谷歌联合CMU提出全新语义金字塔概念,无需额外训练使LLMs学会执行视觉任务

论文链接:https://arxiv.org/abs/2306.17842
代码仓库:https://github.com/google-research/magvit/
在目前的大模型社区中,发展较为成熟的当属以ChatGPT为代表的纯语言模型(LLMs),以GPT-4为代表的多模态模型发展相对较慢。因此如何进一步挖掘和激发现有LLMs的内在潜力已经成为一个非常有趣的方向,研究者们开始思考如何仅通过冻结的LLMs来执行涉及图像或视频等非语言模态的理解和生成任务。
本文介绍一篇来自谷歌研究院与卡内基梅隆大学合作完成的工作,在这项工作中,作者团队提出了一种全新的“语义金字塔自编码器(Semantic Pyramid AutoEncoder,SPAE)”概念,意在将输入的视觉内容转换为包含丰富语义的token,该token呈现金字塔结构的多尺度表示,金字塔上层包含了较强的语义中心概念(semantic-central concepts),金字塔底层则侧重于捕获将输入图像重构所需要的细节外观表示。这种设计可以将输入的视觉信息直接转换为LLMs可以理解的嵌入空间token,使得模型可以直接执行后续的多种多模态任务,而无需像其他多模态大模型一样使用海量的图像文本对进行预训练,大大降低了模型成本。作者分别使用谷歌的PaLM 2和OpenAI的GPT 3.5模型作为基础LLM模型进行实验,在多种图像理解和生成任务上进行上下文学习(In-Context Learning)评估,实验结果表明,SPAE可以赋予原生LLMs理解生成视觉内容的能力,在相同实验设置下可以超过其他图像理解SOTA性能约25%。
01. 引言
目前社区内常见的LLMs通常以Transformer为基础backbone,这使得它们在广泛的自然语言处理任务上具有天然的优势,尤其是在经过大规模语料库预训练后,LLMs在一些特定领域中甚至出现了“涌现”现象,例如智能问答、代码生成、推理、解决数学问题等多种复杂任务。目前已经证明,LLMs在其词汇嵌入中捕获了有关自然场景中的丰富概念知识。这就引出了一个很自然的问题:如果提供适当的视觉表示作为输入,LLMs能否解决视觉模态中的复杂任务? 事实是,不使用视觉样本进行微调,想让LLMs直接编码和理解视觉内容是一个极具挑战性的任务。
为了赋予LLMs解决这类跨模态任务的能力,本文提出了SPAE方法,SPAE主要通过学习一组特征编码器来将图像或其他非语言模态信息映射到LLMs的token空间,然后可以借助LLMs强大的语义理解和生成能力来完成各种视觉任务。此外,SPAE还设置了一个额外的解码器来将编码得到的语义token转换回像素空间,构建起视觉空间到LLMs嵌入空间的信息传输桥梁。在具体实现时,SPAE提供了一种新型的语义金字塔结构,该结构可以动态调整视觉编码特征的长度来适应到多种下游任务中,例如使用较少的token来执行理解任务,使用较多的token来执行生成任务。作者提到,SPAE方法并没有对LLMs进行任何形式的参数更新,只对引入的编码器和解码器进行独立训练。此外,SPAE还具有即插即用的特点,可以兼容任意的LLMs。
02. 本文方法
设计语义金字塔自编码器(SPAE)的目标是将图像或其他非语言模态(例如视频或音频)建模为LLMs可以直接理解的token序列,该token序列的长度可以进行动态调整来适应不同的下游任务,SPAE的整体框架示意图如下图所示。

2.1 语义金字塔自编码器

2.2 渐进式的上下文去噪


03. 实验效果
为了验证本文方法的灵活性以及与不同LLMs的兼容性,作者选取了两个具有代表性的LLMs(PaLM 2和GPT 3.5)进行实验,构建了SPAE的两种变体,即SPAEPaLM和SPAEGPT.为了与之前的方法进行公平对比[28],SPAE的编码器可以将128×128大小的图像编码为具有6层的token金字塔。本文的实验包含常规的视觉分类任务和复杂的视觉理解和推理任务,对于前者,作者在mini-ImageNet上的few-shot分类基准上进行。

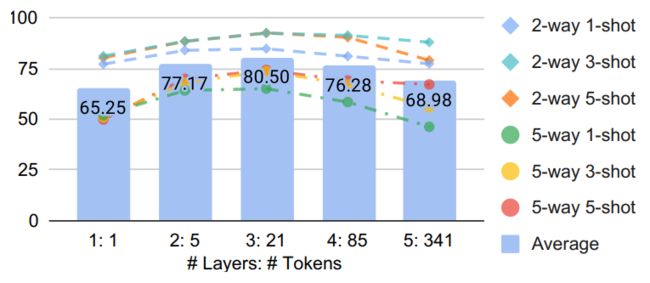
上表展示了SPAE与其他基线方法的对比情况,可以看到,SPAE的两个版本的小样本识别性能均高于对比基线方法。下图进一步展示了本文方法在六种其他few-shot设置中的性能表现,可以看到,使用3层的21个token的SPAEPaLM达到了最佳性能,这表示SPAE可以在语义概念纯度和序列长度之间进行权衡。
此外作者也进一步探索了SPAE在其他下游任务上的性能表现,对于图像到文本生成任务和VQA任务,作者分别选取了来自COCO数据中的10个样本示例作为LLMs的提示信息,然后使用SPAE的不同金字塔层进行文本生成,如下图所示。

而对于VQA任务,作者对每个样本提供10个不同的答案来构成10-way 1-shot的上下文提示,然后使用SPAE对新查询图像进行预测,下图展示了部分问答效果。

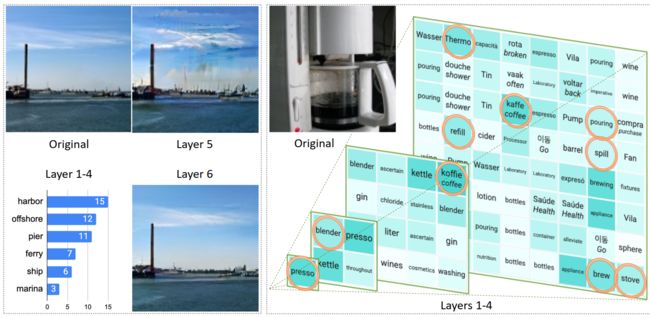
为了清晰的验证SPAE确实可以捕获到不同尺度的语义概念和图像细节信息,作者在下图中对token金字塔进行了可视化,其中1-4层为出现最高频率的token直方图,5层和6层为模型重构出来的图像。可以看到,位于顶层的几个token似乎抓住了图像的主要主题,例如图中使用橙色圆圈标注的presso代表浓缩咖啡机,而其他token(如搅拌机)则指向其周围的相关区域。此外,第3层和第4层分别表示局部对象的其他详细信息。例如,Thermo指的是图中左上角区域的温度计,而炉灶(stove)则出现在右下角区域。
04. 总结
本文引入了一种全新的多模态理解概念,即语义金字塔,作者在此基础上提出了一种SPAE框架,使大型语言模型能够直接执行涉及图像或视频等非语言模式的理解和生成任务,SPAE可以在原始像素和LLMs所包含的词表中提取可解释的token,并将二者联系起来,由此产生的token捕获了视觉重建所需的语义概念和细粒度细节,可以有效地将视觉内容翻译成LLMs可以直接理解的内容,从而使其能够执行各种多模态视觉任务。此外,SPAE具有跨模型兼容的特点,其仅需要任意一个预训练LLMs的API即可开始工作,具有非常高的灵活性和兼容性,它为我们将LLMs更快更好地引入视觉社区提供了一种全新的范式。
参考
[1] Aaron Van Den Oord, Oriol Vinyals, et al. Neural discrete representation learning. In NeurIPS, 2017. 2, 3
[2] Lijun Yu, Yong Cheng, Kihyuk Sohn, José Lezama, Han Zhang, Huiwen Chang, Alexander G Hauptmann, Ming-Hsuan Yang, Yuan Hao, Irfan Essa, t al. MAGVIT: Masked generative video transformer. In CVPR, 2023. 3, 4, 7
关于TechBeat人工智能社区
▼
TechBeat(www.techbeat.net)隶属于将门创投,是一个荟聚全球华人AI精英的成长社区。
我们希望为AI人才打造更专业的服务和体验,加速并陪伴其学习成长。
期待这里可以成为你学习AI前沿知识的高地,分享自己最新工作的沃土,在AI进阶之路上的升级打怪的根据地!
更多详细介绍>>TechBeat,一个荟聚全球华人AI精英的学习成长社区