data = Tensor(
np.array([[1, 2, 3, 4, 5], [6, 7, 8, 0, 0]])
)
# batch_size = 2
# seq_len = 5
batch_size, seq_len = input_data.shape
embedding = nn.Embedding(vocab_size, embed_dim)
# 模拟嵌入层
input_embeds = embedding(input_data)
mask = generate_mask(input_data)
attn = MultiHeadAttention(embed_dim=embed_dim, num_heads=num_heads)
# 编码器中,query、key、value来自同一个嵌入
values = attn(input_embeds, input_embeds, input_embeds, mask)
print(values.shape)
参考
- [论文翻译]Attention Is All You Need
- The Annotated Transformer
- Speech and Language Processing
- The Illustrated Transformer