PyTorch深度学习实战(9)——学习率优化
PyTorch深度学习实战(9)——学习率优化
-
- 0. 前言
- 1. 学习率简介
- 2. 梯度值、学习率和权重之间的相互作用
- 3. 学习率优化实战
-
- 3.1 学习率对缩放后的数据集的影响
- 3.2 学习率对未缩放数据集的影响
- 小结
- 系列链接
0. 前言
学习率( learning rate )是神经网络训练中一个重要的超参数,用于控制模型更新参数的步长大小,它决定了每次迭代中模型参数更新的幅度。学习率的选择对于训练的结果具有重要影响,学习率过高会导致模型震荡不收敛甚至发散,无法有效优化目标函数;而学习率过低则会导致收敛速度缓慢,需要更多的迭代才能达到较好的效果。本节首先介绍学习率如何影响模型训练,并通过修改学习率观察不同学习率对模型性能的影响。
1. 学习率简介
在神经网络训练中,我们通过最小化损失函数来优化模型的参数。梯度下降是一种常用的优化算法,它通过计算损失函数对于每个参数的导数来指导参数的更新,而学习率就是梯度下降算法中的一个重要的调节参数。
为了了解学习率对模型训练的影响,我们尝试拟合以下简单方程:
y = 3 × x y=3\times x y=3×x
其中, y y y 是输出, x x x 是输入。给定一组输入和预期输出值,我们使用不同的学习率拟合方程,以了解学习率的影响。
(1) 定义输入和输出数据集:
x = [[1],[2],[3],[4]]
y = [[3],[6],[9],[12]]
(2) 定义 feed_forward() 函数,此处使用的网络并不包含隐藏层:
y = w × x + b y=w\times x+b y=w×x+b
在以上函数中,我们尝试估计参数 w w w 和 b b b:
from copy import deepcopy
import numpy as np
def feed_forward(inputs, outputs, weights):
out = np.dot(inputs,weights[0])+ weights[1]
mean_squared_error = np.mean(np.square(out - outputs))
return mean_squared_error
(3) 定义 update_weights() 函数利用梯度下降更新网络权重:
def update_weights(inputs, outputs, weights, lr):
original_weights = deepcopy(weights)
org_loss = feed_forward(inputs, outputs, original_weights)
updated_weights = deepcopy(weights)
for i, layer in enumerate(original_weights):
for index, weight in np.ndenumerate(layer):
temp_weights = deepcopy(weights)
temp_weights[i][index] += 0.0001
_loss_plus = feed_forward(inputs, outputs, temp_weights)
grad = (_loss_plus - org_loss)/(0.0001)
updated_weights[i][index] -= grad*lr
return updated_weights
(4) 将权重和偏差值初始化为随机值:
W = [np.array([[0]], dtype=np.float32), np.array([[0]], dtype=np.float32)]
权重和偏差值随机初始化为 0,输入权重值的形状为 1 x 1,因为输入中每个数据点的形状为 1 x 1,偏置值的形状为 1 x 1 (输出中只有一个节点,每个输出只有一个值)。
(5) 将学习率设为 0.01 执行 update_weights() 函数,循环迭代 1,000 次,并检查权重值( W )随时间的变化:
weight_value = []
for epx in range(1000):
W = update_weights(x,y,W,0.01)
weight_value.append(W[0][0][0])
在以上代码中,设置学习率为 0.01 并重复调用 update_weights() 函数以在每个 epoch 结束时获取修改后的权重。此外,在每个 epoch 中,我们将最近更新的权重作为输入,以在下一 epoch 中继续更新权重。
(6) 绘制每个 epoch 结束时的权重参数值:
import matplotlib.pyplot as plt
plt.plot(weight_value)
plt.title('Weight value over increasing epochs')
plt.xlabel('Epochs')
plt.ylabel('Weight value')
plt.show()
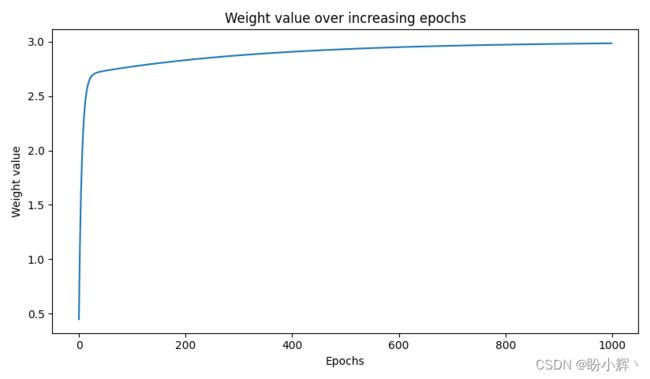
可以看到,在上图中,权重值逐渐增加,最终在 3 附近达到稳定。
为了了解学习率对权重更新的影响,我们测试当学习率为 0.1 和 1 时,权重值随时间的变化情况,下图显示了使用不同学习率时,权重的变化情况:
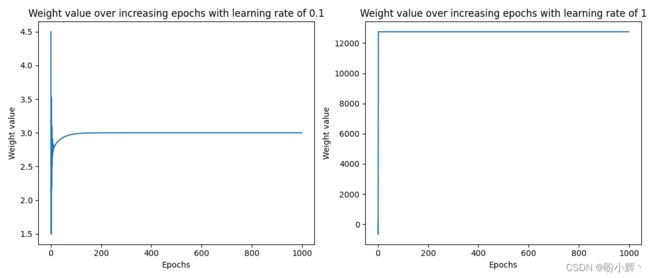
可以看到,当学习率非常小时( 0.01 )时,权重值缓慢向最优值移动(需要更多的 epoch);而在学习率较高( 0.1 )时,权重值最初变化较为剧烈,然后迅速得到最优值(需要较少的 epoch);而当学习率过高( 1 )时,权重值无法达到最优值。
学习率低时权重值没有大幅变化的原因是我们将权重更新量限制为 梯度x学习率,本质上是由于学习率较小导致更新量较小;当学习率过高时,权重更新量相应较高,损失的变化非常小,以至于权重无法达到最优值。
2. 梯度值、学习率和权重之间的相互作用
为了更深入地了解梯度值、学习率和权重之间的相互作用,我们只运行 10 个 epoch 的 update_weights() 函数,并打印以下值以了解它们如何随 epoch 变化:
- 每个
epoch开始时的权重值 - 权重更新前的损失
- 少量更新权重后的损失
- 梯度值
修改 update_weights() 函数以打印以上值:
def update_weights(inputs, outputs, weights, lr):
original_weights = deepcopy(weights)
org_loss = feed_forward(inputs, outputs, original_weights)
updated_weights = deepcopy(weights)
for i, layer in enumerate(original_weights):
for index, weight in np.ndenumerate(layer):
temp_weights = deepcopy(weights)
temp_weights[i][index] += 0.0001
_loss_plus = feed_forward(inputs, outputs, temp_weights)
grad = (_loss_plus - org_loss)/(0.0001)
updated_weights[i][index] -= grad*lr
if(i % 2 == 0):
print('weight value:', np.round(original_weights[i][index],2),
'original loss:', np.round(org_loss,2),
'loss_plus:', np.round(_loss_plus,2),
'gradient:', np.round(grad,2),
'updated_weights:', np.round(updated_weights[i][index],2))
return updated_weights
在以上代码中,打印原始权重值( original_weights[i][index])、损失( org_loss)、权重更新后损失值( _loss_plus)、梯度( grad )以及更新后的权重值( updated_weights)。使用不同的学习率,观察以上各值如何随着 epoch 变化。
学习率 0.01 时:
W = [np.array([[0]], dtype=np.float32), np.array([[0]], dtype=np.float32)]
weight_value = []
for epx in range(10):
W = update_weights(x,y,W,0.01)
weight_value.append(W[0][0][0])
print(W)
import matplotlib.pyplot as plt
plt.plot(weight_value[:100])
plt.title('Weight value over increasing epochs when learning rate is 0.01')
plt.xlabel('Epochs')
plt.ylabel('Weight value')
plt.show()
输出结果如下所示:
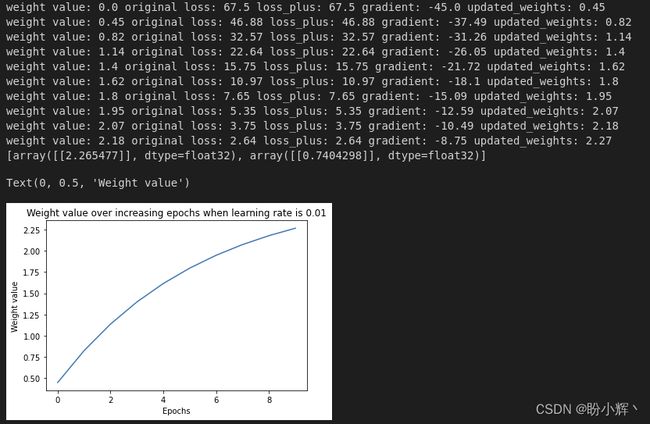
可以看到,当学习率为 0.01 时,损失值缓慢下降,权重值也缓慢向最优值移动。
学习率为 0.1,改变学习率参数值运行相同代码的输出如下:
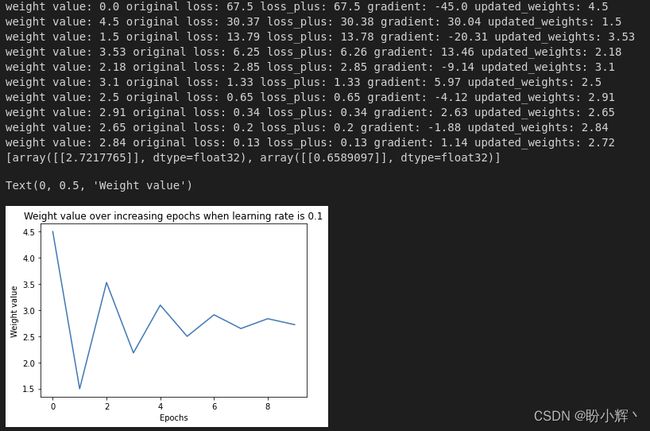
对比学习率分别为 0.01 和 0.1 的结果,主要区别如下:与学习率为 0.1 时相比,学习率为 0.01 时,权重的更新要慢得多,更新速度较慢的原因是学习率较低,因为权重是通过梯度乘以学习率来更新的。
除了权重更新的幅度,我们还要注意权重更新的方向:当权重值小于最优值时梯度为负,当权重值大于最优值时梯度为正,从而保证了网络在正确的方向上更新权重值。
最后,我们观察与学习率为 1 时的运行结果,学习率为 1,改变学习率参数值运行相同代码的输出如下:
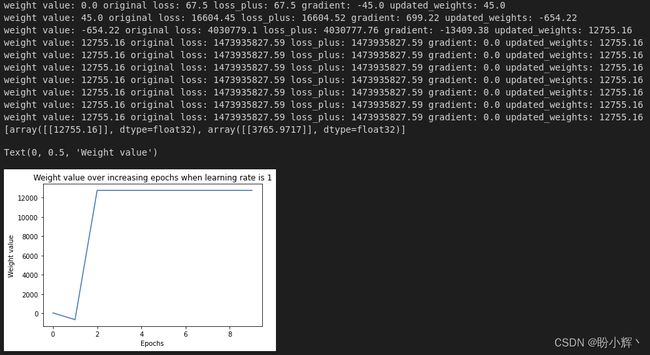
从上图中可以看出,权重与最优值间的偏离较大,除此之外,权重值更新幅度较大,因此权重值的微小变化几乎不会影响梯度的变化,权重并不能收敛于最优值。
一般来说,学习率越低越好。这样,模型能够缓慢学习,并将权重调整为最佳值,学习率参数值通常设置在 0.0001 和 0.01 之间。
3. 学习率优化实战
我们已经了解到学习率在获得最佳权重方面起着关键作用。当学习率较小时,权重会平滑的向最优值移动,而当学习率较大时,权重会在非最优值处振荡(陷于局部最优值)。为了理解不同学习率的影响,我们将使用 Fashion MNIST 进行以下实验:
- 在缩放后的数据集上使用较高学习率 (
0.1) - 在缩放后的数据集上使用较低学习率 (
0.00001) - 在未缩放的数据集上使用较低学习率 (
0.001) - 在未缩放的数据集上使用较高学习率 (
0.1)
3.1 学习率对缩放后的数据集的影响
在本节中,我们将使用不同学习率对比模型在训练和验证数据集上的准确率。
3.1.1 较高学习率
本节中,我们使用 Adam 优化器,训练过程中唯一的变化是定义 get_model() 函数时,修改优化器中的学习率,将学习率( lr )修改为 0.1。除了对 get_model() 函数进行的修改之外,其他代码都与神经网络训练一节中完全相同。修改优化器,使其学习率为 0.1 ( lr=1e-1):
def get_model():
model = nn.Sequential(
nn.Linear(28 * 28, 1000),
nn.ReLU(),
nn.Linear(1000, 10)
).to(device)
loss_fn = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=1e-1)
return model, loss_fn, optimizer
执行代码后,模型在训练和验证数据集上对应的准确率和损失变化如下:
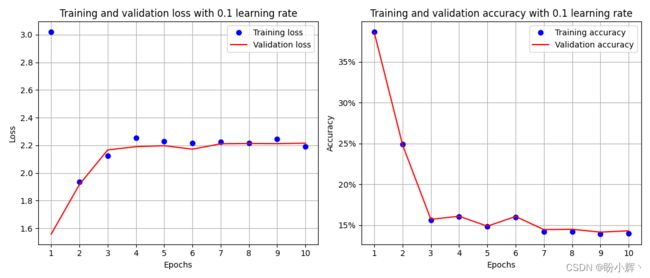
3.1.2 中等学习率
通过修改 get_model() 函数并从头开始重新训练模型,将优化器的学习修改为 0.001:
def get_model():
model = nn.Sequential(
nn.Linear(28 * 28, 1000),
nn.ReLU(),
nn.Linear(1000, 10)
).to(device)
loss_fn = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=1e-3)
return model, loss_fn, optimizer
在以上代码中,我们修改了 lr 参数值,与训练和验证数据集对应的准确率和损失值变化如下:
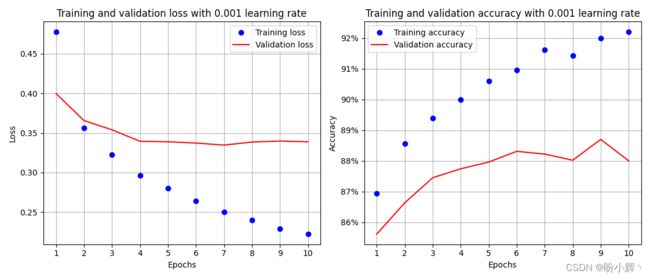
从以上输出结果可以看出,当学习率从 0.1 降低到 0.001 时,模型性能有了大幅提升。
3.1.3 较低学习率
通过修改 get_model() 函数并从头开始重新训练模型,将优化器的学习率修改为 0.00001,并运行模型更多的 epoch (100):
def get_model():
model = nn.Sequential(
nn.Linear(28 * 28, 1000),
nn.ReLU(),
nn.Linear(1000, 10)
).to(device)
loss_fn = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=1e-5)
return model, loss_fn, optimizer
在以上中,我们修改了 lr 参数值,与训练和验证数据集对应的准确率和损失变化如下:
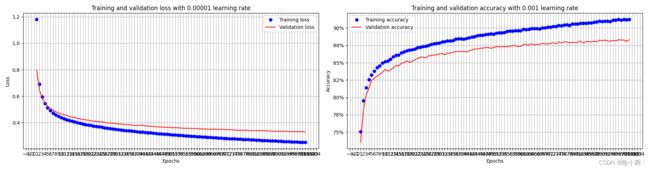
从上图中,我们可以看到模型的学习速度相对而言慢了很多,与学习率为 0.001 时相比,需要 100 个 epoch 模型才能达到约 89% 的准确率,而学习率为 0.001 时只需要 8 个 epoch。此外,与较大学习率相比,当学习率较低时,训练和验证损失之间的差距要小得多。这是因为,当学习率较低时,权重更新幅度也要低得多,训练和验证损失之间的差距并不会迅速扩大。
我们已经了解了学习率对训练和验证数据集准确率的影响。在下一节中,我们将了解不同学习率的权重值在各层之间的分布变化。
3.1.4 不同学习率的模型参数分布
我们已经了解到,在较高学习率时( 0.1),模型被无法正确训练(模型欠拟合)在学习率中等( 0.001 )或低 (0.00001 )时可以得到较高的准确率。中等学习率能够快速过拟合,而较低学习率需要更长的时间才能达到与中等学习率模型相近的准确率。在本节中,我们将了解参数分布如何衡量模型过拟合和欠拟合。
在我们使用的简单模型中有四个参数组:
- 连接输入层和隐藏层的层的权重
- 隐藏层中的偏置值
- 连接隐藏层和输出层的层的权重
- 输出层中的偏置值
可以使用以下代码来观察参数的分布情况:
for ix, par in enumerate(model.parameters()):
if(ix == 0):
plt.subplot(141)
plt.hist(par.cpu().detach().numpy().flatten())
plt.title('Distribution of weights conencting input to hidden layer')
elif(ix == 1):
plt.subplot(142)
plt.hist(par.cpu().detach().numpy().flatten())
plt.title('Distribution of biases of hidden layer')
elif(ix == 2):
plt.subplot(143)
plt.hist(par.cpu().detach().numpy().flatten())
plt.title('Distribution of weights conencting hidden to output layer')
elif(ix == 3):
plt.subplot(144)
plt.hist(par.cpu().detach().numpy().flatten())
plt.title('Distribution of biases of output layer')
plt.show()
使用三种不同的学习率,输出结果如下所示:
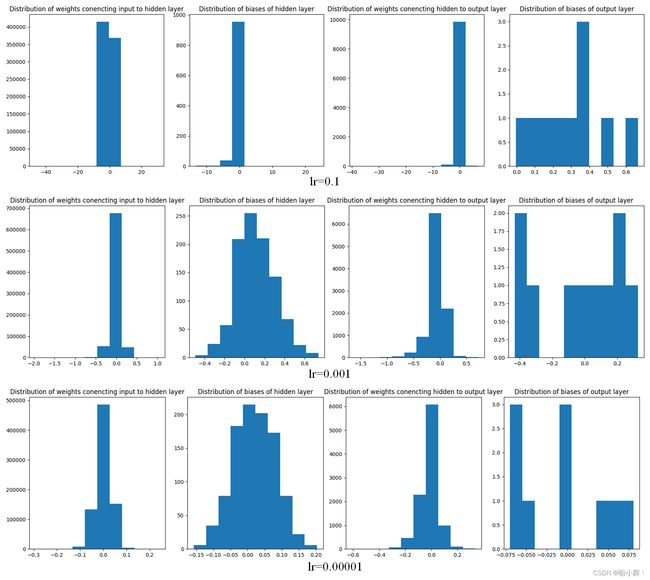
在上图中,我们可以看到:
- 当学习率较高时,与中低学习率相比,参数的分布范围大得多
- 当参数分布范围较大时,就会发生过拟合
3.2 学习率对未缩放数据集的影响
在本节中,我们在定义数据集类时使用原始未缩放数据集:
class FMNISTDataset(Dataset):
def __init__(self, x, y):
x = x.float()
x = x.view(-1,28*28)
self.x, self.y = x, y
def __getitem__(self, ix):
x, y = self.x[ix], self.y[ix]
return x.to(device), y.to(device)
def __len__(self):
return len(self.x)
使用不同学习率训练模型,准确率和损失随 epoch 的变化如下:
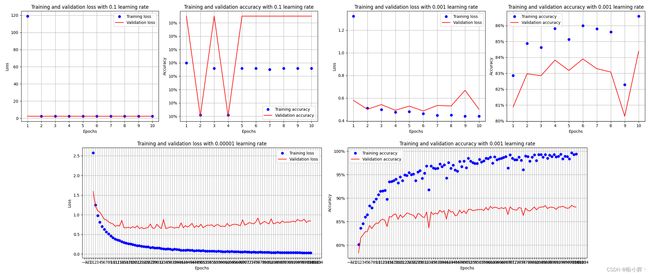
在上图中可以看到,当数据集并未缩放时,学习率为 0.1 时无法训练出准确的模型,而学习率为 0.001 时准确率也会下降,当学习率非常小时( 0.00001 )时,模型同样能够学习得到较优性能,但出现了过拟合问题。我们可以通过查看网络各层的权重参数分布来理解这种情况发生的原因:
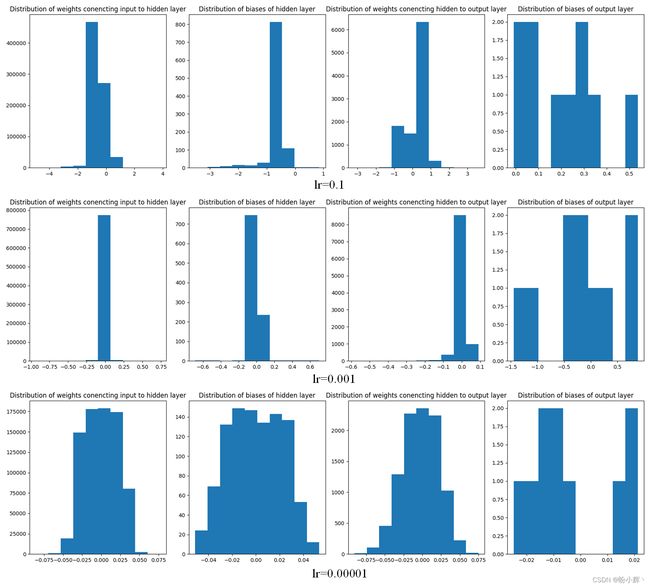
可以看到,与较高的学习率相比,当模型学习率较低时,权重的范围相对小得多。在未缩放数据集上学习率为 0.00001 等价于在缩放数据集上学习率为 0.001 时的模型性能,这时学习率较低时权重可以以较小幅度进行修改,因为在这种情况下 梯度x学习率 是一个非常小的值。通常,学习率过低会导致训练模型需要较长时间,而学习率过高会导致模型训练变得不稳定。
小结
学习率的优化是神经网络训练中不可或缺的一环,合理地选择学习率及采用适当的调整策略,能够帮助提升模型的训练效果。本节中,我们介绍了学习率影响模型训练的原理,并通过实战展示了不同学习率对模型性能的影响。
系列链接
PyTorch深度学习实战(1)——神经网络与模型训练过程详解
PyTorch深度学习实战(2)——PyTorch基础
PyTorch深度学习实战(3)——使用PyTorch构建神经网络
PyTorch深度学习实战(4)——常用激活函数和损失函数详解
PyTorch深度学习实战(5)——计算机视觉基础
PyTorch深度学习实战(6)——神经网络性能优化技术
PyTorch深度学习实战(7)——批大小对神经网络训练的影响
PyTorch深度学习实战(8)——批归一化