基于大数据框架的协同过滤算法餐饮推荐系统【Update2023-6-25】
开始之前
设计思路
首先这位作者的推荐系统给了我很大的构思启发。
Github地址:https://github.com/share23/Food_Recommender
他的系统采用实时大数据技术组件,具体有Spark Streaming,HDFS分布式存储,Hbase存储计算,消息队列采用Kafka,Flume,其中的餐饮数据是用python生成,加上linux的contab模拟流式数据。推荐模块使用ALS算法加评分。
他的系统架构和技术组件选用给了我很大帮助,包括系统业务逻辑代码,让我顺利完成了我的毕业设计。
我的推荐系统设计背景是普通本科的计算机专业毕设,所以我在原作者的基础上进行了较大的调整。具体使用三台CentOS虚拟机,砍掉了实时处理组件,使用数据仓库(Data Warehouse)的设计理念,加入了基于用户、物品和ALS评分的协同过滤推荐算法,解决冷启动问题。
我的餐饮推荐系统是基于PySpark技术,综合运用Django框架、MySQL数据库等技术设计实现。具体来说,在数据采集阶段,使用Python爬虫获取公开数据;预处理阶段,通过MapReduce进行数据清洗,HDFS负责存储ods层;核心推荐功能采用Spark框架实现协同过滤算法。
系统启动使用流程
在答辩现场应该演示什么?
Step1:启动虚拟机集群,启动大数据相关组件;
Step2:在PyCharm的命令行终端启动Django服务器;
Step3:进入Web端,可以对菜品进行浏览,评分;
Step4:选择不同方式的推荐,查看推荐结果,重点突出计算推荐的过程。
一、数据采集清洗
该阶段需要完成的工作是:
1.构建完整的符合协同过滤推荐算法需求的餐饮数据集,其中包含餐饮数据以及用户历史行为数据;
2.完成采集数据的清洗工作,构建ODS层上传至HDFS中;
3.将HDFS中的数据转移至本地DWD层,为CF推荐做预处理。
1.1 爬虫采集
这里我采用了最简单的方式实现数据的采集收集。这个python脚本很可能会随着网页的更新而失去作用,仅供参考。
需要的主要字段有:菜品ID,菜品名字,菜品口味,菜品图片的URL。
注意,我在数据库中只体现了这些字段,其实在ODS层中完全可以添加更多字段,但是与本次毕业设计的既定目标已经偏离,不宜加过多需求。所以我遵循的原则是一切从简,尽量用最少的数据完成协同过滤算法的流程,并且做好网页的可视化。
我为什么没有用户的历史行为数据?
因为我不需要抓取,我只需要模拟出少部分的用户评分数据即可完成基于用户历史行为的协同过滤推荐。
值得注意的是,如果需要后期完善的话,餐饮相关的数据集也可以从网上进行下载,包含更丰富的字段,可以满足更多的机器学习需求。
import requests
from bs4 import BeautifulSoup
head = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36',
}
# 目标保存文件
file = open('./cai.txt', 'w+')
# 获取菜品分类页面
recipeTypeResponse = requests.get(url="https://home.meishichina.com/recipe-type.html", headers=head)
recipeTypeResponse.encoding = recipeTypeResponse.apparent_encoding
soup = BeautifulSoup(recipeTypeResponse.text, 'html.parser')
# 食谱大类列表
divNodeList = soup.find_all('div', class_="category_sub clear")
for divNode in divNodeList:
# # 这里只获取第一个大类
# divNode = soup.find_all('div', class_="category_sub clear")[0]
file.writelines(divNode.find('h3').text+": \n")
# 获取每个大类里的所有小类
aNodeList = divNode.find_all('a')
for aNode in aNodeList:
file.writelines("【" + aNode.text + "】\n")
recipeTypeHref = aNode.get('href')
caiResponse = requests.get(url=recipeTypeHref, headers=head)
caiSoup = BeautifulSoup(caiResponse.text, 'html.parser')
caiList = caiSoup.find('div', class_="ui_newlist_1 get_num").select('a[title]:not(:has(*))')
for cai in caiList:
# 获取菜的详情信息
caiName = cai.get('title')
caiHref = cai.get('href')
caiDetailResponse = requests.get(caiHref, headers=head)
caiDetailResponse.encoding =caiDetailResponse.apparent_encoding
caiDetailSoup = BeautifulSoup(caiDetailResponse.text, 'html.parser')
# 图片链接
caiImg = caiDetailSoup.find('div', class_="recipe_De_imgBox")
caiImgSrc = caiImg.find('img').get('src')
caikouweiDiv = caiDetailSoup.find('div', class_="recipeCategory_sub_R mt30 clear")
caikouweiLiList = caikouweiDiv.find_all('li')
caikouwei = "未知"
caigongyi = "未知"
for li in caikouweiLiList:
caikouweiTag = li.find('span', class_="category_s2")
if caikouweiTag.text == '口味':
caikouwei = li.select('a[title]')[0].text
if caikouweiTag.text == '工艺':
caigongyi = li.select('a[title]')[0].text
# # 口味
# caikouwei = caikouweiList[6].select('a[title]')[0].text
# # 工艺
# caigongyi = caikouweiList[7].select('a[title]')[0].text
file.writelines(caiName + "\t" + caikouwei + "\t" + caigongyi + "\tImg url:" + caiImgSrc + "\n")
print(caiName + " ==> 完成!")
print("【" + aNode.text + "】完成!")
1.2 mapreduce阶段清洗数据
这里使用到了Hadoop中的MapReduce计算框架和HDFS分布式存储框架。首先将爬虫采集到的数据读入MapReduce,进行简单的数据清洗操作,然后将文件输出到HDFS中存放。MR中的清洗只是为了增加毕业设计中需求技术的一个操作,可以不做,因为数据就是我自己生成的,我自己爬取的,我完全可以按照我想要的格式去拿数据,造数据,但是为了模拟真实的生产环境(论文有的写),虽然只抓取了几百条数据,但是也添加了数据清洗阶段。
package foodclean;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
public class FoodClean {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 1. 初始化配置
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://hadoop10:8020");
//2. 创建job
Job job = Job.getInstance(conf);
job.setJarByClass(FoodClean.class);
//3. 设置输入格式化工具和输出格式化
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
//4. 设置输入路径和输出路径
TextInputFormat.addInputPath(job, new Path("/food_clean/cai.txt"));
TextOutputFormat.setOutputPath(job, new Path("/food_clean/out"));
//5. 设置mapper和reducer
job.setMapperClass(StartCleanMapper.class);
//job.setReducerClass(WordCount.WordCountReducer.class);
// 6. 设置mapper的kv类型和reducer的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
// 7. 启动job
boolean b = job.waitForCompletion(true);
System.out.println(b);
}
static class StartCleanMapper extends Mapper<LongWritable, Text, Text, NullWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
if (value.toString().contains("Img url:")) { //筛选出包含图
String[] parts = value.toString().split("\t"); // 使用制表符作为分隔符
String httpUrl = parts[3].substring(8); //截取多余字
// 1 拔丝苹果 酸甜 拔丝 Img url:https://i3.
// 2 xxxx xxx xx xxx
// ...
String result = key.toString() + "\t" + parts[0] + "\t" + parts[1] + "\t" + parts[2] + "\t" + httpUrl;
context.write(new Text(result), NullWritable.get());
}
}
}
}
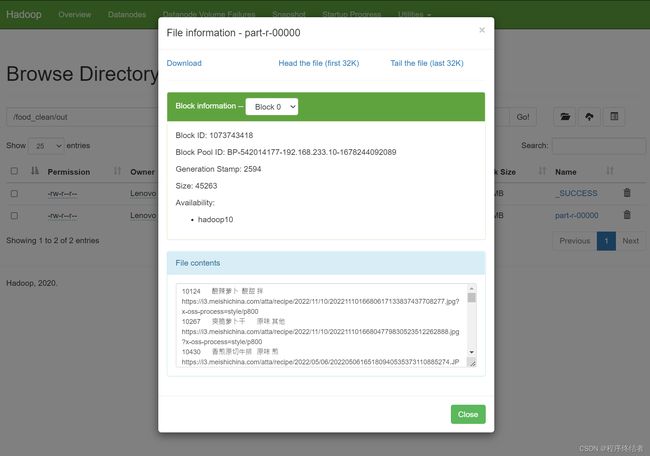
数据清洗成功,并且存储在HDFS中。
1.3 在Django中进行数据库转移
通过在PyCharm中编写Django程序,创建MySQL数据库。Django中的特性功能,数据库管理。首先要在Django中配置好数据库连接、用户、密码等。而且localhost主机要有Navicate数据库管理工具,方便查看数据。
1.3.1 数据库转移设计:
models.py
from django.db import models
class Foodlist(models.Model):
foodid = models.IntegerField(primary_key=True)
fname = models.CharField(max_length=50)
ftaste = models.CharField(max_length=50)
cooking_method = models.CharField(max_length=50)
img_url = models.CharField(max_length=255)
class Rating(models.Model):
foodid = models.ForeignKey(Foodlist, on_delete=models.CASCADE)
username = models.CharField(max_length=50)
rating = models.IntegerField()
class Recommendation(models.Model):
re_foodid = models.IntegerField(primary_key=True)
re_fname = models.CharField(max_length=50)
re_username = models.CharField(max_length=255)
re_food_url = models.CharField(max_length=255)
1.3.2 mysql数据库内容
这里和Django代码中的数据库设计是一一对应的,MySQL中的数据库是Django生成的。
数据库:
food_recommend
表:
ratings_foodlist:foodid是餐品的唯一id,fname是餐品的名字,ftaste是餐品的口味,cooking_method是餐品的制作方法,img_url是餐品图片;
ratings_rating:id是该表数据行的顺序id,foodid_id是餐品的唯一外键id,username是评分的用户名,rating是用户对餐品的评分;
ratings_recommendation:id是该表数据行的顺序id,re_foodid是经过推荐之后的餐品id,re_username是评分的用户名,re_food_ur是经过推荐之后的餐品图片;
1.3.3 启动命令:
这是操作Django进行数据库转移操作的命令。
C:\Users\Lenovo\.conda\envs\pythonProject1\python.exe manage.py makemigrations
C:\Users\Lenovo\.conda\envs\pythonProject1\python.exe manage.py migrate
C:\Users\Lenovo\.conda\envs\pythonProject1\python.exe manage.py runserver
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-stxa9SZH-1686719313916)(毕设.assets\image-20230413235952699.png)]
1.4 hdfs2mysql脚本datax
在这里也可以用其他工具导入mysql,如sqoop,甚至可以用hive,之所以选mysql是因为我当时关系型数据库就会mysql。
脚本启动命令
python /opt/installs/datax/bin/datax.py /opt/installs/datax/job/hdfs2mysql.json
{
"job": {
"setting": {
"speed": {
"channel": 2
}
},
"content": [
{
"reader": {
"name": "hdfsreader",
"parameter": {
"path": "/food_clean/out/part-r-00000",
"defaultFS": "hdfs://hadoop10:8020",
"column": [
{
"index": 0,
"type": "long"
},
{
"index": 1,
"type": "string"
},
{
"index": 2,
"type": "string"
},
{
"index": 3,
"type": "string"
},
{
"index": 4,
"type": "string"
}
],
"fileType": "text",
"encoding": "UTF-8",
"fieldDelimiter": "\t"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": ["foodid","fname","ftaste","cooking_method","img_url"],
"connection": [
{
"jdbcUrl": "jdbc:mysql://hadoop13:3306/food_recommend?com.mysql.jdbc.faultInjection.serverCharsetIndex=45",
"table": ["ratings_foodlist"]
}
],
"password": "0000",
"preSql": [],
"session": [],
"username": "root",
"writeMode": "insert"
}
}
}
]
}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WIZrB9VN-1686719313917)(毕设.assets\image-20230413235732664.png)]
执行结果
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-K51bNQ2S-1686719313918)(毕设.assets\image-20230414000048379.png)]
1.5 mysql去重操作
CREATE TEMPORARY TABLE temp_table
SELECT MAX(foodid) AS max_id
from ratings_foodlist
GROUP BY fname
DELETE FROM ratings_foodlist
WHERE foodid NOT IN (
SELECT max_id
FROM temp_table
);
DROP TEMPORARY TABLE temp_table;
这个语句会先创建一个临时表,该表包含每个 fname 的最大 ID,然后将该临时表与 ratings_foodlist 表进行比较,删除不在临时表中的记录,最后删除临时方法可以避免在子查询中更新同一个表的问题。如果不创建临时表会You can't specify target table 'ratings_foodlist' for update in FROM clause
0614更新:
其实不做去重操作也ok,有重复的数据并不影响CF算法的建模和计算,至于推荐结果的准确度和科学性,它并不是本科生毕业设计的考虑范围,能跑起来就万事大鸡。
二、建模和推荐
ALS
#!/usr/bin/env python
# coding: utf-8
# In[7]:
from pyspark.ml.evaluation import RegressionEvaluator
from pyspark.ml.feature import StringIndexer, VectorAssembler
from pyspark.ml.recommendation import ALS
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
SparkSession.builder.config('spark.driver.extraClassPath',
'/opt/installs/spark3.1.2/jars/mysql-connector-java-8.0.20.jar')
# In[8]:
def get_data(table_name, re_spark):
url = "jdbc:mysql://hadoop13:3306/food_recommend?characterEncoding=UTF-8&useSSL=false&serverTimezone=GMT%2B8"
properties = {"user": "root", "password": "0000", "driver": "com.mysql.cj.jdbc.Driver"}
df = re_spark.read.jdbc(url=url, table=table_name, properties=properties)
return df
# In[17]:
spark = SparkSession.builder.appName("FoodRecommendation").getOrCreate()
foodlist_df = get_data("ratings_foodlist", spark)
rating_df = get_data("ratings_rating", spark)
foodlist_df.show(10, truncate=False)
rating_df.show(10, truncate=False)
# In[18]:
# 将类别、风格、颜色、品牌字符串转为数值类型,离散变量数值化
ftaste_indexer = StringIndexer(inputCol="ftaste", outputCol="ftaste_index")
method_indexer = StringIndexer(inputCol="cooking_method", outputCol="method_index")
user_indexer = StringIndexer(inputCol='username', outputCol='user_id')
# 将所有特征向量化
feature_columns = ["ftaste_index", "method_index"]
assembler = VectorAssembler(inputCols=feature_columns, outputCol="features")
# 对数据进行特征工程
indexed_foodlist_df = ftaste_indexer.fit(foodlist_df).transform(foodlist_df)
indexed_foodlist_df = method_indexer.fit(indexed_foodlist_df).transform(indexed_foodlist_df)
foodlist_df_with_features = assembler.transform(indexed_foodlist_df)
foodlist_df.show(10, truncate=False)
foodlist_df_with_features.show(10, truncate=False)
# In[41]:
# 使用编码器拟合数据,并转换数据集,以添加新的user_id列
indexed_df = user_indexer.fit(rating_df).transform(rating_df).withColumn('user_id', col('user_id').cast('integer'))
features = foodlist_df_with_features.select("foodid", "features", "img_url")
users = indexed_df.select("username", "foodid_id", "user_id", "rating").withColumnRenamed("foodid_id", "foodid")
# features 包含字段 "foodid", "features", "img_url"
# users 包含字段 "username", "foodid", "user_id", "rating"
indexed_df.show(10, truncate=False)
features.show(10, truncate=False)
users.show(10, truncate=False)
# In[42]:
rec_df = users.join(features.select("foodid", "features"), "foodid", how='left').select("user_id", "foodid", "rating",
"features")
(training, test) = rec_df.randomSplit([0.8, 0.2])
als = ALS(rank=10, maxIter=10, regParam=0.01, userCol="user_id", itemCol="foodid", ratingCol="rating",
coldStartStrategy="drop")
model = als.fit(rec_df)
# In[44]:
# 对测试集进行预测并进行评估
predictions = model.transform(test)
evaluator = RegressionEvaluator(metricName="rmse", labelCol="rating", predictionCol="prediction")
rmse = evaluator.evaluate(predictions)
mae = evaluator.setMetricName("mae").evaluate(predictions)
print("Root-mean-square error = " + str(rmse))
print("Mean absolute error = " + str(mae))
# 得到全部用户的推荐结果
user_recs = model.recommendForAllUsers(5)
user_recs_with_foodid = user_recs.select("user_id", "recommendations.foodid", "recommendations.rating")
user_recs_with_foodid.show(truncate=False)
foodid_df = user_recs_with_foodid.select("user_id", explode("foodid").alias("foodid"), "rating")
foodid_df.show(truncate=False)
# In[45]:
users_unique = users.groupBy('user_id').agg(first('username').alias('username'))
users = foodid_df.selectExpr("user_id", "foodid").join(users_unique.selectExpr("user_id", "username"), "user_id",
how='left').join(foodlist_df.select("foodid", "img_url"),
"foodid", how='left').selectExpr(
"foodid as re_foodid", "username as re_username", "img_url as re_food_url")
users.show(truncate=False)
# In[46]:
users = foodid_df.selectExpr("user_id", "foodid").join(foodlist_df.select("foodid", "fname", "img_url"), "foodid",
how='left').join(users_unique.selectExpr("user_id", "username"),
"user_id", how='left').selectExpr(
"foodid as re_foodid", "fname as re_fname", "username as re_username", "img_url as re_food_url")
users.show(truncate=False)
# In[47]:
users.write.format("jdbc").option("url",
"jdbc:mysql://hadoop13:3306/food_recommend?characterEncoding=UTF-8&useSSL=false&serverTimezone=GMT%2B8") \
.option("dbtable", "ratings_recommendation") \
.option("user", "root") \
.option("password", "0000") \
.option("driver", "com.mysql.cj.jdbc.Driver") \
.mode("overwrite") \
.save()
# In[ ]:
Item-based
from pyspark.ml.evaluation import RegressionEvaluator
from pyspark.ml.recommendation import ALS
from pyspark.sql import SparkSession
from pyspark.ml.feature import StringIndexer
# 数据库连接函数
SparkSession.builder.config('spark.driver.extraClassPath',
'/opt/installs/spark3.1.2/jars/mysql-connector-java-8.0.20.jar')
# In[8]:
def get_data(table_name, re_spark):
url = "jdbc:mysql://hadoop13:3306/food_recommend?characterEncoding=UTF-8&useSSL=false&serverTimezone=GMT%2B8"
properties = {"user": "root", "password": "0000", "driver": "com.mysql.cj.jdbc.Driver"}
df = re_spark.read.jdbc(url=url, table=table_name, properties=properties)
return df
# 初始化 SparkSession
spark = SparkSession.builder.appName("FoodRecommendation_ItemBased").getOrCreate()
# 获取数据
foodlist_df = get_data("ratings_foodlist", spark)
rating_df = get_data("ratings_rating", spark)
# 显示数据
print("Foodlist Data:")
foodlist_df.show(10, truncate=False)
print("Rating Data:")
rating_df.show(10, truncate=False)
# 数据预处理:确保 ALS 算法所需的列的数据类型正确
# rating_df = rating_df.withColumn("user_id", rating_df["username"].cast("integer"))
rating_df = rating_df.withColumn("food_id", rating_df["foodid_id"].cast("integer"))
rating_df = rating_df.withColumn("rating", rating_df["rating"].cast("float"))
# userid的处理为数值
user_indexer = StringIndexer(inputCol="username", outputCol="user_id")
user_indexer_model = user_indexer.fit(rating_df)
rating_df = user_indexer_model.transform(rating_df)
# 显示处理后的评分数据
print("Processed Rating Data:")
rating_df.show(10, truncate=False)
# 数据划分:将数据划分为训练集和测试集
(training, test) = rating_df.randomSplit([0.8, 0.2])
# 构建基于物品的协同过滤模型
als = ALS(
rank=10,
maxIter=10,
regParam=0.01,
userCol="user_id",
itemCol="food_id",
ratingCol="rating",
coldStartStrategy="drop",
implicitPrefs=False, # 将此设置为 False 以进行显式反馈,基于物品的协同过滤
)
# 拟合模型
model = als.fit(training)
# 对测试集进行预测
predictions = model.transform(test)
# 显示预测结果
print("Predictions:")
predictions.show(10, truncate=False)
# 评估模型
evaluator = RegressionEvaluator(metricName="rmse", labelCol="rating", predictionCol="prediction")
rmse = evaluator.evaluate(predictions)
print("Root-mean-square error = " + str(rmse))
# 为所有物品生成推荐
item_recs = model.recommendForAllItems(5)
# 显示推荐结果
print("Item Recommendations:")
item_recs.show(truncate=False)
# Predictions:
# +---+--------+------+---------+-------+-------+----------+
# |id |username|rating|foodid_id|food_id|user_id|prediction|
# +---+--------+------+---------+-------+-------+----------+
# |22 |zhangsan|3.0 |28 |28 |0.0 |0.75916743|
# +---+--------+------+---------+-------+-------+----------+
#
# Root-mean-square error = 2.240832567214966
# Item Recommendations:
# +-------+---------------------------------+
# |food_id|recommendations |
# +-------+---------------------------------+
# |623 |[{0, 4.9992123}, {1, 2.999935}] |
# |28 |[{1, 4.9966803}, {0, 0.75916743}]|
# |16114 |[{0, 4.995712}, {1, 0.69256437}] |
# |178 |[{0, 3.9965696}, {1, 0.5540514}] |
# |470 |[{0, 3.9965696}, {1, 0.5540514}] |
# |5203 |[{0, 2.9974272}, {1, 0.4155385}] |
# |1811 |[{0, 4.995712}, {1, 0.69256437}] |
# |2822 |[{0, 2.9974272}, {1, 0.4155385}] |
# |35119 |[{1, 3.997344}, {0, 0.6073338}] |
# |28347 |[{0, 1.9982848}, {1, 0.2770257}] |
# |4771 |[{1, 4.9966803}, {0, 0.75916743}]|
# |3274 |[{1, 4.9966803}, {0, 0.75916743}]|
# |45383 |[{0, 3.9965696}, {1, 0.5540514}] |
# |31051 |[{1, 2.9980083}, {0, 0.45550042}]|
# +-------+---------------------------------+
#
# 这是基于物品的协同过滤模型的输出结果。我们逐一解释一下:
#
# Predictions:这个表格显示了模型对测试集中的评分进行的预测。对于每个用户-物品对,模型预测用户对该物品的评分。例如,对于用户zhangsan(user_id为0)和物品28,模型预测的评分为0.75916743。实际评分为3.0,所以预测误差为2.240832567214966。
#
# Root-mean-square error:这是模型预测评分和实际评分之间的均方根误差(RMSE)。RMSE值越低,模型预测的准确性越高。
#
# Item Recommendations:这个表格显示了为每个物品生成的推荐用户。对于每个物品(food_id),推荐系统为其推荐一组用户,这些用户可能对该物品感兴趣。例如,对于物品623,推荐给用户0(评分为4.9992123)和用户1(评分为2.999935)。这些推荐是根据用户之间的相似性和他们对其他物品的评分生成的。
#
# 这些输出可以帮助你了解模型的性能以及为每个物品生成的推荐。你可以根据这些推荐来为用户提供个性化的物品推荐。
# 这里的数据表示物品623对于用户0的预测评分是4.9992123,对于用户1的预测评分是2.999935。评分越高,表示用户对该物品的喜欢程度越高。因此,根据这个预测结果,物品623更适合用户0,而不是用户1。
#
# RMSE(均方根误差)是用于评估整个模型预测评分和实际评分之间的误差。RMSE值越低,表示模型预测的整体准确性越高,但这并不直接关系到单个物品对于某个用户的推荐。
user-based
from pyspark.ml.evaluation import RegressionEvaluator
from pyspark.ml.feature import StringIndexer
from pyspark.ml.recommendation import ALS
from pyspark.sql import SparkSession
from pyspark.sql.functions import col
def get_data(table_name, re_spark):
url = "jdbc:mysql://hadoop13:3306/food_recommend?characterEncoding=UTF-8&useSSL=false&serverTimezone=GMT%2B8"
properties = {"user": "root", "password": "0000", "driver": "com.mysql.cj.jdbc.Driver"}
df = re_spark.read.jdbc(url=url, table=table_name, properties=properties)
return df
spark = SparkSession.builder \
.appName("FoodRecommendation") \
.config('spark.driver.extraClassPath', '/opt/installs/spark3.1.2/jars/mysql-connector-java-8.0.20.jar') \
.getOrCreate()
foodlist_df = get_data("ratings_foodlist", spark)
rating_df = get_data("ratings_rating", spark)
user_indexer = StringIndexer(inputCol="username", outputCol="user_id").fit(rating_df)
food_indexer = StringIndexer(inputCol="foodid_id", outputCol="food_id").fit(rating_df)
indexed_rating_df = user_indexer.transform(rating_df)
indexed_rating_df = food_indexer.transform(indexed_rating_df)
print('foodlist_df.show rating_df.show')
foodlist_df.show(10, truncate=False)
rating_df.show(10, truncate=False)
indexed_rating_df.show()
# 训练ALS模型
als = ALS(rank=10, maxIter=10, regParam=0.01,
userCol="user_id", itemCol="food_id", ratingCol="rating",
coldStartStrategy="drop")
(training, test) = indexed_rating_df.randomSplit([0.8, 0.2])
model = als.fit(training)
# 预测和评估
predictions = model.transform(test)
evaluator = RegressionEvaluator(metricName="rmse", labelCol="rating", predictionCol="prediction")
rmse = evaluator.evaluate(predictions)
print("Root-mean-square error = " + str(rmse))
# Root-mean-square error = 0.022859573364257812
# 获取用户推荐
user_recs = model.recommendForAllUsers(5)
user_recs.show(truncate=False)
# 23/04/24 14:52:58 WARN LAPACK: Failed to load implementation from: com.github.fommil.netlib.NativeRefLAPACK
# Root-mean-square error = 0.030036449432373047
# +-------+---------------------------------------------------------------------------------+
# |user_id|recommendations |
# +-------+---------------------------------------------------------------------------------+
# |1 |[{11, 5.001959}, {15, 5.001959}, {0, 4.9699636}, {3, 4.0015674}, {12, 4.0015674}]|
# |0 |[{5, 5.0003386}, {2, 5.0003386}, {8, 5.0003386}, {1, 4.9684596}, {13, 4.0002704}]|
# +-------+---------------------------------------------------------------------------------+
#
# 基于模型ALS算法和基于物品算法都是流行的协同过滤推荐算法,它们都有一些优势和劣势。相比之下,基于用户的算法有以下两个优势:
#
# 解释性更好
# 基于用户的协同过滤算法更加直观,因为它可以告诉我们每个用户对哪些物品有偏好,可以更容易地解释推荐结果。
# 而基于物品的协同过滤算法只能告诉我们哪些物品与某个物品相似,而无法告诉我们哪些用户对这些物品感兴趣。
#
# 可扩展性更好
# 基于用户的协同过滤算法相对于基于物品的协同过滤算法具有更好的可扩展性。因为在基于用户的协同过滤算法中,
# 每个用户的偏好可以被认为是相对独立的。因此,它可以更容易地扩展到大量用户的情况下,而不需要考虑物品的数量。
# 而在基于物品的协同过滤算法中,考虑到每个物品需要与其他物品计算相似度,因此在物品数量较大时,计算成本会变得更高。
#
三、网页加入评分入库
3.1 food_list.html网页代码
{% extends 'base.html' %}
{% block title %}
餐饮推荐系统
{% endblock %}
{% block content %}
<h1 class="text-center my-5">请对以下菜品打上您心中的分数h1>
<div class="container">
{% for food in food %}
<div class="row">
<div class="col-md-4">
<div class="food-card">
<div class="image-container">
<img src="{{ food.img_url }}" alt="{{ food.fname }}"
class="img-fluid rounded">
div>
<div class="food-info">
<h4>{{ food.fname }}h4>
<p>口味:{{ food.ftaste }}p>
<p>烹饪方法:{{ food.cooking_method }}p>
<form method="post" action="{% url 'rate_food' %}">
{% csrf_token %}
<select name="rating">
<option value="" disabled selected>请选择评分option>
<option value="1">1option>
<option value="2">2option>
<option value="3">3option>
<option value="4">4option>
<option value="5">5option>
select>
<input type="hidden" name="foodid_id" value="{{ food.foodid }}">
<input type="hidden" name="username" value="admin">
<button type="submit" class="btn btn-primary">提交评分button>
form>
div>
div>
div>
div>
{% endfor %}
div>
<a href="#top" class="anchor">TOPa>
<style>
.container {
display: grid;
grid-template-columns: repeat(auto-fit, minmax(300px, 1fr));
gap: 20px;
justify-items: center;
}
.food-card {
transition: transform 0.3s;
box-sizing: border-box;
width: 300px;
}
.food-card:hover {
transform: scale(1.05);
}
.food-card img {
max-height: 200px;
object-fit: cover;
width: 100%;
height: 100%;
}
.food-info {
margin-top: 10px;
transition: color 0.3s;
}
.food-card:hover .food-info h4,
.food-card:hover .food-info p {
color: #007bff;
}
.anchor {
position: fixed;
bottom: 60px;
right: 20px;
padding: 10px 20px;
background-color: #666666;
color: #fff;
text-decoration: none;
border-radius: 5px;
z-index: 9999;
}
.anchor:hover {
background-color: #999999;
text-decoration: none;
color: #fff;
}
.button-container button {
padding: 10px 20px;
background-color: #007bff;
color: #fff;
border: none;
border-radius: 5px;
cursor: pointer;
}
.button-container button:hover {
background-color: #0056b3;
}
style>
{% endblock %}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NJpLmZWn-1686719313919)(毕设.assets/Snipaste_2023-04-23_22-57-36.png)]
3.2 recommendations.html页代码
{% extends 'base.html' %}
{% block title %}
餐饮推荐系统
{% endblock %}
{% block content %}
<h1 class="text-center my-5">请对以下菜品打上您心中的分数h1>
<div class="container">
{% for food in food %}
<div class="row">
<div class="col-md-4">
<div class="food-card">
<div class="image-container">
<img src="{{ food.img_url }}" alt="{{ food.fname }}"
class="img-fluid rounded">
div>
<div class="food-info">
<h4>{{ food.fname }}h4>
<p>口味:{{ food.ftaste }}p>
<p>烹饪方法:{{ food.cooking_method }}p>
<form method="post" action="{% url 'rate_food' %}">
{% csrf_token %}
<select name="rating">
<option value="" disabled selected>请选择评分option>
<option value="1">1option>
<option value="2">2option>
<option value="3">3option>
<option value="4">4option>
<option value="5">5option>
select>
<input type="hidden" name="foodid_id" value="{{ food.foodid }}">
<input type="hidden" name="username" value="admin">
<button type="submit" class="btn btn-primary">提交评分button>
form>
div>
div>
div>
div>
{% endfor %}
div>
<a href="#top" class="anchor">TOPa>
<style>
.container {
display: grid;
grid-template-columns: repeat(auto-fit, minmax(300px, 1fr));
gap: 20px;
justify-items: center;
}
.food-card {
transition: transform 0.3s;
box-sizing: border-box;
width: 300px;
}
.food-card:hover {
transform: scale(1.05);
}
.food-card img {
max-height: 200px;
object-fit: cover;
width: 100%;
height: 100%;
}
.food-info {
margin-top: 10px;
transition: color 0.3s;
}
.food-card:hover .food-info h4,
.food-card:hover .food-info p {
color: #007bff;
}
.anchor {
position: fixed;
bottom: 60px;
right: 20px;
padding: 10px 20px;
background-color: #666666;
color: #fff;
text-decoration: none;
border-radius: 5px;
z-index: 9999;
}
.anchor:hover {
background-color: #999999;
text-decoration: none;
color: #fff;
}
.button-container button {
padding: 10px 20px;
background-color: #007bff;
color: #fff;
border: none;
border-radius: 5px;
cursor: pointer;
}
.button-container button:hover {
background-color: #0056b3;
}
style>
{% endblock %}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-A9CU1kYd-1686719313930)(毕设.assets/image-20230423232004274.png)]
3.3 views.py视图层
import os
from django.conf import settings
from django.http import HttpResponse
from django.shortcuts import render, redirect
from .models import Foodlist, Rating, Recommendation
import subprocess
# food_list.html中使用的数据库
def food_list(request):
food = Foodlist.objects.all()
return render(request, 'food_list.html', {'food': food})
# 增加提交数据库功能
def rate_food(request):
if request.method == 'POST':
username = request.POST['username']
rating = request.POST['rating']
foodid_id = int(request.POST['foodid_id'])
foodlist = Foodlist.objects.get(foodid=foodid_id) # 根据 foodid 获取 Foodlist 实例
rating = Rating(username=username, rating=rating, foodid=foodlist) # 修改字段名为foodid
rating.save()
return redirect('rate_food') # 根据需要跳转到成功页面
else:
# 处理 GET 请求,渲染表单页面
food_list = Foodlist.objects.all() # 获取所有食品对象,用于渲染表单页面
return render(request, 'food_list.html', {'food': food_list})
def recommendations(request):
re_username = request.GET.get('re_username')
re = request.GET.get('re')
if re_username:
recommend = Recommendation.objects.filter(re_username=re_username)
else:
recommend = []
if re == "yes":
print("yes")
subprocess.run(['python', 'ratings/utils/food_recommend.py'])
context = {
're_username': re_username,
'recommendations': recommend,
}
return render(request, 'recommendations.html', context)
3.4 urls.py路由层
from django.urls import path
from ratings.views import food_list, rate_food, recommendations
from django.conf.urls.static import static
from django.conf import settings
from . import views
urlpatterns = [
path('', food_list, name='food_list'),
path('rate_food/', rate_food, name='rate_food'),
path('recommendations/', views.recommendations, name='recommendations'),
] + static(settings.MEDIA_URL, document_root=settings.MEDIA_ROOT)
3.5 后端
views.py
from django.shortcuts import render, redirect
from .models import Foodlist
from .forms import FoodlistForm
def manage_food(request):
if request.method == 'POST':
# 添加新菜品
if 'add_food' in request.POST:
form = FoodlistForm(request.POST)
if form.is_valid():
form.save()
# 删除菜品
elif 'delete_food' in request.POST:
food_id = request.POST.get('foodid')
Foodlist.objects.filter(foodid=food_id).delete()
# 获取菜品列表
food_list = Foodlist.objects.all()
form = FoodlistForm()
context = {'food_list': food_list, 'form': form}
return render(request, 'manage_food.html', context)
url层
from django.urls import path
from . import views
urlpatterns = [
# 其他路由...
path('manage_food/', views.manage_food, name='manage_food'),
]
html
{% extends 'base.html' %}
{% block content %}
后端管理界面
添加菜品
删除菜品
菜品列表
ID
菜品名
口味
烹饪方法
图片 URL
{% for food in food_list %}
{{ food.foodid }}
{{ food.fname }}
{{ food.ftaste }}
{{ food.cooking_method }}
{{ food.img_url }}
{% endfor %}
forms.py
from django import forms
from .models import Foodlist
class FoodlistForm(forms.ModelForm):
class Meta:
model = Foodlist
fields = ['foodid', 'fname', 'ftaste', 'cooking_method', 'img_url']
labels = {
'foodid': '菜品 ID',
'fname': '菜品名',
'ftaste': '口味',
'cooking_method': '烹饪方法',
'img_url': '图片 URL',
}