PromQL看这个就够了附程序接入及函数
目录
1、什么是PromQL?
2、PromQL的格式是什么?
3、数据是如何采集的
4、PromQL的类型有哪些?
5、指标查询
6、操作符的使用
7、匹配模式-一对一
8、匹配模式-一对多
9、范围
10、偏移查询
11、常用的PromQL函数
12、常见问题
12.1、标签被排除
12.2、标签替换错误
12.3、除数为零
12.4、运算结果丢失
12.5、step影响
12.6、重复采集影响
资料链接合集
福利:文末有chat-gpt纯分享,无魔法,无限制
也有资源合集哦
1、什么是PromQL?
这张图记录了在这段时间,数据的走势情况,比如股票大盘就是这样以时间为横坐标,数值为纵坐标的数据,这种以时间序列为横坐标的一串数据又称为时序数据。
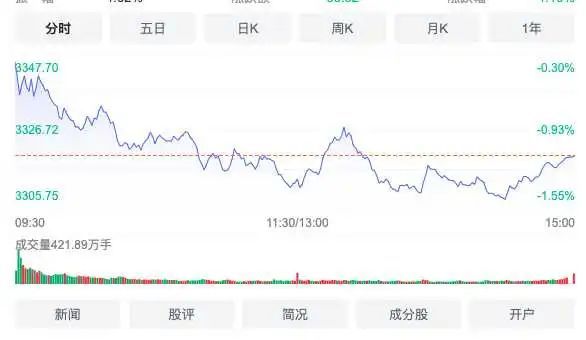
不是专业做监控的不用考虑这些数据是如何存储,只需要会使用就可以了,也许你用过Prometheus,而PromQL就是它使用的查询语言。类似于SQL语句。
2、PromQL的格式是什么?
这条数据表达了某个时间点的http请求总量。

-
metric代表一条完整的指标,http_request_total表明指标是哪一个。 -
大括号内的标签可以理解为字段 ,以键值对的方式存储。
-
label是用来筛选指标的,是不是和mysql非常类似。 -
另外两个一个是时间戳,一个是此时间的指标值(
float64)。
同一个metric中label的值不同,就是不同的指标。
3、数据是如何采集的
一图胜千言。
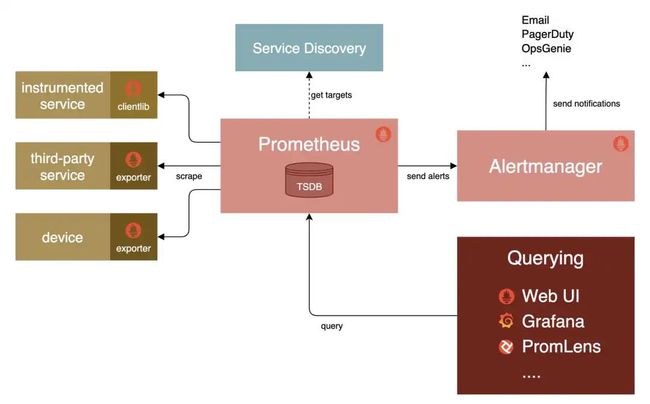
TSDB是时序数据库,用来存时序数据。我在很早以前有写过 这就是Prometheus 涵盖了整个Prometheus的介绍和使用,想看懂这张图的可以先复习一下方便我们后续展开讲解。
所有的应用都可以通过引用sdk来暴露数据(通过HTTP的方式,比如 http://xxx/metrics),再由Prometheus远程拉取数据。资料放文末了。
4、PromQL的类型有哪些?
这就要看需要具体的需求了。
-
监控一般做为组件和系统的健康状态存在,所以最常用的就是实时数据/瞬时数据类型。
-
在统计数据中累计个数,就会有累加类型。
-
想分析大量数据的分布情况,会用到其他两种类型,具体如下。
| 类型 | 作用 |
|---|---|
| Gauge (仪表盘) | 瞬时数据,可增可减,反映当前状态,比如cpu使用率 |
| Counter (计数器) | 累加数据,只增不减,比如HTTP请求总数,推荐使用 _total 作为后缀。 |
| Histogram (直方图) | 统计样本分布情况,比如50%、90%、99%的人工资分别是多少。 |
| Summary (摘要) | 记录当前指标的总数count以及值的总和sum |
-
在统计指标数值分布时,为了区分是平均分布还是长尾效应,最简单的方式就是按照请求延迟的范围进行分组。所以需要后两种类型来统计分布情况。
-
最常用类型是
Gauge顺时值记录
5、指标查询
-
metric{label1="abc",label2="abc"}检索,这就是最简单的PromQL表达式,直接用键值对来检索。 -
指标名称也是一个名为
__name__的内置标签。所以也可以{__name__=~"cpu.*"}来批量匹配指标。 -
标签内支持正则匹配
(=~, !~)和完全匹配(=, !=)的字符串匹配。比如
metric{label1=~"aa.*",label2!~"bb.*",label3!="123"}
6、操作符的使用
数据要能运算才有价值,所以监控领域设计的这门PromQL语言,除了能做过滤筛选的功能以外还能做运算,是不是很强大。
数学运算
-
支持全部基础数学运算:
+(加法)、-(减法)、*(乘法)、/(除法)、%(求余)、^(幂运算)。 -
非特殊标签匹配情况下,只有同
metric才可以运算。 -
标签匹配(就是指标标签相同)情况下,可以灵活控制不同
metric进行运算。
布尔运算
-
布尔运算则支持用户根据时间序列中样本的值,对时间序列进行过滤:
==(相等)、!=(不相等)、>(大于)、<(小于)、>=(大于等于)、<=(小于等于) -
瞬时向量与标量进行布尔运算时,
PromQL依次比较向量中的所有时间序列样本的值,如果比较结果为true则保留,反之丢弃。 -
瞬时向量与瞬时向量直接进行布尔运算时,依次找到与左边向量元素匹配(标签完全一致)的右边向量元素进行相应的操作,如果没找到匹配元素,则直接丢弃。
-
使用
bool修饰符让预算结果产出为1 (true)或0 (false)。
集合运算
-
使用集合运算,可以在两个瞬时向量与瞬时向量之间进行相应的集合操作:
and(并且)、or(或者)、unless(排除) -
vector1 and vector2会产生一个由vector1的元素组成的新的向量。该向量包含vector1中完全匹配 vector2 中的元素组成。 -
vector1 or vector2会产生一个新的向量,该向量包含vector1中所有的样本数据,以及vector2中没有与 vector1 匹配到的样本数据。 -
vector1 unless vector2会产生一个新的向量,新向量中的元素由vector1中没有与vector2匹配的元素组成。
7、匹配模式-一对一
一对一匹配模式会从操作符两边表达式获取的瞬时向量依次比较并找到唯一匹配(标签完全一致)的样本值。
vector1 vector2
-
在操作符两边表达式标签不一致的情况下,可以使用
on(label list)或者ignoring(label list)来修改标签的匹配行为。 -
使用
ignoreing可以在匹配时忽略某些标签。而on则用于将匹配行为限定在某些便签之内。
ignoring()
on()
比如限定后面的指标忽略method标签,来进行运算。
metric1{code="500"} 120
metric2{method="get", code="500"} 24
metric1{code="500"} / ignoring(method) metric2
metric1{code="500"} / on(code) metric2
一般这种操作都都是和其他函数一起出现的,也没必要这么弄,直接这样就行了。
sum(metric1) by(code) / sum(metric2) by(code)
8、匹配模式-一对多
多对一和一对多两种匹配模式指的是“一”侧的每一个向量元素可以与"多"侧的多个元素匹配的情况。
左侧的序列有多个而右侧只有一个时候,不能简单通过 on (label) 来进行查询。
要解决这个问题,我们可以使用 group_left 或group_right 关键字。这两个关键字将匹配分别转换为多对一或一对多匹配。左侧和右侧表示基数较高的一侧。因此,group_left 意味着左侧的多个序列可以与右侧的单个序列匹配。结果是,返回的瞬时向量包含基数较高的一侧的所有标签,即使它们与右侧的任何标签都不匹配。
例如如下所示的查询语句就可以正常获取到结果,而且获取到的时间序列数据包含所有的标签:
metric{code="500",method="get"} 120
metric{code="500",method="post"} 120
total 144
#分别计算出get和post的占比
metric /group_left() total
如果这是从很多台服务器取上来的,还要加on,这样可以算出每台服务器get和post分别的情况。
metric /on(instance) group_left() total
9、范围
-
如果想过去一段时间范围内的样本数据时,需要使用区间向量表达式。
-
在检索指标时,定义时间选择的范围,时间范围通过时间范围选择器 [] 进行定义。
-
s- 秒、m- 分钟、h- 小时、d- 天、w- 周、y- 年。
# 区间1分钟的数据
metric[1m]
还有些专门用于计算范围向量的函数。参考 https://prometheus.io/docs/prometheus/latest/querying/functions/#aggregation_over_time
比如把1h内全部的点加起来如下(不用担心超过数据范围)。
sum_over_time(metric[1h])
10、偏移查询
-
在瞬时向量表达式或者区间向量表达式中,都是以当前时间为基准。
-
位移操作的关键字为 offset 设置与当前时间点的偏移间隔。
例:10分钟前的差值对比。
metric - offset 10m
要做为告警配置的条件则需要更精确的标准,比如数据对比1分钟前减少30%
metric/(metric offset 1m) <0.7
还支持查询接口,参考:https://prometheus.io/docs/prometheus/latest/querying/api/
11、常用的PromQL函数
PromQL 内置函数:https://prometheus.io/docs/prometheus/latest/querying/functions/ MetricsQL 内置函数:https://docs.victoriametrics.com/MetricsQL.html#metricsql-functions
12、常见问题
12.1、标签被排除
使用了 without 导致标签被排除。
sum without(code) (http_xxx)
上述表达式排除了code标签。
12.2、标签替换错误
sum by(code) (label_replace(http_xxx,"code",$2,"code","\d+"))
label_replace 函数的五个参数分别是
12.3、除数为零
-
问题:语句里有除法预算,除数为零时,会导致无效计算而数据为空。
-
解决:减少除数为零的计算模式;添加
or vector(0)来默认null为0;panel上设置null为0。
12.4、运算结果丢失
不同指标运算
-
问题:在没有合理使用
on/ignoring筛选标签时,直接运算会结果为null。 -
解决:注意指标的标识是 name+labels,不同指标运算要注意标签处理。
主要体现在多指标计算时,需要label 完全匹配,如果多指标不匹配会出现意外的情况。
1、完全不匹配会导致结果为空
2、部分不匹配则仅计算匹配label的指标
12.5、step影响
-
问题:step 参数表示查询时序数据库时的跨度步长,计算时会影响精度和斜率,一般 auto 会根据查询时长变长而加大。
-
解决:根据面板的常规查询时长设置合理 step。
要注意采集的间隔会影响到展示的精度,查询的间隔会自动降准导致曲线波动。
同时要注意,监控数据本身就是相对准确的数据,如果配置多个采集那大概率曲线会出现轻微不一致是正常的。
12.6、重复采集影响
irate 与 rate 的计算差异
-
问题:irate 会根据相邻的两个点求速率,因此抖动更加明显;rate 是时间范围内求差值平均速率,因而更平滑。重复采集会出现 irate 取相邻两个点变化一致,而出现空白。
-
解决:减少重复采集,rate 有时候更加合理。
资料链接合集
-
所有的程序如何接入prometheus https://prometheus.io/docs/instrumenting/exporters/
-
PromQL 内置函数:https://prometheus.io/docs/prometheus/latest/querying/functions/
-
MetricsQL 内置函数:https://docs.victoriametrics.com/MetricsQL.html#metricsql-functions
-
查询接口https://prometheus.io/docs/prometheus/latest/querying/api/
-
范围向量的函数。https://prometheus.io/docs/prometheus/latest/querying/functions/#aggregation_over_time
-
全部函数 https://prometheus.io/docs/prometheus/latest/querying/functions
-
充电君会在第一时间给你带来最新、最全面的解读,别忘了三联一波哦。

-
关注公众号:资源充电吧
回复:Chat GPT
充电君发你:免费畅享使用中文版哦
点击小卡片关注下,回复:IT想要的资料全都有