详解Seaborn,看这一篇就够了
转载:Seaborn常见绘图总结
Seaborn是一个比Matplotlib集成度更高的绘图库,在科研和数据分析中我们常常看到一些画的非常高大上的图,这往往就是Seaborn绘制的图形。因此我们就使用短短的半天时间来学习一下Seaborn的使用吧。
首先我们在学习之前,先下载一下Seaborn的数据集,如果不下载的话,我们在导入数据的时候往往会被拦截,网址如下:
https://github.com/mwaskom/seaborn-data
根据Seaborn的API,我们总体可以分成如下的总体框架:
文章目录
- 1. Relational plots(关系图)
-
- 1.1 scatterplot(散点图)
- 1.2 lineplot(线图)
- 1.3 relplot(关系图)
- 2. Categorical plots(分类图)
-
- 2.1 Categorical scatterplots(分类散点图)
-
- 2.1.1 stripplot(分布散点图)
- 2.1.2 swarmplot(分布密度散点图)
- 2.2 Categorical distribution plots(分类分布图)
-
- 2.2.1 boxplot(箱型图)
- 2.2.2 violinplot(小提琴图)
- 2.2.3 violinplot+stripplot(小提琴图+分布散点图)
- 2.2.4 violinplot+swarmplot(小提琴图+分布密度散点图)
- 2.2.5 boxplot+stripplot(箱线图+分布散点图)
- 2.2.6 boxplot+swarmplot(箱线图+分布密度散点图)
- 2.3 Categorical estimate plots(分类估计图)
-
- 2.3.1 barplot(条形图)
- 2.3.2 countplot(计数图)
- 2.3.3 piontplot(点图)
- 2.3.4 catplot()
- 3. Distribution plots(分布图)
-
- 3.1 histplot(直方图)
- 3.2 kdeplot(核密度图)
- 3.3 jointplot(联合分布图)
- 3.4 pairplot(变量关系组图)
- 4. Regression plots(回归图)
-
- 4.1 regplot(回归图)
- 4.2 lmplot(网格+回归图)
- 5. Matrix plots(矩阵图)
-
- 5.1 heatmap(热力图)
- 5.2 clustermap(聚类图)
- 6. FacetGrid()
- 7. PairGrid()
- 8. 主题和颜色
-
- 8.1 主题(style)
- 8.2 环境(context)
- 8.3 颜色(color_plette())
- 补充
1. Relational plots(关系图)
数据分析中就是理解变量如何相互关联,当这些关系被正确可视化时,我们往往可以从中获取某种关系或模式。
Relational plots 主要讨论三个函数:
- scatterplot(散点图)
- lineplot(线图)
- relplot(关系图)
首先,我们导入库函数:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
1.1 scatterplot(散点图)
散点图是利用散点来描述两个变量的联合分布,scatterplot 适用于变量都是数字的情况。在后面的Categorical plots(分类图)中,我们将会看到使用散点图可视化分类数据的专门工具。
#scatterplot参数
seaborn.scatterplot(x=None, y=None, hue=None, style=None, size=None,
data=None, palette=None, hue_order=None, hue_norm=None, sizes=None,
size_order=None, size_norm=None, markers=True, style_order=None,
x_bins=None, y_bins=None, units=None, estimator=None, ci=95, n_boot=1000,
alpha='auto', x_jitter=None, y_jitter=None, legend='brief', ax=None, **kwargs)
Seaborn函数中的参数特别多,但是其实大部分都是相同的,因此,我们可以很容易类推到其他函数的使用。下面简单介绍这些参数的含义。
- x,y: 传入的
特征名字或Python/Numpy数据,x表示横轴,y表示纵轴,一般为dataframe中的列。如果传入的是特征名字,那么需要传入data,如果传入的是Python/Numpy数据,那么data不需要传入。因为Seaborn一般是用来可视化Pandas数据的,如果我们想传入数据,那使用Matplotlib也可以。 - hue: 分组变量,将产生不同颜色的点。可以是分类的,也可以是数字的。
被视为类别。 - data: 传入的数据集,可选。一般是dataframe
- style: 分组变量,将产生不同标记点的变量分组。
被视为类别。 - size: 分组变量,将产生不同大小的点。可以是分类的,也可以是数字的。
- palette: 调色板,后面单独介绍。
- markers: 绘图的形状,后面单独介绍。
- ci: 允许的误差范围(空值误差的百分比,0-100之间),可为‘sd’,则采用标准差(默认95)
- n_boot(int): 计算置信区间要使用的迭代次数
- alpha: 透明度
- x_jitter, y_jitter: 设置点的抖动程度。
下面给出两个例子:
# 使用seaborn的数据
tips = sns.load_dataset('tips')
sns.scatterplot(x='total_bill',y='tip',data=tips)
plt.show()

sns.scatterplot(x='total_bill',y='tip',hue='day',style='time',size='size',data=tips)
plt.show()

1.2 lineplot(线图)
seaborn.lineplot(x=None, y=None, hue=None, size=None, style=None,
data=None, palette=None, hue_order=None, hue_norm=None, sizes=None,
size_order=None, size_norm=None, dashes=True, markers=None,
style_order=None, units=None, estimator='mean', ci=95, n_boot=1000,
sort=True, err_style='band', err_kws=None, legend='brief', ax=None, **kwargs)
参数和散点图差不多,所以直接上例子:
fmri = sns.load_dataset('fmri')
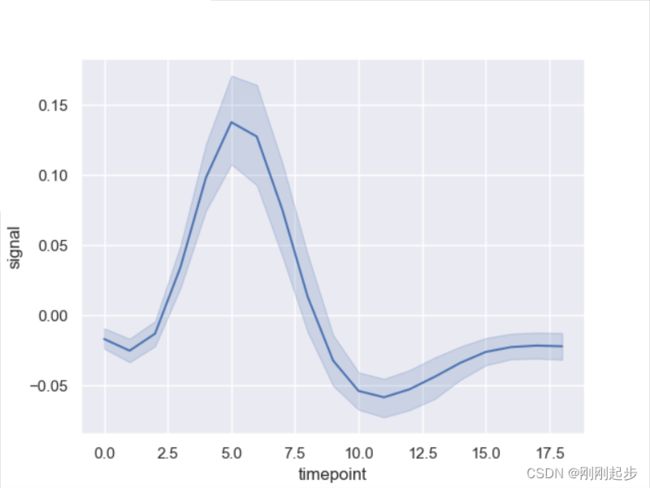
sns.lineplot(x="timepoint", y="signal", data=fmri)
# 阴影是默认的置信区间,可设置ci=0,将其去除
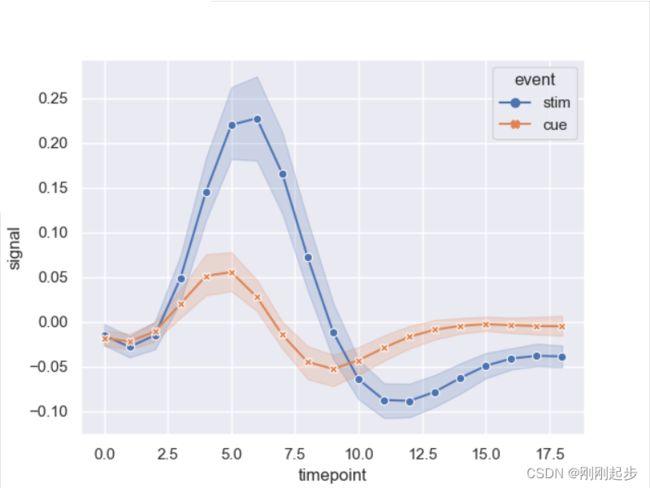
sns.lineplot(x="timepoint", y="signal",hue="event", style="event",
markers=True, dashes=False, data=fmri)
# markers=True表示使用不同的标记
# dashes=True表示一条实线,一条虚线
1.3 relplot(关系图)
seaborn.relplot(x=None, y=None, hue=None, size=None, style=None,
data=None, row=None, col=None, col_wrap=None, row_order=None,
col_order=None, palette=None, hue_order=None, hue_norm=None,
sizes=None, size_order=None, size_norm=None, markers=None, dashes=None,
style_order=None, legend='brief', kind='scatter', height=5, aspect=1,
facet_kws=None, **kwargs)
相当于lineplot和scatterplot的归约,可以通过kind参数指定画什么图形,参数解释如下:
- kind: 默认是’scatter’,也可以选择kind=‘line’
- sizes: List、dict或tuple,可选,说白了就是图片大小,注意和size区分;
- col、row: col指定列的分组变量,row指定行的分组变量,具体看下面例子
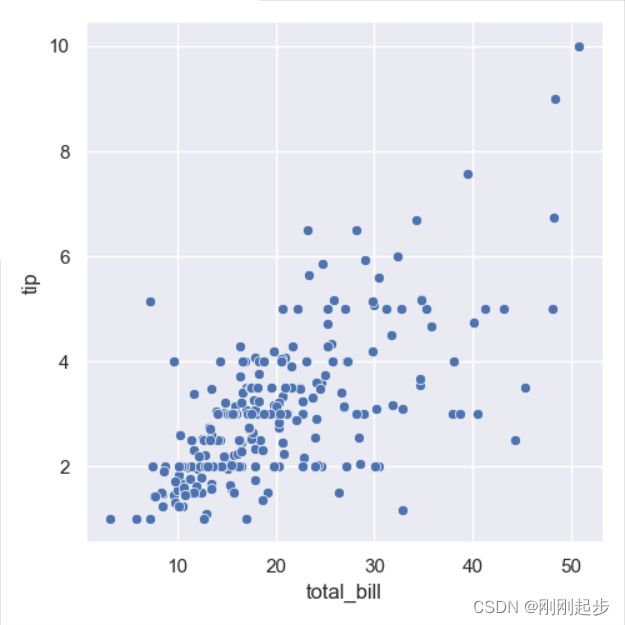
tips = sns.load_dataset("tips")
g = sns.relplot(x="total_bill", y="tip", data=tips)
#两者效果一模一样
ax = sns.scatterplot(x="total_bill", y="tip", data=tips)
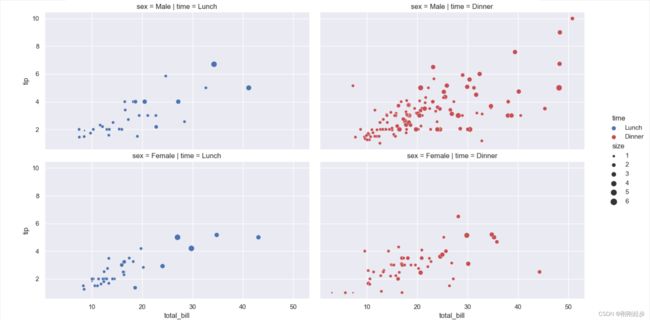
sns.relplot(x="total_bill", y="tip", hue="time", size="size",
palette=["b", "r"], sizes=(10, 100),col="time",row='sex', data=tips)
2. Categorical plots(分类图)
Categorical plots(分类图) 具体可以分为下main三种类型,11种图形:
- Categorical scatterplots(分类散点图)
- stripplot(分布散点图)
- swarmplot(分布密度散点图)
- Categorical distribution plots(分类分布图)
- boxplot(箱型图)
- violinplot(小提琴图)
- violinplot+stripplot(小提琴图+分布散点图)
- violinplot+swarmplot(小提琴图+分布密度散点图)
- boxplot+stripplot(箱线图+分布散点图)
- Categorical estimate plots(分类估计图)
- barplot(条形图)
- countplot(计数图)
- piontplot(点图)
- catplot()
2.1 Categorical scatterplots(分类散点图)
2.1.1 stripplot(分布散点图)
stripplot(分布散点图) 就是其中一个变量是分类变量的scatterplot(散点图)。stripplot(分布散点图)一般并不单独绘制,它常常与boxplot和violinplot联合起来绘制,作为这两种图的补充。
seaborn.stripplot(x=None, y=None, hue=None, data=None, order=None,
hue_order=None, jitter=True, dodge=False, orient=None, color=None,
palette=None, size=5, edgecolor='gray', linewidth=0, ax=None, **kwargs)
参数:
- order:用order参数进行筛选分类类别,例如:order=[‘sun’,‘sat’];
- jitter:抖动项,表示抖动程度,可以是float,或者True。如果不抖动的话,那么散点就会呈现一条直线了,并不利于可视化
- dodge:重叠区域是否分开,当使用hue时,将其设置为True,将沿着分类轴将不同色调级别的条带分开。
- orient:“v” | “h”,vertical(垂直) 和 horizontal(水平)的意思;
两个例子:
tips = sns.load_dataset("tips")
sns.stripplot(x="day", y="total_bill", data=tips)
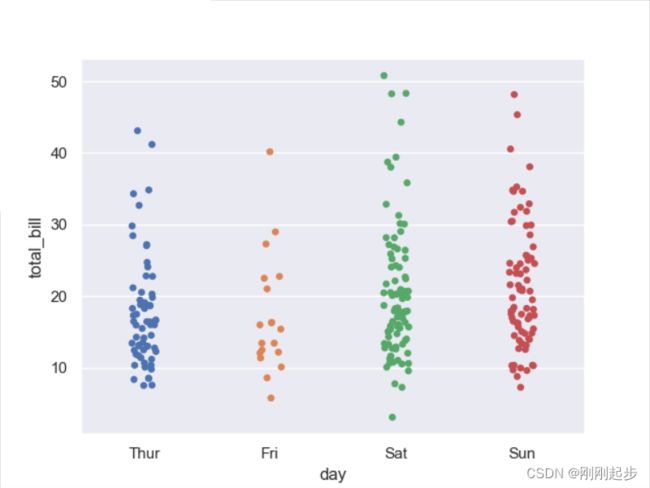
sns.stripplot(x="day", y="total_bill", hue="smoker",data=tips,
jitter=True,palette="Set2", dodge=False)

2.1.2 swarmplot(分布密度散点图)
这个函数类似于stripplot(),但是对点进行了调整(只沿着分类轴),使每个点都不会重叠。这更好地表示了值的密度分布,但显然,不适用大量观测的可视化。
seaborn.swarmplot(x=None, y=None, hue=None, data=None, order=None,
hue_order=None, dodge=False, orient=None, color=None, palette=None, size=5,
edgecolor='gray', linewidth=0, ax=None, **kwargs)
两个例子:
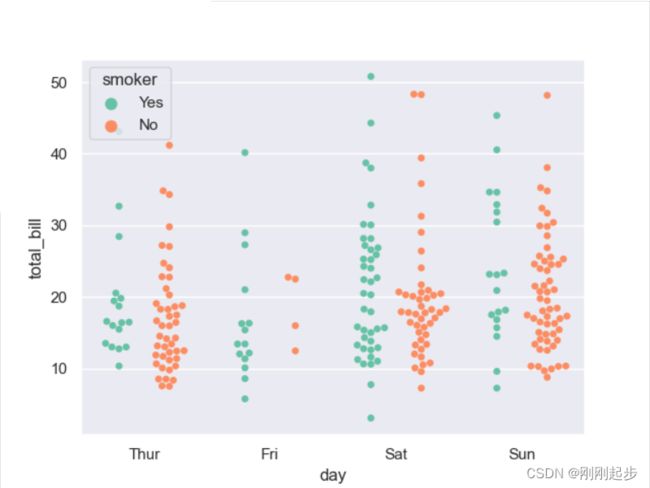
sns.swarmplot(x="day", y="total_bill", data=tips)

sns.swarmplot(x="day", y="total_bill", hue="smoker",data=tips,
palette="Set2", dodge=True)
2.2 Categorical distribution plots(分类分布图)
2.2.1 boxplot(箱型图)
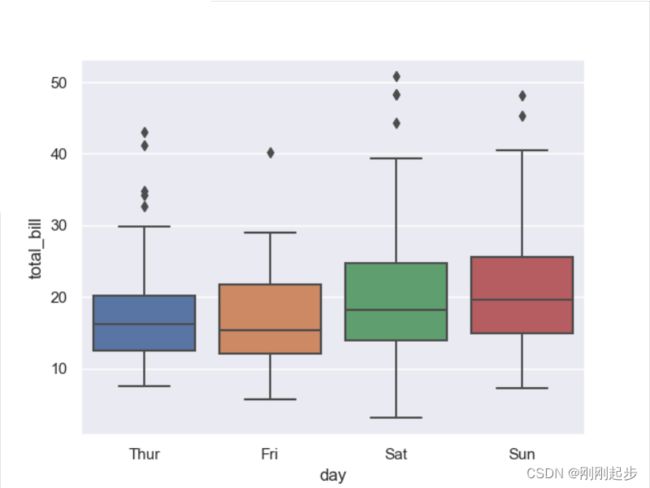
boxplot(箱型图) 就是描述变量关于不同类别的分布情况。框显示数据集的四分位数,线显示分布的其余部分,它能显示出一组数据的最大值、最小值、中位数及上下四分位数,使用四分位数范围函数的方法可以确定“离群值”的点。具体用法如下:
seaborn.boxplot(x=None, y=None, hue=None, data=None, order=None,
hue_order=None, orient=None, color=None, palette=None, saturation=0.75,
width=0.8, dodge=True, fliersize=5, linewidth=None, whis=1.5, notch=False, ax=None, **kwargs)
参数:
- saturation:饱和度,可设置为1;
- width:float,控制箱型图的宽度大小;
- fliersize:float,用于指示离群值观察的标记大小;
- whis:可理解为异常值的上限IQR比例;
两个例子:
sns.boxplot(x="day", y="total_bill", data=tips)
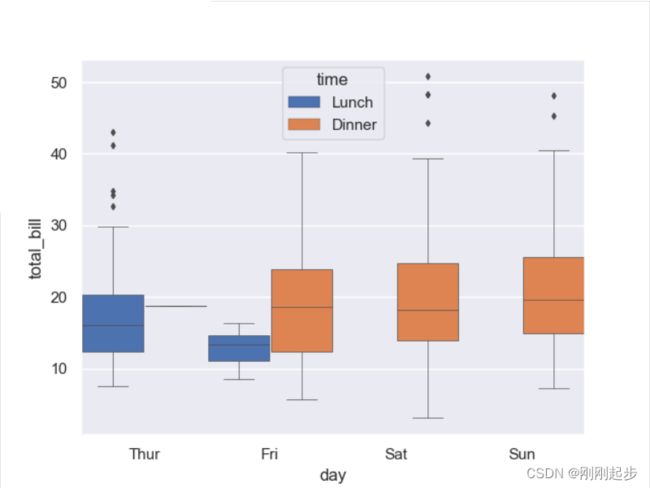
sns.boxplot(x="day", y="total_bill", hue="time",data=tips,
linewidth=0.5,saturation=1,width=1,fliersize=3)
2.2.2 violinplot(小提琴图)
violinplot(小提琴图) 就是绘制箱线图和核密度估计的组合。通过箱线图,我们可以得到数据对于分类变量的分位数,通过核密度估计,我们可以知道哪些位置的密度大。
seaborn.violinplot(x=None, y=None, hue=None, data=None, order=None,
hue_order=None, bw='scott', cut=2, scale='area', scale_hue=True, gridsize=100,
width=0.8, inner='box', split=False, dodge=True, orient=None, linewidth=None,
color=None, palette=None, saturation=0.75, ax=None, **kwargs)
参数:
- bw:‘scott’, ‘silverman’, float,
控制拟合程度。在计算内核带宽时,可以引用规则的名称(‘scott’, ‘silverman’)或者使用比例(float)。实际内核大小将通过将比例乘以每个bin内数据的标准差来确定; - cut:空值外壳的延伸超过极值点的密度,float;
- scale:“area”, “count”, “width”,用来缩放每把小提琴的宽度的方法;
- scale_hue:当使用hue分类后,设置为True时,此参数确定是否在主分组变量进行缩放;
- gridsize:设置小提琴图的平滑度,越高越平滑;
- inner:“box”, “quartile”, “point”, “stick”, None,小提琴内部数据点的表示。分别表示:箱子,四分位,点,数据线和不表示;
- split:是否拆分,当设置为True时,绘制经hue分类的每个级别画出一半的小提琴;
两个例子:
sns.violinplot(x="day", y="total_bill", data=tips)

# 设置按性别分类,调色为“Set2”,分割,以计数的方式,不表示内部。
sns.violinplot(x="day", y="total_bill", hue="sex",data=tips,
palette="Set2", split=True,scale="count", inner=None)

2.2.3 violinplot+stripplot(小提琴图+分布散点图)
sns.violinplot(x="tip", y="day", data=tips, inner=None,whis=np.inf)
sns.stripplot(x="tip", y="day", data=tips,jitter=True, color="c")
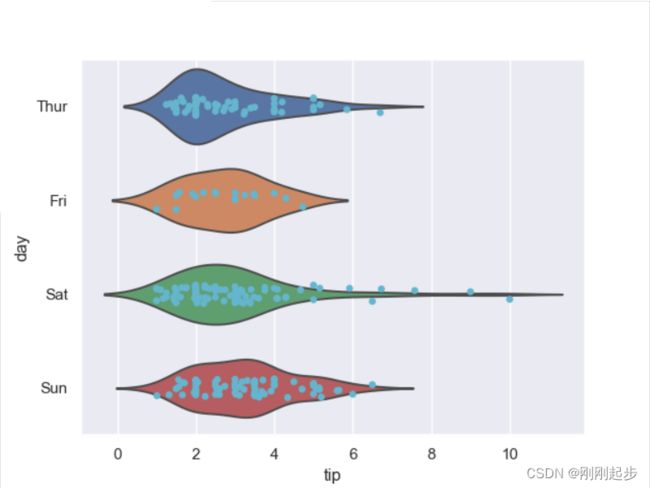
2.2.4 violinplot+swarmplot(小提琴图+分布密度散点图)
sns.violinplot(x="tip", y="day", data=tips, inner=None,whis=np.inf)
sns.swarmplot(x="tip", y="day", data=tips, color="c")
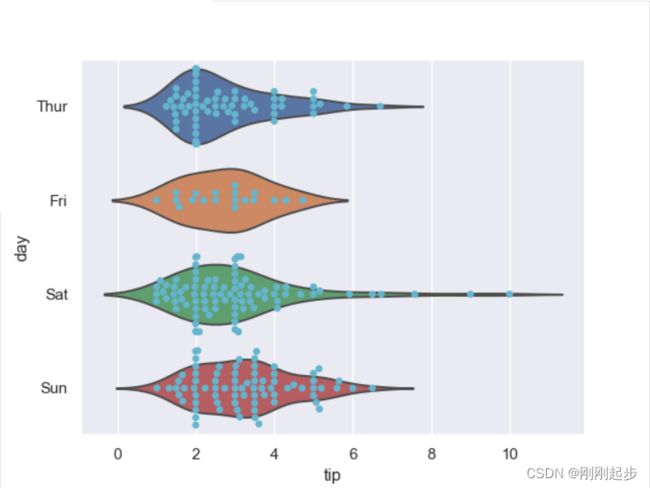
2.2.5 boxplot+stripplot(箱线图+分布散点图)
sns.boxplot(x="tip", y="day", data=tips, whis=np.inf)
sns.stripplot(x="tip", y="day", data=tips,jitter=True, color="c")
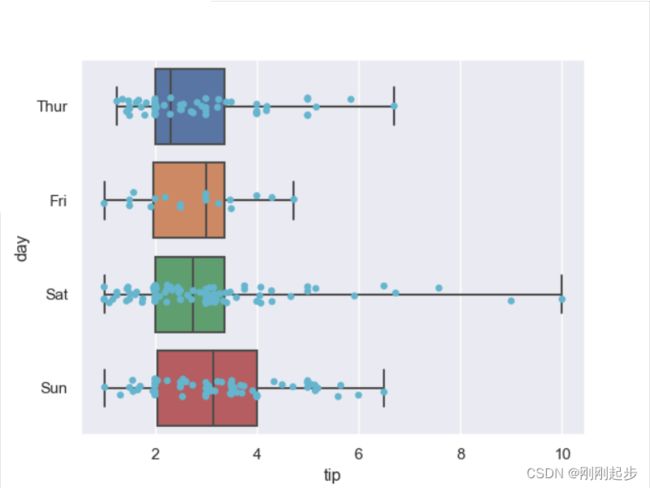
2.2.6 boxplot+swarmplot(箱线图+分布密度散点图)
sns.boxplot(x="tip", y="day", data=tips, whis=np.inf)
sns.swarmplot(x="tip", y="day", data=tips, color="c")
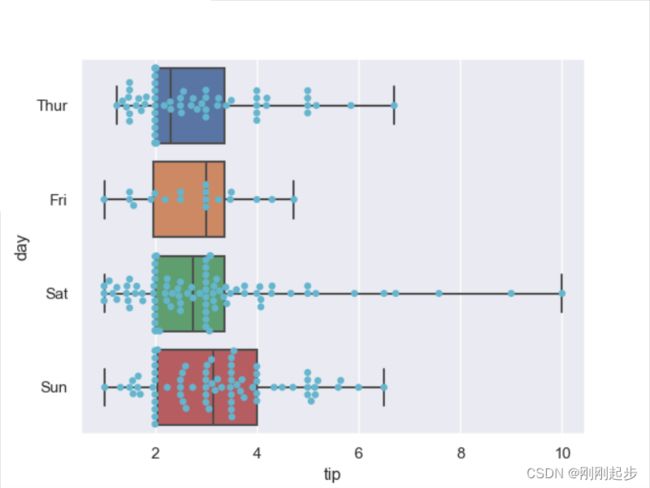
2.3 Categorical estimate plots(分类估计图)
2.3.1 barplot(条形图)
barplot(条形图) 用矩形条表示估计点和置信区间,使用误差线提供关于该估计值附近的不确定性的一些指示。
seaborn.barplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None,
estimator=<function mean>, ci=95, n_boot=1000, units=None, orient=None,
color=None, palette=None, saturation=0.75, errcolor='.26', errwidth=None,
capsize=None, dodge=True, ax=None, **kwargs)
参数:
- estimator:用于估计每个分类箱内的统计函数,默认为mean。当然你也可以设置estimator=np.median/np.std/np.var……
- order:设置特征值的顺序,例如:order=[‘Sat’,‘Sun’];
- ci:允许的误差的范围(控制误差棒的百分比,在0-100之间),若填写"sd",则用标准误差(默认为95),也可设置ci=None;
- capsize:设置误差棒帽条(上下两根横线)的宽度,float;
- errcolor:表示置信区间的线条的颜色;
- errwidth:float,设置误差条线(和帽)的厚度。
两个例子:
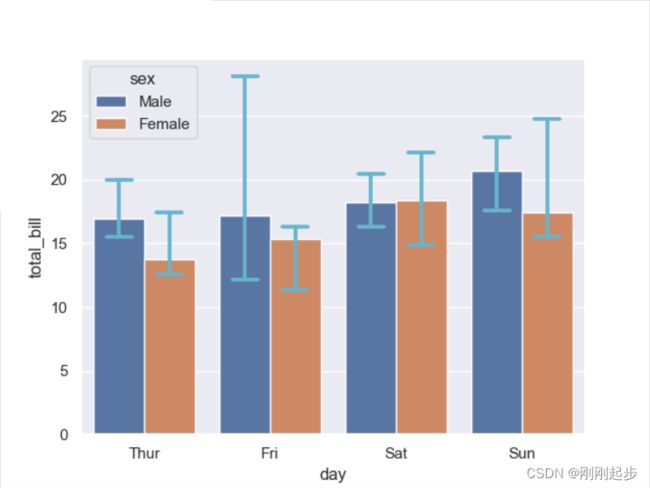
sns.barplot(x="day", y="total_bill", hue="sex", data=tips)
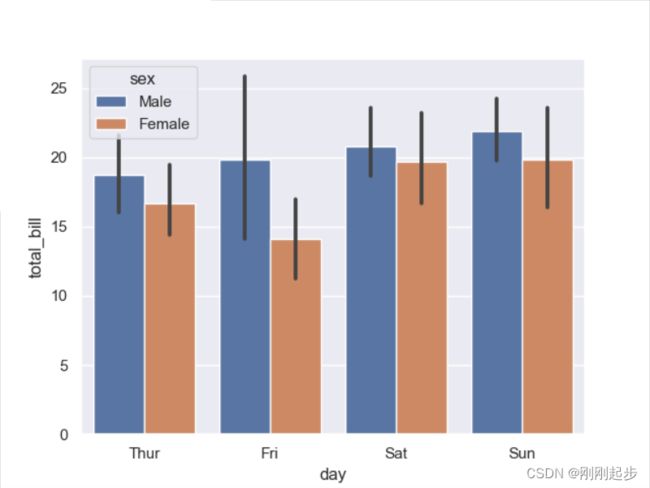
sns.barplot(x="day", y="total_bill",hue='sex', data=tips,
estimator=np.median,capsize=0.2,errcolor='c')
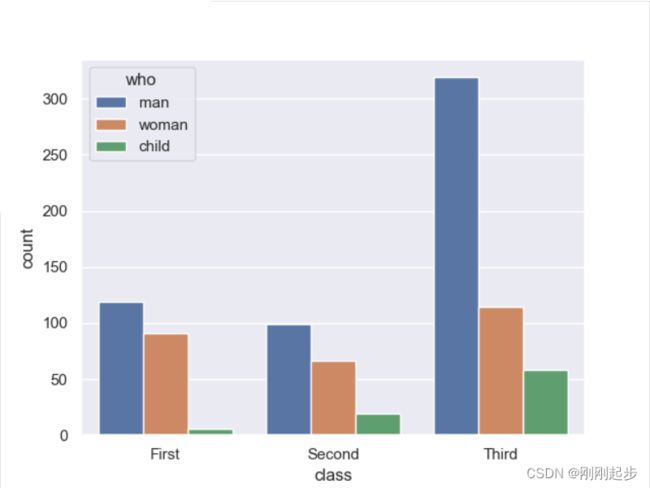
2.3.2 countplot(计数图)
countplot(计数图) 用条形图显示每个分类的观察次数,实际就是一个分类直方图。因为是用来计数的,count是一个轴,然后特征是一个轴,因此不能同时输入x和y。
seaborn.countplot(x=None, y=None, hue=None, data=None, order=None,
hue_order=None, orient=None, color=None, palette=None, saturation=0.75,
dodge=True, ax=None, **kwargs)
例子:
titanic = sns.load_dataset("titanic")
sns.countplot(x="class",hue="who", data=titanic)
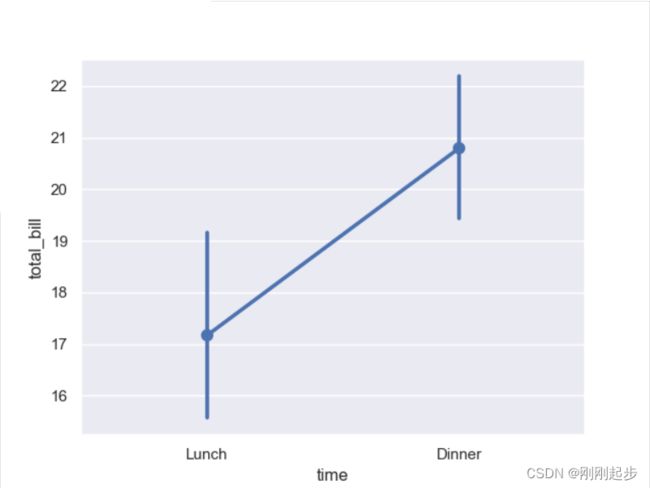
2.3.3 piontplot(点图)
piontplot(点图) 使用散点图图形显示点估计和置信区间,并使用误差线提供关于该估计的不确定性的一些指示。点图比条形图更加聚焦于变量的不同值之间的比较,可以通过点连线的斜率差异来判断。
seaborn.pointplot(x=None, y=None, hue=None, data=None, order=None,
hue_order=None, estimator=<function mean>, ci=95, n_boot=1000,
units=None, markers='o', linestyles='-', dodge=False, join=True,
scale=1, orient=None, color=None, palette=None, errwidth=None,
capsize=None, ax=None, **kwargs)
参数:
- join:默认两个统计点会相连接,若不想显示,可以通过join=False参数实现;
- scale:float,均值点(默认)和连线的大小和粗细。
两个例子:
tips = sns.load_dataset("tips")
sns.pointplot(x="time", y="total_bill", data=tips)
sns.pointplot(x="time", y="total_bill", hue="smoker",data=tips,estimator=np.median,
dodge=True, palette="Set2",markers=["o", "x"],linestyles=["-", "--"])

2.3.4 catplot()
catplot() 说白了就是对前面几个分类估计图的归约,通过kind参数来选择具体的图形。
seaborn.catplot(x=None, y=None, hue=None, data=None, row=None, col=None,
col_wrap=None, estimator=<function mean>, ci=95, n_boot=1000, units=None,
order=None, hue_order=None, row_order=None, col_order=None, kind='strip',
height=5, aspect=1, orient=None, color=None, palette=None, legend=True,
legend_out=True, sharex=True, sharey=True, margin_titles=False,
facet_kws=None, **kwargs)
它和regplot(关系图)的使用方法差不多。
参数:
- kind:默认strip(分布散点图),也可以选择“point”, “bar”, “count”,
- col、row:将决定网格的面数的分类变量,可具体制定;
- col_wrap:指定每行展示的子图个数,但是与row不兼容;
- row_order, col_order : 字符串列表,安排行和列,以及推断数据中的对象;
- height,aspect:与图像的大小有关;
- sharex,sharey:bool, ‘col’or ‘row’,是否共享x,y坐标;
两个例子:
# 绘制一个小提琴图,按数据中的kind类别分组(数据中的),不要中心框线。
exercise = sns.load_dataset("exercise")
sns.catplot(x="time", y="pulse", hue="kind",data=exercise, kind="violin",inner=None)
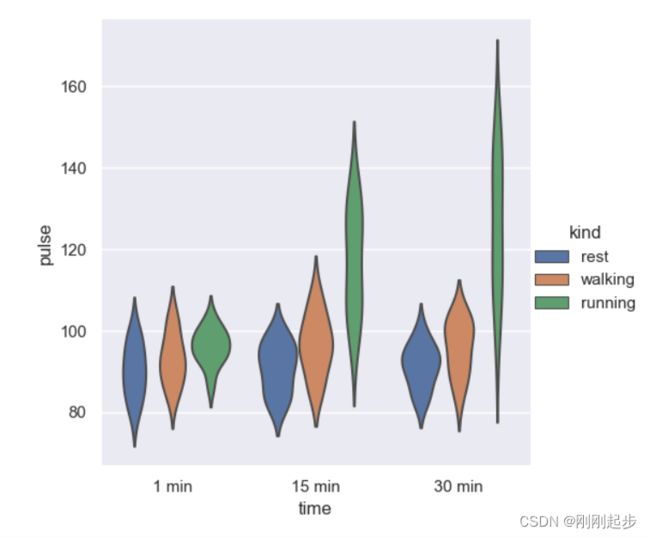
sns.catplot(x="time", y="pulse", hue="kind",kind='bar',col="diet",
data=exercise,height=4, aspect=0.8)

3. Distribution plots(分布图)
3.1 histplot(直方图)
histplot(直方图) 绘制单变量或双变量直方图,以显示数据集的分布。该函数可以对每个bin内计算的统计量进行归一化估计频率、密度或概率质量,它可以添加一个平滑的曲线得到使用内核密度估计。
histplot(
data=None, *, x=None, y=None, hue=None, weights=None,
stat="count", bins="auto", binwidth=None, binrange=None,
discrete=None, cumulative=False, common_bins=True,
common_norm=True, multiple="layer", element="bars",
fill=True, shrink=1, kde=False, kde_kws=None, line_kws=None,
thresh=0, pthresh=None, pmax=None, cbar=False, cbar_ax=None, cbar_kws=None, palette=None, hue_order=None, hue_norm=None,
color=None, log_scale=None, legend=True, ax=None, **kwargs,)
参数:
- bins:int或list,控制直方图的划分,设置矩形图(就是块儿的多少)数量,除特殊要求一般默认;
- kde:是否显示核密度估计曲线;
- common_norm:若为True,则直方图高度显示频率而非计数
两个例子:
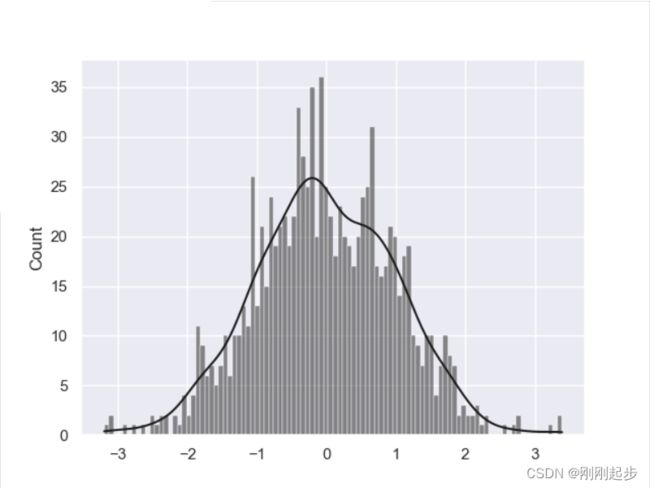
# 随机生成1000个符合正态分布的数
np.random.seed(666)
x = np.random.randn(1000)
sns.histplot(x,kde=True)
plt.show()

# 修改更多参数,设置方块的数量,颜色为‘k’
sns.histplot(x,kde=True,bins=100,color='k')
3.2 kdeplot(核密度图)
kdeplot(核密度图) 使用核密度估计绘制单变量或双变量分布。
seaborn.kdeplot(data, data2=None, shade=False, vertical=False, kernel='gau',
bw='scott', gridsize=100, cut=3, clip=None, legend=True, cumulative=False,
shade_lowest=True, cbar=False, cbar_ax=None, cbar_kws=None, ax=None, **kwargs)
参数:
- data、data2:表示可以输入双变量,绘制双变量核密度图;
- shade:是否填充阴影,默认不填充;
- vertical:放置的方向,如果为真,则观测值位于y轴上(默认False,x轴上);
- kernel:{‘gau’ | ‘cos’ | ‘biw’ | ‘epa’ | ‘tri’ | ‘triw’ }。默认高斯核(‘gau’)二元KDE只能使用高斯核。
- bw:{‘scott’ | ‘silverman’ | scalar | pair of scalars }。四类核密度带方法,默认scott (斯考特带宽法)
- gridsize:这个参数指的是每个格网里面,应该包含多少个点,越大,表示格网里面的点越多,越小表示格网里面的点越少;
- cut:参数表示,绘制的时候,切除带宽往数轴极限数值的多少,这个参数可以配合bw参数使用;
- cumulative:是否绘制累积分布;
- shade_lowest:是否有最低值渲染,这个参数只有在二维密度图上才有效;
- clip:表示查看部分结果,是一个区间;
- cbar:参数若为True,则会添加一个颜色棒(颜色棒在二元kde图像中才有);
这个函数的使用是有难度的,下面逐步学习:
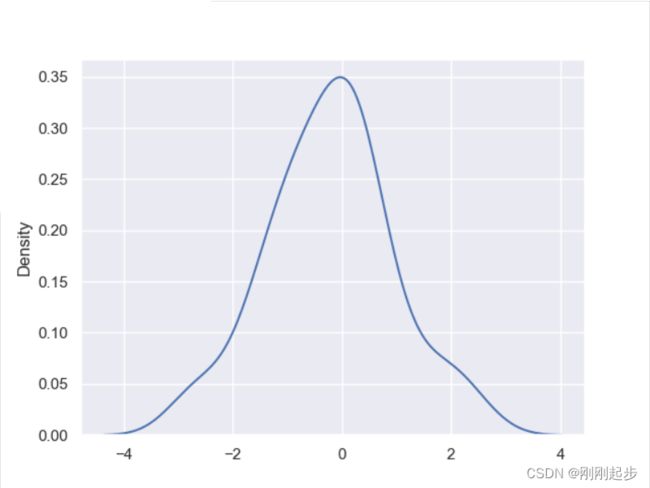
mean, cov = [0, 2], [(1, .5), (.5, 1)]
#这是一个多元正态分布,x和y都是长度为50的向量
x, y = np.random.multivariate_normal(mean, cov, size=50).T
sns.kdeplot(x)
plt.show()
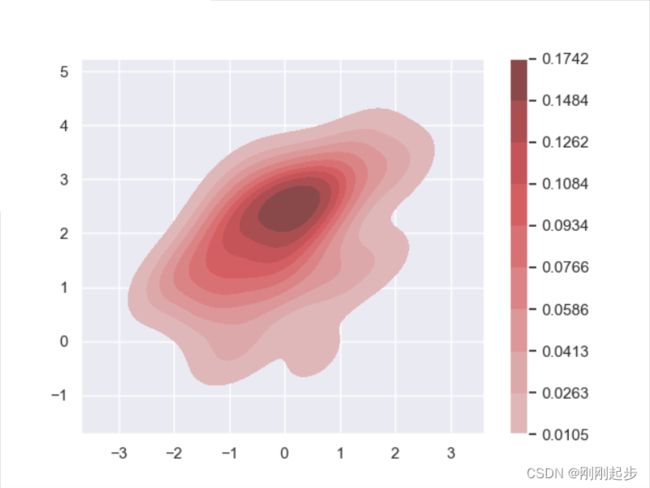
# 接下来绘制双变量核密度图①:
sns.kdeplot(x,y,shade=True,shade_lowest=False,cbar=True,color='r')
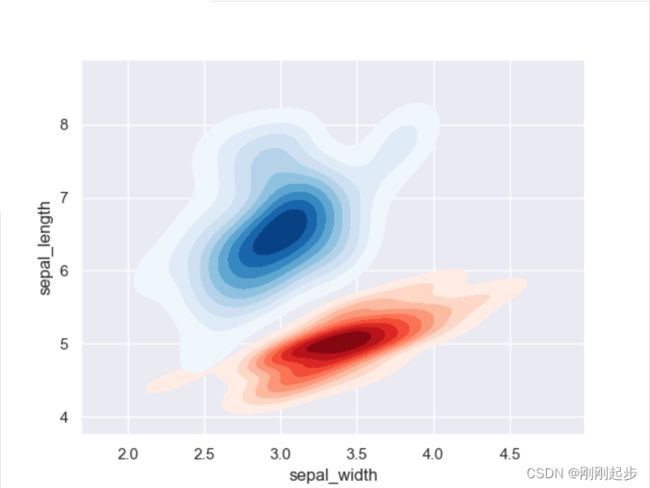
# 接下来绘制双变量核密度图②:二色二元密度图,使用大名鼎鼎的鸢尾花数据集
iris = sns.load_dataset("iris")
setosa = iris[iris.species == "setosa"]
virginica = iris[iris.species == "virginica"]
sns.kdeplot(setosa.sepal_width, setosa.sepal_length,cmap="Reds",
shade=True, shade_lowest=False)
sns.kdeplot(virginica.sepal_width, virginica.sepal_length,cmap="Blues",
shade=True, shade_lowest=False)
plt.show()
3.3 jointplot(联合分布图)
jointplot(联合分布图) 说白了就是直方图和核密度图的组合。
seaborn.jointplot(x, y, data=None, kind='scatter', stat_func=None, color=None,
height=6, ratio=5, space=0.2, dropna=True, xlim=None, ylim=None, joint_kws=None,
marginal_kws=None, annot_kws=None, **kwargs)
- x,y:为DataFrame中的列名或者是两组数据,data指向dataframe;
- kind : { “scatter” | “reg” | “resid” | “kde” | “hex” }。默认散点图;
- stat_func:用于计算统计量关系的函数;
- ratio:中心图与侧边图的比例,越大、中心图占比越大;
- dropna:去除缺失值;
- height:图的尺度大小(正方形);
- space:中心图与侧边图的间隔大小;
- xlim,ylim:x,y的范围
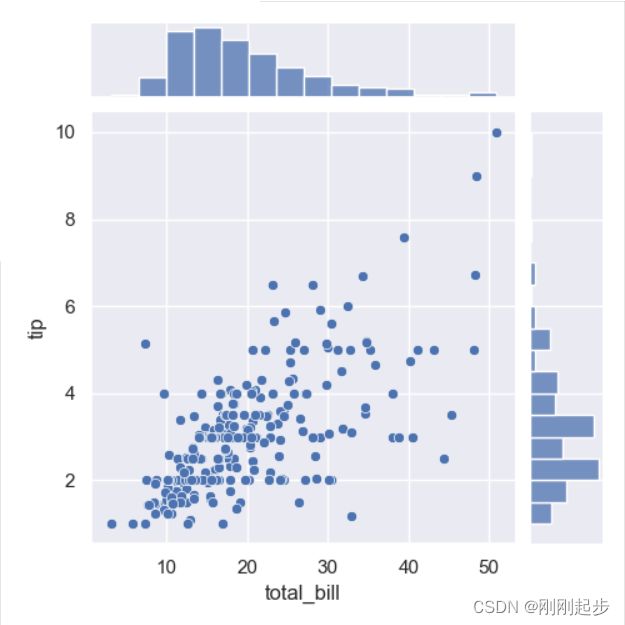
# 用边缘直方图绘制散点图
tips = sns.load_dataset("tips")
sns.jointplot(x="total_bill", y="tip", data=tips,height=5)
plt.show()
# 用密度估计替换散点图和直方图,调节间隔和比例:
iris = sns.load_dataset("iris")
sns.jointplot("sepal_width", "petal_length", data=iris,kind="kde", space=0,ratio=6 ,color="r")
plt.show()
3.4 pairplot(变量关系组图)
pairplot(变量关系组图) 描述数据集中的成对关系。默认情况下,该函数将创建一个轴网格,对角线图 描述该变量的直方图分布,非对角线图描述两个变量之间的联合分布。
seaborn.pairplot(data, hue=None, hue_order=None, palette=None, vars=None,
x_vars=None, y_vars=None, kind='scatter', diag_kind='auto', markers=None,
height=2.5, aspect=1, dropna=True, plot_kws=None, diag_kws=None,
grid_kws=None, size=None)
- vars:data中的子集,否则使用data中的每一列
- x_vars / y_vars:可以具体细分,谁与谁比较;
- kind:{‘scatter’, ‘reg’};
- diag_kind:{‘auto’, ‘hist’, ‘kde’}。对角线的图样。默认情况取决于是否使用“hue”。
两个例子:
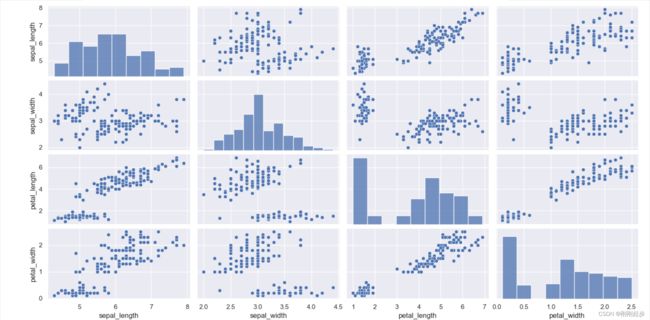
# 采用默认格式绘制鸢尾花数据集,这样对于分类问题来说并不能有效的观察数据情况。
iris = sns.load_dataset("iris")
sns.pairplot(iris)
plt.show()
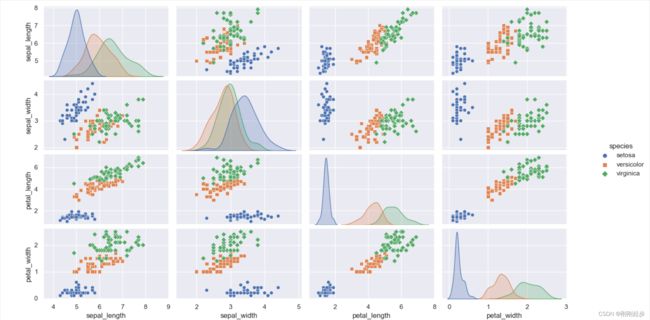
# 使用hue="species"对不同种类区分颜色绘制,并使用不同标记:
sns.pairplot(iris, hue="species", markers=["o", "s", "D"])
4. Regression plots(回归图)
4.1 regplot(回归图)
regplot(回归图) 在绘制图时自动进行线性回归模型拟合。
seaborn.regplot(x, y, data=None, x_estimator=None, x_bins=None, x_ci='ci',
scatter=True, fit_reg=True, ci=95, n_boot=1000, units=None, order=1, logistic=False,
lowess=False, robust=False, logx=False, x_partial=None, y_partial=None,
truncate=False, dropna=True, x_jitter=None, y_jitter=None, label=None, color=None,
marker='o', scatter_kws=None, line_kws=None, ax=None)
- order:多项式回归,控制进行回归的幂次,设定指数,可以用多项式拟合;
- logistic:逻辑回归;
- x_jitter,y_jitter:给x,y轴随机增加噪音点,设置这两个参数不影响最后的回归直线;
tips = sns.load_dataset("tips")
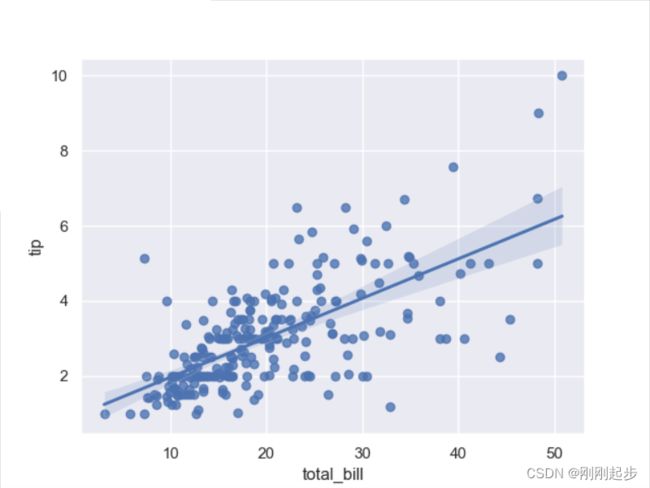
sns.regplot(x="total_bill", y="tip",data=tips)
plt.show()
4.2 lmplot(网格+回归图)
lmplot(网格+回归图) 相当于regplot(回归图)和网格的组合。
seaborn.lmplot(x, y, data, hue=None, col=None, row=None, palette=None,
col_wrap=None, height=5, aspect=1, markers='o', sharex=True, sharey=True,
hue_order=None, col_order=None, row_order=None, legend=True, legend_out=True,
x_estimator=None, x_bins=None, x_ci='ci', scatter=True, fit_reg=True, ci=95,
n_boot=1000, units=None, order=1, logistic=False, lowess=False, robust=False,
logx=False, x_partial=None, y_partial=None, truncate=False, x_jitter=None,
y_jitter=None, scatter_kws=None, line_kws=None, size=None)
- col,row:和前面一样,根据所指定属性在列,行上分类;
- col_wrap:指定每行的列数,最多等于col参数所对应的不同类别的数量;
- aspect:控制图的长宽比;
- robust:如果是True,使用statsmodels来估计一个稳健的回归(鲁棒线性模型)。这将减少异常值。请注意 logistic回归和robust回归相较于简单线性回归需要更大的计算量,其置信区间的产生也依赖于bootstrap采样,你可以关掉置信区间估计来提高速度(ci=None);
- lowess:如果是True,使用statsmodels来估计一个非参数的模型(局部加权线性回归)。这种方法具有最少的假设,尽管它是计算密集型的,但目前无法为这类模型绘制置信区间;
两个例子:
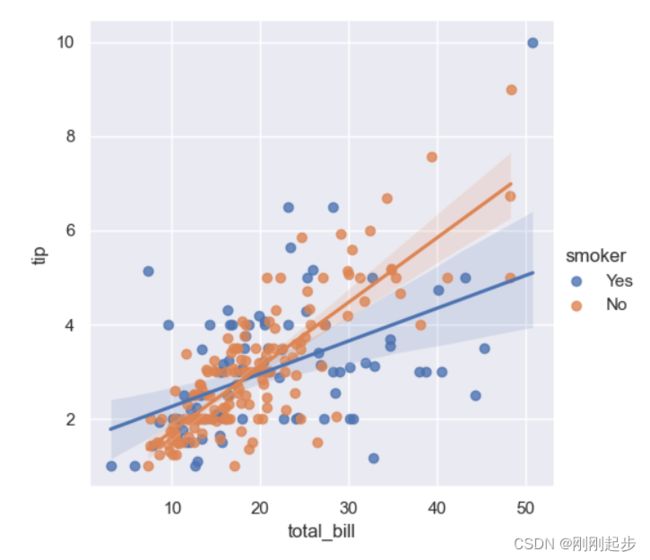
# 绘制一个第三个变量的条件,并绘制不同颜色的回归图
tips = sns.load_dataset("tips")
sns.lmplot(x="total_bill", y="tip", hue="smoker", data=tips)
plt.show()
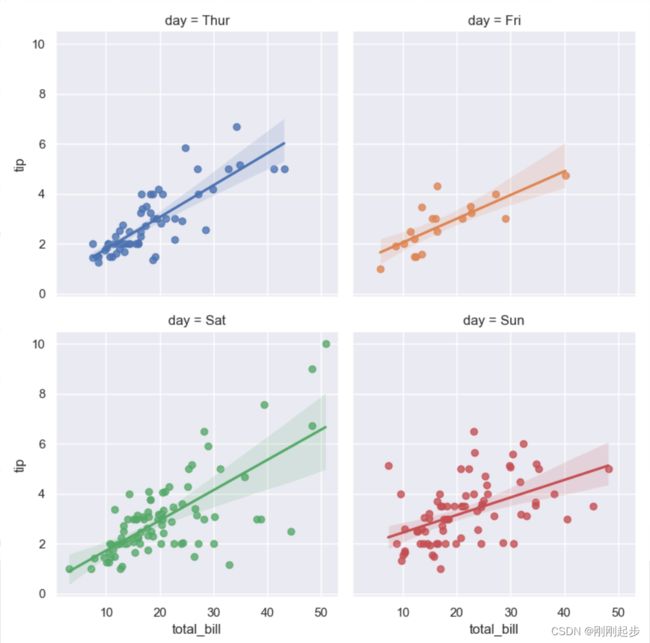
# 将变量分为多行,并改变大小:
sns.lmplot(x="total_bill", y="tip", col="day", hue="day", data=tips,
col_wrap=2, height=4)
5. Matrix plots(矩阵图)
5.1 heatmap(热力图)
利用热力图可以看数据表里多个特征两两的相关性,类似于色彩矩阵。
seaborn.heatmap(data, vmin=None, vmax=None, cmap=None, center=None,
robust=False, annot=None, fmt='.2g', annot_kws=None, linewidths=0, linecolor='white',
cbar=True, cbar_kws=None, cbar_ax=None, square=False, xticklabels='auto',
yticklabels='auto', mask=None, ax=None, **kwargs)
- data:矩阵数据集,可以使numpy的数组(array),如果是pandas的dataframe,则df的index/column信息会分别对应到heatmap的columns和rows;
- vmax,vmin:图例中最大值和最小值的显示值,没有该参数时默认不显示;
- cmap:从数字到色彩空间的映射,取值是matplotlib包里的colormap名称或颜色对象,或者表示颜色的列表;
- center:数据表取值有差异时,设置热力图的色彩中心对齐值。通过设置center值,可以调整生成的图像颜色的整体深浅;设置center数据时,如果有数据溢出,则手动设置的vmax、vmin会自动改变 ;
- robust:默认取值False;如果是False,且没设定vmin和vmax的值,热力图的颜色映射范围根据具有鲁棒性的分位数设定,而不是用极值设定;
- annot(annotate的缩写):默认取值False;如果是True,在热力图每个方格写入数据;如果是矩阵,在热力图每个方格写入该矩阵对应位置数据;
- fmt:字符串格式代码,矩阵上标识数字的数据格式,比如保留小数点后几位数字;
- annot_kws:默认取值False;如果是True,设置热力图矩阵上数字的大小颜色字体;
- square:设置热力图矩阵小块形状,默认值是False;
- xticklabels, yticklabels:控制每行列标签名的输出。默认值是auto,自动选择标签的标注间距,将标签名不重叠的部分(或全部)输出。如果是True,则以DataFrame的列名作为标签名;
- mask:控制某个矩阵块是否显示出来。默认值是None。如果是布尔型的DataFrame,则将DataFrame里True的位置用白色覆盖掉。
两个例子:
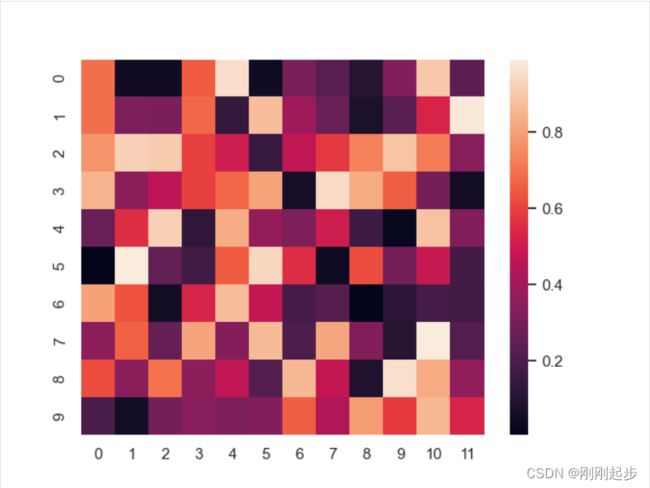
# 绘制一个简单的numpy数组的热力图:
x = np.random.rand(10, 12)
sns.heatmap(x)
plt.show()
# 显示数字和保留几位小数,并修改数字大小字体颜色格式:
x= np.random.rand(10, 10)
sns.heatmap(x,annot=True,annot_kws={'size':9,'weight':'bold', 'color':'w'},fmt='.2f')
plt.show()
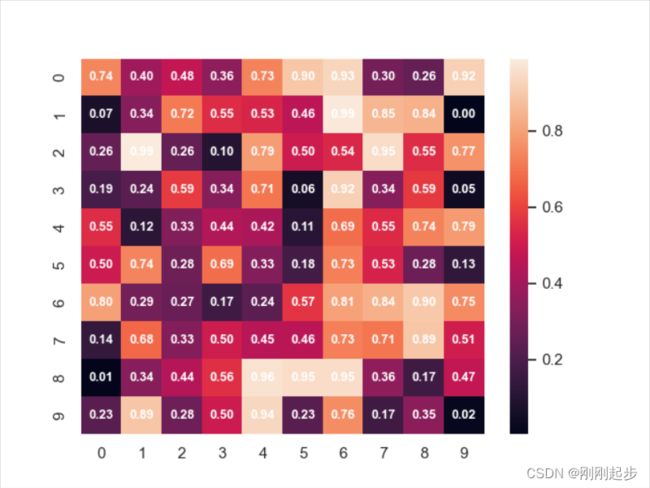
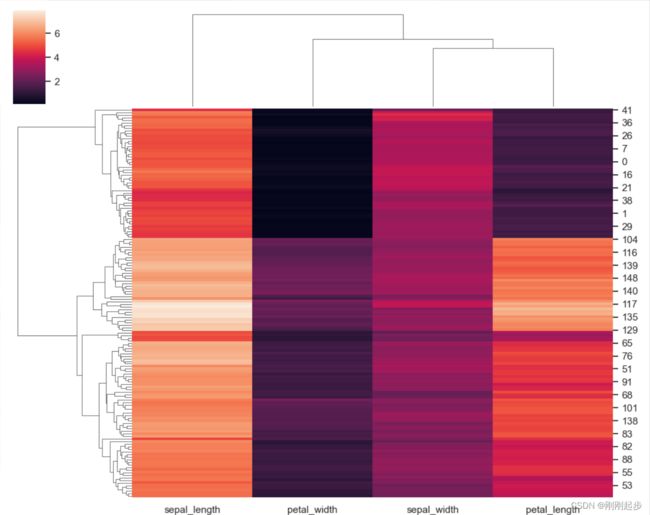
5.2 clustermap(聚类图)
clustermap() 可以将矩阵数据集绘制为层次聚类热图。说实话不太懂。
seaborn.clustermap(data, pivot_kws=None, method='average', metric='euclidean',
z_score=None, standard_scale=None, figsize=None, cbar_kws=None, row_cluster=True,
col_cluster=True, row_linkage=None, col_linkage=None, row_colors=None, col_colors=None,
mask=None, **kwargs)
# 抛砖引玉的画一下图
iris = sns.load_dataset("iris")
species = iris.pop("species")
sns.clustermap(iris)
plt.show()
6. FacetGrid()
FacetGrid() 用于初始化网格对象,每一个子图都称为一个格子。它其实就是我们之前学的relplot(),catplot()以及lmplot()这几个函数的一个上层类,我们可以根据自己的需求定制每个格子中画什么样的图形,使用更加自由。
在大多数情况下,与直接使用FacetGrid相比,使用图形级函数(例如relplot()或catart()要好得多。
seaborn.FacetGrid(data, row=None, col=None, hue=None, col_wrap=None,
sharex=True, sharey=True, height=3, aspect=1, palette=None,
row_order=None, col_order=None, hue_order=None, hue_kws=None,
dropna=True, legend_out=True, despine=True, margin_titles=False,
xlim=None, ylim=None, subplot_kws=None, gridspec_kws=None, size=None)
FacetGrid并不能直接绘制我们想要的图像,它的基本工作流程是FacetGrid使用数据集和用于构造网格的变量初始化对象。然后,可以通过调用FacetGrid.map()或将一个或多个绘图函数应用于每个子集 FacetGrid.map_dataframe(),最后,可以使用其他修改参数的方法调整绘图。
直接看例子:
# 使用TIPS数据集初始化2x2个面网格:
tips = sns.load_dataset("tips")
sns.FacetGrid(tips, col="time", row="smoker") # 2*2
plt.show()
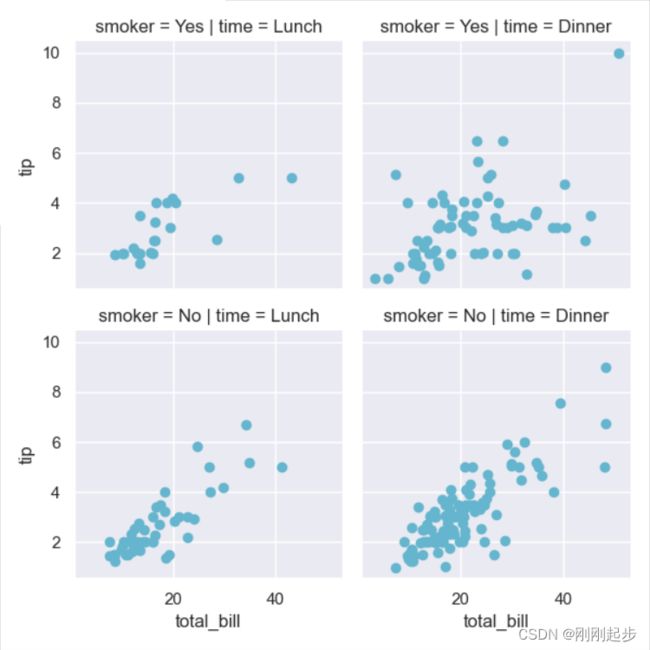
# 然后,在每个格子上绘制一个散点图,根据列和行进行分类,描述两个变量的联合分布:
tips = sns.load_dataset("tips")
g = sns.FacetGrid(tips, col="time", row="smoker")
g = g.map(plt.scatter, "total_bill", "tip", color="c") # g.map()需要传入一个绘图函数
plt.show()
我们来对比一下FacetGrid.map()绘图与relplot()、catplot()、lmplot()绘图的区别(这里只比较relplot()来绘制散点图):
sns.relplot(x="total_bill", y="tip", color="c",col="time", hue="smoker",data=tips)
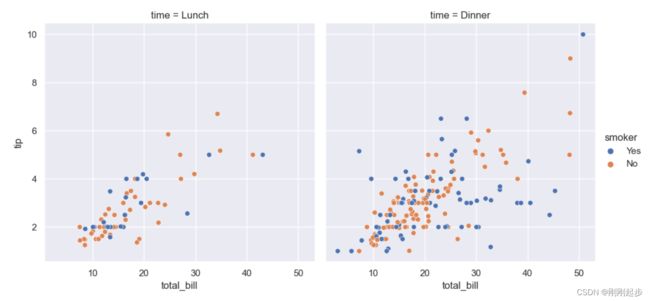
显然,在大多数情况下,与直接使用FacetGrid相比,使用图形级函数(例如relplot()或catart()要好得多。
7. PairGrid()
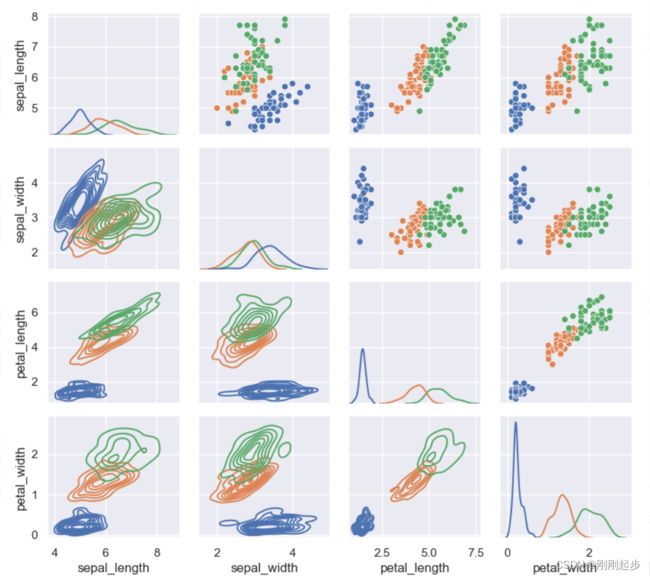
PairGrid() 用于绘制数据集中成对关系的子图网格。它的原理和我们之前的pairplot是一样的,但是前面我们可以发现pairplot绘制的图像上、下三角形是关于主对角线对称的,而PairGrid则可修改上、下三角形和主对角线的图像形状。
iris = sns.load_dataset("iris")
g = sns.PairGrid(iris,hue="species")
g = g.map_upper(sns.scatterplot)#在上对角线子图上用二元函数绘制的图
g = g.map_lower(sns.kdeplot)#在下对角线子图上用二元函数绘制的图
g = g.map_diag(sns.kdeplot)#对角线单变量子图
plt.show()
8. 主题和颜色
8.1 主题(style)
seaborn设置风格的方法主要有三种:
set,通用设置接口set_style,风格专用设置接口,设置后全局风格随之改变axes_style,设置当前图(axes级)的风格,同时返回设置后的风格系列参数,支持with关键字用法
seaborn中主要有以下几个主题:
sns.set_style("whitegrid") # 白色网格背景
sns.set_style("darkgrid") # 灰色网格背景
sns.set_style("dark") # 灰色背景
sns.set_style("white") # 白色背景
sns.set_style("ticks") # 四周加边框和刻度
例子:
# 用不同风格的背景来画直方图
np.random.seed(666)
x = np.random.randn(1000)
plt.subplot(231)
plt.hist(x)
plt.title('style=matplotlib')
with sns.axes_style('darkgrid'):
plt.subplot(232)
sns.histplot(x)
plt.title('style=darkgrid')
with sns.axes_style('whitegrid'):
plt.subplot(233)
sns.histplot(x)
plt.title('style=whitegrid')
with sns.axes_style('ticks'):
plt.subplot(234)
sns.histplot(x)
plt.title('style=ticks')
with sns.axes_style('dark'):
plt.subplot(235)
sns.histplot(x)
plt.title('style=dark')
with sns.axes_style('white'):
plt.subplot(236)
sns.histplot(x)
plt.title('style=white')
plt.tight_layout()
plt.show()

相比matplotlib绘图风格,seaborn绘制的直方图会自动增加空白间隔,图像更为清爽。而不同seaborn风格间,则主要是绘图背景色的差异。
8.2 环境(context)
设置环境的方法也有3种:
set,通用设置接口set_context,环境设置专用接口,设置后全局绘图环境随之改变plotting_context,设置当前图(axes级)的绘图环境,同时返回设置后的环境系列参数,支持with关键字用法
sns.plotting_context("notebook") # 默认
sns.plotting_context("paper")
sns.plotting_context("talk")
sns.plotting_context("poster")
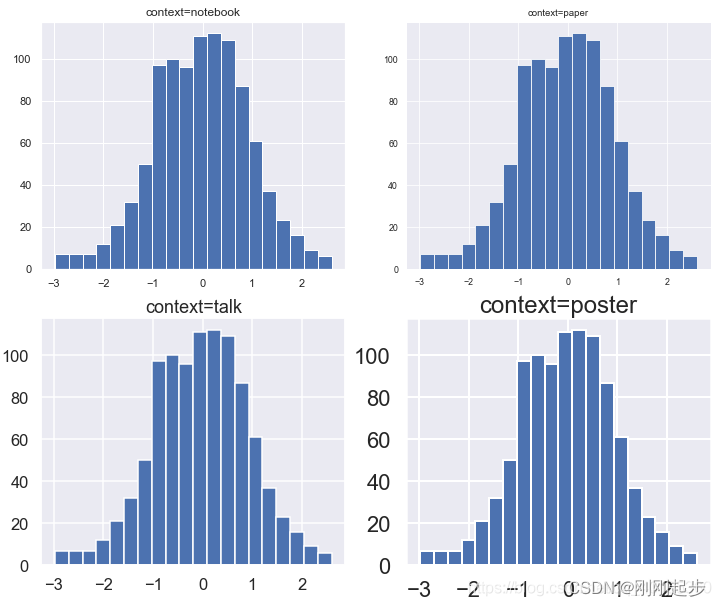
可以看出,4种默认绘图环境最直观的区别在于字体大小的不同,而其他方面也均略有差异。
8.3 颜色(color_plette())
seaborn风格多变的另一大特色就是支持个性化的颜色配置。颜色配置的方法有多种,常用方法包括以下两个:
- color_palette,基于RGB原理设置颜色的接口,可接收一个调色板对象作为参数,同时可以设置颜色数量
- hls_palette,基于Hue(色相)、Luminance(亮度)、Saturation(饱和度)原理设置颜色的接口,除了颜色数量参数外,另外3个重要参数即是hls
同时,为了便于查看调色板样式,seaborn还提供了一个专门绘制颜色结果的方法palplot。

补充
Seaborn入门详细教程