jsoncpp 1.8.4 中文值乱码问题指南
最近在使用c++解析 读写 json文件发现jsoncpp接口写出来的中文值都是 \u6e21\uxxxx等,字符;传入的std::string 已经是utf-8编码了;按理来说不应该乱码才对;
代码是在gitbub上下载编译的1.8.4;
using namespace std;
#include "json\include\json.h"
#include "json\include\writer.h"
#include
#include
#include
#include
#include
#include "ANSI_UTF8_UNICODE_Translate.h"
using namespace utf_ansi_unicode_translate;
int main()
{
int nRetCode = 0;
HMODULE hModule = ::GetModuleHandle(nullptr);
if (hModule != nullptr)
{
// 初始化 MFC 并在失败时显示错误
if (!AfxWinInit(hModule, nullptr, ::GetCommandLine(), 0))
{
// TODO: 更改错误代码以符合您的需要
wprintf(L"错误: MFC 初始化失败\n");
nRetCode = 1;
}
else
{
// TODO: 在此处为应用程序的行为编写代码。
Json::StreamWriterBuilder writer0;
Json::Value root;
Json::Value useproperty;
{
useproperty["title"] = "Tips";
useproperty["type"] = "string";
std::string str_ansi = "温馨提示";
useproperty["value_ansi"] = str_ansi;
std::string str_utf8 = AnsiToUtf8(str_ansi);
useproperty["value_utf8"] = str_utf8;
std::wstring str_uincode = UTF8ToUnicode(str_utf8);
str_utf8 = UnicodeToUTF8(str_uincode);
useproperty["value_unicode"] = str_utf8;
root["Userproperty"] = useproperty;
}
root["tmp"] = "/mnt/share/a3/0527";
root["type"] = "DLG";
Json::StreamWriterBuilder builder;
builder["commentStyle"] = "None";
builder["indentation"] = " "; // or whatever you like
builder["emitUTF8"] = true;
std::string str = Json::writeString(builder, root);
std::unique_ptr writer(builder.newStreamWriter());
writer->write(root, &std::cout);
std::cout << std::endl; // add lf and flush
std::ofstream ofs;
ofs.open("F:\\Code\\0525\\json_test\\bin\\my_json002.json", 0x02);
ASSERT(ofs.is_open());
writer->write(root, &ofs);
ofs.close();
int a;
std::cin >> a;
}
}
else
{
// TODO: 更改错误代码以符合您的需要
wprintf(L"错误: GetModuleHandle 失败\n");
nRetCode = 1;
}
return nRetCode;
}
#pragma once
#include
using namespace std;
namespace utf_ansi_unicode_translate
{
std::wstring StdstrToStdwstr(const std::string& strAnsi);
std::wstring AnsiToUnicode(const std::string& strAnsi);
std::string UnicodeToANSI(const std::wstring& strUnicode);
std::wstring UTF8ToUnicode(const std::string& str);
std::string UnicodeToUTF8(const std::wstring& strUnicode);
std::string AnsiToUtf8(const std::string& strAnsi);
std::string Utf8ToAnsi(const std::string& strUtf8);
//探测输入字符串是否是UTF8字符串
bool IsUtf8String(const char* pString);
};
#include "stdafx.h"
#include "ANSI_UTF8_UNICODE_Translate.h"
#include
#include
#include
#include
#include
#include
#include
#include "stdafx.h"
namespace utf_ansi_unicode_translate
{
std::wstring StdstrToStdwstr(const std::string& strAnsi)
{
if (IsUtf8String(strAnsi.c_str()))
return UTF8ToUnicode(strAnsi);
else
return AnsiToUnicode(strAnsi);
}
std::wstring AnsiToUnicode(const std::string& strAnsi)
{
//获取转换所需的接收缓冲区大小
int nUnicodeLen = ::MultiByteToWideChar(CP_ACP,
0,
strAnsi.c_str(),
-1,
NULL,
0);
//分配指定大小的内存
wchar_t* pUnicode = new wchar_t[nUnicodeLen + 1];
memset((void*)pUnicode, 0, (nUnicodeLen + 1) * sizeof(wchar_t));
//转换
::MultiByteToWideChar(CP_ACP,
0,
strAnsi.c_str(),
-1,
(LPWSTR)pUnicode,
nUnicodeLen);
std::wstring strUnicode;
strUnicode = (wchar_t*)pUnicode;
delete[]pUnicode;
return strUnicode;
}
std::string UnicodeToANSI(const std::wstring& strUnicode)
{
int nAnsiLen = WideCharToMultiByte(CP_ACP,
0,
strUnicode.c_str(),
-1,
NULL,
0,
NULL,
NULL);
char* pAnsi = new char[nAnsiLen + 1];
memset((void*)pAnsi, 0, (nAnsiLen + 1) * sizeof(char));
::WideCharToMultiByte(CP_ACP,
0,
strUnicode.c_str(),
-1,
pAnsi,
nAnsiLen,
NULL,
NULL);
std::string strAnsi;
strAnsi = pAnsi;
delete[]pAnsi;
return strAnsi;
}
std::wstring UTF8ToUnicode(const std::string& str)
{
int nUnicodeLen = ::MultiByteToWideChar(CP_UTF8,
0,
str.c_str(),
-1,
NULL,
0);
wchar_t* pUnicode;
pUnicode = new wchar_t[nUnicodeLen + 1];
memset((void*)pUnicode, 0, (nUnicodeLen + 1) * sizeof(wchar_t));
::MultiByteToWideChar(CP_UTF8,
0,
str.c_str(),
-1,
(LPWSTR)pUnicode,
nUnicodeLen);
std::wstring strUnicode;
strUnicode = (wchar_t*)pUnicode;
delete[]pUnicode;
return strUnicode;
}
std::string UnicodeToUTF8(const std::wstring& strUnicode)
{
int nUtf8Length = WideCharToMultiByte(CP_UTF8,
0,
strUnicode.c_str(),
-1,
NULL,
0,
NULL,
NULL);
char* pUtf8 = new char[nUtf8Length + 1];
memset((void*)pUtf8, 0, sizeof(char) * (nUtf8Length + 1));
::WideCharToMultiByte(CP_UTF8,
0,
strUnicode.c_str(),
-1,
pUtf8,
nUtf8Length,
NULL,
NULL);
std::string strUtf8;
strUtf8 = pUtf8;
delete[] pUtf8;
return strUtf8;
}
std::string AnsiToUtf8(const std::string& strAnsi)
{
//先判断一下是不是utf-8 字符;若是 则直接返回;
if (IsUtf8String(strAnsi.c_str()))
{
return strAnsi;
}
std::wstring strUnicode = AnsiToUnicode(strAnsi);
return UnicodeToUTF8(strUnicode);
}
std::string Utf8ToAnsi(const std::string& strUtf8)
{
//先判断一下是不是utf-8 字符;若不是 则直接返回;
if (!IsUtf8String(strUtf8.c_str()))
{
return strUtf8;
}
std::wstring strUnicode = UTF8ToUnicode(strUtf8);
return UnicodeToANSI(strUnicode);
}
/*
UTF-8 编码规则
1字节 0BBBBBBB
2字节 110BBBBB 10BBBBBB
3字节 1110BBBB 10BBBBBB 10BBBBBB
4字节 11110BBB 10BBBBBB 10BBBBBB 10BBBBBB
5字节 111110BB 10BBBBBB 10BBBBBB 10BBBBBB 10BBBBBB
6字节 1111110B 10BBBBBB 10BBBBBB 10BBBBBB 10BBBBBB 10BBBBBB
*/
bool IsUtf8String(const char* pString)
{
bool bRet = true;
//输入长度
int iStrLen = pString ? strlen(pString) : 0;
//临时变量
int m = 0, n = 0, iBLen = 0; BYTE b0 = 0;
for (m = 0; bRet && m < iStrLen; )
{
//根据第一个字节计算长度
b0 = (BYTE)pString[m];
iBLen = 0;
if ((b0 & 0x80) == 0x00) { iBLen = 1; } //1字节
else if ((b0 & 0xE0) == 0xC0) { iBLen = 2; } //2字节
else if ((b0 & 0xF0) == 0xE0) { iBLen = 3; } //3字节
else if ((b0 & 0xF8) == 0xF0) { iBLen = 4; } //4字节
else if ((b0 & 0xFC) == 0xF8) { iBLen = 5; } //5字节
else if ((b0 & 0xFE) == 0xFC) { iBLen = 6; } //6字节
else {} //非法
//非法长度或超出缓冲区范围
if (iBLen <= 0 || m + iBLen > iStrLen)
{
bRet = false;
break;
}
//判断后续字节需 10xxxxxx
for (n = 1; n < iBLen; n++)
{
if ((pString[m + n] & 0xC0) == 0x80)
continue;
bRet = false;
break;
}
//对齐到下一个长度
m += iBLen;
}
return bRet;
}
};
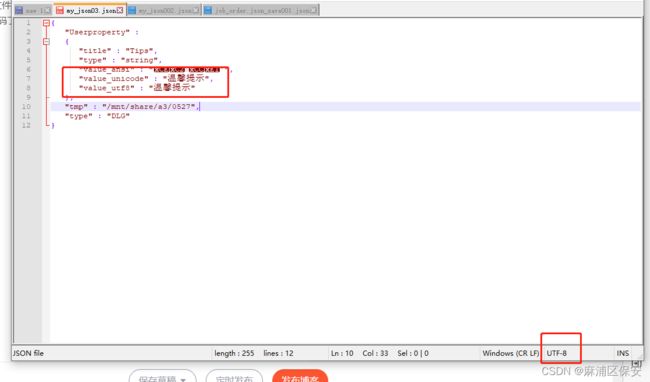
结果如图:发现中文是乱码的;
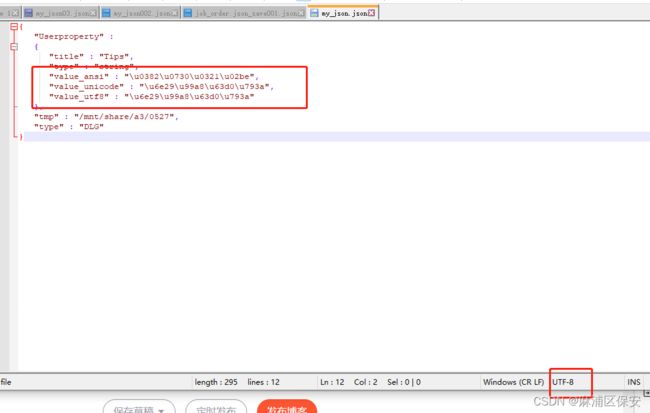
后面调试发现是 static JSONCPP_STRING valueToQuotedStringN(const char* value, unsigned length) {} 这里是转换将中文code转成了乱码;
static JSONCPP_STRING valueToQuotedStringN(const char* value, unsigned length) {
if (value == NULL)
return "";
if (!isAnyCharRequiredQuoting(value, length))
return JSONCPP_STRING("\"") + value + "\"";
// We have to walk value and escape any special characters.
// Appending to JSONCPP_STRING is not efficient, but this should be rare.
// (Note: forward slashes are *not* rare, but I am not escaping them.)
JSONCPP_STRING::size_type maxsize =
length * 2 + 3; // allescaped+quotes+NULL
JSONCPP_STRING result;
result.reserve(maxsize); // to avoid lots of mallocs
result += "\"";
char const* end = value + length;
for (const char* c = value; c != end; ++c) {
switch (*c) {
case '\"':
result += "\\\"";
break;
case '\\':
result += "\\\\";
break;
case '\b':
result += "\\b";
break;
case '\f':
result += "\\f";
break;
case '\n':
result += "\\n";
break;
case '\r':
result += "\\r";
break;
case '\t':
result += "\\t";
break;
// case '/':
// Even though \/ is considered a legal escape in JSON, a bare
// slash is also legal, so I see no reason to escape it.
// (I hope I am not misunderstanding something.)
// blep notes: actually escaping \/ may be useful in javascript to avoid = 0x20)
result += static_cast(cp);
else if (cp < 0x10000) { // codepoint is in Basic Multilingual Plane
result += "\\u";
result += toHex16Bit(cp);
}
else { // codepoint is not in Basic Multilingual Plane
// convert to surrogate pair first
cp -= 0x10000;
result += "\\u";
result += toHex16Bit((cp >> 10) + 0xD800);
result += "\\u";
result += toHex16Bit((cp & 0x3FF) + 0xDC00);
}
*/
//此处为新增代码
result += *c;
std::cout << result;
}
break;
}
}
result += "\"";
std::cout << result;
return result;
} 修改jsoncpp源码后;测试结果正确: