C++常用算法
排序算法
- sort (first, last)
对容器或普通数组中 [first, last) 范围内的元素进行排序,默认进行升序排序。 - stable_sort (first, last)
和 sort() 函数功能相似,不同之处在于,对于 [first, last) 范围内值相同的元素,该函数不会改变它们的相对位置。 - partial_sort (first, middle, last)
从 [first,last) 范围内,筛选出 muddle-first 个最小的元素并排序存放在 [first,middle) 区间中。 - partial_sort_copy (first, last, result_first, result_last)
从 [first, last) 范围内筛选出 result_last-result_first 个元素排序并存储到 [result_first, result_last) 指定的范围中。 - is_sorted (first, last)
检测 [first, last) 范围内是否已经排好序,默认检测是否按升序排序。 - is_sorted_until (first, last)
和 is_sorted() 函数功能类似,唯一的区别在于,如果 [first, last) 范围的元素没有排好序,则该函数会返回一个指向首个不遵循排序规则的元素的迭代器。 - void nth_element (first, nth, last)
找到 [first, last) 范围内按照排序规则(默认按照升序排序)应该位于第 nth 个位置处的元素,并将其放置到此位置。同时使该位置左侧的所有元素都比其存放的元素小,该位置右侧的所有元素都比其存放的元素大。
合并算法
merge() 函数用于将 2 个有序序列合并为 1 个有序序列,前提是这 2 个有序序列的排序规则相同(要么都是升序,要么都是降序)
#include
查找算法
- find(first,last,val)
其中,first 和 last 为输入迭代器,[first, last) 用于指定该函数的查找范围;val 为要查找的目标元素
#include
- find_if(first,last,pred)
first 和 last 都为输入迭代器,其组合 [first, last) 用于指定要查找的区域;pred 用于自定义查找规则。
#include![]()
-
find_if_not(first,last,pred)
find_if_not() 函数和 find_if() 函数的功能恰好相反,通过上面的学习我们知道,find_if() 函数用于查找符合谓词函数规则的第一个元素,而 find_if_not() 函数则用于查找第一个不符合谓词函数规则的元素。 -
find_end(first1, last1,first2, last2,pred)
其组合 [first1, last1) 用于指定查找范围(也就是上面例子中的序列 A)其组合 [first2, last2) 用于指定要查找的序列(也就是上面例子中的序列 B)pred自定义查找规则
#include
-
find_first_of(first1, last1,first2, last2,pred)
find_first_of() 函数用于在 [first1, last1) 范围内查找和 [first2, last2) 中任何元素相匹配的第一个元素。如果匹配成功,该函数会返回一个指向该元素的输入迭代器;反之,则返回一个和 last1 迭代器指向相同的输入迭代器。 -
adjacent_find(first,last,pred) 函数用于在指定范围内查找 2 个连续相等的元素。
#include
- search(first1, last1,first2, last2,pred)
其功能恰好和 find_end() 函数相反,用于在序列 A 中查找序列 B 第一次出现的位置。 - search_n(first1, last1,first2, last2,pred)
用于在指定区域内查找第一个符合要求的子序列。不同之处在于,search查找的子序列中可包含多个不同的元素,而search_n查找的只能是包含多个相同元素的子序列。 - lower_bound(begin,end,x,pred)
lower_bound() 函数用于在指定区域内查找不小于x目标值的第一个元素(pred可选自定义规则)
#include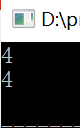
- upper_bound(begin,end,x,pred)
用于在指定范围内查找大于目标值的第一个元素。
分组算法
- partition(first,end,pred)可根据用户自定义的筛选规则,重新排列指定区域内存储的数据,使其分为 2 组,第一组为符合筛选条件的数据,另一组为不符合筛选条件的数据。
#include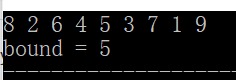
-
stable_partition(first,end,pred)
与partition一样,就是分组后组内元素相对位置不变 -
partition_copy(begin,end,r1,r2,pred)
partition_copy() 函数也能按照某个筛选规则对指定区域内的数据进行“分组”,并且分组后不会改变各个元素的相对位置。r1,r2是分组后的两个储存空间
#include
全排列算法
- next_permutation(begin,end)
下一个全排列next_permutation(begin,end)
#include
- prev_permutation
上一个全排列prev_permutation(begin,end) - is_permutation()
is_permutation() 算法可以用来检查一个序列是不是另一个序列的排列,如果是,会返回 true
#include
去重算法
- unique() 算法可以在序列中原地移除重复的元素
#include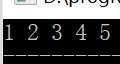
其他函数
- fill() 和 fill_n() 算法提供了一种为元素序列填入给定值的简单方式,fill() 会填充整个序列; fill_n() 则以给定的迭代器为起始位置,为指定个数的元素设置值
#include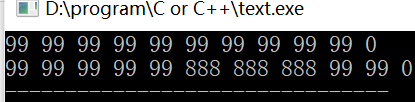
- replace()
算法会用新的值来替换和给定值相匹配的元素 - transform()
- 可以将函数应用到序列的元素上,并将这个函数返回的值保存到另一个序列中,它返回的迭代器指向输出序列所保存的最后一个元素的下一个位置。