机器学习&&深度学习——卷积神经网络(LeNet)
作者简介:一位即将上大四,正专攻机器学习的保研er
上期文章:机器学习&&深度学习——池化层
订阅专栏:机器学习&&深度学习
希望文章对你们有所帮助
卷积神经网络(LeNet)
- 引言
- LeNet
- 模型训练
- 小结
引言
之前的内容中曾经将softmax回归模型和多层感知机应用于Fashion-MNIST数据集中的服装图片。为了能应用他们,我们首先就把图像展平成了一维向量,然后用全连接层对其进行处理。
而现在已经学习过了卷积层的处理方法,我们就可以在图像中保留空间结构。同时,用卷积层代替全连接层的另一个好处是:模型更简单,所需参数更少。
LeNet是最早发布的卷积神经网络之一,之前出来的目的是为了识别图像中的手写数字。
LeNet
总体看,由两个部分组成:
1、卷积编码器:由两个卷积层组成
2、全连接层密集快:由三个全连接层组成

上图中就是LeNet的数据流图示,其中汇聚层也就是池化层。
最终输出的大小是10,也就是10个可能结果(0-9)。
每个卷积块的基本单元是一个卷积层、一个sigmoid激活函数和平均池化层(当年没有ReLU和最大池化层)。每个卷积层使用5×5卷积核和一个sigmoid激活函数。
这些层的作用就是将输入映射到多个二维特征输出,通常同时增加通道的数量。(从上图容易看出:第一卷积层有6个输出通道,而第二个卷积层有16个输出通道;每个2×2池操作(步幅也为2)通过空间下采样将维数减少4倍)。卷积的输出形状那是由批量大小、通道数、高度、宽度决定。
为了将卷积块的输出传递给稠密块,我们必须在小批量中展平每个样本(也就是把四维的输入转换为全连接层期望的二维输入,第一维索引小批量中的样本,第二维给出给个样本的平面向量表示)。
LeNet的稠密块有三个全连接层,分别有120、84和10个输出。因为我们在执行分类任务,所以输出层的10维对应于最后输出结果的数量(代表0-9是个结果)。
深度学习框架实现此类模型非常简单,用一个Sequential块把需要的层连接在一个就可以了,我们对原始模型做一个小改动,去掉最后一层的高斯激活:
import torch
from torch import nn
from d2l import torch as d2l
net = nn.Sequential(
# 输入图像和输出图像都是28×28,因此我们要先进行填充2格
nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Flatten(),
nn.Linear(16 * 5 * 5, 120), nn.Sigmoid(),
nn.Linear(120, 84), nn.Sigmoid(),
nn.Linear(84, 10)
)
上面的模型图示就为:

我们可以先检查模型,在每一层打印输出的形状:
X = torch.rand(size=(1, 1, 28, 28), dtype=torch.float32)
for layer in net:
X = layer(X)
print(layer.__class__.__name__, 'output shape:\t', X.shape)
输出结果:
Conv2d output shape: torch.Size([1, 6, 28, 28])
Sigmoid output shape: torch.Size([1, 6, 28, 28])
AvgPool2d output shape: torch.Size([1, 6, 14, 14])
Conv2d output shape: torch.Size([1, 16, 10, 10])
Sigmoid output shape: torch.Size([1, 16, 10, 10])
AvgPool2d output shape: torch.Size([1, 16, 5, 5])
Flatten output shape: torch.Size([1, 400])
Linear output shape: torch.Size([1, 120])
Sigmoid output shape: torch.Size([1, 120])
Linear output shape: torch.Size([1, 84])
Sigmoid output shape: torch.Size([1, 84])
Linear output shape: torch.Size([1, 10])
模型训练
既然已经实现了LeNet,现在可以查看它在Fashion-MNIST数据集上的表现:
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
计算成本较高,因此使用GPU来加快训练。为了进行评估,对之前的evaluate_accuracy进行修改,由于完整的数据集位于内存中,因此在模型使用GPU计算数据集之前,我们需要将其复制到显存中。
def evaluate_accuracy_gpu(net, data_iter, device=None):
"""使用GPU计算模型在数据集上的精度"""
if isinstance(net, nn.Module):
net.eval() # 设置为评估模式
if not device:
device = next(iter(net.parameters())).device
# 正确预测的数量,总预测的数量
metric = d2l.Accumulator(2)
with torch.no_grad():
for X, y in data_iter:
if isinstance(X, list):
# BERT微调所需(后面内容)
else:
X = X.to(device)
y = y.to(device)
metric.add(d2l.accuracy(net(X), y), y.numel())
return metric[0] / metric[1]
要使用GPU,我们要在正向和反向传播之前,将每一小批量数据移动到我们GPU上。
如下所示的train_ch6类似于之前定义的train_ch3。以下训练函数假定从高级API创建的模型作为输入,并进行相应的优化。
使用Xavier来随机初始化模型参数。有关于Xavier的推导和原理可以看下面的文章:
机器学习&&深度学习——数值稳定性和模型化参数(详细数学推导)
与全连接层一样,使用交叉熵损失函数和小批量随机梯度下降,代码如下:
def train_ch6(net, train_iter, test_iter, num_epochs, lr, device): #@save
"""用GPU训练模型"""
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
print('training on', device)
net.to(device)
optimizer = torch.optim.SGD(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss()
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=['train loss', 'train acc', 'test acc'])
timer, num_batches = d2l.Timer(), len(train_iter)
for epoch in range(num_epochs):
# 训练损失之和,训练准确率之和,样本数
metric = d2l.Accumulator(3)
net.train()
for i, (X, y) in enumerate(train_iter):
timer.start()
optimizer.zero_grad()
X, y = X.to(device), y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
optimizer.step()
with torch.no_grad():
metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])
timer.stop()
train_l = metric[0] / metric[2]
train_acc = metric[1] / metric[2]
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i+1) / num_batches, (train_l, train_acc, None))
test_acc = evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, '
f'test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec '
f'on {str(device)}')
此时我们可以开始训练和评估LeNet模型:
lr, num_epochs = 0.9, 10
train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
d2l.plt.show()
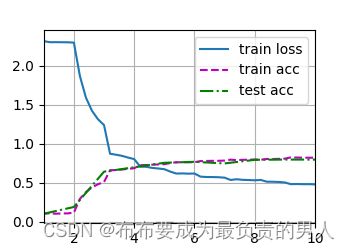
运行输出(这边我没有用远程的GPU,在自己本地跑了,本地只有CPU):
training on cpu
loss 0.477, train acc 0.820, test acc 0.795
8004.2 examples/sec on cpu
运行图片:
小结
1、卷积神经网络(CNN)是一类使用卷积层的网络
2、在卷积神经网络中,我们组合使用卷积层、非线性激活函数和池化层
3、为了构造高性能的卷积神经网络,我们通常对卷积层进行排列,逐渐降低其表示的空间分辨率,同时增加通道数
4、传统卷积神经网络中,卷积块编码得到的表征在输出之前需要由一个或多个全连接层进行处理