【Transformer】2、DETR: End-to-End Object Detection with Transformers

文章目录
-
- 一、背景和动机
- 二、方法
-
- 2.1 DETR 结构
- 2.2 目标检测集合的 loss
- 三、效果
- 四、全景分割
- 五、代码
论文链接:https://arxiv.org/abs/2005.12872
代码链接:https://github.com/facebookresearch/detr
一、背景和动机
目标检测任务是对图片中的每个感兴趣的目标预测位置和类别,现在流行的 CNN 方法的目标检测器大都使用的非直接手段进行预测,比如通过大量的 proposal、anchor、window center 来回归和分类出目标的位置和类别。这种方法会被后处理方法(如 NMS)影响效果,为了简化这种预测方法,作者提出了一种直接的 end-to-end 的方法,输入一张图片,输出直接是预测结果,不需要后处理。
二、方法
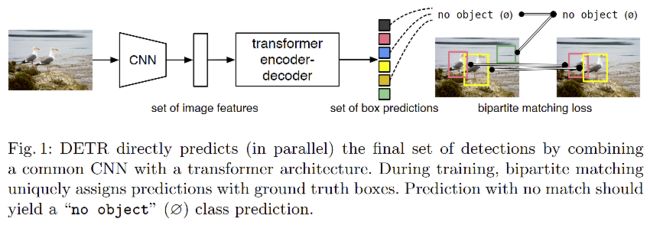
DETR 的结构如图 1 所示,DEtection TRsformer(DETR)可以直接预测所有目标,训练也是使用一个 loss 来进行端到端的训练。
DETR 的两大特点:
- 一个大的特点是简化了检测的 pipeline,不需要手工设计的模块来编码先验信息,如 anchor 和 non-maximal suppression
- 另外一个是不需要特定的层,能够方便的重用到其他结构中
DETR 的训练阶段:(需要二分图匹配的 loss)
- 首先,使用 CNN 抽取图像特征
- 其次,将抽取得到的图像特征输入 Transformer 的 encoder-decoder 框架
- 最后,通过二分图匹配损失将预测框和真实框匹配起来,然后使用 FFN 计算分类损失和回归损失,这里的匹配是对真实框和预测框进行一对一的匹配,没有匹配的预测框为 ϕ \phi ϕ,即没有类别
DETR 的推理阶段:(不需要二分图匹配的 loss)
- 首先,使用 CNN 抽取图像特征
- 其次,将图像特征输入 encoder-decoder,生成一系列预测框
- 最后,保留置信度高于阈值的框作为最终输出
DETR 的预测框和真实框是如何匹配的:
- 设定了 object query=100,也就是每张图都输入 100 个预测结果
- 假设一张图中只有 2 个 gt,在训练过程中就是对这输出的 100 个 query 和这个 2 个 gt 计算 match loss,从而决定这 100 个 object query 中哪两个框是一对一对应到这个两个 gt 上的
- 当 gt 和 object query 进行匹配了之后,才会像普通的目标检测一样来计算分类和回归的 loss
- 其他 98 个 没有匹配到 gt 的 object query 框就被标记为 ϕ \phi ϕ。
二分图匹配:
- 对预测框和 gt 这两个集合进行最佳匹配,使得 cost 代价最小
- 举例:假设有 N 个工人和 N 个任务,每个工人各有长处,所以他们干活需要的回报就不同,每个工人和每个任务的花费就形成了一个 N × N N\times N N×N 的矩阵,这个矩阵就称为 cost matric,最优二分图匹配就是能够找到唯一解,让每个人都得到其最擅长的工作,且花费最低
- 二分图匹配如何解决:匈牙利算法用的较多
DETR 中的二分图匹配:
- 100 个 object query(预测框)
- 100 个 gt(不够的话用 ϕ \phi ϕ 来填充)
- 最终的花费就是每个预测框和每个 gt 匹配损失,把每个预测框和每个一一 gt 进行匹配并计算损失,把 cost matric 填充完整,然后送入
scipy库中的linear_sum_assigment函数中,得到最后的最优解。这里的匹配方式约束更强,一定要得到这个一对一的匹配关系,也就是每个预测框只会与一个 gt 框是对应的,这样后面才不需要去做那个后处理 nms
二分匹配后如何计算损失:
- 二分匹配后,每个预测框都和 gt 框有了固定的匹配,然后就可以计算分类和回归损失了

2.1 DETR 结构
DETR 的结构如图 2,包括三个部分:
- CNN backbone,提取特征
- encoder-decoder transformer
- simple feed forward network,进行最终的检测预测

Backbone:
-
输入:原始图片: x i m g ∈ R 3 × H 0 × W 0 x_{img}\in R^{3\times H_0 \times W_0} ximg∈R3×H0×W0
-
输出:低分辨率的特征图: f ∈ R 2048 × H × W f \in R^{2048\times H \times W} f∈R2048×H×W ( H = H 0 / 32 , W = W 0 / 32 ) (H=H_0/32 , W=W_0/32) (H=H0/32,W=W0/32)
Transformer encoder:
- 降维:使用 1x1 卷积,将 2048 降到 d d d 维
- 编码为序列的输入:Transformer 期望的输入为一维,所以要将二维特征转换成一维特征 d × H W d\times HW d×HW
- 每个 encoder 都是由一个多头自注意力结构和一个 feed forward network 组成,特征输入 attention 结构之前,都会加上位置编码。
Transformer decoder:
- decoder 的输入是 object query,可以理解为不同 object 的 positional embedding,object query 通过decoder 转换成一个 output embedding
- decoder 是为了把 N 个大小为 d 的 embedding 特征进行 transforming
- decoder 是由多头自注意力结构和多头 encoder-decoder 结构组成
- 本文的decoder特点:同时并行的在每一个 decoder 层对 N 个目标进行解码
- 在每个 attention 层输入的时候,会给输入加上位置编码,最终得到输出
- 然后使用 FFN 对这些特征进行映射,映射为位置和类别,得到 N 个预测
- decoder 的输入在本文中是大小为 [100, 2, 256] ,初始化为全 0 的向量,即 decoder 学习的就是输入的这个向量
- decoder 的输出会分别送入分类头得到 [6, 2, 100,92] (coco) 和bbox头得到 [6, 2, 100, 4],然后取第一个 [2, 100,92] 和 [2, 100, 4] 作为预测的结果
Prediction feed-forward networks (FFNs)
- FFN 由 RELU + 隐层 + 线性映射层组成
- 预测:框的中心和宽高
- 线性层预测类别
- 由于预测的是一个固定长度为 N 的输出,所以新加了一个类别 ϕ \phi ϕ,表示没有目标,可以看做其他检测网络中的 “背景” 类
Auxiliary decoding losses
- 经过实验,作者发现在训练 decoder 时,使用额外的 loss 很有效果,能够帮助模型输出每个类别的目标数量,所以,在每个 decoder 层,作者都会即将 FFN 和 Hungarian loss 加起来,所有 FFN 都是共享参数的。
2.2 目标检测集合的 loss
DETR 能够一次性推断出 N 个预测结果,其中 N 是远远大于图像中目标个数的值。
训练中的一个难点在于根据真值给每个预测目标(类别、位置、尺寸)打分,所以本文的 loss 能够得到一个在预测和真值之间的最优双向匹配,然后优化 object-specific loss。
- y y y:真值,假设维度也为 N,不够的用空值来补全
- y ^ = { y i } ^ i = 1 N \hat{y} = \{\hat{y_i\}}_{i=1}^N y^={yi}^i=1N:预测的结果,N 远远大于目标个数
第一步:二分匹配求最低 cost
为了获得最优的二分匹配,作者在 N 个元素 σ \sigma σ 中寻找出了一个集合,这个集合有最低的 cost:

-
L m a t c h L_{match} Lmatch 是真值 y i y_i yi 和第 σ ( i ) \sigma(i) σ(i) 个预测结果的 matching cost,是用匈牙利算法计算的。
-
这个 matching cost 同时考虑了类别、框的相似度
-
第 i 个真值可以看成 y i = ( c i , b i ) y_i=(c_i, b_i) yi=(ci,bi),其中 c i c_i ci 是类别 label, b i ∈ [ 0 , 1 ] 4 b_i\in[0, 1]^4 bi∈[0,1]4 是框的中心和宽高
-
对于第 σ ( i ) \sigma(i) σ(i) 个预测,作者定义类别 c i c_i ci 的预测为 p ^ σ ( i ) ( c i ) \hat{p}_{\sigma(i)}(c_i) p^σ(i)(ci),框的预测为 b ^ σ ( i ) \hat{b}_{\sigma(i)} b^σ(i)
-
L m a t c h ( y i , y ^ σ ( i ) ) L_{match}(y_i, \hat{y}_{\sigma(i)}) Lmatch(yi,y^σ(i)) 为
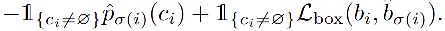
-
这种过程类似于之前的 proposal match 或 anchor match,最主要的不同是作者需要进行一对一的匹配,没有过多剩余的匹配。
第二步:计算预测框和真实框一对一匹配后的 loss

- σ ^ \hat{\sigma} σ^ 是第一步中计算得到的最优分配
- 在实际操作中,为了类别平衡,作者把 c i = ϕ c_i=\phi ci=ϕ 的预测结果的 log-probability 的权重下降 10 倍
- 一个目标和 ϕ \phi ϕ 的 matching cost 是不基于预测的,而是一个常数
Bounding box loss:
matching cost 和 loss 的第二项都是 L b o x ( . ) L_{box}(.) Lbox(.),不同于其他检测器,本文作者直接对 box 进行预测,但这种简化的实现方法引入了一个相对缩放损失的问题,L1 损失对不同大小的框的相同偏移的惩罚是相同的,所以作者将 L1 loss 和 generalized IoU loss 进行了组合,所以 box loss L b o x ( b i , b ^ σ ( i ) ) L_{box}(b_i,\hat{b}_{\sigma(i)}) Lbox(bi,b^σ(i)) 为:
![]()
三、效果

1、Encoder layer 个数的影响:
表 2 展示了不同 encoder 个数对效果的影响,使用 encoder AP 能提升 3.9 个点,作者猜想是因为 encoder 能捕捉全局场景,所以有利于对不同目标的解耦。

在图 3 中,展示了最后一层 encoder 的 attention map,可以看出特征图注意到了图中的很多位置,看起来能够对不同实例进行区分,能够简化decoder的目标提取和定位。

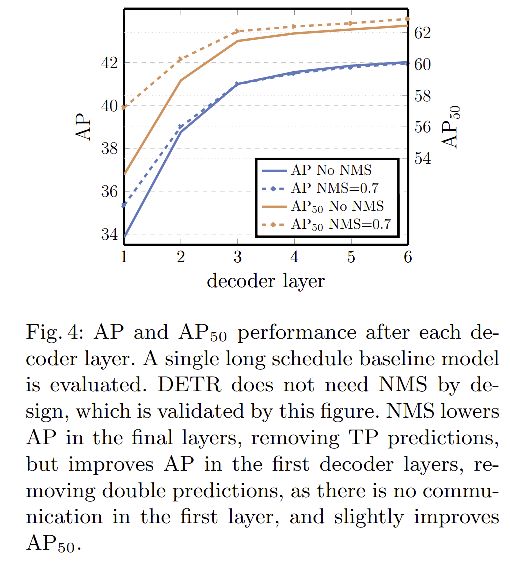
2、Decoder layer 个数的影响:
图 4 展示了随着 decoder layer 数量增加,AP 和 AP50 的变化情况,每增加一层,效果就有一定上升,总共带来了 8.2/9.5 的增加。
NMS 的影响:
- 使用了一个decoder时,当引入 NMS 后,效果得到了明显的增加,这可以解释为单个 decoding layer 没有计算输入元素的相关关系的能力,即会对一个目标产生很多预测。
- 当增加了 decoder 模块(2个和多个)后再使用 NMS 时,就没有很明显的效果提升了,即随着深度的增加而逐渐减小。这是因为 self-attention 机制能够抑制模型产生重复的预测。
使用相同的方法进行可视化,可以看出 decoder attention 比较注意位置信息,会更关注目标的末端,如头和腿,作者猜测是因为encoder已经对不同的目标进行了全局上的区分,decoder 只需要关注变化剧烈的纹理区域来提取出类别的边界。

3、Importance of FFN
- FFN 可以看成一个 1x1 的卷积层,使得 encoder 类似于一个基于 attention 的卷积网络
- 作者将该结构完全移除,只留下 attention,把网络参数从 41.3 M 降低到了 28.7 M,transformer 仅有 10.8 M 的参数,但性能降低了 2.3 AP,所以 FFN 是很重要的
4、Importance of positional encoding
- 本文的位置编码有两种,一个是空间位置编码,一个是输出位置编码,输出位置编码是不能移除的,所以作者对空间位置编码做了实验
- 实验发现位置编码对结果还是很有作用的

5、Decoder output slot analysis
图 7 可视化了 COCO2017 验证集的 20 种 bbox 预测输出, DETR 给每个查询输入学习了不同的特殊效果。
可以看出,每个 slot 都会聚焦于不同的区域和目标大小,所有的 slot 都有预测 image-wide box 的模式(对齐的红点),作者假设这与 COCO 的分布有关。

四、全景分割



五、代码
这是论文中的一段简化的 inference 代码
import torch
from torch import nn
from torchvision.models import resnet50
class DETR(nn.Module):
def __init__(self, num_classes, hidden_dim, nheads,
num_encoder_layers, num_decoder_layers):
super().__init__()
# We take only convolutional layers from ResNet-50 model
import pdb; pdb.set_trace()
self.backbone = nn.Sequential(*list(resnet50(pretrained=True).children())[:-2])
self.conv = nn.Conv2d(2048, hidden_dim, 1)
self.transformer = nn.Transformer(hidden_dim, nheads, num_encoder_layers, num_decoder_layers)
self.linear_class = nn.Linear(hidden_dim, num_classes + 1)
self.linear_bbox = nn.Linear(hidden_dim, 4)
self.query_pos = nn.Parameter(torch.rand(100, hidden_dim))
self.row_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))
self.col_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))
def forward(self, inputs):
x = self.backbone(inputs) # inputs=[1, 3, 800, 1200], x=[1, 1024, 25, 38]
h = self.conv(x) # h=[1, 256, 25, 38]
H, W = h.shape[-2:] # H=25, W=38
pos = torch.cat([
self.col_embed[:W].unsqueeze(0).repeat(H, 1, 1),
self.row_embed[:H].unsqueeze(1).repeat(1, W, 1),], dim=-1).flatten(0, 1).unsqueeze(1) # pos=[950, 1, 256]
h = self.transformer(pos + h.flatten(2).permute(2, 0, 1), self.query_pos.unsqueeze(1)) # h=[100, 1, 256]
return self.linear_class(h), self.linear_bbox(h).sigmoid() # [100, 1, 92], [100, 1, 4]
detr = DETR(num_classes=91, hidden_dim=256, nheads=8, num_encoder_layers=6, num_decoder_layers=6)
detr.eval()
inputs = torch.randn(1, 3, 800, 1200)
logits, bboxes = detr(inputs)
训练:下载代码detr,然后把coco图像放到dataset下即可训练
python main.py
DETR 模型结构:detr.py
-
输入:原始图片
-
build backbone:
def build_backbone(args):
position_embedding = build_position_encoding(args) # PositionEmbeddingSine()
train_backbone = args.lr_backbone > 0 # True
return_interm_layers = args.masks # False
backbone = Backbone(args.backbone, train_backbone, return_interm_layers, args.dilation)
model = Joiner(backbone, position_embedding) #(0) backbone() (1) PositionEmbeddingSine()
model.num_channels = backbone.num_channels # 2048
return model
- build transformer:
def build_transformer(args):
return Transformer(
d_model=args.hidden_dim,
dropout=args.dropout,
nhead=args.nheads,
dim_feedforward=args.dim_feedforward,
num_encoder_layers=args.enc_layers,
num_decoder_layers=args.dec_layers,
normalize_before=args.pre_norm,
return_intermediate_dec=True,
)
class Transformer(nn.Module):
def __init__(self, d_model=512, nhead=8, num_encoder_layers=6,
num_decoder_layers=6, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False,
return_intermediate_dec=False):
super().__init__()
encoder_layer = TransformerEncoderLayer(d_model, nhead, dim_feedforward,
dropout, activation, normalize_before)
encoder_norm = nn.LayerNorm(d_model) if normalize_before else None
self.encoder = TransformerEncoder(encoder_layer, num_encoder_layers, encoder_norm)
decoder_layer = TransformerDecoderLayer(d_model, nhead, dim_feedforward,
dropout, activation, normalize_before)
decoder_norm = nn.LayerNorm(d_model)
self.decoder = TransformerDecoder(decoder_layer, num_decoder_layers, decoder_norm,
return_intermediate=return_intermediate_dec)
self._reset_parameters()
self.d_model = d_model
self.nhead = nhead
def _reset_parameters(self):
for p in self.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
def forward(self, src, mask, query_embed, pos_embed):
# flatten NxCxHxW to HWxNxC
bs, c, h, w = src.shape
src = src.flatten(2).permute(2, 0, 1)
pos_embed = pos_embed.flatten(2).permute(2, 0, 1)
query_embed = query_embed.unsqueeze(1).repeat(1, bs, 1)
mask = mask.flatten(1)
tgt = torch.zeros_like(query_embed)
memory = self.encoder(src, src_key_padding_mask=mask, pos=pos_embed)
hs = self.decoder(tgt, memory, memory_key_padding_mask=mask,
pos=pos_embed, query_pos=query_embed)
return hs.transpose(1, 2), memory.permute(1, 2, 0).view(bs, c, h, w)
其中各个模块:
encoder_layer:
TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(out_proj): _LinearWithBias(in_features=256, out_features=256, bias=True)
)
(linear1): Linear(in_features=256, out_features=2048, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=2048, out_features=256, bias=True)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
)
self.encoder
TransformerEncoder(
(layers): ModuleList(
(0): TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(out_proj): _LinearWithBias(in_features=256, out_features=256, bias=True)
)
(linear1): Linear(in_features=256, out_features=2048, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=2048, out_features=256, bias=True)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
)
(1): TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(out_proj): _LinearWithBias(in_features=256, out_features=256, bias=True)
)
(linear1): Linear(in_features=256, out_features=2048, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=2048, out_features=256, bias=True)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
)
(2): TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(out_proj): _LinearWithBias(in_features=256, out_features=256, bias=True)
)
(linear1): Linear(in_features=256, out_features=2048, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=2048, out_features=256, bias=True)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
)
(3): TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(out_proj): _LinearWithBias(in_features=256, out_features=256, bias=True)
)
(linear1): Linear(in_features=256, out_features=2048, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=2048, out_features=256, bias=True)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
)
(4): TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(out_proj): _LinearWithBias(in_features=256, out_features=256, bias=True)
)
(linear1): Linear(in_features=256, out_features=2048, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=2048, out_features=256, bias=True)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
)
(5): TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(out_proj): _LinearWithBias(in_features=256, out_features=256, bias=True)
)
(linear1): Linear(in_features=256, out_features=2048, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=2048, out_features=256, bias=True)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
)
)
)
decoder layer:
TransformerDecoderLayer(
(self_attn): MultiheadAttention(
(out_proj): _LinearWithBias(in_features=256, out_features=256, bias=True)
)
(multihead_attn): MultiheadAttention(
(out_proj): _LinearWithBias(in_features=256, out_features=256, bias=True)
)
(linear1): Linear(in_features=256, out_features=2048, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=2048, out_features=256, bias=True)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm3): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
(dropout3): Dropout(p=0.1, inplace=False)
)
self.decoder
TransformerDecoder(
(layers): ModuleList(
(0): TransformerDecoderLayer(
(self_attn): MultiheadAttention(
(out_proj): _LinearWithBias(in_features=256, out_features=256, bias=True)
)
(multihead_attn): MultiheadAttention(
(out_proj): _LinearWithBias(in_features=256, out_features=256, bias=True)
)
(linear1): Linear(in_features=256, out_features=2048, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=2048, out_features=256, bias=True)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm3): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
(dropout3): Dropout(p=0.1, inplace=False)
)
(1): TransformerDecoderLayer(
(self_attn): MultiheadAttention(
(out_proj): _LinearWithBias(in_features=256, out_features=256, bias=True)
)
(multihead_attn): MultiheadAttention(
(out_proj): _LinearWithBias(in_features=256, out_features=256, bias=True)
)
(linear1): Linear(in_features=256, out_features=2048, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=2048, out_features=256, bias=True)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm3): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
(dropout3): Dropout(p=0.1, inplace=False)
)
(2): TransformerDecoderLayer(
(self_attn): MultiheadAttention(
(out_proj): _LinearWithBias(in_features=256, out_features=256, bias=True)
)
(multihead_attn): MultiheadAttention(
(out_proj): _LinearWithBias(in_features=256, out_features=256, bias=True)
)
(linear1): Linear(in_features=256, out_features=2048, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=2048, out_features=256, bias=True)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm3): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
(dropout3): Dropout(p=0.1, inplace=False)
)
(3): TransformerDecoderLayer(
(self_attn): MultiheadAttention(
(out_proj): _LinearWithBias(in_features=256, out_features=256, bias=True)
)
(multihead_attn): MultiheadAttention(
(out_proj): _LinearWithBias(in_features=256, out_features=256, bias=True)
)
(linear1): Linear(in_features=256, out_features=2048, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=2048, out_features=256, bias=True)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm3): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
(dropout3): Dropout(p=0.1, inplace=False)
)
(4): TransformerDecoderLayer(
(self_attn): MultiheadAttention(
(out_proj): _LinearWithBias(in_features=256, out_features=256, bias=True)
)
(multihead_attn): MultiheadAttention(
(out_proj): _LinearWithBias(in_features=256, out_features=256, bias=True)
)
(linear1): Linear(in_features=256, out_features=2048, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=2048, out_features=256, bias=True)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm3): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
(dropout3): Dropout(p=0.1, inplace=False)
)
(5): TransformerDecoderLayer(
(self_attn): MultiheadAttention(
(out_proj): _LinearWithBias(in_features=256, out_features=256, bias=True)
)
(multihead_attn): MultiheadAttention(
(out_proj): _LinearWithBias(in_features=256, out_features=256, bias=True)
)
(linear1): Linear(in_features=256, out_features=2048, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=2048, out_features=256, bias=True)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm3): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
(dropout3): Dropout(p=0.1, inplace=False)
)
)
(norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
)
训练:engine.py
def train_one_epoch(model: torch.nn.Module, criterion: torch.nn.Module,
data_loader: Iterable, optimizer: torch.optim.Optimizer,
device: torch.device, epoch: int, max_norm: float = 0):
model.train()
criterion.train()
metric_logger = utils.MetricLogger(delimiter=" ")
metric_logger.add_meter('lr', utils.SmoothedValue(window_size=1, fmt='{value:.6f}'))
metric_logger.add_meter('class_error', utils.SmoothedValue(window_size=1, fmt='{value:.2f}'))
header = 'Epoch: [{}]'.format(epoch)
print_freq = 10
for samples, targets in metric_logger.log_every(data_loader, print_freq, header):
samples = samples.to(device) # samples.tensors.shape=[2, 3, 736, 920]
targets = [{k: v.to(device) for k, v in t.items()} for t in targets]
outputs = model(samples) # outputs.keys(): ['pred_logits', 'pred_boxes', 'aux_outputs']
# outputs['pred_logits'].shape=[2, 100, 92], outputs['pred_boxes'].shape=[2, 100, 4]
# outputs['aux_outputs'][0]['pred_logits'].shape = [2, 100, 92]
# outputs['aux_outputs'][0]['pred_boxes'].shape = [2, 100, 4]
loss_dict = criterion(outputs, targets)
weight_dict = criterion.weight_dict
losses = sum(loss_dict[k] * weight_dict[k] for k in loss_dict.keys() if k in weight_dict)
# reduce losses over all GPUs for logging purposes
loss_dict_reduced = utils.reduce_dict(loss_dict)
loss_dict_reduced_unscaled = {f'{k}_unscaled': v
for k, v in loss_dict_reduced.items()}
loss_dict_reduced_scaled = {k: v * weight_dict[k]
for k, v in loss_dict_reduced.items() if k in weight_dict}
losses_reduced_scaled = sum(loss_dict_reduced_scaled.values())
loss_value = losses_reduced_scaled.item()
if not math.isfinite(loss_value):
print("Loss is {}, stopping training".format(loss_value))
print(loss_dict_reduced)
sys.exit(1)
optimizer.zero_grad()
losses.backward()
if max_norm > 0:
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm)
optimizer.step()
metric_logger.update(loss=loss_value, **loss_dict_reduced_scaled, **loss_dict_reduced_unscaled)
metric_logger.update(class_error=loss_dict_reduced['class_error'])
metric_logger.update(lr=optimizer.param_groups[0]["lr"])
# gather the stats from all processes
metric_logger.synchronize_between_processes()
print("Averaged stats:", metric_logger)
return {k: meter.global_avg for k, meter in metric_logger.meters.items()}
上述代码中的 target 长下面这个样子:len(target)=2
({'boxes': tensor([[0.4567, 0.4356, 0.3446, 0.2930],
[0.8345, 0.4459, 0.3310, 0.3111],
[0.4484, 0.0582, 0.3947, 0.1164],
[0.8436, 0.0502, 0.3128, 0.1005],
[0.7735, 0.5084, 0.0982, 0.0816],
[0.1184, 0.4742, 0.2369, 0.2107],
[0.4505, 0.4412, 0.3054, 0.2844],
[0.8727, 0.4563, 0.1025, 0.0892],
[0.1160, 0.0405, 0.2319, 0.0810],
[0.8345, 0.4266, 0.3310, 0.2843]]),
'labels': tensor([2, 2, 2, 2, 2, 2, 2, 2, 2, 2]),
'image_id': tensor([382006]),
'area': tensor([45937.5547, 46857.6406, 20902.2129, 14303.7432, 3646.2932, 22717.0332, 39523.7812, 4161.9199, 8552.1719, 42826.0391]),
'iscrowd': tensor([0, 0, 0, 0, 0, 0, 0, 0, 0, 0]),
'orig_size': tensor([429, 640]),
'size': tensor([711, 640])},
{'boxes': tensor([[0.7152, 0.3759, 0.0934, 0.0804],
[0.8129, 0.3777, 0.0576, 0.0562],
[0.7702, 0.3866, 0.0350, 0.0511],
[0.7828, 0.6463, 0.0743, 0.2580],
[0.8836, 0.5753, 0.1511, 0.2977],
[0.9162, 0.6202, 0.0880, 0.3273],
[0.8424, 0.3788, 0.0254, 0.0398],
[0.9716, 0.3712, 0.0569, 0.0707],
[0.0615, 0.4210, 0.0242, 0.0645],
[0.8655, 0.3775, 0.0398, 0.0368],
[0.8884, 0.3701, 0.0349, 0.0329],
[0.9365, 0.3673, 0.0144, 0.0221],
[0.5147, 0.1537, 0.0220, 0.0541],
[0.9175, 0.1185, 0.0294, 0.0438],
[0.0675, 0.0934, 0.0223, 0.0596],
[0.9125, 0.3683, 0.0185, 0.0347],
[0.9905, 0.3934, 0.0191, 0.0373],
[0.5370, 0.1577, 0.0211, 0.0553]]),
'labels': tensor([2, 2, 2, 2, 1, 1, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2]),
'image_id': tensor([565286]),
'area': tensor([ 3843.2710, 1264.0637, 753.2280, 8374.9131, 11725.9863, 11407.3760, 373.8589, 1965.6881, 649.5052, 625.6856, 483.2297, 117.1264, 733.8372, 727.9525, 758.3719, 307.3998, 365.8919, 712.7703]),
'iscrowd': tensor([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]),
'orig_size': tensor([512, 640]),
'size': tensor([736, 920])})