20数学建模C-中小微企业的信贷决策


前言
源码文末获取
小编在 9 月份参加了今年的数学建模,成绩怎么样不知道,能有个成功参与奖就不错了哈哈~
最近整理了一下,写下这篇文章分享小编的思路。
能力知识水平有限,欢迎各位大佬前来指教\(^o^)/~
主要分享的是模型的使用思路,策略怎么分配的就不说了。
全过程使用的语言为 Python,数据预处理 pandas 库,可视化 pyecharts 库,模型用到了 RFM,KMeans,KNN,Logit。
题目及数据
先来看看题目:


再来看看数据,有三个附件,附件1与附件2有比较大,几十 M 的大小。
附件1中又有三张表,企业信息,进项发票信息,销项发票信息:
附件2中也有三张表,企业信息,进项发票信息,销项发票信息:
附件3一张表:
导入数据
为了方便查看数据,先把数据导入,使用 pandas 库导入即可,可以分别导入不同的表。
把每一张表命名为 dfn_m,n 为附件 n,m 为附件中的第几张表:

数据是很多的,是几十万条,想全部一一查看不太可能,所以导入也仅仅显示前五行的数据样本。
附件1中的三张表:
附件2中的三张表:
附件3中的表:

RFM 模型
第一题要我们对这些公司分配信贷策略,那到底怎么分,每家公司分配多少,题目没有给出一个标准。
所以小编在这里想到的是客户价值分层模型 RFM,在这里,客户是每个公司,价值是每个公司是否具有还款能力。
RFM 模型,在一定时间窗口,R 时间窗口内最近一次消费离现在的时间,F 时间窗口内消费频率,M 时间窗口消费金额。
在这个问题中,没有这些数据,而我们是利用 RFM 模型的思想,找出几个指标,利用这些指标对公司进行分层。
我们经过查阅资料,发现影响公司是否能还款的因素有很多复杂的,但在此问题中,我们没有那么多数据,利用现有数据挖掘。
于是,有这三个影响公司能否还贷的指标是可以利用现有数据构造出来的,成立年限,客户数 ,年均收益率。
成立年限,每家公司的成立年限,第一张发票时间到最后一张发票时间的差值作为成立年限,以月为单位,因为附件1有销项,进项两张表,所以计算结果取大的值:

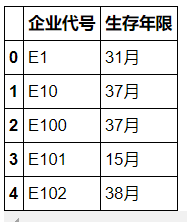
客户数,查阅资料了解到,一家公司客户数越多,经营能力也相对不错,所以选择客户数作为第二个指标,以有效进项(收入)发票为依据计算:
年均收益率,这个是间接构造出来的,使用“销项价税合计”“进项价税合计”计算的,先计算每一家公司这两个指标,当然计算是计算有效发票的:

在计算时,把其他指标也顺便一起计算出来,每个企业的进项,作废发票数,有效发票数:

每个企业的销项作废发票数,有效发票数:
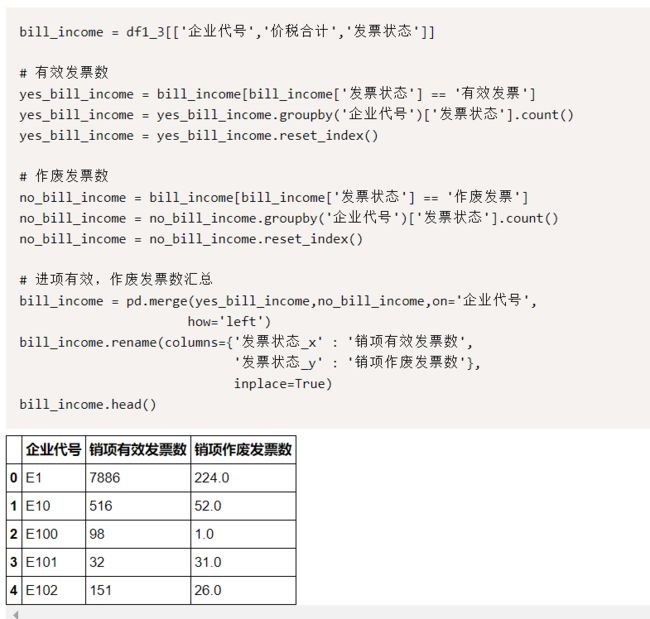
最后,生存年限,需要把月转为年为单位的,年均利率=(销项价税合计-进项加税合计)/进项价税合计,在除以生存年限,最后得到处理后的数据:


把三个指标数据单独提出来:

这样根据 RFM 模型的思想再结合数据构造出了分层用的指标。
KMeans
在构造完指标后,那接下来就对公司分层,这里映射的问题为对每个公司分类,把相似的公司聚类在一起。
何为相似,根据那三个指标,把距离相近的聚类到一起,聚类到一起的可以认为他们是属于同一类,也就是话说聚类到一起的公司还款能力是相似的。
根据这思想,使用 KMeans 聚类算法,进行聚类,因为在数据中每个公司都有“信誉评级”这个变量,有 ABCD 四个取值,所以聚类的簇数为 4。
KMeans 的思想是,设置初始聚类中心数,计算每一个样本到这个中心的距离,离哪个中心近就归为哪一类,在取平均值作为中心重复上面步骤,直到聚类中心变化不大。
使用 sklearn 库中的 KMeans 算法,把公司分为 4 类,最后一列种类为聚类结果,取值为 0-3:
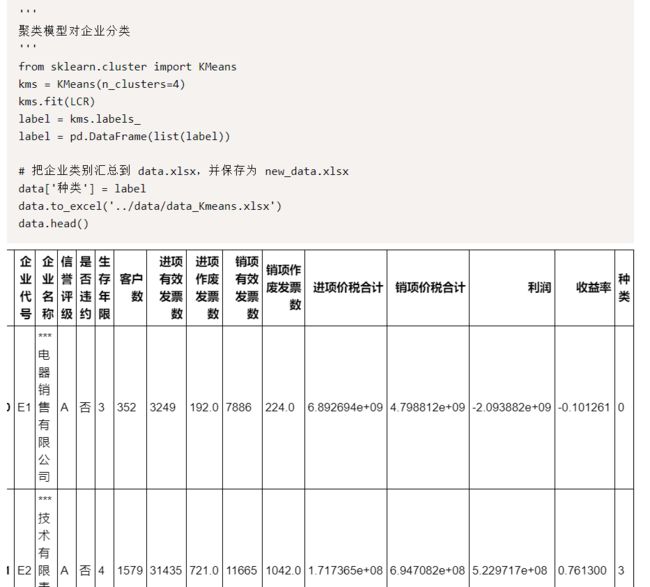
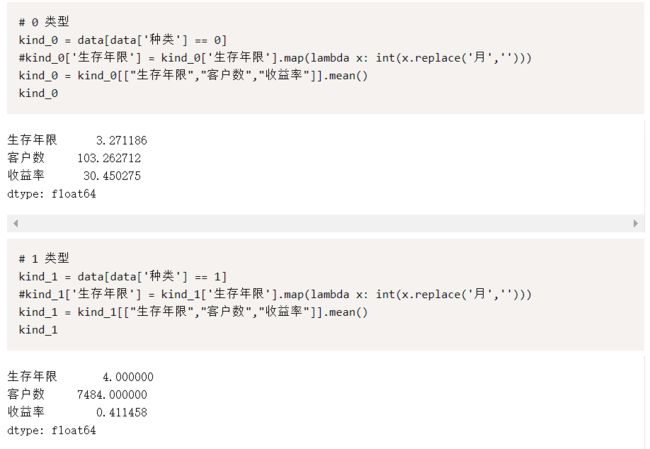
聚类得到结果后,我们需要知道这四类,都有什么特征,分别计算着四类三个指标的平均值,以 0-1 种类为例:
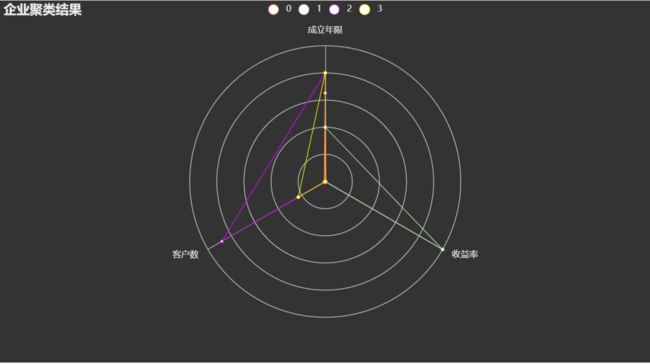
使用 pyecharts 可视化库,把聚类聚量化出来,我们使用雷达图进行对比:

然后根据每一类公司进行策略分配,怎么分配结合金融方面的知识吧,这样第一题就算完成了。
KNN 模型
第二题,和第一题类似,需要分配策略,在数据上,附件1比附件二多了“信誉评级”“是否违约”这两个变量,其他都一样。
所以这里的问题是要得到这两个变量,也就是预测分类问题。
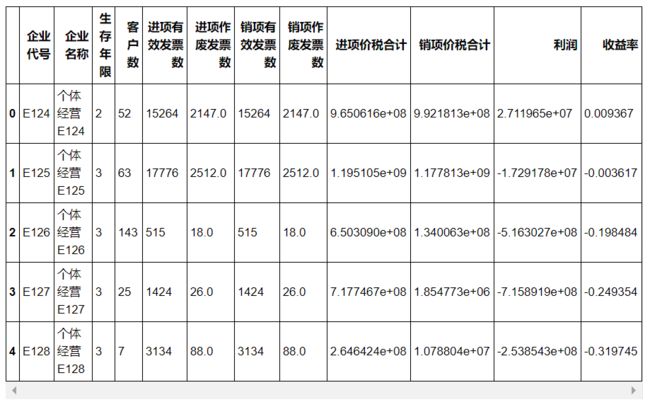
对于“信誉评级”,有 ABCD 四个取值,我们之前把附件1的数据已经处理成这样了:
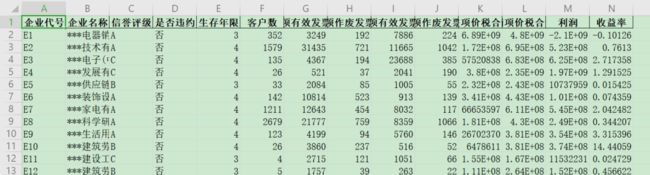
把这份数据作为训练集,也就是构造模型的数据集,取除掉 ABCD 四列的其他列作为 x,“信誉评级”作为 y,也就是标签,训练模型。
KNN 模型的思想是设置一个 n,当有一个新样本时,选择离它最近的 n 个样本,这 n 个样本中,哪个种类的数量多,那这个新样本就属于哪一类。
我们使用附件1处理后的数据训练构造模型,再使用构造的模型,检验预测“信誉评级”的准确率,也就是使用处理后的数据作为测试集与真实的数据对比得到准确率:

当 n 为 2 时,准确率为 72%,效果可以接受。
把附件2处理为跟附件一处理后一样的形式,也就是重复使用处理附件1的代码得到结果:
调用模型,分类预测附件2中每个公司的“信誉评级”:

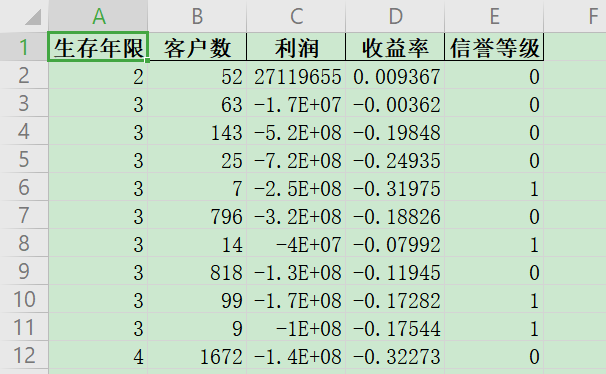
这样我们就通过 KNN 模型得到了附件2中原来没有的“信誉评级”这个变量。
Logit 模型
“是否违约”这个变量也需要我们进行预测,处理后的附件1,以“是否违约”作为 y,其他几个数值变量作为 x,训练模型。
Logit 模型,就是逻辑回归,一种分类模型,常用于二分类,原理是把 x 带进模型,得到的 y 在 0-1 之间,大于 0.5 归类为 1,小于 0.5 归类为 0。
在逻辑回归中,变量需要数值化,标准化,还是使用 sklearn 库,训练的模型测试,与真实结果对比,还可以查看各个项的系数:

准确率达到 97.5%,模型可用,处理后的附件2作为预测数据:
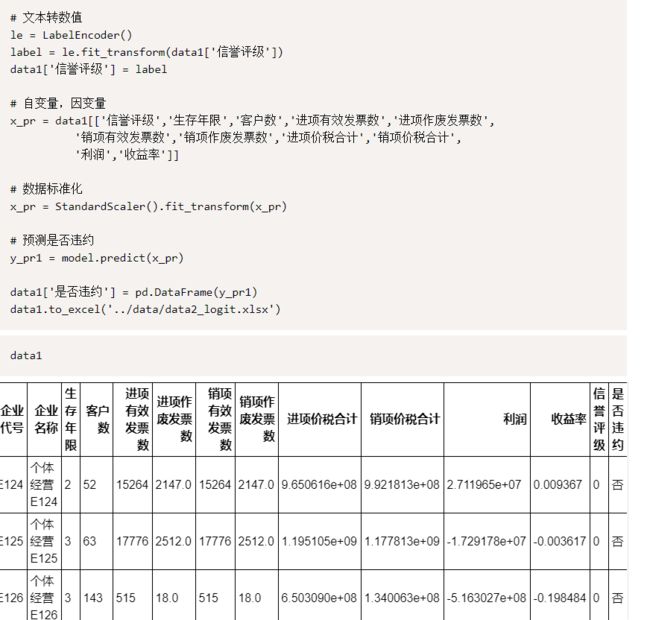
最后两列可以看到,是通过模型得到的结果,然后又根据金融什么的知识来分配啥的,这里就不写了。
第三题就没做了。。。。。。
源码获取
扫描文末二维码,关注公众号,回复关键字“20建模”获取
END
读者交流群已建立,找到我备注 “交流”,即可获得加入我们~
听说点 “在看” 的都变得更好看呐~
关注关注小编呗~小编给你分享爬虫,数据分析,可视化的内容噢~
扫一扫下方二维码即可关注我噢~
-END-
