序列建模简史(DIN/DIEN/DSIN/BST/MIMN/SIM/ETA/SDIM/TWIN)
序列建模简史(DIN/DIEN/DSIN/BST/MIMN/SIM/ETA/SDIM/TWIN)
史前史
在用户序列专门用于建模之前,一般对序列的建模的处理就是将所有序列行为进行sum/avg pooling操作,将用户的多个序列行为简单聚合成一个Embedding,然后和其他特征一起拼接。这就是最开始粗放地利用序列,序列行为的威力完全没有释放出来。也不难怪,史前史时期,各种眼花缭乱的模型结构、学习方式喷涌而出,序列建模才刚开始冒头。

后来工业界和学术界都证明序列建模能够有效提升用户建模的精度,头部大厂开始有人在序列建模领域专注研究,其中尤其以阿里的序列建模出名,一系列序列建模相关论文一发表就受到广泛关注,为序列建模领域开辟出一片光明的前途。
历史脉络
在梳理历史脉络之前,我们看看史前史时期对序列利用有哪些不足。
用户序列里面包含了丰富的用户行为模式、兴趣模式、用户兴趣变化迁移的信号,可以说利用好用户序列,能大幅提升模型的精度,大幅提升用户体验。如果只是简单的对用户序列进行聚合操作,丢失了很多信息。
比如说用户每个序列重要性必然是不同的,和目标物料相关性的权重都不一样。
再比如说用户序列用户兴趣的变化怎么刻画,模型怎么学习用户兴趣的迁移。
再比如说现在用户序列越来越长了,越长越全面的序列保存的用户信息越完整,如何建模超长序列。
再比如说用户序列里面包含的用户形态各异的兴趣,如何建模出用户的多峰兴趣。
还有用户序列是用户在多个session内产生的,session内与其他session又有所不同,如何建模刻画这种差异。
还有session的其他相关信息(sideinfomation)怎么利用起来,进一步丰富和补充序列,提升建模精度。
DIN
背景
阿里巴巴在电商的在线展示广告场景。基于Embedding & MLP 的网络结构通过固定长度的向量作为用户表征的方式限制了用户的多兴趣表达,而用户的兴趣是多样的,这样就产生了矛盾。
解决这种矛盾,可以增加用户向量表征维度。不过缺点也是明显的,会增加计算量,增加了模型复杂度,重点是可能会过拟合。也可以通过学习用户序列,在不同的广告上面有不同的用户向量表征,提升用户和目标广告的个性化相关性,DIN就是这个思路。
介绍
DIN的结构图如下
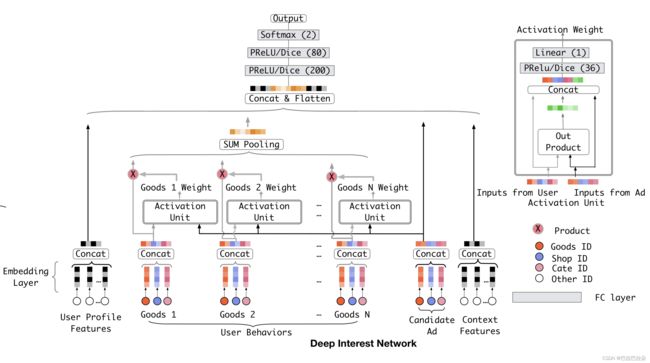
DIN通过引入attention来解决用户表征向量和目标广告的自适应匹配。使用attention机制来表达用户的动态兴趣,可以表示如下
v U ( A ) = f ( v A , e 1 , e 2 , . . . , e H ) = ∑ j = 1 H a t t e n t i o n ( e j , v A ) = ∑ j = 1 H w j e j \mathbf v_U(A) = f(\mathbf v_A,\mathbf e_1, \mathbf e_2, ..., \mathbf e_H ) = \sum_{j=1}^H attention(\mathbf e_j,\mathbf v_A) = \sum_{j=1}^H \mathbf w_j \mathbf e_j vU(A)=f(vA,e1,e2,...,eH)=j=1∑Hattention(ej,vA)=j=1∑Hwjej
{ e 1 , e 2 , . . . , e H } \{\mathbf e_1, \mathbf e_2, ..., \mathbf e_H\} {e1,e2,...,eH}是用户历史行为的一组Embedding,长度为 H H H
这个来源于一个朴素的想法,如果用户购买序列中有鞋子、袜子、水杯、键盘、风扇,后面那么用户如果购买了鼠标,鼠标和前面键盘相关性较大,和其他的购买行为相关性不大,模型通过attention能够捕捉到这种信息。面对目标广告时,不同的用户序列的权重是不一样的。
DIEN
背景
DIN通过attention能够动态刻画用户的兴趣,不过DIN没有考虑用户序列之间的相关性,用户序列之间的顺序也没有考虑。
也就是如果用户购买序列为“鞋子->袜子->水杯->键盘->风扇”和用户序列是“鞋子->水杯->袜子>风扇->键盘”通过attention得到的用户表征完全一样,实际上这两个序列是不同的。用户兴趣是在演变与进化迁移的,DIEN通过兴趣提取层和兴趣进化层精细刻画用户兴趣的演进过程,进一步提升用户表征的多样性和准确性。
介绍
DIEN的结构图如下
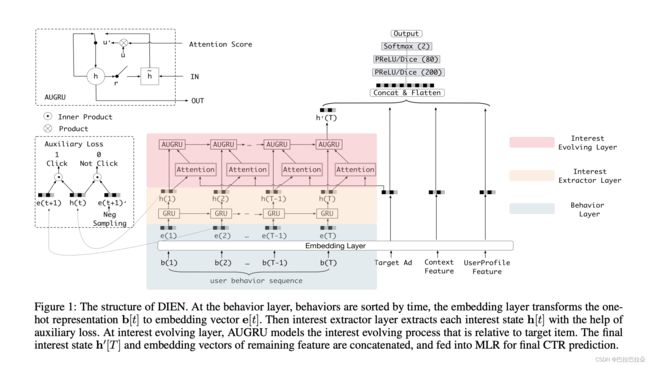
兴趣提取层
用户序列行为存在前后相关性,兴趣也随着行为发生变化,某个时刻的兴趣不仅与当前的行为相关,也和历史各个时刻的行为相关。用GRU建模用户序列的这种前后依赖的关系,用隐状态表示用户当前时刻的兴趣。同时引入辅助loss,通过下一个时刻的行为对当前行为进行监督,保证隐状态的有效性。
引入辅助loss可以有效缓解长序列梯度传播问题,引入用户非点击序列作为负样本,限制用户隐状态包含用户兴趣,模型用到的用户行为序列数据,长度可能非常大,容易导致GRU面临梯度消失问题;而且对各个时刻隐状态进行监督,可以提高提取到的兴趣表征效果,从而有利于下一个阶段兴趣演化层对兴趣的学习
兴趣进化层
通过基于attention的GRU方式,把attention分数当做更新门的作用,对GRU的隐状态进行更新。减弱不想管历史行为隐藏状态的更新,因此可以对隐状态的更新更细化。使兴趣演化过程聚焦在相关兴趣上,相关性越高,对隐状态的更新越大,从而对最终兴趣表征影响越大。
DSIN
背景
用户序列在一个时间片段里面有很大的相关性,不同时间段内的用户序列差异可能比较大。例如用户上午在淘宝搜索或者浏览衣服相关商品,下午使用淘宝可能搜索笔记本电脑相关商品。这里不同session之间差异较大,同一个session内部具有较大相关性。DSIN就是这个思路,对用户序列更细粒度的处理。
介绍
DSIN结构图如下

session划分层
对session进行分组,按间隔30分钟进行分组
session兴趣提取层
提取每个session的用户兴趣,使用multi-head attention方式提取,将position Embedding 替换为bias Embedding
session兴趣交互层
学习session内序列的依赖顺序关系,使用双向lstm对提取出的session用户兴趣向量进行建模,目的是建模各个session兴趣向量的演化迁移规律
session兴趣激活层
计算用户兴趣和目标物料的attention分数,强化相关的用户兴趣,减弱不相关的用户兴趣。不过论文用session兴趣向量和lstm输出的兴趣向量都和目标物料向量做attention打分
DSIN对用户序列的利用力度更加细化,按照session进行分组建模,思路还是非常不错的。不过结构过于复杂,最后的lstm效率较低,个人以为,即便按照阿里的强悍工程技术能力,也未必能在线上主流量上面使用,这个模型耗时太大了。
BST
背景
Transformer在NLP领域大放异彩后,很多领域都开始使用这个彪悍的结构,NLP处理的就是各种字词序列问题,用户序列也是一种序列问题,Transformer很自然的就拿过来应用到这个序列建模上面了。
介绍
BST结构图如下
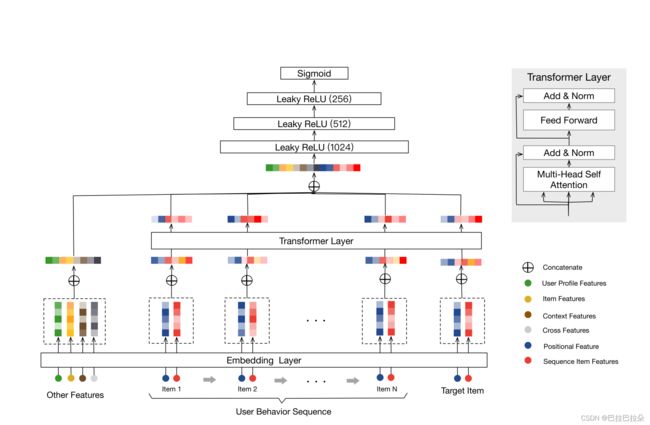
这里兴趣提取与演化过程简化为了Transformer结构,为了能学到用户序列和目标item的相关性,将目标item也一同输入给Transformer,然后用Transformer的输出和用户其他特征一起进入DNN。BST相当于用到了序列建模领域的利刃。
MIMN
背景
用户长期用户行为序列建模,当序列进一步拉长到千级别,会面临着几个挑战,其中最关键的两个包括:
存储约束 推荐系统有6亿用户,每个用户的行为序列的最大长度为150,存储约为1TB,不仅存储product_id,还存储其他相关功能id,如shop_id, brand_id等。当行为序列的长度达到1000需要6TB的存储空间。在淘宝场景的系统中使用高性能存储来保持低功耗延迟和高吞吐量,如此巨大的存储空间太昂贵了。因此,一个相当长的行为序列意味着不可接受的存储消耗。
耗时限制 深度网络非常具有挑战性,特别是在有大量请求的情况下。淘宝场景下QPS为500耗时为14ms,当用户行为的长度可达1000,DIEN的耗时达到200毫秒,30ms就已经不可接受了。
介绍
MIMN通过对机器学习算法和服务系统的协同设计来解决长序列建模的问题

(i) 服务系统视角:设计了一个单独的UIC(用户兴趣中心)模块。UIC关注用户行为的在线服务问题行为建模,为用户提供最新的兴趣表示每个用户。UIC的一个关键点是它的更新机制。更新只依赖于实时的用户行为触发事件,而不是流量请求。也就是说,UIC是无延迟的实时点击率预测。
(ii) 机器学习算法视角:仅解耦UIC模块无法解决存储问题,因为它仍然很难存储和进行推理
用户行为序列的长度扩展到1000到数百数以百万计的用户。借用记忆网络的概念
从NTM中提出了一种新的架构,称为MIMN(多通道用户兴趣记忆网络)。MIMN采用增量方式,可通过UIC模块实现很容易。这有助于解决存储挑战。此外,MIMN通过两种内存利用率设计改进了传统的NTM正则化和记忆归纳单元,使其更高效用于在有限存储空间下对用户行为序列进行建模。
SIM
背景
MIMN虽然可以理论上可以处理任意长度的序列,但实际上面是通过一个size固定大小的记忆矩阵实现的,当序列越长,记忆里面包含的噪声会越多,反而会影响兴趣建模的效果。也就是说当用户行为序列的长度进一步增加时,MIMN无法精确捕捉用户对特定候选项目的兴趣。SIM摒弃记忆网络的做法,开辟了一条新的道路。
介绍
SIM提出的基于搜索的兴趣模型(SIM)通过两个级联搜索单元提取用户兴趣:

(i) 泛搜单元GSU(General Search Unit) 负责从原始序列泛搜任意长的顺序行为数据,并获得相关的子用户行为序列(SBS),将候选序列从数万降为数百个。
(ii) 精搜单元ESU(Exact Search Unit) 对目标候选物料和SBS选出的数百个候选行为按照注意力机制进行建模。
这种级联搜索模式使SIM具有更好的能力,在可伸缩性和可扩展性方面更准确地建模终身序列行为,SIM对顺序用户行为数据进行建模最大长度可达54000。
ETA
背景
SIM提出了两阶段方法。第一阶段,辅助任务旨在从长序列用户行为检索最相关的用户行为序列。第二阶段,经典的注意力机制用来处理目标物料和第一阶段选出来的用户子序列的关系,进行CTR预估。
这种方式存在两个问题,首先是目标不一致,第一阶段目的是找到和目标物料相似的用户序列行为,第二阶段是尽可能的准确建模点击率;其次,第一阶段和第二阶段的更新频率不同,第一阶段是离线构建索引,然后导入到线上,第二阶段是参与在线训练。
ETA是一种端到端的目标注意力方法,可以大大降低训练和推理成本,并端到端训练长期用户行为序列。
介绍
ETA 实现端到端的长期用户行为建模,以减轻上述信息缺失(即目标发散和更新频率不一致)。通过使用SimHash来生成用户行为序列中每个行为的指纹。然后用汉明距离是用来帮助选择top-k物料,这样把检索复杂性从O(LBd)降低到O(L*B),其中L为行为序列的长度,B是候选物料的数量,d为embedding的尺寸。降低复杂性是有帮助我们删除了离线辅助模型,并实时进行训练和服务过程中进行检索。
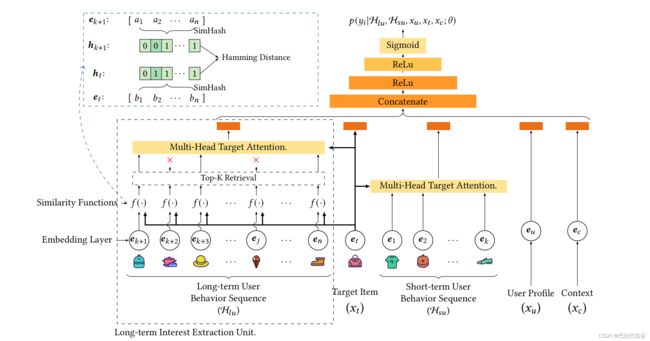
实际上ETA是将SIM两阶段的第一阶段泛搜阶段嵌入了SimHash,筛选和目标候选物料相关的用户行为序列,这样实现端到端的建模长期用户序列。
SDIM
背景
SIM、ETA都是基于检索的方法。基于这些方法存在以下缺点:从整个序列中检索top-k项是次优的。因为即便是ETA,第一阶段是基于检索选取相似候选行为序列,第二阶段是基于注意力机制目标的,两阶段目标总归是不完全一致,这会对用户的长期兴趣产生有偏的估计。在用户具有丰富的行为的情况下,检索到的top-k项可能都与候选项相似,并且估计的用户兴趣表示将是不准确的。此外,检索算法的有效性和效率也难以达到平衡。
介绍
SDIM提出了一种利用LSH获取用户兴趣的新方法。在哈希之后,我们通过将与具有相同签名的候选项q相关联的行为项s相加,直接形成用户的兴趣。在单个哈希函数r中,所提出的估计用户兴趣的方法可以通过以下方法来计算。
输入的行为embedding向量为 x ∈ R d \mathbf x \in R^d x∈Rd,hash函数向量为 r ∈ R d \mathbf r \in R^d r∈Rd,其中 r i ∼ N ( 0 , 1 ) r_i \sim N(0, 1) ri∼N(0,1),hash计算过程如下
h ( x , r ) = s i g n ( r T x ) = ± 1 h(\mathbf x, \mathbf r) = sign (\mathbf r^T \mathbf x) = \pm 1 h(x,r)=sign(rTx)=±1
如果输入向量 x 1 \mathbf x_1 x1和向量 x 2 \mathbf x_2 x2相似,那么他们的hash码相同
P ( r ) = 1 h ( x 1 , r ) = h ( x 2 , r ) P^{(r)} = 1_{h(\mathbf x_1, \mathbf r) = h(\mathbf x_2, \mathbf r)} P(r)=1h(x1,r)=h(x2,r)
上面hash是对每个维度使用一个hash函数,实际应用中每个维度使用多个hash函数,能有效降低碰撞概率,假设采用 m m m个hash函数,则有hash函数矩阵 R ∈ R m × d \mathbf R \in R^{m \times d} R∈Rm×d
h ( x , R ) = s i g n ( R x ) ∈ R m h(\mathbf x, \mathbf R) = sign(\mathbf R \mathbf x) \in R^{m} h(x,R)=sign(Rx)∈Rm
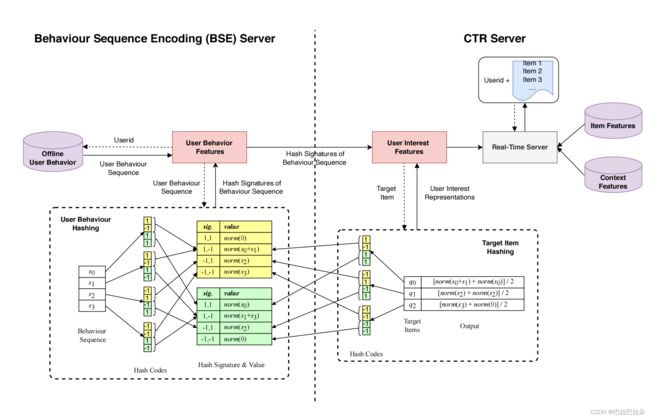
这样就得到了输入向量的hash签名(长度为 m m m),然后再将hash签名分隔成 τ \tau τ组,每组视作一个hash桶,用这个hash桶作为索引,保存落入到这个hash桶的输入embedding列表,并对每个embedding使用L2归一化。
下图是 m = 4 m=4 m=4且 τ = 2 \tau =2 τ=2,将每个序列行为embedding hash成4个bit,然后这4个bit分成2组(黄色和绿色2组),然后每组的签名值作为key建立索引,保存对应的经过L2归一化的embedding。

对于序列行为 s j \mathbf s_j sj,候选物料为 q \mathbf q q,那么根据用户序列可以得到用户行为向量
l 2 ( P ( r ) S ) = l 2 ( ∑ j = 1 L p j ( r ) s j ) l_2(\mathbf P^{(\mathbf r)} \mathbf S)=l_2(\sum_{j=1}^L\mathbf p_j^{(\mathbf r)} \mathbf s_j) l2(P(r)S)=l2(j=1∑Lpj(r)sj)
其中 S \mathbf S S为用户序列Embedding, p j r = { 0 , 1 } \mathbf p_j^{r}=\{0, 1\} pjr={0,1},当序列 s j \mathbf s_j sj和候选物料 q \mathbf q q在hash函数向量 r \mathbf r r下的签名一样时为1,否则为0。
q j ( r ) = 1 h ( s j , r ) = h ( q , r ) \mathbf q^{(r)}_j=1_{ h(\mathbf s_j, \mathbf r) = h(\mathbf q, \mathbf r)} qj(r)=1h(sj,r)=h(q,r)
用户兴趣表示为和候选物料签名一致的序列向量的attention值
A t t e n t i o n ( q , S ) = 1 m / τ ∑ i = 1 m / τ l 2 ( P ( r i ) S ) = 1 m / τ ∑ i = 1 m / τ l 2 ( ∑ j = 1 L p j ( r i ) s j ) Attention(\mathbf q, \mathbf S)=\frac{1}{ {m}/ {\tau} } \sum_{i=1}^{m/ \tau} l_2(\mathbf P^{(\mathbf r_i)} \mathbf S) = \frac{1}{ {m}/ {\tau} } \sum_{i=1}^{m/ \tau} l_2( \sum_{j=1}^L \mathbf p^{(\mathbf r_i)}_j \mathbf s_j) Attention(q,S)=m/τ1i=1∑m/τl2(P(ri)S)=m/τ1i=1∑m/τl2(j=1∑Lpj(ri)sj)
相当于直接在用户长期序列上面做attention操作,作者也进行了理论证明。总体架构如下:
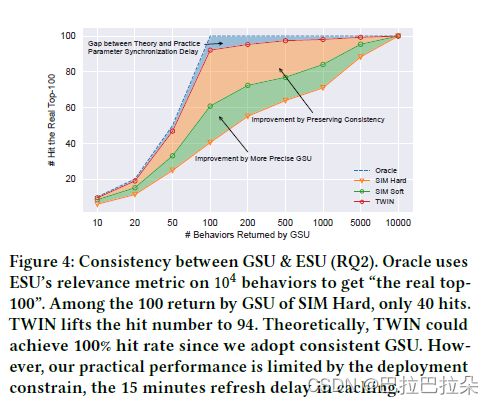
TWIN
背景
长期用户序列建模两阶段框架下的核心问题:两阶段目标(相似性度量标准)不一致,GSU很容易筛选出相关性不高的item,浪费了计算资源,偏离了用户的兴趣。SIM是明显的两阶段,ETA和SDIM是端到端的,两阶段的emb也是一样的,但是只是用GSU的LSH去近似ESU的Target Attention,因此仍然存在不一致性。
介绍
TWIN:就是为了解决这个不一致的问题,用于终身用户行为建模的两阶段兴趣网络,其中 Consistency-Preserved GSU (CP-GSU) 采用与 ESU 中的 TA 相同的目标行为相关性度量,使两个阶段成为双胞胎.为了将昂贵的 TA 扩展到 CP-GSU,TWIN 通过有效的行为特征拆分、简化的 TA 架构和高度优化的在线基础设施,打破了 TA 的关键计算瓶颈,即 1 0 4 10^4 104 个行为的线性投影。
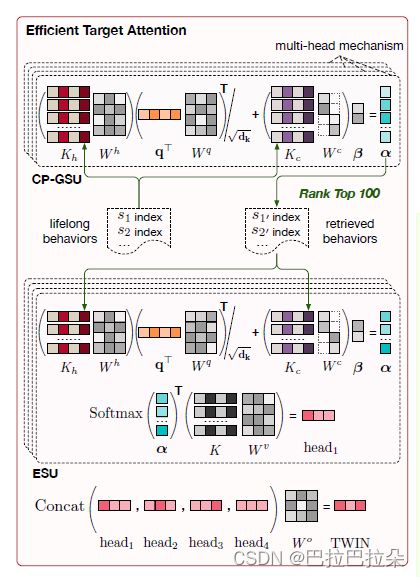
通过对用户行为序列特征进行拆分,将特征分为两部分:item固有特征H与user-item交互特征C。固有特征有:id、作者、主题、时长,交互特征有:用户点击时间戳、用户播放时间、点击页面位置、用户视频交互。
![]()
固有特征可以通过缓存策略减少计算。
对于用户项目交叉特征,缓存策略不适用,因为:1)。交叉特征描述了用户和视频之间的交互细节,因此不会在用户行为序列之间共享。 2).每个用户最多观看一次视频。即,在投影交叉特征时没有重复计算。因此,我们通过简化线性投影权重来降低计算成本。计算公式如下图所示,其实就是把每个交叉特征的emb映射到1维,最终输出一个L*J的向量,L:序列长度,J:交叉特征个数。

整体上是一个QKV的过程
alpha是一个序列长度的权重,query只与固有特征计算attention,交叉特征作为bias,不与query进行计算。
α = ( K h W h ) ( q T W q ) T d k + ( K c W c ) β ( 6 ) \alpha = \frac{ (K_hW^h) (q^TW^q)^T}{\sqrt{d_k} } + (K_cW^c) \beta \ \ \ \ \ \ (6) α=dk(KhWh)(qTWq)T+(KcWc)β (6)
上式中 α \alpha α 是一个L*1的向量,表示的是TA的attention结果。注意,公式(6)中, K h W h K_hW^h KhWh 通过离线缓存拿到,线上只计算其他部分。个人认为,将特征分为固有特征和交叉特征的原因在于:target没有交叉特征。
根据 α \alpha α 选择出top100,计算最终的attention:(该预测仅执行 100 多个行为,因此可以在线高效地进行,不需要再对特征K进行拆分。)从6式中取出top100个alpha聚合value。
A t t e n t i o n ( q T W q , K h W h , K c W c , K W v ) = S o f t m a x ( α ) T K W v ( 7 ) \mathrm{Attention} (q^TW^q, K_hW^h, K_cW^c, KW^v) =\mathrm{Softmax}(\alpha)^TKW^v \ \ \ (7) Attention(qTWq,KhWh,KcWc,KWv)=Softmax(α)TKWv (7)
T W I N = C o n c a t ( h e a d 1 , . . . , h e a d 4 ) W o \mathrm{TWIN} = \mathrm{Concat}(\mathrm{head_1},..., \mathrm{head_4} )W^o TWIN=Concat(head1,...,head4)Wo
h e a d α = A t t e n t i o n ( q T W α q , K h W α h , K W α v ) , α ∈ { 1 , 2 , 3 , 4 } ( 8 ) \mathrm{head_{\alpha}=\mathrm{Attention}(q^TW^q_{\alpha} , K_hW^h_{\alpha}, KW^v_{\alpha} )}, \alpha \in \{1,2,3,4\} \ \ \ \ \ \ \ \ (8) headα=Attention(qTWαq,KhWαh,KWαv),α∈{1,2,3,4} (8)