03_008内存映射原理_虚拟内存区域vm_area_struct详解,和mmap系统钓调用及物理内存结构体完全分析
前言
上一个记录中的 虚拟地址里的虚拟内存区域没有说的很完全
这次补充一下 同时记录一些 物理地址空间 内存映射原理 最后直接通过进程使用函数完成虚拟空间到物理空间的映射
物理地址空间
物理地址是处理器在系统总线上看到的地址。使用RISC的处理器通常只实现一个物理地址空间,外围设备和物理内存使用统一 的物理地址空间。有些处理器架构把分配给外围设备的物理地址区域称为设备内存。
处理器通过外围设备控制器的寄存器访问外围设备,寄存器分为控制寄存器,状态寄存器和数据寄存器三大类。
外围设备的寄存器通常被连续地编址,处理器对外围设备寄存编址方式分为两种: I/O映射方式(I/O-mapped) ,内存映射方式(memory-mapped).
举个例子
Io映射x86上 给io专门分配了空间 访问要啥in out指令之类的
内存映射是使用risc 实现一个物理地址空间 外围设备和物理内存使用统一的物理地址空间
处理器可以像访问一个内存单元这样一样访问外围设备 不需要提供专门的io指令
进程这些程序只能通过虚拟地址访问外设 所以内核需要提供一些接口把这些外围设备的物理地址映射到虚拟地址空间中 ----> ioremaap
感觉是这个样子

ARM64架构分为两种内存类型:
正常内存(Normal Memory) :包括物理ram内存和只读存在器(ROM) ;
设备内存(Device Memory) :指分配给外围设备寄存器的物理地址区域;
当把这两种内存都映射到虚拟空间的时候 需要用 vm_area_struct 来描述
应用程序只能通过虚拟地址访问外设寄存器,内核提供API函数来把外设寄存器的物理地址映射
到虚拟地址空间。
内存映射原理
下面这一段简单描述
创建内存映射时,在进程的用户虚拟地址空间中分配一个虚拟内存区域 vm_area_struct 。
内核采用延迟分配物理ram内存的策略,在进程第一-次访问虚拟页的时候, 产生缺页异常。如果是文件映射,那么分配物理页,把文件指定区间的数据读到物理页中,然后在页表中把虚拟页映射到物理页。
如果是匿名映射,就分配物理页,然后在页表中把虚拟页映射到物理页。(就像映射iic的控制器地址)
下面这一段具体一点描述 有点绕 ,哪天被绕晕了没事 下面还有实例
进程启动后在虚拟地址空间 给映射创建映射区 先在用户空间调用mmp 在这个进程的虚拟地址空间中找一段空闲满足要求的连续虚拟地址 作为内存虚拟映射区 对这个区域初始化 插入这个进程的虚拟区域链表vm_area_struct
比如进程在读写这块虚拟地址 去查询这个页表 发现这一段内存并不在物理页上 因为虽然建立了映射关系 但是还没有把这个文件从磁盘中移到内存当中 所以这次就发生了缺页异常中断 内存就请求磁盘调度到这个页面
调页过程: 先在交换缓存空间 switch chache当中进行查找 如果没有就通过not_page()这个函数把这个缺页从磁盘调入内存 之后进程就对它进行读写操作 如果在读写操作中改变页面内容了 一段时间后系统会自动回写一些脏页面到磁盘中
后面继续讲解 比如修改后的脏页面 不会立刻更新到文件当中 我们可以调用ms_sync()强制进行回写
vm_area_struct结构体分析
对一个vm_area区域进行描述 有成员标志位用来表示该虚拟区域是否能可读可写 是否支持共享
有file_operation成员 用来表示对这个区域的操作函数
struct vm_ area_ struct {
//这两个成员分别用来保存该虚拟内存空间的首地址和末地址后第--个字节的地址。
unsigned long vm_ start;
unsigned long vm_ end;
struct vm_ area_ struct *vm_ next, *vm_ prev;
//^分别VMA链表的前后成员连接操作
//如果采用链表组织化,会影响到它搜索速度问题,解决此问题采用红黑树(每个进程结构体mm_struct中都
//创建一棵红黑树,将VMA作为一个节点加入到红黑树中,这样可以提升搜索速度)
struct rb_ node vm_ _rb;
/*
Largest free memory gap in bytes to the left of this VMA.
Either between this VMA and vma->vm_ prev, or between
one of the
x VMAs below us in the VMA rbtree and its ->vm_ prev. This helps
x get_ unmapped_ area find a free area of the right size.
unsigned long rb_ subtree_ gap;
/* Second cache line starts here. */
struct mm_ struct *vm_ mm;
//指向内存描述符,即虚拟内存区域所属的用户虚拟地址空间
pgprot_ t Vm_ page_ prot;
保护位,即访问权限
/*标志
#define VM_ READ
0x00000001
#define VM_ WRITE
0x00000002
#define VM_ EXEC
0x00000004
#define VM_ _SHARED 00000008 */
unsigned long Vm_ flags;
/*上面的宏为了支持查询一个文件区间被映射到哪些虚拟内存区域,把--个文件映射到的所有虚拟内存区域加入该文件地地址空间结构
address_ space的成员i_ _mmap指 向的区域树*/
struct {
struct rb_ node rb;
unsigned long rb_ subtree_ last;
} shared;
/*把虚拟内存区域关联的所有anon__vma实例串联起来,一个虚拟内存区域会关联到父进程的anon__vma实例和自己的anon__vma实例*/
struct list_ head anon_ vma_ chain;
/*指向一个anon__vma实例,结构anon__vma用来组织匿名页被映射到的所有的虚拟地址空间*/
struct anon_ vma *anon vma; /* Serialized by page_ table_ lock
/*
虚拟内存操作集合 fileoperation下面的各种操作函数
struct vm_ operations_ struct{
void (*open) (struct vm_ area_ struct *area); // 在创建虚拟内存区域时调用open方法
void (*close) (struct vm_ area_ struct *area); //在删除虛拟内存区域时调用close方法
int (*mremap) (struct vm_ area_ struct*area); //使用系统调用mremap移动虚拟内存区域时调用mremap方法
int (*fault) (struct vm_ fault *vmf); //访问文件映射的虛拟页时,如果没有映射到物理页,生成缺页异常,
异常处理程序调用fault就去来把文件的数据读到文件页缓存当中
. //与fault类似, 区别是huge_ fault方法针对使用透明巨型页的文件映射
int (*huge_ fault) (struct vm_ fault *vmf, enum page_ entry_ size pe_ size) ;
读文件映射的虚拟页时,如果没有映射到物理页,生成缺页异常,异常处理程序除了读入正在访问的文件页,
还会预读后续的文件页,调用map_ pages方法在文件的页缓存中分配物理页
void (*map_ pages) (struct vm_ fault *vmf,
pgoff_ _t start_ pgoff, pgoff_ t end_ pgoff);
//第一次写私有的文件映射时,生成页错误异常,异常处理程序执行写时复制,
调用page_ mkwrite 方法以通知文件系统页即将变成可写,以便文件系统检查是否允许写,或者等待页进入合适的状态。
int (*page_ mkwrite) (struct vm_ fault *vmf) ; .
*/
const struct Vm_ operations_ struct *vm_ ops;
/* Information about our backing store: */
unsigned long vm_ pgoff;
//文件偏移,单位是页
struct file * vm_ file;
//文件,如果是私有的匿名映射,该成员是空指针。
void * Vm_ private_ data;
//指向内存区的私有数据
}
系统调用实战
先分清c库提供的mmap()函数 是在应用层使用的
内核层是linux内核提供的mmap()函数 不要搞混了
函数介绍 c库mmap
1、mmap0----创建内存映射
#include
void *mmap(void *addr,size_ t length, int prot, int flags, int fd, off t offset);
为什么要使用mmap映射呢 直接读写文件不香吗???
1.系统调用mmap():进程创建匿名的内存映射,把内存的物理页映射到进程的虚拟地址空间。
2.进程把文件映射到进程的虚拟地址空间,可以像访问内存一样访问文件,不需要调用系统调用read()/write()访问文件,
从而避免用户模式和内核模式之间的切换,提高读写文件速度。
3.两个进程针对同一个文件创建共享的内存映射,实现共享内存。
代码
进程1 映射磁盘的文件 从物理空间到虚拟空间 给里面写入一堆结构体people
过15秒再读一下这个文件
#include 此时能发现进程1过了15s后 内容被修改了
代码具体原理分析
上面不就改了文件内容吗 但是背后的原理其实为 mmap做了什么好事情
mmap内存映射的实现过程主要分为三个阶段:
(一):进程启动映射过程并在虚拟地址空间当中为映射创建映射区域
1.进程在用户空间调用mmap也就是上面那个函数。
2.在当前进程的地址空间当中寻找一段连续的空虚的虚拟地址
3.给这块虚拟地址分配一个vm_area_struct的结构并对其各个区域进行初始化
4.将新键的虚拟结构插入到虚拟地址空间(mm_struc)的链表或者红黑树当中
(二):实现物理内存地址和虚拟地址的映射关系
1.为映射分配了新的虚拟地址空间之后通过待映射的文件描述符指针,在文件描述符表当中找到对应的文件描述符链接到内核已经打开的文件描述符集当中的struct_file,这个struct_file维护着这个被打开的文件的各项信息
2.通过这个文件的结构体链接到file_operations,调用内核的mmap其函数原型为int mmap(struct filefilp,struct vm_area_structvma),请注意不是用户态的mmap
3.内核mmap函数通过虚拟文件系统当中的inode定位到文件的物理地址
4.通过reamp_pfn_range函数建立页表即实现了文件地址和虚拟地址的映射关系。
(三)
1.进程的读或写操作访问虚拟地址空间这一段映射地址,通过查询页表,发现这一段地址并不在物理页面上。因为目前只建立了地址映射,真正的硬盘数据还没有拷贝到内存中,因此引发缺页异常。
2.缺页异常进行一系列判断,确定无非法操作后,内核发起请求调页过程。
3.调页过程先在交换缓存空间(swap cache)中寻找需要访问的内存页,如果没有则调用nopage函数把所缺的页从磁盘装入到主存中。
4.之后进程即可对这片主存进行读或者写的操作,如果写操作改变了其内容,一定时间后系统会自动回写脏页面到对应磁盘地址,也即完成了写入到文件的过程
物理ram内存结构
内存管理的最终目标 是合理的不浪费的使用内存
Linux 针对如何合理使用物理内存 软件上设计很多管理方案
1、体系结构
目前多处理器系统有两种体系结构:
1)非一致内存访问(Non-Unit Memory Access, NUMA) :指内存被划分成多个内存节点的多处理器系统。访问一个内存节点花费的时间取决于处理器和内存节点的距离。

2)对称多处理器(Symmetric Multi-Processor, SMP) :即一致内存访问(Uniform Memory Access, UMA),所有处理器访问内存花费的时间是相同。

2、内存模型
内存模型是从处理器角度看到的物理内存分布,内核管理不同内存模型的方式存差异。
内存管理子系统支持3种内存模型:
1)平坦内存(Flat Memory) :内存的物理地址空间是连续的,没有空洞。
2)不连续内存(Discontiguous Memory) :内存的物理地址空间存在空洞,这种模型可以高效地处理空洞。
3)稀疏内存(Space Memory) :内存的物理地址空间存在空洞,如果要支持内存热插拔,只能选择稀疏内存模型。
什么时候会有空洞呢 系统有很多个物理内存 两个内存的物理地址空间存在空洞
一块物理内存地址中间也可能会有空洞 如果物理地址是连续的使用不连续的内存模型会有额外开销
如果物理地址空间有空洞 平摊内存模型会给页分配结构体page 这样会浪费内存 不连续内存模型有优化处理不对空洞分配page
3、三级结构
内存管理子系统使用节点(node),区域(zone)、 页(page)三级结构描述物理内存。
可以把节点理解成就是一个物理硬盘
a、内存节点----->分为两种情况:
(1) NUMA体系的内存节点,根据处理器和内存的距离划分;
(2)在具有不连续内存的NUMA系统中,表示比区域的级别更高的内存区域,根据物
理地址是否连续划分,每块物理地址连续的内存是一个内存节点。

表达节点用pglist_data结构体
pglist_ data结构体内核源码: include/linux/mmzone.h
表达节点用pglist_data结构体
要注意一下里面的成员 page *node_mem_map
Node是内存管理的最顶层结构 在numa架构下面 cpu划分了很多node
每个node有自己的内存控制器 和对应的内存插槽 cpu访问自己的node时速非常的快
如果访问cpu关联的node节点就慢一点
typedef struct pglist_ data {
struct zone node_ Zones [MAX NR ZONES]; // 内存区域数组
struct zonelist node_ zonelists [MAX_ ZONELISTS]; //备用区域列表
intnr_zones;//该节点包含的内存区域数量
#ifdef CONFIG_ FLAT_ NODE_ MEM MAP //除了稀疏内存模型以外
struct page *node_ mem_ map; //页描述符数组
#ifdef CONFIG_ _PAGE_ EXTENSION
struct page_ ext *node_ page_ ext; //页的扩展属性
unsigned long node_ start_ pfn; // 该节点的起始物理页号
unsigned 1ong node_ present_ pages;
unsigned long node_ spanned pages; /* total size of physical page
range, including holes */
int node_ id;
wait_ queue_ head_ t kswapd_ wait;
node_ mem_ map此成员指向页描述符数组,每个物理页对应一个页描述符。
内存区域 zone
每个内存区都用一个zone来描述
把一个node(硬盘) 划分了很多个zone干不同的事
每个区域的定义如下
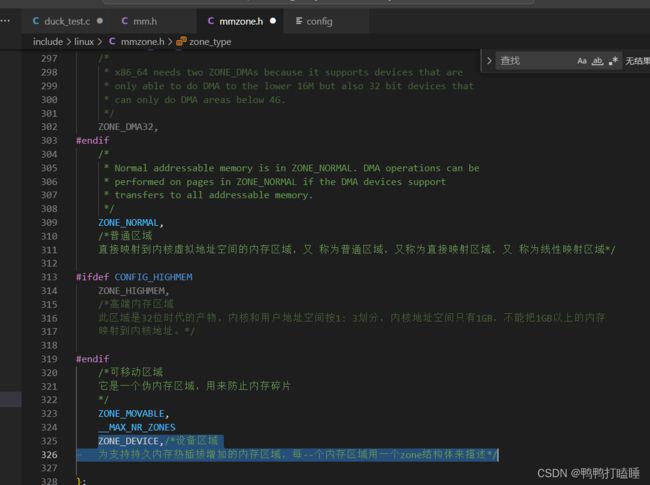
ZONE_NORMAL,
/*普通区域
直接映射到内核虛拟地址空间的内存区域,又 称为普通区域,又称为直接映射区域,又 称为线性映射区域*/
`ZONE_HIGHMEM,
/*高端内存区域
此区域是32位时代的产物,内核和用户地址空间按1: 3划分,内核地址空间只有1GB,不能把1GB以上的内存
映射到内核地址。*/
ZONE_MOVABLE,
/*可移动区域
它是一个伪内存区域,用来防止内存碎片
*/
ZONE_DEVICE,/*设备区域
为支持持久内存热插拔增加的内存区域,每--个内存区域用一个zone结构体来描述*/
同时使用struct zone 结构体来表示一个区
struct zone {
Read-mostly fields */
/* zone watermarks, access with★_ wmark_ pages (zone) macros */
unsigned long watermark [NR_ WMARK] ; //页分配器使用的水线
unsigned long nr_ reserved_ highatomic;
longlowmem_reserve[MAX_NR_ZONES];//页分配器使用,当前区域保留多少页不能借给高的区域类型
#ifdef CONFIG_ NUMA
int node ;
#endif
struct pglist_ data *zone_ pgdat; //指向内存节点的pglist_ data实例
struct per_ cpu_ pageset__ percpu *pageset; // 每处理页集合
#ifndef CONFIG_ SPARSEMEM
/*
Flags for a pageblock_ nr_ pages block. See pageblock- flags.h.
In SPARSEMEM,this map is stored in struct mem_ section
*/
unsigned long
*pageblock_ flags ;
#endif /* CONFIG_ SPARSEMEM */
/* zone_ start_ pfn == zone_ start_ paddr >> PAGE_ SHIFT */
unsigned long zone_ _start_ pfn; 1// 当前区域的起始物理页号
unsigned long managed_pages;//伙伴分配器管理的物理页的数量
unsigned long spanned_ pages; //当前区域跨越的总页数,包括空洞
unsigned long present_ pages; //当前区域存在的物理页的数量,不包括空洞
const char *name; //区域名称
/* free areas of different sizes */
struct free_ area
free_ area [MAX_ ORDER]; //不同长度的空间区域
}
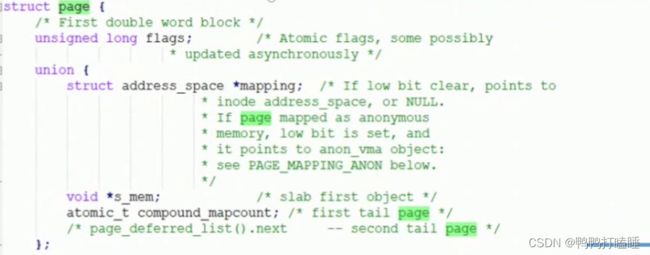
最后到物理页的结构体
每个物理页对应一个page结构体, 称为页描述符,
页是内存管理当中的最小单位,页面中的内存其物理地址是连续的,每个物理页由struct page描述。
为了节省内存,struct page是个联合体。
页有的时候也叫页帧 内存管理单元mmu 负责虚拟地址和物理地址转换的硬件 把物理page作为内存管理的基本单元 32位可以支持4k一页 64位可以支持8k一页
内存节点node 的pglist_ data实例的成员node_ mem_ map指向该内存节点包含的所有物理页的页描述符组成的数组。
Linux内核源码分析: include/linux/mm_ types.h