Benchmarking Augmentation Methods for Learning Robust Navigation Agents 论文阅读
论文信息
题目:Benchmarking Augmentation Methods for Learning Robust Navigation Agents: the Winning Entry of the 2021 iGibson Challenge
作者:Naoki Yokoyama, Qian Luo
来源:arXiv
时间:2022
Abstract
深度强化学习和可扩展的真实感模拟的最新进展使得用于各种视觉任务(包括导航)的具体人工智能日益成熟。然而,虽然在教导实体主体在静态环境中导航方面取得了令人印象深刻的进展,但在可能包括移动行人或可移动障碍物的动态环境中却取得了较少的进展。
在这项研究中,我们的目标是对不同的增强技术进行基准测试,以提高代理在这些具有挑战性的环境中的性能。我们表明,在训练过程中向场景中添加几个动态障碍可以显着提高测试时泛化能力,从而实现比基线智能体更高的成功率。我们发现这种方法还可以与图像增强方法相结合,以获得更高的成功率。此外,我们还表明,与图像增强方法相比,这种方法对于模拟到模拟的传输也更加稳健。
最后,我们通过使用这种动态障碍物增强方法来训练代理参加 CVPR 的 2021 年 iGibson 挑战赛,展示了这种动态障碍物增强方法的有效性,该方法在交互式导航方面获得了第一名。

Introduction
自主导航是一项艰巨的挑战,通常需要机器人使用视觉传感器来理解和推理周围环境。幸运的是,最近的几项使用深度强化学习的工作通过部署可以在现实世界的新环境中成功导航的机器人显示出了有希望的结果[1],[2]。
PointGoal Navigation [3] 是一项经过充分研究的任务,它要求代理到达其环境中的目标坐标位置。然而,它通常假设环境是静态的并且没有动态物体,这与可能包含移动的人类和宠物或小型可移动障碍物和家具的真实家庭和办公室相去甚远。
最近 2021 年 CVPR 会议上的 iGibson 挑战赛 [4] 旨在鼓励研究人员研究两个难度更大的 PointNav 修改版本:交互式导航(InteractiveNav)和社交导航(SocialNav)。在 InteractiveNav 中,代理必须到达目标,同时推开阻碍路径的可移动障碍物。对于 SocialNav,代理必须达到目标,同时避免与穿越可能无法屈服的环境的人类发生碰撞。
这些动态任务带来了静态导航设置中不存在的新挑战。
对于 InteractiveNav,代理必须区分可移动和不可移动的物体,并学习如何在必要时将可移动的物体推向正确的方向,以形成到达目标的更短路径。
对于 SocialNav,智能体必须避开附近行人的轨迹并在不与任何人发生碰撞的情况下到达目标。使动态导航任务变得更加困难的另一个因素是可用于模拟动态环境的数据的稀疏性。
虽然静态 3D 环境有大量数据集,例如 Gibson [5] 和 HM3D [6],但包含单独可交互且正确布置的家具的动态环境数据集却要稀疏得多。对于 2021 年 iGibson 挑战赛,只有 8 个训练场景可用
为了解决动态导航的挑战和训练场景可用性的限制,我们的目标是提供视觉导航增强技术的基准和分析,以便其他研究人员可以利用我们在 iGibson 挑战赛中的发现。
特别是,我们表明,在训练期间简单地向场景中添加几个动态障碍物(行人)可以显着提高代理在新环境中的测试时成功率,即使对于环境中不涉及动态障碍物的导航任务(例如 PointNav 和互动Nav.我们进行了系统分析,其中我们扫描了可用的训练数据量和训练期间使用的动态行人的数量
我们将这种动态障碍物增强方法与两种图像增强方法(Crop 和 Cutout)进行比较,Laskin 等人 [7] 证明这两种方法可以显着提高视觉任务各种基准上的测试时间泛化性(高达 4 倍的性能改进)[8 ],[9]。
我们表明
- 动态障碍物增强可以与图像增强协同结合,以进一步提高性能。
- 相比之下,组合不同的图像增强方法会降低性能增益。
- 动态障碍物增强对于模拟到模拟的传输也更加稳健。
Related work
PointGoal Navigation
点目标导航(PointNav)由 Anderson 等人在 [3] 中正式定义,是机器人必须从环境中的起始位置导航到目标坐标的任务。在包含障碍物的新场景中执行这是一项具有挑战性的任务,特别是当代理只能访问以自我为中心的相机和自我运动传感器时。尽管存在这些限制,Wijmans 等人 [12] 证明,可以通过深度强化学习在模拟中训练近乎完美(>97% 成功)的 PointNav 代理。
然而,这项工作利用了大量的训练场景;在这项工作中,我们重点关注增强方法如何在只有少量场景可用的场景中提高性能,并表明在此类场景中训练代理以达到相同成功水平的问题尚未解决。
Navigation in Dynamic Environments
Xia 等人最近的工作[11]引入了一项新任务“InteractiveNav”,其中机器人与可移位的物体进行交互以达到目标。这不需要机器人使用机械手;机器人在移动时可以使用其底座简单地推过物体。 InteractiveNav 评估机器人如何平衡采取最短路径到达目标以及它对环境中存在的障碍物的干扰程度。他们的工作表明,可以通过深度强化学习来教导智能体完成这项任务,尽管他们为智能体提供了接下来的十个到达目标位置的路径点作为每一步的观察。
在这项工作中,我们寻求仅使用自我中心视觉和自我运动传感器来研究此任务的性能,以及如何使用增强方法来改进它。
SocialNav 是另一项要求机器人围绕环境中的动态元素进行机动的任务,其中机器人必须在不与附近移动的行人碰撞的情况下到达目标。与我们的工作类似,最近的几项工作也使用了深度强化学习来避免与行人碰撞,例如 SA-CADRL [13] 和 SARL [14],它们使用行人的位置作为对其策略的观察,以及Pérez-D’Arpino 等人 [15] 使用可以访问环境地图和 LiDAR 数据的运动规划器。
与这些作品相比,我们的目标是在没有运动规划器或激光雷达的情况下完成 SocialNav 的任务,并研究如何使用视觉深度强化学习的增强方法来提高性能。我们相信这种设置更适合在新环境中部署,在这些环境中,准确定位行人位置或向运动规划器提供地图可能很困难或不可行。
Enhancing visual navigation performance
Ye 等人 [16] 通过使用自我监督的辅助任务以 Wijman 等人 [12] 的工作为基础,事实证明这可以显着提高样本效率。 Sax 等人 [17] 结合了关于世界的视觉先验,与没有先验的从头到尾的训练相比,获得了性能提升。 Chaplot 等人 [18]、[19] 与典型的端到端代理相比,通过让代理推断有关映射和定位的信息来提高样本效率,这些信息可以使用来自模拟器的特权信息进行监督。
与上面提到的工作不同,我们研究的方法可以在不使用额外的辅助损失、额外的网络头或额外的感官信息(例如,局部占用图)的情况下,对视觉导航产生显着的改进。
Method
Augmentation
训练有效的视觉导航代理需要大型数据集(>70 个 3D 公寓扫描)以避免过度拟合 [12]。然而,访问不同的交互式训练环境可能很困难,特别是对于每个对象都可以单独交互并且必须以现实的方式在环境中排列的动态环境,例如 iGibson 数据集中的合成场景,其中仅包含 15 个场景。对于 2021 年 iGibson 挑战赛,只有 8 个训练场景可用。
在这种数据受限的场景中,增强方法对于提高代理在测试时泛化到新环境的能力至关重要。
Dynamic Obstacle Augmentation
为了提高视觉导航代理的测试时泛化能力,我们在环境中引入了几个移动的行人(如图 1 和图 2 所示)。

这种方法旨在防止智能体学习过度适应训练期间看到的环境;
由于场景中存在大量移动的视觉干扰物,智能体更难以通过摄像头的观察来记住训练环境的布局。
此外,与简单地扰乱智能体视觉输入的图像增强方法不同,该方法迫使智能体为给定情节的一对起始目标位置学习更多种类的路径。
由于每次重置环境时行人所采取的路径都是新生成的,因此代理无法始终在同一对起始目标位置之间采取相同的路径而不与行人发生碰撞。
在训练过程中,这些移动的行人被视为不允许智能体碰撞的动态障碍物。如果特工与行人之间发生碰撞,则事件会直接终止。
使用来自 iGibson 挑战赛 [4] 的站立人 3D 模型代表 3 到 12 名行人,我们发现该模型足够大(对于视觉遮挡),同时具有足够小的半径,可供代理在周围机动。
大多数情况。在每次开始时,对于每个行人,从环境中随机采样两个相距至少 3 米的可导航点。
在整个情节中,每个行人都沿着连接这些点的最短无障碍路径来回移动。它具有与智能体相同的最大线速度和角速度,但其速度在每集的基础上从最大值随机降低最多 10%,这样同一集内的不同行人可以以不同的速度移动
Comparison with Image–based Data Augmentyation
图像增强旨在使用随机扰动(例如裁剪、擦除或旋转)注入不变性先验。
特别是,Laskin 等人 [7] 表明,裁剪和剪切图像增强(见图 3)是提高视觉深度强化学习性能最有效的方法之一。

Crop从原始帧中提取随机补丁;与 Laskin 等人类似,我们在随机位置裁剪帧,使生成的图像在高度和宽度上缩短 8%(即保持原始纵横比)。 Chung 等人[20]详细介绍了 Cutout,将随机形状、长宽比和位置的黑色矩形插入到原始帧中。我们使用与Zhong等人相同的参数,其中矩形的长宽比可以在[0.3,3.33]之间,并且其相对于原始帧的比例可以在[0.02,0.33]之间。此外,我们还研究了 Crop&Cutout,它通过顺序应用将 Crop 和 Cutout 结合起来。
Problem Formulation and Learning Method
Observation and Action Spaces
在每一步中,该策略都会观察以自我为中心的(第一人称)深度图像及其相对距离以及到目标点的方向作为输入。
由于目标点是相对于智能体的初始位置指定的,并且自我运动传感器指示智能体距其初始位置的相对距离和航向,因此它们可用于计算智能体当前到目标的相对距离和航向。
我们选择仅使用深度视觉,而不是同时使用深度和 RGB 视觉,正如 Wijmans 等人 [12] 所表明的那样,与单独使用深度相比,包含 RGB 会损害性能。该策略输出二维对角高斯动作分布,从中采样一对动作(线速度和角速度)。最大速度为 0.5 m/s 和 90°/s,策略轮询频率为 10 Hz。如果速度的大小低于某个阈值(我们实验中最大值的 10%),则会被视为代理调用停止操作,从而结束该事件
Reward Function
无论使用哪种增强方法(如果有的话),我们所有实验使用的奖励函数都是相同的:
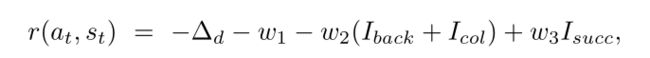
其中 − Δ d -Δ_d −Δd 是自前一个状态以来到目标的测地距离的变化, I b a c k 、 I c o l I_{back}、I_{col} Iback、Icol 和 I s u c c I_{succ} Isucc 是二进制标志,指示智能体是否已向后移动、与环境发生碰撞或成功终止该事件(请参阅成功标准分别见第 III-B 小节)。 w 1 w_1 w1 充当每一步产生的恒定松弛惩罚,以鼓励智能体最大限度地减少剧集完成时间。 w 1 、 w 2 w_1、w_2 w1、w2 和 w 3 w_3 w3 设置为 0.002、0.02 和 10.0。向后运动受到惩罚,因为我们观察到它通常会导致视觉导航性能不佳。然而,我们并不能完全阻止它,因为向后移动有助于避免突然出现在机器人视野中的传入障碍物
Success Criteria
对于所有任务,仅当代理满足以下条件时,事件才会被视为成功:
(1) 调用终止事件的停止操作
(2) 代理位于目标点的 0.2 m 范围内。在 500 步后,或者在进行 SocialNav 或使用动态障碍物增强训练时,如果智能体与动态行人发生碰撞,则情节将终止并被视为不成功。如果智能体距离行人 0.3 m 以内,则视为与行人发生碰撞。
Network Architecture and Training
我们的网络架构有两个主要组成部分;视觉编码器和循环策略。
视觉编码器是一个 ResNet-18 [21] 卷积神经网络,它从深度图像中提取视觉特征。该策略是具有 512 维隐藏状态的 2 层 LSTM [22]。该策略接收视觉特征、相对距离和到目标的方向、先前的动作及其先前的 LSTM 隐藏状态。除了输出动作的头之外,该策略还有一个输出状态值估计的批评者头,用于近端策略优化(PPO)强化学习,如 Schulman 等人在 [23] 中所述。我们使用 Wijmans 等人的去中心化分布式 PPO [12] 来使用并行化来训练我们的代理,并使用相同的学习超参数。
我们为每个 GPU 训练 8 个工作线程,使用 8 个 GPU 总共 64 个工作线程并行收集经验。每个代理都经过 500M 步骤的训练(约 280 个 GPU 小时,或约 35 小时挂钟)
Experiment
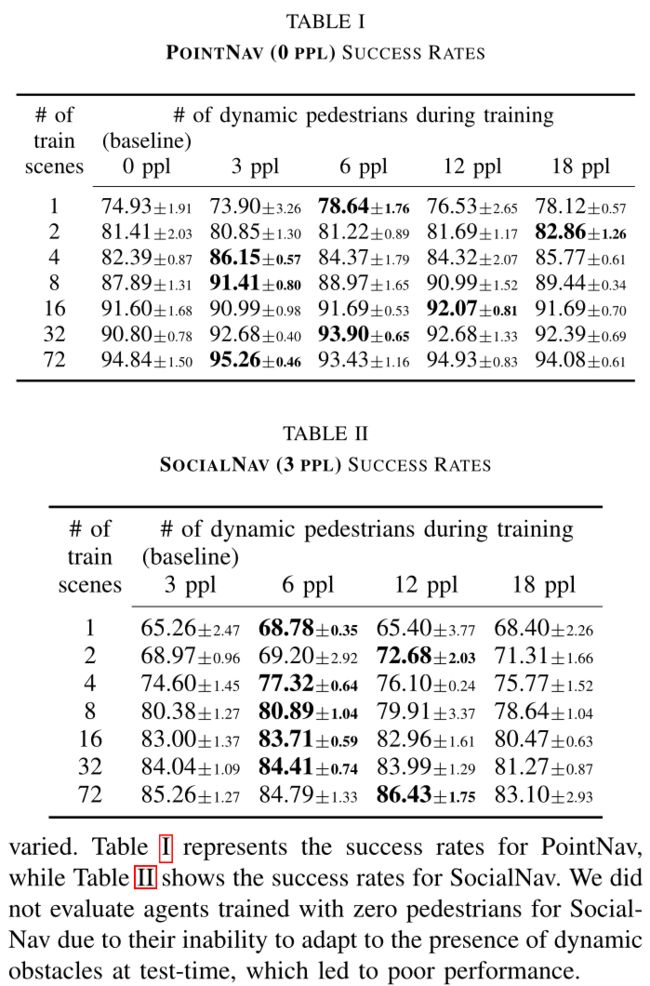
发现 1:即使环境是静态的,动态障碍物增强也能提高视觉导航性能。
发现2:动态障碍物增强在训练场景较少的情况下更有效。
发现 3:图像增强也可以提高测试时的成功率,但将它们结合起来会降低性能增益。
发现 4:将动态障碍物和图像增强技术相结合可以进一步提高成功率。

发现 5:动态障碍物增强对于从 Gibson-4+ 到 iGibson 场景的 sim-to-sim 传输更加稳健。
Conclusion
我们的工作可以在几个方向上扩展。我们怀疑,虽然使用动态行人可以提高性能,但过度拥挤可能会使智能体过于保守并导致行为不佳。未来,我们计划引入curriculum learning,在训练过程中逐步增加行人数量,以潜在地增加行人数量,从而最大限度地提高性能。
我们还计划通过将所提出的技术部署到有行人的现实世界来研究其从模拟到真实的转移。然而,我们预计模拟与真实的差距将导致性能显着下降,特别是因为模拟中使用的行人是单个刚体(即四肢不是独立的动画)。这可以通过为模拟人类添加更真实的动作和手势来解决,以减少模拟与真实的差距。