LangChain:LLM应用程序开发(上)——Models、Prompt、Parsers、Memory、Chains
文章目录
-
- 一、Models、Prompt、Parsers
-
- 1.1 环境配置(导入openai)
- 1.2 辅助函数(Chat API : OpenAI)
- 1.3 使用OpenAI API进行文本翻译
- 1.4使用LangChain进行文本翻译
- 1.5 使用LangChain解析LLM的JSON输出
-
- 1.5.1 LangChain输出为string格式
- 1.5.2 LangChain输出解析器,解析LLM输出为字典
- 二、LangChain: Memory
-
- 2.1 ChatMessageHistory
- 2.2 ConversationBufferMemory(对话缓冲区memory)
-
- 2.2.1 直接添加memory
- 2.2.2 Using in a chain
- 2.2.3 Saving Message History
- 2.3 ConversationBufferWindowMemory(追踪最近的k次对话)
- 2.4 ConversationTokenBufferMemory(追踪最近的max_token_limit个tokens对话)
- 2.4 ConversationSummaryMemory(旧的交互保存为摘要)
-
- 2.5 其它类型memory
- 三、 Chains
-
- 3.1 LLMChain
- 3.2 SequentialChain
-
- 3.2.1 SimpleSequentialChain
- 3.2.2 SequentialChain
- 3.3 Router Chain
- deeplearning官网课程《LangChain for LLM Application Development》(含代码)、 B站中文字幕视频《LLM应用程序开发的LangChain》
- LangChain官网、LangChain官方文档、LangChain ️ 中文网
OpenAI API Key(创建API Key,以及侧边栏Usage选项查看费用)
一、Models、Prompt、Parsers
基础组件文档
- Direct API calls to OpenAI
- API calls through LangChain:
- Models:LangChain可以外接多种模型;
- Prompts:创建输入以传递给模型的方式;
- Output parsers:将模型的输出进行解析,以更结构化的方式呈现,便于后续处理。
当我们构建LLMs 应用程序时,通常会有重复提示的模型、解析器的输出,LangChain提供了简化这种操作流程的框架。
1.1 环境配置(导入openai)
导入OpenAI API和OpenAI API Key
#!pip install python-dotenv
#!pip install openai
import os
import openai
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
openai.api_key = os.environ['OPENAI_API_KEY']
1.2 辅助函数(Chat API : OpenAI)
根据OpenAI.的API编写辅助函数get_completion,这个函数会调用chatgpt(GPT 3.5 Turbo模型),然后根据输入得到响应。
def get_completion(prompt, model="gpt-3.5-turbo"):
messages = [{"role": "user", "content": prompt}]
response = openai.ChatCompletion.create(
model=model,
messages=messages,
temperature=0,
)
return response.choices[0].message["content"]
get_completion("What is 1+1?")
1+1 equals 2.
1.3 使用OpenAI API进行文本翻译
下面是一封海盗语言风格的英文邮件,我们需要将其用平静、尊重的口吻翻译为美式英语。
customer_email = """
Arrr, I be fuming that me blender lid flew off and splattered me kitchen walls \
with smoothie! And to make matters worse,the warranty don't cover the cost of \
cleaning up me kitchen. I need yer help right now, matey!
"""
style = """American English in a calm and respectful tone
"""
下面使用一个f字符串来指定prompt——将```包围的文本翻译为指定的style。
prompt = f"""Translate the text that is delimited by triple backticks
into a style that is {style}.text: ```{customer_email}```
"""
print(prompt)
Translate the text that is delimited by triple backticks
into a style that is American English in a calm and respectful tone
.
text: ```
Arrr, I be fuming that me blender lid flew off and splattered me kitchen walls with smoothie! And to make matters worse,the warranty don't cover the cost of cleaning up me kitchen. I need yer help right now, matey!
```
response = get_completion(prompt)
response
I am quite frustrated that my blender lid flew off and made a mess of my kitchen walls with smoothie! To add to my frustration, the warranty does not cover the cost of cleaning up my kitchen. I kindly request your assistance at this moment, my friend.
如果你有不同客户、不同语言不同风格写的评论,就需要像上面这样不停的使用prompt来获得结果,而LangChain可以更方便快捷的做到这一点。
1.4使用LangChain进行文本翻译
- Model
调用ChatOpenAI模型,查看其对象。
#!pip install --upgrade langchain
from langchain.chat_models import ChatOpenAI
# To control the randomness and creativity of the generated
# text by an LLM, use temperature = 0.0
chat = ChatOpenAI(temperature=0.0)
chat # 查看对象
ChatOpenAI(verbose=False, callbacks=None, callback_manager=None, client=, model_name='gpt-3.5-turbo', temperature=0.0, model_kwargs={}, openai_api_key=None, openai_api_base=None, openai_organization=None, request_timeout=None, max_retries=6, streaming=False, n=1, max_tokens=None)
- Prompt template(提示模板)
下面是我们的任务模板——将```包围的text翻译为style风格文本,为了重复使用这个模板,我们导入langchain的chat prompt模板
template_string = """Translate the text that is delimited by triple backticks \
into a style that is {style}. text: ```{text}```"""
from langchain.prompts import ChatPromptTemplate
prompt_template = ChatPromptTemplate.from_template(template_string)
使用刚刚创建的prompt_template来构建prompt
prompt_template.messages[0].prompt # 原始提示,有两个变量:text和style
PromptTemplate(input_variables=['style', 'text'], output_parser=None, partial_variables={}, template='Translate the text that is delimited by triple backticks into a style that is {style}. text: ```{text}```\n', template_format='f-string', validate_template=True)
prompt_template.messages[0].prompt.input_variables
['style', 'text']
# 客户指定样式
customer_style = """American English in a calm and respectful tone"""
customer_email = """
Arrr, I be fuming that me blender lid flew off and splattered me kitchen walls \
with smoothie! And to make matters worse, the warranty don't cover the cost of \
cleaning up me kitchen. I need yer help right now, matey!
"""
customer_messages = prompt_template.format_messages(
style=customer_style,
text=customer_email)
print(type(customer_messages)) # 列表类型,第一个元素就是我们希望创建的提示
print(type(customer_messages[0]))
print(customer_messages[0])
content="Translate the text that is delimited by triple backticks into a style that is American English in a calm and respectful tone\n. text: ```\nArrr, I be fuming that me blender lid flew off and splattered me kitchen walls with smoothie! And to make matters worse, the warranty don't cover the cost of cleaning up me kitchen. I need yer help right now, matey!\n```\n" additional_kwargs={} example=False
这个提示模板也可重复用于其它的文本翻译任务,例如客服的回复。
# Call the LLM to translate to the style of the customer message
customer_response = chat(customer_messages)
print(customer_response.content)
I'm really frustrated that my blender lid flew off and made a mess of my kitchen walls with smoothie! And to make things even worse, the warranty doesn't cover the cost of cleaning up my kitchen. I could really use your help right now, my friend!
service_reply = """Hey there customer, the warranty does not cover \
cleaning expenses for your kitchen because it's your fault that \
you misused your blender by forgetting to put the lid on before \
starting the blender. Tough luck! See ya!
"""
service_style_pirate = """a polite tone that speaks in English Pirate"""
service_messages = prompt_template.format_messages(
style=service_style_pirate,
text=service_reply)
print(service_messages[0].content)
Translate the text that is delimited by triple backticks into a style that is a polite tone that speaks in English Pirate. text: ```Hey there customer, the warranty does not cover cleaning expenses for your kitchen because it's your fault that you misused your blender by forgetting to put the lid on before starting the blender. Tough luck! See ya!
service_response = chat(service_messages)
print(service_response.content)
Ahoy there, matey! I regret to inform ye that the warranty be not coverin' the costs o' cleanin' yer galley, as 'tis yer own fault fer misusin' yer blender by forgettin' to secure the lid afore startin' it. Aye, tough luck, me heartie! Fare thee well!
为什么使用提示模板而不是f字符串来构建提示? 因为随着任务越来越复杂,提示会变得越来越长,越来越详细。这时候提示模板就是非常有用的,可以让你快速的构建提示。

下面是一个长提示的例子,用于在线学习程序中对学生提交的结果进行评估。我们要求模型先解决问题,再按照要求的格式返回结果,使用语言链提示可以做到这一点。

左侧示例演示了语言模型使用思维链进行推理,框架是React。
Thought:思维链,即语言模型的思考过程,是prompt_template的关键。给予模型充分的思考空间,往往可以得到更准确的结果。Action:表示特定的操作Observation:显示从action操作中学习到的内容
重复以上过程,配合解析器,解析带有这些关键词的prompt输入LLM后得到的响应的。
语言链用于一些常见操作的提示,例如摘要、问答、连接SQL数据库或者不同的API。通过语言链内置的提示模板,你可以快速构建APP提示让其work,而不再需要自己绞尽脑汁的编写。另外语言链提示还支持输出暂停,后续会进行介绍。
使用语言链提示时,通常会让模型按特定格式进行输出,例如使用特定的关键词。
1.5 使用LangChain解析LLM的JSON输出
1.5.1 LangChain输出为string格式
下面是一个JSON格式化的产品评论示例,也是我们期望模型输出的示例。
{
"gift": False, # 是否为gift
"delivery_days": 5, # 交货天数
"price_value": "pretty affordable!" # 价格合理
}
{'gift': False, 'delivery_days': 5, 'price_value': 'pretty affordable!'}
下面是一个顾客评论的示例,以及prompt模板。模板要求LLM提取上诉三个字段之后,以JSON格式输出。
customer_review = """This leaf blower is pretty amazing. It has four settings:candle blower, gentle breeze, \
windy city, and tornado. It arrived in two days, just in time for my wife's anniversary present. I think \
my wife liked it so much she was speechless. So far I've been the only one using it, and I've been using \
it every other morning to clear the leaves on our lawn. It's slightly more expensive than the \
other leaf blowers out there, but I think it's worth it for the extra features.
"""
review_template = """For the following text, extract the following information:
gift: Was the item purchased as a gift for someone else? Answer True if yes, False if not or unknown.
delivery_days: How many days did it take for the product to arrive? If this information is not found, output -1.
price_value: Extract any sentences about the value or price,and output them as a comma separated Python list.
Format the output as JSON with the following keys:
gift
delivery_days
price_value
text: {text}
"""
from langchain.prompts import ChatPromptTemplate
prompt_template = ChatPromptTemplate.from_template(review_template)
print(prompt_template)
input_variables=['text'] output_parser=None partial_variables={} messages=[HumanMessagePromptTemplate(prompt=PromptTemplate(input_variables=['text'], output_parser=None, partial_variables={}, template='For the following text, extract the following information:\n\ngift: Was the item purchased as a gift for someone else? Answer True if yes, False if not or unknown.\n\ndelivery_days: How many days did it take for the product to arrive? If this information is not found, output -1.\n\nprice_value: Extract any sentences about the value or price,and output them as a comma separated Python list.\n\nFormat the output as JSON with the following keys:\ngift\ndelivery_days\nprice_value\n\ntext: {text}\n', template_format='f-string', validate_template=True), additional_kwargs={})]
# 根据提示模板创建提示
messages = prompt_template.format_messages(text=customer_review)
chat = ChatOpenAI(temperature=0.0) # 调用模型
response = chat(messages) # 获取响应
print(response.content)
input_variables=['text'] output_parser=None partial_variables={} messages=[HumanMessagePromptTemplate(prompt=PromptTemplate(input_variables=['text'], output_parser=None, partial_variables={}, template='For the following text, extract the following information:\n\ngift: Was the item purchased as a gift for someone else? Answer True if yes, False if not or unknown.\n\ndelivery_days: How many days did it take for the product to arrive? If this information is not found, output -1.\n\nprice_value: Extract any sentences about the value or price,and output them as a comma separated Python list.\n\nFormat the output as JSON with the following keys:\ngift\ndelivery_days\nprice_value\n\ntext: {text}\n', template_format='f-string', validate_template=True), additional_kwargs={})]
响应的类型看起来有键值对,像是字典,但其实是字符串。我们其实是希望输出结果是JSON格式,可以根据键来获取值,例如response.content.get('gift'),但现在这样的格式只会报错。
type(response.content)
str
# You will get an error by running this line of code
# because'gift' is not a dictionary,it is a string
response.content.get('gift')
AttributeError: 'str' object has no attribute 'get'
1.5.2 LangChain输出解析器,解析LLM输出为字典
下面使用解析器,来将LLM 的输出从string 格式转为Python字典格式。首先导入响应模式ResponseSchema和结构化输出解析器StructuredOutputParser。我们可以通过指定响应模式来暂停输出的位置。
定义ResponseSchema模式名为gift,其描述为:作为某人的礼物返回True,否则返回False或者unkown。类似的还有交货天数模式、价格模式。最后讲这些模式作为列表整合到response_schemas。
既然我们为这些模板指定了结构,LangChain就可以使用输出解析器进行对应的解析。其实就是使用解析器的模式名,作为字典的键;模式的描述,用于提取这个键对应的字段值。
from langchain.output_parsers import ResponseSchema
from langchain.output_parsers import StructuredOutputParser
gift_schema = ResponseSchema(name="gift",
description="Was the item purchasedas a gift for someone else? \
Answer True if yes,False if not or unknown.")
delivery_days_schema = ResponseSchema(name="delivery_days",
description="How many days,did it take for the product\
to arrive? If this information is not found,output -1.")
price_value_schema = ResponseSchema(name="price_value",
description="Extract any sentences about the value or \
price, and output them as a comma separated Python list.")
response_schemas = [gift_schema,
delivery_days_schema,
price_value_schema]
output_parser = StructuredOutputParser.from_response_schemas(response_schemas)
format_instructions = output_parser.get_format_instructions()
print(format_instructions)
The output should be a markdown code snippet formatted in the following schema, including the leading and trailing "\`\`\`json" and "\`\`\`":
```json
{
"gift": string // Was the item purchased as a gift for someone else? Answer True if yes, False if not or unknown.
"delivery_days": string // How many days did it take for the product to arrive? If this information is not found, output -1.
"price_value": string // Extract any sentences about the value or price, and output them as a comma separated Python list.
}
下面是一个新的评论模板,包括了输出格式要求的指令。我们可以根据提示模板来构建prompt,再结合输出解析器的模式来构建messages。
review_template_2 = """For the following text, extract the following information:
gift: Was the item purchased as a gift for someone else? Answer True if yes, False if not or unknown.
delivery_days: How many days did it take for the productto arrive? If this information is not found, output -1.
price_value: Extract any sentences about the value or price,and output them as a comma separated Python list.
text: {text}
{format_instructions}
"""
prompt = ChatPromptTemplate.from_template(template=review_template_2)
messages = prompt.format_messages(text=customer_review,
format_instructions=format_instructions)
# 整合后的提示,包括提示模板的内容,以及输出的模式(含三个键及其描述,输出要求的JSON格式,以及最后的格式化输出指令)
print(messages[0].content)
For the following text, extract the following information:
gift: Was the item purchased as a gift for someone else? Answer True if yes, False if not or unknown.
delivery_days: How many days did it take for the productto arrive? If this information is not found, output -1.
price_value: Extract any sentences about the value or price,and output them as a comma separated Python list.
text: This leaf blower is pretty amazing. It has four settings:candle blower, gentle breeze, windy city, and tornado. It arrived in two days, just in time for my wife's anniversary present. I think my wife liked it so much she was speechless. So far I've been the only one using it, and I've been using it every other morning to clear the leaves on our lawn. It's slightly more expensive than the other leaf blowers out there, but I think it's worth it for the extra features.
The output should be a markdown code snippet formatted in the following schema, including the leading and trailing "\`\`\`json" and "\`\`\`":
```json
{
"gift": string // Was the item purchased as a gift for someone else? Answer True if yes, False if not or unknown.
"delivery_days": string // How many days did it take for the product to arrive? If this information is not found, output -1.
"price_value": string // Extract any sentences about the value or price, and output them as a comma separated Python list.
}
```
response = chat(messages)
print(response.content)
```json
{
"gift": false,
"delivery_days": "2",
"price_value": "It's slightly more expensive than the other leaf blowers out there, but I think it's worth it for the extra features."
}
```
output_dict = output_parser.parse(response.content)
output_dict
{'gift': False,
'delivery_days': '2',
'price_value': "It's slightly more expensive than the other leaf blowers out there, but I think it's worth it for the extra features."}
现在输出是字典类型,可以根据键来获取对应的值。
type(output_dict)
dict
output_dict.get('delivery_days')
'2'
感觉这样还是比较麻烦啊,为什么不是有个参数直接决定最终输出是什么格式。
二、LangChain: Memory
Chains和Agents默认是无状态的,但在某些应用中,如聊天机器人,记住先前的互动很重要。为此,LangChain提供了memory组件,以管理和操作先前的聊天消息。这些组件可以灵活地嵌入Chains中,并通过独立函数或Chains方式使用。
memory类型可以返回字符串或消息列表,用于提取信息,比如最近的N条消息或所有先前消息的摘要。最简单的内存类型是buffer memory,用来保留先前的所有消息。下面展示如何使用模块化的实用函数及在Chains中应用这些memory,实现记忆功能。

2.1 ChatMessageHistory
在大多数内存模块中,其中一个核心实用类是ChatMessageHistory类。这是一个非常轻量级的包装器,提供了保存人类消息、AI消息以及获取它们的便捷方法。
from langchain.memory import ChatMessageHistory
history = ChatMessageHistory()
history.add_user_message("hi!")
history.add_ai_message("whats up?")
history.messages
[HumanMessage(content='hi!', additional_kwargs={}),
AIMessage(content='whats up?', additional_kwargs={})]
2.2 ConversationBufferMemory(对话缓冲区memory)
2.2.1 直接添加memory
现在我们来展示如何在Chains中使用这个简单的概念。我们首先展示ConversationBufferMemory,它只是ChatMessageHistory的一个包装器,用于提取变量中的消息。我们可以首先将其提取为一个字符串。
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory()
memory.chat_memory.add_user_message("hi!")
memory.chat_memory.add_ai_message("whats up?")
memory.load_memory_variables({})
{'history': 'Human: hi!\nAI: whats up?'}
设置return_messages=True,我们也可以将历史记录提取为消息列表:
memory = ConversationBufferMemory(return_messages=True)
memory.chat_memory.add_user_message("hi!")
memory.chat_memory.add_ai_message("whats up?")
memory.load_memory_variables({})
{'history': [HumanMessage(content='hi!', additional_kwargs={}),
AIMessage(content='whats up?', additional_kwargs={})]}
2.2.2 Using in a chain
下面让我们看一下如何在Chains中使用它(设置verbose=True以便查看提示信息)
import os
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
import warnings
warnings.filterwarnings('ignore')
from langchain.chat_models import ChatOpenAI
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
llm = ChatOpenAI(temperature=0.0)
memory = ConversationBufferMemory()
conversation = ConversationChain(
llm=llm,
memory = memory,
verbose=True)
下面开始一段对话。verbose=True时,可以查看LangChain 正在做什么。下面打印的输出,可以看到模型在做生成时的prompt,是让系统进行一次充满希望和友好的对话,且保存对话。
conversation.predict(input="Hi, my name is Andrew")
> Entering new ConversationChain chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
Human: Hi, my name is Andrew
AI:
> Finished chain.
"Hello Andrew! It's nice to meet you. How can I assist you today?"
conversation.predict(input="What is 1+1?")
> Entering new ConversationChain chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
Human: Hi, my name is Andrew
AI: Hello Andrew! It's nice to meet you. How can I assist you today?
Human: What is 1+1?
AI:
> Finished chain.
'1+1 is equal to 2.'
因为我们使用了buffermemory来保存所有对话,所以当问到我的名字时,LLM可以读取历史信息给出答案。
conversation.predict(input="What is my name?")
> Entering new ConversationChain chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
Human: Hi, my name is Andrew
AI: Hello Andrew! It's nice to meet you. How can I assist you today?
Human: What is 1+1?
AI: 1+1 is equal to 2.
Human: What is my name?
AI:
> Finished chain.
'Your name is Andrew.
打印memory.buffer,会输出目前保存的对话内容。
print(memory.buffer)
Human: Hi, my name is Andrew
AI: Hello Andrew! It's nice to meet you. How can I assist you today?
Human: What is 1+1?
AI: 1+1 is equal to 2.
Human: What is my name?
AI: Your name is Andrew.
# {}是一个空字典,也有一些高级功能使用更复杂的输入
memory.load_memory_variables({})
{'history': "Human: Hi, my name is Andrew\nAI: Hello Andrew! It's nice to meet you. How can I assist you today?\nHuman: What is 1+1?\nAI: 1+1 is equal to 2.\nHuman: What is my name?\nAI: Your name is Andrew."}
目前,LangChain存储对话的方式是使用一个对话缓冲区ConversationBufferMemory。如果要指定向memory中添加一些新的输入或者输出,可以使用memory.save_context。
memory = ConversationBufferMemory()
memory.save_context({"input": "Hi"},
{"output": "What's up"})
下面再次打印一下memory变量。
print(memory.buffer)
Human: Hi
AI: What's up
memory.load_memory_variables({})
{'history': "Human: Hi\nAI: What's up"}
重复使用memory.save_context以继续添加新的内容。
memory.save_context({"input": "Not much, just hanging"},
{"output": "Cool"})
memory.load_memory_variables({})
{'history': "Human: Hi\nAI: What's up\nHuman: Not much, just hanging\nAI: Cool"}
我们还可以将历史记录作为消息列表提取出来(如果您将其与聊天模型一起使用,这将非常有用)。
memory = ConversationBufferMemory(return_messages=True)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.load_memory_variables({})
{'history': [HumanMessage(content='hi', additional_kwargs={}, example=False),
AIMessage(content='whats up', additional_kwargs={}, example=False)]}
2.2.3 Saving Message History
您可能经常需要保存消息,并在需要时加载它们以供再次使用。这可以通过先将消息转换为普通的Python字典,将其保存(例如作为JSON格式),然后再加载它们来轻松实现。以下是一个示例:
import json
from langchain.memory import ChatMessageHistory
from langchain.schema import messages_from_dict, messages_to_dict
history = ChatMessageHistory()
history.add_user_message("hi!")
history.add_ai_message("whats up?")
dicts = messages_to_dict(history.messages)
dicts
[{'type': 'human', 'data': {'content': 'hi!', 'additional_kwargs': {}}},
{'type': 'ai', 'data': {'content': 'whats up?', 'additional_kwargs': {}}}]
new_messages = messages_from_dict(dicts)
new_messages
[HumanMessage(content='hi!', additional_kwargs={}),
AIMessage(content='whats up?', additional_kwargs={})]
随着对话越来越长,所需的buffer memory也越来越长,这就非常耗成本(LLM模型通常按tokens数计费)。因此,LangChain 提供了几种更便捷的memory类型来存储对话内容。
2.3 ConversationBufferWindowMemory(追踪最近的k次对话)
ConversationBufferWindowMemory用于追踪最近的K个交互,以保持一个滑动窗口的最新交互,避免缓冲区memory随着对话无限增长。下面显示其基本功能:
from langchain.memory import ConversationBufferWindowMemory
memory = ConversationBufferWindowMemory(k=1)
memory.save_context({"input": "Hi"},
{"output": "What's up"})
memory.save_context({"input": "Not much, just hanging"},
{"output": "Cool"})
memory.load_memory_variables变量只会记得最近的对话内容,因为上面我们设置了k=1
memory.load_memory_variables({})
{'history': 'Human: Not much, just hanging\nAI: Cool'}
让我们通过一个示例来演示Using in a chain,再次设置verbose=True以便查看提示信息。
llm = ChatOpenAI(temperature=0.0)
memory = ConversationBufferWindowMemory(k=1)
conversation = ConversationChain(
llm=llm,
memory = memory,
verbose=False
)
conversation.predict(input="Hi, my name is Andrew")
"Hello Andrew! It's nice to meet you. How can I assist you today?"
conversation.predict(input="What is 1+1?")
'1+1 is equal to 2.'
因为只保留一轮对话,模型已经不记得我叫什么了
conversation.predict(input="What is my name?")
"I'm sorry, but I don't have access to personal information."
2.4 ConversationTokenBufferMemory(追踪最近的max_token_limit个tokens对话)
ConversationTokenBufferMemory在memory中保留最近交互的缓冲区,并使用令牌长度而不是交互数量来确定何时刷新交互,这样可以更直接的反映调用LLM的成本(tokens计费)。
#!pip install tiktoken
from langchain.memory import ConversationTokenBufferMemory
from langchain.llms import OpenAI
llm = ChatOpenAI(temperature=0.0)
memory = ConversationTokenBufferMemory(llm=llm, max_token_limit=30)
memory.save_context({"input": "AI is what?!"},
{"output": "Amazing!"})
memory.save_context({"input": "Backpropagation is what?"},
{"output": "Beautiful!"})
memory.save_context({"input": "Chatbots are what?"},
{"output": "Charming!"})
memory.load_memory_variables({})
{'history': 'AI: Beautiful!\nHuman: Chatbots are what?\nAI: Charming!'}
我们也可以通过设置return_messages=True将历史记录作为消息列表提取出来(如果您将其与聊天模型一起使用,这将非常有用)。
让我们通过一个示例来演示Using in a chain
from langchain.chains import ConversationChain
conversation_with_summary = ConversationChain(
llm=llm,
# We set a very low max_token_limit for the purposes of testing.
memory=ConversationTokenBufferMemory(llm=OpenAI(), max_token_limit=60),
verbose=False,
)
conversation_with_summary.predict(input="Hi, what's up?")
"Hello! I'm an AI designed to assist with various tasks and provide information. Right now, I'm here to chat with you. How can I help you today?"
conversation_with_summary.predict(input="Just working on writing some documentation!")
"That's great! Writing documentation can be a valuable task to ensure clear communication and understanding. Is there anything specific you need help with or any questions you have?"
conversation_with_summary.predict(input="For LangChain! Have you heard of it?")
'Yes, I am familiar with LangChain. It is a blockchain-based platform that aims to provide language services such as translation, interpretation, and language learning. It utilizes smart contracts and decentralized technology to connect language service providers with clients in a secure and transparent manner. The platform also incorporates machine learning algorithms to improve the quality and efficiency of language services. Is there anything specific you would like to know about LangChain?'
2.4 ConversationSummaryMemory(旧的交互保存为摘要)
ConversationSummaryBufferMemory是将前面两种方法结合起来的一种内存类型,不再单纯的将memory限制为最近的k次交互或者最近的max_token_limit个tokens,而是使用LLM来编写目前为止的对话摘要,并将其作为记忆。摘要的长度使用max_token_limit控制。
下面用包含某个人的日程安排的长文本来进行实验。
from langchain.memory import ConversationSummaryBufferMemory
# create a long string
schedule = "There is a meeting at 8am with your product team. You will need your powerpoint presentation \
prepared. 9am-12pm have time to work on your LangChain project which will go quickly because Langchain is \
such a powerful tool. At Noon, lunch at the italian resturant with a customer who is driving from over \
an hour away to meet you to understand the latest in AI. Be sure to bring your laptop to show the latest LLM demo."
memory = ConversationSummaryBufferMemory(llm=llm, max_token_limit=100)
memory.save_context({"input": "Hello"}, {"output": "What's up"})
memory.save_context({"input": "Not much, just hanging"},
{"output": "Cool"})
memory.save_context({"input": "What is on the schedule today?"},
{"output": f"{schedule}"})
memory.load_memory_variables({})
{'history': 'System: The human and AI exchange greetings. The human asks about the schedule for the day. The AI provides a detailed schedule, including a meeting with the product team, work on the LangChain project, and a lunch meeting with a customer interested in AI. The AI also mentions the need to bring a laptop to showcase the latest LLM demo during the lunch meeting.'}
下面创建一个对话链。
conversation = ConversationChain(
llm=llm,
memory = memory,
verbose=True
)
conversation.predict(input="What would be a good demo to show?")
> Entering new ConversationChain chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
System: The human and AI exchange greetings. The human asks about the schedule for the day. The AI provides a detailed schedule, including a meeting with the product team, work on the LangChain project, and a lunch meeting with a customer interested in AI. The AI also mentions the need to bring a laptop to showcase the latest LLM demo during the lunch meeting.
Human: What would be a good demo to show?
AI:
> Finished chain.
"A good demo to show during the lunch meeting with the customer interested in AI would be the latest LLM (Language Model) demo. The LLM is a cutting-edge AI model that can generate human-like text based on a given prompt. It has been trained on a vast amount of data and can generate coherent and contextually relevant responses. By showcasing the LLM demo, you can demonstrate the capabilities of AI in natural language processing and generate interest in potential applications for the customer's business."
可以看到打印结果中有一个system消息。本例中,并非使用OpenAI的系统消息,只是作为提示的一部分。
memory.load_memory_variables({})
{'history': "System: The human and AI exchange greetings and discuss the schedule for the day. The AI provides a detailed schedule, including a meeting with the product team, work on the LangChain project, and a lunch meeting with a customer interested in AI. The AI also mentions the need to bring a laptop to showcase the latest LLM demo during the lunch meeting. The human asks what would be a good demo to show, and the AI suggests showcasing the latest LLM (Language Model) demo. The LLM is a cutting-edge AI model that can generate human-like text based on a given prompt. By showcasing the LLM demo, the AI can demonstrate the capabilities of AI in natural language processing and generate interest in potential applications for the customer's business."}
可以看到已经整合了目前为止的对话总结,并作为系统消息加入到对话中。
2.5 其它类型memory

LangChain还有一些其它类型的memory,包括:
- vector data memory。LangChain可以使用这种类型的向量数据库来检索最相关的文本块作为memory存储。
- entity memory:实体类型memory,适用于记忆特定的人物、实体的详细情况。比如你可以让LangChain记住你提到的某个朋友,这是一种显式的实体。
你也可以使用多种类型的memory,比如SummaryMemory+entity memory,可以记住对话的摘要,以及显式地存储对话中重要人物的重要事实。
除了使用memory之外,开发人员通常也会将对话内容存储在传统的数据库中,比如key-value或者SQL数据库,这样就可以回顾整个对话,进行审计或者进一步改进。
三、 Chains
Chain是LangChain的关键模块,通常是将LLM与提示一起结合使用。Chain的优势是,可以对多个输入同时进行处理,得到输出。在简单的应用中,单独使用LLM是可以的,但在更复杂的应用中,需要与其他LLM或其他组件进行链式调用。
LangChain提供了Chain接口,用于这种“链式”应用。我们将Chain定义为一个包含组件调用序列的概念,可以包含其他链。基本接口非常简单:
class Chain(BaseModel, ABC):
"""Base interface that all chains should implement."""
memory: BaseMemory
callbacks: Callbacks
def __call__(
self,
inputs: Any,
return_only_outputs: bool = False,
callbacks: Callbacks = None,
) -> Dict[str, Any]:
下面我们用一个示例来进行说明。首先用pandas加载数据,准备后续处理。
import os
import warnings
warnings.filterwarnings('ignore')
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
#!pip install pandas
import pandas as pd
df = pd.read_csv('Data.csv')
df.head()

加载后的数据有产品和评论这两列,每行是一条数据,可以用Chain进行传递。
3.1 LLMChain
LLMChain是最基本的链类型,会经常使用。它接收一个提示模板,用于将用户输入进行格式化,然后从LLM返回响应。下面先导入模型、提示模板和LLMChain,然后初始化LLM和提示模板。
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.chains import LLMChain
llm = ChatOpenAI(temperature=0.9)
# prompt接受变量product,为公司取名
prompt = ChatPromptTemplate.from_template(
"What is the best name to describe a company that makes {product}?")
下面将llm和prompt组合成chain,我们就可以按顺序将提示输入模型,得到结果。
chain = LLMChain(llm=llm, prompt=prompt)
product = "Queen Size Sheet Set"
chain.run(product)
'"Royal Comfort Linens" or "LuxuryDream Bedding"'
3.2 SequentialChain
SequentialChain会按照顺序运行一系列链。SimpleSequentialChain(简单顺序链)可用于处理单个输入且单个输出的情况。

3.2.1 SimpleSequentialChain
下面例子中,我们会根据公司的产品来为公司取名,然后根据公司名来生成一段20字的描述文本。
from langchain.llms import ChatOpenAI
from langchain.chains import SimpleSequentialChain
from langchain.chains import LLMChain
from langchain.prompts import ChatPromptTemplate
llm = ChatOpenAI(temperature=0.9)
构建prompt template 1和Chain 1、prompt template 2和Chain 2
first_prompt = ChatPromptTemplate.from_template(
"What is the best name to describe a company that makes {product}?")
chain_one = LLMChain(llm=llm, prompt=first_prompt)
second_prompt = ChatPromptTemplate.from_template(
"Write a 20 words description for the following company:{company_name}")
chain_two = LLMChain(llm=llm, prompt=second_prompt)
构建 SimpleSequentialChain
overall_simple_chain = SimpleSequentialChain(chains=[chain_one, chain_two],
verbose=True)
overall_simple_chain.run(product)
> Entering new SimpleSequentialChain chain...
"Royalty Linens" or "Regal Beddings" would be good names to describe a company that makes Queen Size Sheet Sets.
"Royalty Linens" or "Regal Beddings" are fitting names for a company specializing in luxurious Queen Size Sheet Sets.
> Finished chain.
'"Royalty Linens" or "Regal Beddings" are fitting names for a company specializing in luxurious Queen Size Sheet Sets.'
在这个例子中,chain_one的输出传递到chain_two。如果有多个输入和多个输出该怎么办呢?我们可以使用常规顺序链SequentialChain来实现。
3.2.2 SequentialChain
下面例子中
- chain1将评论
Review翻译为英语English_Review - chain2为
English_Review创建一句话的摘要summary - chain3检测评论原文
Review的语言language - chain4根据
summary和language两个变量,以指定语言对摘要进行回复。
在SimpleSequentialChain中,是单个输入输出进行顺序链式传递,不需要额外说明。而这里涉及到多个输入输出变量,所以需要指定output_key。

from langchain.chains import SequentialChain
llm = ChatOpenAI(temperature=0.9)
# prompt template 1: 将评论翻译为英文
first_prompt = ChatPromptTemplate.from_template(
"Translate the following review to english:"
"\n\n{Review}")
# chain 1: input= Review and output= English_Review
chain_one = LLMChain(llm=llm, prompt=first_prompt,
output_key="English_Review")
# prompt template 2:创建一句话摘要
second_prompt = ChatPromptTemplate.from_template(
"Can you summarize the following review in 1 sentence:"
"\n\n{English_Review}")
# chain 2: input= English_Review and output= summary
chain_two = LLMChain(llm=llm, prompt=second_prompt,
output_key="summary")
# prompt template 3: translate to english
third_prompt = ChatPromptTemplate.from_template(
"What language is the following review:\n\n{Review}"
)
# chain 3: input= Review and output= language
chain_three = LLMChain(llm=llm, prompt=third_prompt,
output_key="language")
# prompt template 4: follow up message
fourth_prompt = ChatPromptTemplate.from_template(
"Write a follow up response to the following "
"summary in the specified language:"
"\n\nSummary: {summary}\n\nLanguage: {language}"
)
# chain 4: input= summary, language and output= followup_message
chain_four = LLMChain(llm=llm, prompt=fourth_prompt,
output_key="followup_message")
下面创建包含上述四个链的chains,输入是Review,然后要求它返回所有中间输出。
# overall_chain: input= Review
# and output= English_Review,summary, followup_message
overall_chain = SequentialChain(
chains=[chain_one, chain_two, chain_three, chain_four],
input_variables=["Review"],
output_variables=["English_Review", "summary","followup_message"],
verbose=True)
review = df.Review[5]
overall_chain(review)
> Entering new SequentialChain chain...
> Finished chain.
{'Review': "Je trouve le goût médiocre. La mousse ne tient pas, c'est bizarre. J'achète les mêmes dans le commerce et le goût est bien meilleur...\nVieux lot ou contrefaçon !?",
'English_Review': "I find the taste mediocre. The foam doesn't hold, it's strange. I buy the same ones in stores and the taste is much better...\nOld batch or counterfeit!?",
'summary': 'The reviewer is disappointed with the taste and foam quality of the product bought online, suspecting it may be a counterfeit or an old batch in comparison to the better-tasting ones purchased in stores.',
'followup_message': "Réponse de suivi:\n\nCher(e) client(e),\n\nNous sommes désolés d'apprendre que vous n'êtes pas satisfait(e) de la qualité gustative et de la mousse de notre produit acheté en ligne. Nous comprenons votre déception et nous souhaitons rectifier la situation.\n\nNous tenons à vous assurer que nous ne vendons que des produits authentiques et frais. Cependant, il est possible qu'il y ait eu une variation dans la qualité due à des facteurs tels que la température de stockage pendant l'expédition ou l'utilisation d'une machine à café différente.\n\nNous aimerions prendre des mesures pour résoudre ce problème. Pourriez-vous s'il vous plaît nous fournir plus de détails sur votre achat en ligne, y compris la date d'achat et le numéro de commande ? Cela nous aidera à enquêter sur le problème et à prendre les mesures nécessaires pour garantir votre satisfaction.\n\nNous vous remercions de votre patience et de votre coopération. Nous sommes déterminés à fournir à nos clients des produits de la plus haute qualité et nous ferons tout notre possible pour résoudre cette situation.\n\nVeuillez nous contacter dès que possible afin que nous puissions résoudre ce problème ensemble.\n\nCordialement,\n\nL'équipe du service client"}
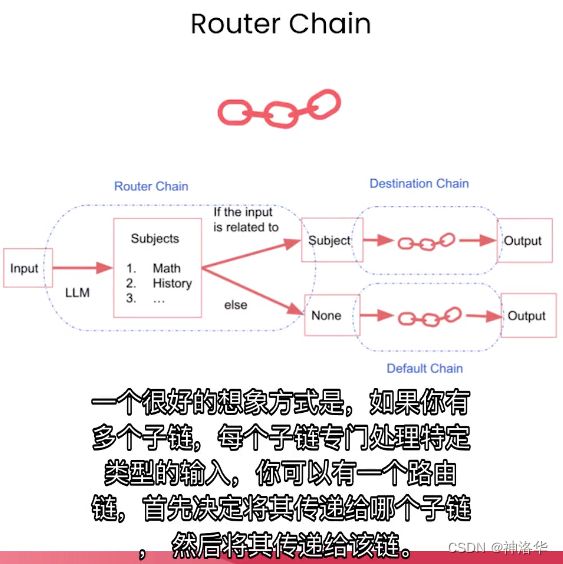
3.3 Router Chain
Router Chain可以用于更复杂的情况,可以将同一输入router到不同的输出。下面有几个不同的提示,分别用于处理物理、数学、历史和计算机科学。
physics_template = """You are a very smart physics professor. You are great at answering questions about physics
in a concise and easy to understand manner. When you don't know the answer to a question you admit that you don't know.
Here is a question:
{input}"""
math_template = """You are a very good mathematician. You are great at answering math questions. \
You are so good because you are able to break down hard problems into their component parts,\
answer the component parts, and then put them together to answer the broader question.
Here is a question:
{input}"""
history_template = """You are a very good historian. You have an excellent knowledge of and understanding of people,\
events and contexts from a range of historical periods. You have the ability to think, reflect, debate, discuss and \
evaluate the past. You have a respect for historical evidence and the ability to make use of it to support your \
explanations and judgements.
Here is a question:
{input}"""
computerscience_template = """ You are a successful computer scientist.You have a passion for creativity, collaboration,\
forward-thinking, confidence, strong problem-solving capabilities,understanding of theories and algorithms, and \
excellent communication skills. You are great at answering coding questions. You are so good because you \
know how to solve a problem by describing the solution in imperative steps that a machine can easily interpret and \
you know how to choose a solution that has a good balance between time complexity and space complexity.
Here is a question:
{input}"""
有了这四个提示模板之后,我们为每个模板创建一个名称和描述,后续都将传递给Router Chain。
prompt_infos = [
{
"name": "physics",
"description": "Good for answering questions about physics",
"prompt_template": physics_template
},
{
"name": "math",
"description": "Good for answering math questions",
"prompt_template": math_template
},
{
"name": "History",
"description": "Good for answering history questions",
"prompt_template": history_template
},
{
"name": "computer science",
"description": "Good for answering computer science questions",
"prompt_template": computerscience_template
}
]
MultiPromptChain用于在多个不同的提示模板直接进行route。你可以在任何类型的链之间进行,这里使用的是LLMRouterChain,用于在不同的LLM本身来路由不同的子链。RouterOutputParser是Router输出解析器,可将输出解析为字典格式,帮助Router Chain来决定在哪些子链之间进行路由。
from langchain.chains.router import MultiPromptChain
from langchain.chains.router.llm_router import LLMRouterChain,RouterOutputParser
from langchain.prompts import PromptTemplate
llm = ChatOpenAI(temperature=0)
destination_chains = {}
for p_info in prompt_infos:
name = p_info["name"]
prompt_template = p_info["prompt_template"]
prompt = ChatPromptTemplate.from_template(template=prompt_template)
chain = LLMChain(llm=llm, prompt=prompt) # 创建不同的子链
destination_chains[name] = chain
destinations = [f"{p['name']}: {p['description']}" for p in prompt_infos]
destinations_str = "\n".join(destinations)
创建默认链,当router无法决定使用哪个子链时,调用默认链。在上面的例子中,当输入与物理、数学、历史、计算机科学无关时,会调用此链。
default_prompt = ChatPromptTemplate.from_template("{input}")
default_chain = LLMChain(llm=llm, prompt=default_prompt)
创建LLM在不同链之间进行路由的模板,包含要完成的任务的说明,以及输出格式。
MULTI_PROMPT_ROUTER_TEMPLATE = """Given a raw text input to a language model select the model prompt best suited \
for the input. You will be given the names of the available prompts and a description of what the prompt is \
best suited for. You may also revise the original input if you think that revising it will ultimately lead \
to a better response from the language model.
<< FORMATTING >>
Return a markdown code snippet with a JSON object formatted to look like:
```json
{{{{
"destination": string \ name of the prompt to use or "DEFAULT"
"next_inputs": string \ a potentially modified version of the original input
}}}}```
REMEMBER: "destination" MUST be one of the candidate prompt names specified below OR it can be "DEFAULT" if the \
input is not well suited for any of the candidate prompts.REMEMBER: "next_inputs" can just be the original input \
if you don't think any modifications are needed.
<< CANDIDATE PROMPTS >>
{destinations}
<< INPUT >>
{{input}}
<< OUTPUT (remember to include the ```json)>>"""
将上述所有组件组合在一起构建Router Chain:
- 使用上面的格式来格式化创建
router_template,这个模板可以适应不同的destinations。比如,你可以添加英语、化学等不同学科 - 使用
router_template创建router_prompt。 - 将
router_prompt传入LLM和LLMRouterChain,来创建Router Chain。
router_template = MULTI_PROMPT_ROUTER_TEMPLATE.format(
destinations=destinations_str)
router_prompt = PromptTemplate(
template=router_template,
input_variables=["input"],
output_parser=RouterOutputParser(),)
router_chain = LLMRouterChain.from_llm(llm, router_prompt)
使用MultiPromptChain创建总体链路。
chain = MultiPromptChain(router_chain=router_chain,
destination_chains=destination_chains,
default_chain=default_chain, verbose=True)
下面如果我们问一个物理问题,这个问题将被首先路由到物理子链,再传递到后续链路中,回答非常详细。
chain.run("What is black body radiation?")
chain.run("what is 2 + 2")
chain.run("Why does every cell in our body contain DNA?")
我们已经掌握了基础链路,可以将它们组合起来构建非常有用的应用程序。下面将演示如何创建一个在文档上进行问答的链式结构。