【Linux多线程】基于生产消费模型写的一个实例(附源代码+讲解)

生产消费模型
- 生产消费模型
-
- 为何要使用生产者消费者模型
- 生产者消费者模型优点
- 基于BlockingQueue的生产者消费者模型
-
- BlockQueue.cc
-
- 代码
- 解释
- BlockQueue.hpp
-
- 代码
- 解释
- Makefile
-
- 代码
- 解释
- Task.hpp
-
- 代码
- 解释
生产消费模型
为何要使用生产者消费者模型
生产者消费者模式就是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而
通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者
要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。这个阻塞队
列就是用来给生产者和消费者解耦的。
生产者消费者模型优点
- 解耦
- 支持并发
这里的支持并发并不是说在临界区(一般情况下都不是在临界区发生的并发),而是 生产前 和消费后两个状态下的并发 举例子:
生产前的准备 和消费后的处理 这两个状态就是并发的!!! - 支持忙闲不均
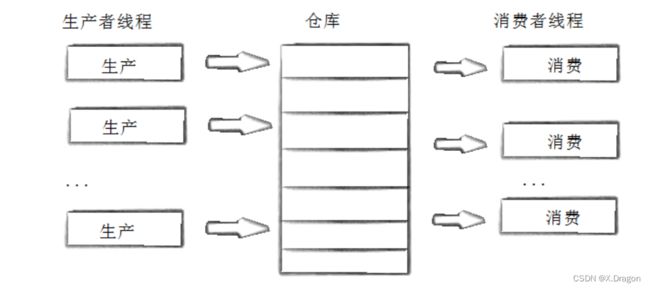
基于BlockingQueue的生产者消费者模型
BlockQueue.cc
代码
#include"BlockQueue.hpp"
#include"Task.hpp"
#include bq;
// bq.push(10);
// int a = bq.pop();
// cout << a << endl;
// 既然可以使用int类型的数据,我们也可以使用自己封装的类型,包括任务
// BlockQueue bq;
BlockQueue<Task> bq;
pthread_t c, p;
pthread_create(&c, nullptr, consumer, &bq);
pthread_create(&p, nullptr, productor, &bq);
pthread_join(c, nullptr);
pthread_join(p, nullptr);
return 0;
}
解释
- 代码是一个简单的多线程程序,涉及生产者-消费者模型。
- 首先,在代码中定义了一个BlockQueue类,它是一个串行,用于在生产者和消费者之间提交任务。
- 接下来,定义了一个Task类,用于表示任务。任务对象包含两个整数和一个字符,用于表示要执行的操作。
- 在main函数中,首先使用srand函数初始化随机数种子,以确保随机数的生成。
- 然后创建了一个BlockQueue对象bq,作为生产者和消费者之间的共享队列。
- 通过调用pthread_create函数创建两个线程c和p,分别用于消费者和生产者。同时,将共享队列bq传递给这两个线程,以便它们可以访问和操作队列中的任务。
- 在消费者线程函数consumer中,通过调用bqp->pop()方法从队列中取出一个任务t,然后执行该任务,计算结果输出并。消费者线程将一直循环执行这个过程。
- 在生产者线程函数中productor,首先生成随机的两个整数和一个操作符,然后创建一个任务对象t表示这个任务。接着,将该任务对象t推入共享队列bq中,表示生产了一个任务。生产者线程将一直循环执行这个过程。
- 最后,主线程使用pthread_join函数等待两个线程c并p结束,然后退出程序。
- 总体来说,大概代码展示了多线程编程中的生产者-消费者模型,其中一个线程生产任务并推入共享队列,另一个线程从队列中取出任务并执行。通过使用互斥锁和条件变量,保证了线程之间的同步与交互,使得生产者和消费者可以安全地协作。
BlockQueue.hpp
代码
#pragma once
#include 解释
这是一个模板类,实现了一个线程安全的阻塞队列(BlockQueue)。阻塞队列是一个在并发编程中常见的数据结构,它可以在多个线程之间安全地传递数据。在这个类中,提供了两个主要的操作,push()和pop(),分别表示向队列中添加数据和从队列中获取数据。当队列满时,push()操作将会阻塞,直到有空间可以添加数据。同理,当队列为空时,pop()操作将会阻塞,直到有数据可以获取。
接下来,我们逐个解释一下代码中的各个部分:
- 成员变量:
cap_:队列的容量。
bq_:队列本身,用于存储数据。
mutex_:用于保护阻塞队列的互斥锁,防止多个线程同时操作队列。
conCond_和proCond_:分别表示消费者和生产者的条件变量。它们用于在特定条件下让线程等待,比如队列为空或队列已满。
成员函数:
BlockQueue()和~BlockQueue():构造函数和析构函数,用于初始化和销毁互斥锁以及条件变量。
push():向队列中添加数据。如果队列已满,该函数将阻塞,直到队列中有可用空间。
pop():从队列中获取数据。如果队列为空,该函数将阻塞,直到队列中有可用数据。
lockQueue()和unlockQueue():用于加锁和解锁队列。
isEmpty()和isFull():用于检查队列是否为空或已满。
proBlockWait()和conBlockwait():用于在特定条件下让生产者和消费者线程等待。
wakeupPro()和wakeupCon():用于唤醒等待的生产者和消费者线程。
pushCore()和popCore():分别表示实际的添加数据和获取数据的操作。
这个阻塞队列可以用于生产者-消费者模型,在多线程编程中,生产者将数据放入队列,消费者从队列中获取数据,由于队列的线程安全性,可以保证数据的一致性。同时,通过条件变量的使用,实现了当队列满或空时,相应的生产者线程或消费者线程会阻塞等待,直到条件满足(即有空间放入数据或有数据可取)时再继续执行
Makefile
代码
CC=g++
FLAGS=-std=c++11
LD=-lpthread
bin=BlockQueue
src=BlockQueueTest.cc
$(bin):$(src)
$(CC) -o $@ $^ $(LD) $(FLAGS)
.PHONY:clean
rm -f $(bin)
解释
CC=g++:定义编译器为g++。
FLAGS=-std=c++11:定义编译标志,这里是指定使用C++11标准。
LD=-lpthread:定义链接标志,这里是链接pthread库。
bin=BlockQueue:定义目标可执行文件的名字为BlockQueue。
src=BlockQueueTest.cc:定义源文件名为BlockQueueTest.cc。
接下来的部分定义了如何生成目标文件:
( b i n ) : (bin): (bin):(src):表示目标文件依赖于源文件,当源文件有任何改动时,目标文件都需要重新生成。
$(CC) -o $@ $^ $(LD) ( F L A G S ) :定义了生成目标文件的命令。 (FLAGS):定义了生成目标文件的命令。 (FLAGS):定义了生成目标文件的命令。(CC)是编译器,-o @ 表示生成的目标文件名, @表示生成的目标文件名, @表示生成的目标文件名,^表示所有的依赖文件, ( L D ) 表示链接标志, (LD)表示链接标志, (LD)表示链接标志,(FLAGS)表示编译标志。总的来说,这条命令的意思是使用g++编译器编译源文件并链接pthread库,生成的目标文件名为BlockQueue。
最后,定义了一个伪目标clean,它不代表任何文件,主要用于清理项目:
.PHONY:clean:声明clean为伪目标。这样,make就不会去检查是否存在一个叫做clean的文件,而是每次都执行clean规则。
rm -f $(bin):删除生成的目标文件。rm是删除文件的命令,-f参数表示强制删除。
总的来说,这个Makefile文件定义了如何编译项目和清理项目,让编译和链接过程更加自动化
Task.hpp
代码
#pragma once
#include 解释
这是一个名为Task的C++类。这个类封装了一种任务,具体来说,就是一个包含两个整数和一个运算符的简单数学运算。类的主要功能由run()函数实现,它根据operator_的值来决定应执行哪种运算,并返回结果。以下是各个部分的详细解释:
成员变量:
elemOne_ 和 elemTwo_:这是两个需要进行运算的整数。
operator_:这是一个字符,表示应执行的运算类型。
构造函数:
Task():默认构造函数,将两个整数初始化为0,运算符初始化为字符’0’。
Task(int one, int two, char op):参数化构造函数,允许在创建对象时指定两个整数和运算符的初始值。
成员函数:
operator()():函数调用运算符重载,使得该类的对象可以像函数一样被调用,实际上调用了run()函数。
run():执行运算并返回结果。如果operator_是’+‘、’-‘、’*‘、’/‘或’%‘,则执行相应的运算。如果operator_是’/‘或’%',并且elemTwo_是0,则打印一条错误信息并返回-1。如果operator_是其他值,则打印一条错误信息并继续运行。
get(int *e1, int *e2, char *op):获取elemOne_、elemTwo_和operator_的值,并将它们分别存储在e1、e2和op指向的内存中。
这个类可以用于表示和执行简单的二元运算任务,例如:
Task task(10, 2, '/');
int result = task(); // result is 5
这将创建一个任务,它将10除以2,并返回结果。