Detecting Everything in the Open World: Towards Universal Object Detection
1. 论文简介
- 论文题目《Detecting Everything in the Open World: Towards Universal Object Detection》
- 发表情况,CVPR2023
- [论文地址][https://arxiv.org/pdf/2303.11749.pdf]
- [代码地址][https://github.com/zhenyuw16/UniDetector]
2.背景与摘要
本文旨在解决通用目标检测问题,也即检测任意场景、任意类别的目标。

对手工标注的依赖、有限的视觉信息以及开放世界中新的物体类别,限制了传统检测器的通用性。因此,本文提出 UniDetector,一个可以识别开放世界中非常多类别的通用目标检测器,其核心要点包括:
- 它通过图像和文本空间的对齐,来利用多个来源以及多种标签空间的图像进行训练,保证有足够的信息让模型学习到通用的表示能力;
- 它很容易泛化到开放世界,同时可以平衡见过和未见过的类别,因为视觉和语言模态提供了丰富的信息;
- 通过作者提出的解耦训练方式以及概率校正,模型对新类别的泛化能力可以得到进一步提升;
最终,UniDetector 在只有 500 个类别参与训练的情况下,可以检测超过 7000 个类别。模型具有非常强的零样本泛化能力,平均可以超过有监督基线方法性能的 4%。在 13 个不同场景的公开检测数据集上,模型只用 3% 的训练数据就可以达到 SOTA 性能。
3. 方法介绍
基本流程包括三个步骤:
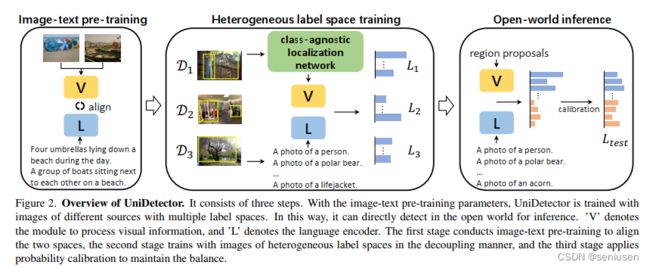
- 大规模图像文本对对齐的预训练,文中使用的是 RegionCLIP 预训练的参数
- 多标签空间的训练,此步骤使用多种来源多种标签空间的数据集来训练模型,并且将候选框生成和 RoI 分类两部分进行解耦
- 开放世界的推理,此步骤通过概率校正来平衡基础类别和未知类别
3.1 多标签空间训练
为了使用多标签空间的数据来进行训练,作者提出了三种可能的模型结构,如下图所示:
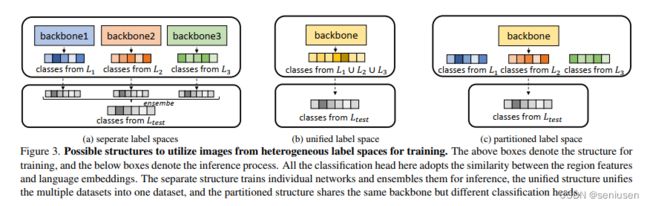
第一种结构,每一个数据集(也即一个标签空间)训练一个单独的模型,测试的时候,针对新类别的语言嵌入向量,每个模型都进行推理,然后再进行融合得到最终的结果。
第二种结构,将多标签空间统一为一个标签空间,这样图片都可以被看作来自一个数据集,诸如 Mosaic、Mixup 的技术手段则可以被用来提升不同标签空间的信息融合。
第三种称之为分区结构,不同来源的图片共享相同的特征提取器,但是有它们各自的分类层,测试时直接使用测试标签的类别嵌入向量来进行推理。
大规模数据不可避免地都存在长尾分布,针对闭集检测,比如 class-aware sampler (CAS)、 repeat factor sampler (RFS) 之类的采样策略都会有所帮助。但是,在开放世界检测问题中,最核心的问题是未知类别,这可以通过语言嵌入向量来解决,而长尾分布的问题则可以忽略不计,因此本文直接使用随机采样器。
同样地,诸如 equalized loss、seesaw loss 之类的损失函数作用也不大,本文直接使用基于 sigmoid 的损失函数,这样已知类别和未知类别之间不存在交互。为了避免随着类别数量的增长损失值过大,会随机采样一定数目的来别作为负例。
3.2 解耦候选框生成和 RoI 分类
两阶段的分类器包含一个视觉 backbone 编码器、一个 RPN 和一个 RoI 分类模块。针对标签空间 L L L 数据集 D D D 中的一张图片 I I I,模型可以总结为:
{ z i j } j = 1 L = Φ R o I ∘ Φ R P N ∘ Φ b a c k b o n e \{z_{ij}\}_{j=1}^L=\Phi_{RoI}\circ\Phi_{RPN}\circ\Phi_{backbone} {zij}j=1L=ΦRoI∘ΦRPN∘Φbackbone
p i j = 1 / ( 1 + e x p ( − z i j T e j / τ ) ) p_{ij}=1/(1+exp(-z_{ij}^Te_j/\tau)) pij=1/(1+exp(−zijTej/τ))
其中, p i j p_{ij} pij 是第 i i i 个区域对应类别 j j j 的概率, e j e_{j} ej 是类别 j j j 的语言嵌入向量。
候选框生成阶段是类别不可知的预测(只预测候选框是前景还是背景),所以,很容易扩展到未知类别。而 RoI 分类阶段是针对特定类别的,尽管有语言嵌入向量的帮助,它还是会偏向于已知类别。因此,若将这两个阶段联合在一起进行训练,分类阶段对新类别的敏感性将不利于候选框生成阶段的通用性,所以作者提出将两个阶段解耦分别训练来避免这种冲突。
作者提出了一个 CLN(class-agnostic localization network),来产生通用的候选框,其包含一个 RPN 和一个 RoI 头,如下图所示:
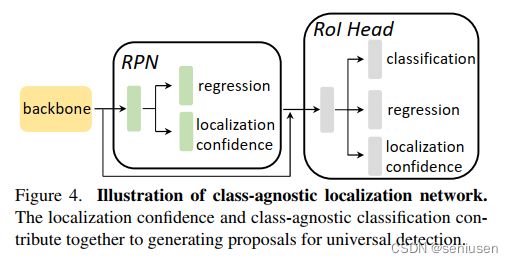
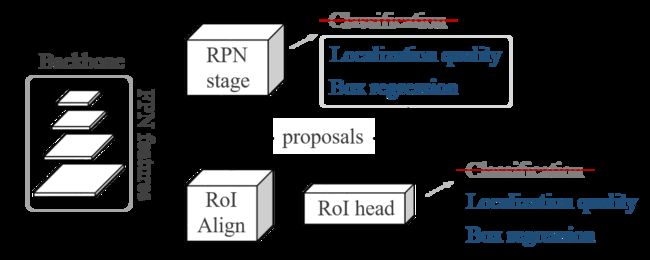
这样既可以产生候选框,进而可以通过 RoI 头来对产生的候选框进行微调。其思想来源自文章《Learning Open-World Object Proposals without Learning to Classify》,该篇文章的网络结构如下图所示,但是保留了 RoI 头里面的与类别无关的分类,文中说这样可以提供更强的监督信号。
针对第 i i i 个候选框,RPN 出来的定位置信度为 s i r 1 s_i^{r_1} sir1,RoI 头出来的定位置信度为 s i r 2 s_i^{r_2} sir2,分类得分为 s i c s_i^c sic,则 CLN 模块的最终置信度为它们的加权 η i = ( s i c ) α ⋅ ( s i r 1 s i r 2 ) 1 − α \eta_i = (s_i^c)^\alpha \cdot (s_i^{r_1}s_i^{r_2})^{1-\alpha} ηi=(sic)α⋅(sir1sir2)1−α。
3.3 推理
因为训练阶段只见过已知类别,所以训练好的检测器还是会偏向于已知类别。为了避免这种偏置问题,作者提出了一个概率校正来对预测结果进行后处理,其目的是降低已知类别的概率增加新的未知类别的概率,公式如下所示:
p i j = 1 1 + e x p ( − z i j T e j / τ ) / π j γ , j ∈ L t e s t p_{ij}=\frac{1}{1+exp(-z_{ij}^Te_j/\tau)}/\pi_j^{\gamma}, j \in L_{test} pij=1+exp(−zijTej/τ)1/πjγ,j∈Ltest
先验概率 π j \pi_j πj 记录了网络对类别 j j j 的偏置, π j \pi_j πj 越大,网络更朝着这个类别偏置,校正后其对应的概率变小。可以先在测试数据上推理一遍,通过结果中的类别数量来获得 π j \pi_j πj,如果测试数据数量太少,也可以使用训练数据来获取。
最终,第 i i i 个候选框针对类别 j j j 的得分为 s i j = p i j β η i 1 − β s_{ij} = p_{ij}^{\beta}{\eta}_i^{1-\beta} sij=pijβηi1−β。
4. 实验与结果
训练数据集从 COCO(80类)、Object365(365类)和 OpenImages(500类)中分别随机选取 35K、60K 和 78K 张图片,测试时在 LVIS、ImageNetBoxes 和 VisualGenome 三个数据集上进行。其中,LVIS v0.5 验证集包含 5000 张图片,1230 个类别;LVIS v1 验证集包含 19,809 张图片,1203 个类别。ImageNetBoxes 包含超过 3,000 个类别,随机选取 20,000 张图片作为验证集,为了和有监督基线方法对比闭集上的检测性能,会抽取 90,000 张图片作为训练集。最新版本的 VisualGenome 包含 7,605 个类别,但是由于大部分是机器标注的,噪声很大,作者选取 5,000 个没出现在训练图片中的类别来进行验证。

从上表可以看到,在 LVIS v0.5 数据集上,UniDetector 只使用采样的 O365 数据集训练就超越了用三个数据集训练的 Faster RCNN。而且,Faster RCNN 在 rare 类别的表现要远远低于 frequent 类别的表现,而 UniDetector 在二者中的表现则更加均衡。
针对多标签空间训练的三种结构,分区结构明显要优于前两个。另外,由于 OImg 数据集标注噪声较大,单独在 OImg 上训练的模型表现还不如单独在 COCO 上训练的模型,但如果在 COOC+O365 的基础上增加 OImg 数据集,反而可以提高模型的泛化能力,这也体现了多标签空间训练对通用目标检测带来的巨大优势。
一个通用的检测器不仅能非常好地泛化到开放世界检测中,其在闭集检测中也应当保持优越性能。在 COCO 数据集上进行 1 × 1\times 1× schedule 的训练,UniDetector 不仅表现超过基于 CNN 的方法,相比最新基于transformer 的方法也稍有提高。
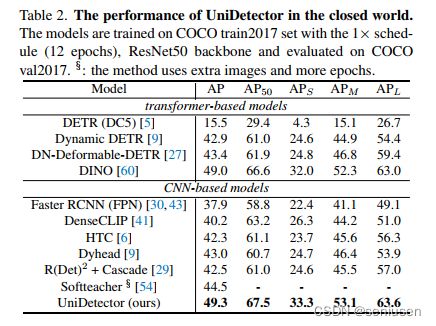
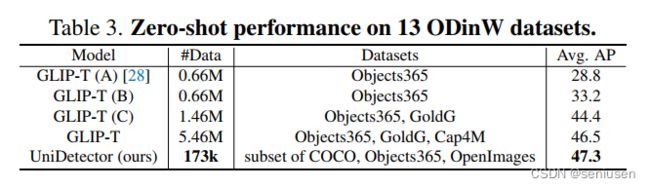
在 13 个自然场景(包括无人机、水下等)的检测数据集上,相比 GLIP-T,UniDetector 使用前者大约 3% 的数据集,就可以取得更好的结果(47.3 AP vs 46.5 AP)。
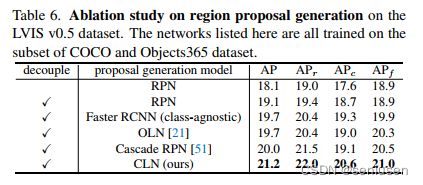
针对本文提出的 CLN 网络以及概率校正模块,作者分别进行了消融实验,验证了 CLN 比 OLN 效果更好,而且解耦训练的方式可以进一步提升模型性能。
增加概率校正模块后,模型在新类别上的 AP 均有明显提升。
