软件安全期末总结
写在前面
所用教材:彭国军等人编著的第一版
博客地址:https://blog.csdn.net/zss192
说明:博客为根据老师所画重点有针对性的总结,供个人复习使用,仅供参考
第一章 软件安全概述
1.软件安全包括三个方面:(P5)
- 软件自身安全(软件缺陷与漏洞)、恶意软件攻击与检测、软件逆向分析(软件破解)与防护
2.软件缺陷或漏洞被触发后典型的威胁有:(P6)
- 软件正常功能被破坏、系统被恶意控制
3.恶意软件对软件及信息系统的威胁有:(P6)
- 已有软件的功能被修改或破坏
- 目标系统中的重要数据被窃取
- 目标系统中的用户行为被监视
- 目标系统被控制
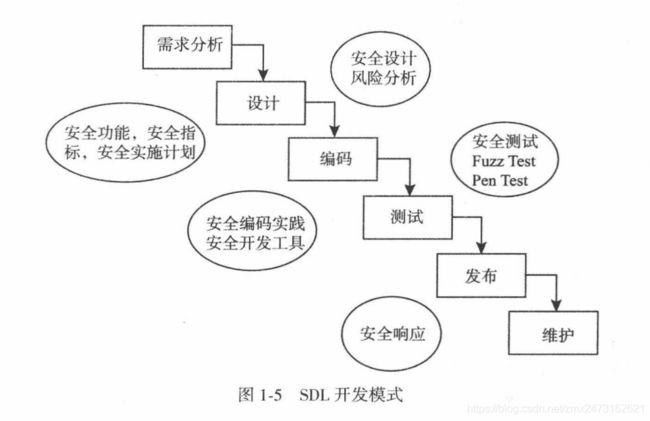
4.微软的SDL开发模式(P9)
5.可信计算的基本思想(P10简答)
首先建立一个信任根,信任根的可信性由物理安全和管理安全确保(目前以TPM作为信任根),再建立一条信任链,从信任根开始到硬件平台、到操作系统、再到应用,一级认证一级,一级信任一级,从而把这种信任边界扩展到整个计算机系统。

第二章 软件安全基础
1.磁盘的三个基本参数(CHS参数) (P13计算)
- 磁头数:有多少个盘片,最大为255(0-255)
- 柱面数:一个盘片有多少圈,最大为1023(0-1023)
- 扇区数:一圈有多少个扇区,最大为63(1-63)(每个扇区一般为512B)
- 最大容量 = (255x1023x63x512)/1048576=8024MB(1MB=220B=1048576B)
最大容量=磁头数x柱面数x扇区数x每个扇区的大小
硬件厂商一般用1M=1000000计算容量,注意单位换算
2.BIOS Int13H(P13)
BIOS Int13H调用是BIOS提供的磁盘基本输入输出中断调用,它可以完成磁盘的复位、读写、检验、定位、诊断、格式化等功能,使用CHS寻址方式,最大能识别8GB左右的硬盘。
3.主引导扇区的组成(P15)
主引导扇区就是硬盘的第一个扇区(0面0磁道1扇区),它由以下三部分组成
- 主引导记录(MBR):占用前446字节,存放着系统主引导程序
- MBR有时也指整个主引导扇区,有时指前446字节的主引导记录
- 硬盘主分区表(DPT):占用64字节,记录磁盘的基本分区信息。分为四个分区项,每项16字节,分别记录每个主分区的信息(因此最多可以有4个主分区)
- 引导扇区标记:占用两个字节,合法引导区固定等于0xAA55,是判断引导区是否合法的标志

4.主分区、扩展分区和逻辑分区的区别(P16)
- 主分区:也叫引导分区,最多能创建4个,主分区就是引导电脑开机读取文件的一个磁盘分区(数量1-4)
- 扩展分区:解决最多只能创建4个分区的问题,主引导分区必须有一个基本扩展分区项,其它扩展分区以链表形式存放。划分主分区后剩余的就是扩展分区。(数量0-1且主分区+扩展分区≤4)
- 逻辑分区:扩展分区并不能直接使用,必须再分成逻辑分区才能使用(数量0-n)

系统中看到的盘都是主分区或者逻辑分区
助记:正常情况只需要划分主分区,但要想划分4个以上分区就要划分扩展分区,这时会有3个主分区1个扩展分区,但扩展分区不能直接用,我们可以再在其基础上划分成两个逻辑分区,这两个分区就是我们平常看到的盘,至此,当前共有3+2=5个分区可用。如果扩展分区并不全都划分成逻辑分区,那么剩余的磁盘空间还是扩展分区,只不过这部分空间不能使用。
新硬盘建立分区过程:建立主分区→建立扩展分区→建立逻辑分区→激活主分区→格式化所有分区


5.当前系统流行的引导形式是什么?它与BIOS引导有什么区别?(P15)
传统模式:BIOS引导,硬盘分区类型必须是MBR
当前模式:UEFI引导,硬盘分区类型必须是GPT
区别如下:
(1)效率方面:大部分BIOS代码使用汇编语言开发,开发效率低;在UEFI中,绝大部分代码采用C语言编写,效率较高。
(2)性能方面:BOIS需要通过中断来完成,开销大,性能低;UEFI舍弃了中断方式,仅仅保留了时钟中断。外部设备的操作采用“事件+异步操作”完成,性能大大提高。
(3)扩展性方面:BIOS代码采用静态链接,不提供动态加载设备驱动的方案,功能扩展性差,升级缓慢;UEFI系统的可扩展性体现在两个方面:一是驱动的模块化设计;二是软硬件升级的兼容性,使得系统升级过程更加简单、平滑。
(4)安全方面:BIOS运行过程中对可执行代码没有安全方面的考虑;当系统的安全启动功能被打开后,UEFI在执行应用程序和驱动前会先检测程序和驱动的证书,仅当证书被信任时才会执行这个应用程序或驱动。
6.文件系统(P16)
- Windows系统:FAT12、FAT16、FAT32(单个文件最大4G)、NTFS、WINFS等
- Linux系统:Ext2、Ext3、Ext4、Minix、NTFS等
7.80X86处理器支持三种工作模式(P20)
- 实模式:复位或加电以实模式启动
- 32位地址线只用了低20位
- 不能分页,指令寻址的地址就是实际物理地址
- 不支持优先级,所有指令工作在特权级别(优先级0)
- 保护模式:80X86的一般工作模式
- 32位地址都用来寻址
- 支持内存分页
- 支持虚拟内存
- 支持优先级机制,操作系统运行在内核模式Ring0(最高优先级),应用程序运行在用户模式Ring3
- 虚拟8086模式:在保护模式下兼容8086而设置的
DOS运行在实模式下,Windows运行在保护模式下
8.(P23)
用户空间:0000 0000H ~ 7FFF FFFFH
系统空间:8000 0000H ~ FFFF FFFFH
推测给地址问在哪个空间下,只需看第一位是0-7还是8-F即可判断出来
9.内存分配与管理函数(P26)
- 分配/保留虚拟内存:VirtualAlloc(lpMem,Size,Type,Access)
- lpMem:要分配/保留的内存地址,可以为NULL
- Size:要分配的内存大小,字节为单位
- Type:分配的类型,如MEM_COMMINT(提交内存)
- Access:保护标志,如PAGE_READONLY、PAGE_READ-WRITE(分配的内存可读可写)
- 释放虚拟内存:VirtualFree(LpMem,Size,Type)
- lpMem:要释放的内存基地址
- Size:要分配的内存大小,字节为单位
- Type:释放的类型,如MEM_DECOMMINT(取消提交内存)、MEM_RELEASE(释放)
10.请你大致写出计算机的启动过程(P28简答)
主要可分为四个阶段
- (1)BIOS:首先进行硬件自检(POST),若有故障会发出蜂鸣声,然后按照启动顺序选择从哪个设备启动
- (2)主引导记录(MBR):读取设备的前512字节,判断设备能否启动,若不能则按启动顺序尝试启动下一个设备。然后BIOS会依次遍历主分区找到激活分区
- (3)硬盘启动:计算机会读取激活分区的第一个扇区即卷引导记录(VBR),VBR告诉计算机操作系统位于该分区的哪个位置,然后计算机就可以加载操作系统了
- (4)操作系统:首先载入操作系统的内核。例如Linux,先载入/boot下的kernel,然后产生init进程,init进程会加载各个模块,等待用户输入用户名和密码。至此,全部启动过程完成。
11.PE文件格式(P34)
PE(Portable Executable,可移植的执行体)是Win32环境自身所带的可执行文件格式。它的一些特性继承自UNIX的COFF(Common Object File Format)文件格式。
可移植的执行体意味着此文件格式是跨Win32平台的,即使 Windows运行在非 Intel的CPU上,任何Win32平台的PE装载器都能识别和使用该文件格式。
当然,移植到不同的CPU上PE执行体必然得有一些改变。除VxD和16位的DLL外,所有Win32执行文件都使用PE文件格式。因此,研究PE文件格式是我们洞悉 Windows结构的良机。
12.一般来说,Win32病毒是怎样被运行的(P35简答)
- 用户点击(或者系统自动运行)HOST程序
- 装载HOST程序到内存中
- 通过PE文件中的ImageBase(优先装载地址即基地址)和AddressOfEntryPoint(代码入口的RVA(偏移)地址)之和定位第一条语句的位置
- 如imagebase:0x40 0000,AddressOfEntryPoint:0x00 12C0,即0x4012c0
- 从第一条语句开始执行(病毒代码可能在此时,也可能在HOST代码运行过程中获得控制权)
- 病毒主体代码执行完毕,将控制权交还给HOST程序
- HOST程序继续执行
13.PE文件结构(P35)

14.病毒如何判断一个文件是不是PE文件(P37)
看文件的前两个字节是不是4D5A(MZ),若不是则说明不是PE文件
若是,在DOS程序头中的偏移3CH处的四个字节找到PE字串的偏移位置,查看该偏移位置的四个字节是不是50 45 00 00(PE…),若不是则不是PE文件,若是则认为它是一个PE文件
15.导出表结构(P43)
导出表:表明自己可以提供哪些函数供别的程序调用,类似于餐厅的菜单

其中AddressOfNameOridinals指向的数组的项目与文件名地址表的项目一一对应,项目的值代表函数入口地址表的索引,这样函数名称就和函数入口地址关联起来了
16.导入表结构(P44)
导入表:记录了一个exe或者一个dll所用到的其他模块导出的函数,类似于自己点的菜的清单
结构中比较重要的为Name:DLL名字的指针如指向user32.dll
第三章 软件缺陷与漏洞机理概述
1.漏洞的分类(P53选择)
- 按漏洞可能对系统造成的直接威胁划分
- 获取访问权限漏洞、权限提升漏洞、拒绝服务攻击漏洞、恶意软件植入漏洞、数据丢失或泄露漏洞等
- 按漏洞的成因划分
- 输入验证错误、访问验证错误、竞争条件错误、意外情况处理错误、设计错误、配置错误、环境错误等
- 按漏洞的严重等级划分可分为高、中、低三个级别
- 远程和本地管理员对应为高,普通用户权限、权限提升、读取受限文件
- 远程和本地拒绝服务对应为中,远程非授权文件存取、口令恢复、欺骗
- 服务器信息泄露对应低级
- 上面只是通常的情况,具体情况要具体分析,如一个广泛使用软件的口令恢复漏洞应该是中或高级
- 按对漏洞被利用的方式划分
- 本地攻击、远程主动攻击、远程被动攻击等
2.CVE、CNVD、CNNVD(P54)
- CVE:MITRE公司建立的通用漏洞列表,将众所周知的安全漏洞的名称标准化,世界最权威的漏洞库。如CVE-2019-0708
- CNVD:国家信息安全漏洞共享平台,类似于补天,厂商和白帽子可以提交漏洞并获得报酬
- CNNVD:中国国家信息安全漏洞库,可以看成中国版的CVE,如CNNVD-202106-1647
3.请列举近3年来和软件缺陷、漏洞相关的重大安全事件(P64)
-
2019年,PHP7的PHP-FPM存在远程代码执行漏洞,导致攻击者可以控制服务器
-
2020年,微软修复了一个有关ECC证书检测绕过的漏洞,攻击者可以伪造签名,影响全球数十亿用户
-
2021年,高通芯片存在缓冲区溢出漏洞,攻击者可以利用该漏洞获取手机用户的短信、通话记录、监听对话等,且无法被常规系统安全功能检测到,影响全球40%的手机
第四章 典型软件漏洞机理分析
1.缓冲区溢出漏洞(P65)
- 缓冲区:指内存空间中用来存储程序运行时临时数据的一片大小有限且连续的内存区域,一般可分为栈和堆,C语言中的数组就是栈缓冲区
- 原理:程序在处理用户数据时,未对其大小做适当的限制,或者在拷贝、填充时没限定边界,导致实际操作的数据大小超过了目标缓冲区的大小,使得一些关键数据被覆盖,从而引发安全问题
- 利用该漏洞,攻击者可植入并执行攻击代码,获得一定的系统权限,从而得到被攻击主机的控制权
2.内存根据进程使用的内存区域的预定功能划分(P66)
- 代码区:存储被装入执行的二进制机器代码,通常只读不可修改
- 静态数据区:存储全局变量,可划分为初始化的数据区和未初始化的数据区
- 动态数据区
- 栈区:存储函数之间的调用关系以及函数内部的变量,保证被调用函数返回时回到父函数中继续执行
- 堆区:程序运行时向系统动态申请的内存空间位于堆区,用完之后需主动释放,如C/C++中的malloc/new
3.系统栈(P67)
- 定义:OS为进程中的每个函数调用都划分了一个栈帧空间,系统栈则是这些函数调用栈帧的集合
- 函数返回地址:函数调用语句的后面一条指令的地址,以便返回时能恢复到被调用前的代码区中继续执行
- ESP:栈指针寄存器,存放的是当前栈帧的栈顶指针
- EBP:基址指针寄存器,存放的是当前栈帧的栈底指针
- EIP:指令寄存器,存放的是下一条等待执行的指令地址
- 当CPU执行完当前的指令后,从EIP寄存器中读取下一条指令的内存地址,然后继续执行
4.栈溢出的利用(P69)
- 修改邻接变量:函数的局部变量依次存放在栈帧中,若其中有数组之类的缓冲区,数组越界后可能破坏相邻变量的值,甚至EBP或返回地址
- 修改函数返回地址:可随意更改程序指向并执行攻击者植入的代码,实现"自主"控制
- 方法1:将内存中的shellcode的地址赋给返回地址
- 但由于动态链接库的装入和卸载,shellcode的地址是动态变化的,因此之后会出现跳转异常
- 且shellcode的开始位置通常为0X00,进行字符串操作如strcpy可能会被截断
- 方法2:用系统动态链接库中某条处于高地址且位置固定的跳转指令所在的地址进行覆盖,指向动态变化的shellcode地址
- 方法1:将内存中的shellcode的地址赋给返回地址
- S.E.H结构覆盖:程序出错之后系统关闭程序之前,让程序转去执行一个预先设定的回调函数
- S.E.H即异常处理结构体,发生异常时(如除零)会用到
- 方法:把S.E.H中异常处理函数的入口地址改为shellcode的地址或可以跳转到shellcode的跳转指令的地址
5.什么是SQL注入,举个例子(P83简答)
攻击者通过把SQL命令插入到Web表单或页面请求的查询字符串,从而欺骗服务器执行恶意的SQL命令,通过提交的参数构造巧妙的SQL语句,从而获取数据库中想要的数据
如判断登录语句,select * from user where username = ‘用户名’ and password = ‘密码’。
如果根据查询到的结果数量判断账号密码是否正确,我们可以构造username=admin’#&&password=test
这样查询语句会变成select * from user where username = ‘admin’#’ and password = ‘test’
由于我们把admin单引号闭合了且加了一个注释符号#,那其实这条语句实际上为select * from user where username = ‘admin’
这样肯定能查到数据也就实现了任意密码都能成功登录
6.什么是跨站脚本(XSS),举个例子(P87)
攻击者嵌入恶意代码到正常网页中,当用户访问该页面时,可导致恶意代码的执行,从而达到攻击用户的目的
如在http://www.test.com/test.php?message=test网址中,用户输入的message信息会显示在当前界面信息内,而如果我们构造message参数值为message=,这样请求页面时就会出现内容为xss的弹框。当然对攻击者更有利的是劫持用户的cookie或重定向到其它恶意网站
第五章 软件漏洞的利用和发现
1.什么是Exploit,分为哪几个部分(P95)
Exploit(漏洞利用程序)是针对某一特定漏洞或一组漏洞而精心编写的漏洞利用程序。其可以触发特定漏洞从而获得系统的控制权。
分为两个部分:被注入到目标进程触发漏洞获得执行权限的二进制串,以及代表攻击者意图的代码
2.可供攻击者利用的漏洞主要来源(P95)
- 黑客自己独享,未被公布、未被修复的漏洞称为0 day漏洞
- 其他黑客发现并公布,可以重现触发漏洞场景的POC代码(验证性代码)
- 安全人员或厂商公布的漏洞补丁或公告,黑客采取补丁对比等技术来定位漏洞,并开发Exploit,主要针对未及时更新补丁的用户,有时也被称为1 day或n day漏洞
3.Exploit结构(P96)
把漏洞利用比作导弹发射过程,Exploit类似导弹发射装置,针对目标发射出导弹(Payload),导弹到达目标后,释放实际危 害的弹头(类似Shellcode)爆炸;导弹除弹头外的其余部分用作定位追踪、引爆等功能对应着Payload的非Shellcode部分。
总的来说,Shellcode用来实现具体的功能,Payload还要考虑如何触发漏洞并让系统去执行Shellcode。因此shellcode往往是通用的,而Payload则是针对特定的漏洞
4.漏洞利用的具体技术(P96)
- 修改内存变量
- 修改代码逻辑
- 修改函数返回地址
- 修改函数指针
- 攻击异常处理机制
- 修改P.E.B中线程同步函数的入口地址
5.什么是shellcode,干什么用的(P97)
Shellcode是一段利用软件漏洞而执行的代码,用来获取shell
6.函数入栈出栈(P105)

上图为书上的原图仅供参考,要搞懂函数入栈出栈的具体流程,具体看综合题
7.常见漏洞挖掘技术的分类(P108)

第六章 Windows系统安全机制及漏洞防护技术
1.GS编译选项(120)
微软在Visual Studio编译器中加入了/GS编译选项,通过向函数的开头和结尾添加代码来阻止针对典型栈溢出漏洞的利用
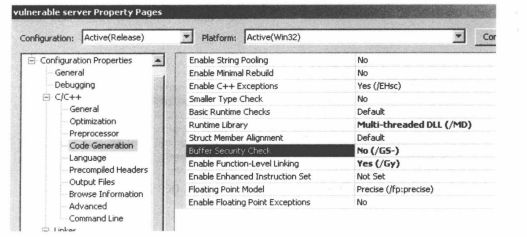

VC++6.0的编译器的设置 如静态加载
(1)直接用project>add to project>files的方式将.lib加入工程
(2)使用#pragma指令,如#pragma comment(lib, “your lib path and name”)
(3)在project>settings>link>input的Additional library path中输入.lib文件所在路径

(4)在project->settting与Tools->Options->Directories指定路径

考试出选择,会放一个设置里的图片让选
第八章 恶意代码及其分类
1.Rootkit(P156)
- 定义:是攻击者用来隐藏自己的踪迹和保留root访问权限的工具。Rootkit一般都和木马、后门等其他恶意程序结合使用(为统一,此处为恶意代码教材的定义)
2.流氓软件也称灰色软件,特点如下(P156)
强制安装、难以卸载、浏览器劫持、广告弹出、恶意收集用户信息、恶意卸载、恶意捆绑
3.僵尸程序(P126)
僵尸(bot)程序是指实现恶意控制功能的程序代码。
僵尸网络:指采用一种或多种传播手段,将大量主机感染僵尸程序,从而在控制者和被感染主机之间形成一对多的控制的网络。攻击者可利用此发起DDOS攻击或发送垃圾邮件
4.Exploit(P158)
Exploit(漏洞利用程序)是针对某一特定漏洞或一组漏洞而精心编写的漏洞利用程序。其可以触发特定漏洞从而获得系统的控制权。可分为主机系统漏洞Exploit、文档类漏洞Exploit、网页挂马类Exploit
第九章恶意代码机理分析
1.计算机病毒的特点与分类 (P161背)
- 传播性
- 非授权性
- 隐蔽性
- 潜伏性
- 破坏性
- 不可预见性
- 可触发性
2.Windows PE病毒的感染技术(P170)
- 病毒感染重定位:病毒随着不同HOST程序载入内存后,病毒的各个变量在内存中的位置会随着HOST程序的大小不同而发生变化,因此病毒必须对病毒代码中的变量进行重定位
- 获取API函数地址:病毒代码没有引入函数机制的支持,所以病毒必须自己获取API函数的地址。首先获得Kernel32的基地址,再从Kernel32中得到API函数的地址
- 添加新节感染:常见感染文件方式是在文件中添加一个新节,然后往新节中添加病毒代码和病毒执行返回HOST程序的代码,并修改文件中代码开始执行位置(AddressOfEntryPoint)指向新添加的病毒节的代码入口,使程序运行后先执行病毒代码
3.Rootkit常用技术(P221)
- 用户态HOOK:主要钩挂一些用户态的API函数
- IAT(导入地址表)钩子:IAT的每个表项存储着程序所引用的其它动态链接库文件中函数的地址,改变IAT表项的值使其指向我们的HOOK函数,即可完成钩挂操作。
- 若程序采用LoadLibrary和GetProcAddress来代码动态定位函数地址,IAT钩子将会失效

- 内联钩子:重写目标函数(如DLL模块中的目标函数)的代码字节,因此无论是函数正常引用机制还是通过代码动态定位函数地址,都能成功
- IAT(导入地址表)钩子:IAT的每个表项存储着程序所引用的其它动态链接库文件中函数的地址,改变IAT表项的值使其指向我们的HOOK函数,即可完成钩挂操作。
- 内核态HOOK:内核钩子是全局的且和防护软件一样都处于Ring0级更难被检测
- IDT(中断描述符表)钩子:IDT指明了每个中断处理进程的地址,通过修改这个表可在发生中断调用时改变正常执行路径
- SSDT(系统服务调度表)钩子:在系统服务调用过程中,会在内核态查找此表来找到系统服务函数的地址,通过修改此表便可钩挂系统服务函数
- 过滤驱动程序:几乎所有硬件都存在驱动程序链,将Rootkit驱动程序挂接到原有的驱动程序链中,即可截获传送的数据,并对其进行修改
- 驱动程序钩子:每个设备驱动程序中包含一个用于处理IRP(I/O请求包)请求的函数指针表,修改这个表使其指向Rootkit函数,即可完成钩挂
- 直接内核对象操作(DKOM):直接修改内核记账和报告所用的一些对象。DKOM很难被检测但并不能实现Rootkit的所有功能,只能对内存中用于记账的内核对象进行操作
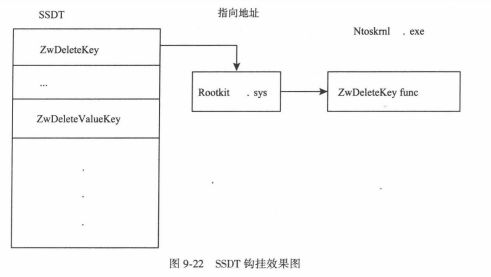


4.进程隐藏技术(P224简答)

进程隐藏思路(如隐藏my.exe):在用户态下,两个位置可以可用来隐藏进程,一个是psapi.dll中的EnumProcess函数,另一个为ntdll.dll中的原生API函数ZwQuerySystemInformation,钩挂这两个函数既可以用IAT钩子的方法,也可使用内联钩子的方法。
在核心态下用来隐藏的位置也有两个:修改系统服务表(SSDT)中ZwQuerySystemInformation的表项和直接修改内核中记录进程信息的结构
5.文件隐藏技术(P227)

文件隐藏思路(如隐藏my.txt):用户态下可通过FindFirstFile和FindNextFile来进行文件隐藏。内核态下通过修改系统服务表(SSDT)中ZwQueryDirectoryInformation对应的表项即可完成挂钩。
6.通信隐藏技术(P229)

通信隐藏思路(如隐藏端口):SSDT钩挂ZwDeviceIoControlFile:首先调用ZwDeviceIoControlFile,设置Inputbuffer的参数,判断OutputBuffer中每个实体的tae_ConnLocalPort是否是隐藏的端口,若是,则删除此条实体,便实现了端口隐藏。钩挂TCPIP.sys驱动程序:IRP会向诸如netstat.exe等程序返回端口列表,只需对这样的IRP做相应处理即可隐藏端口
7.注册表隐藏技术(P322)

注册表隐藏思路(如隐藏注册表中的U盘):通过索引查询注册表的函数是ZwEnumerateKey,对注册表键的索引就是改变相对的索引。获取注册表键值信息的函数是ZwEnumerateValueKey,与隐藏注册表键的原理一样
8.Rootkit检测原理及工具(P236)
- 一般通过检测是否存在某种类型的钩子以此判断是否存在Rootkit
- 查找SSDT钩子:查找名称为ntoskrnl.exe,查找超过ntoskrnl.exe范围之外的地址
- 查找内联钩子:给一个SSDT的一个函数地址,查找是否存在jmp,解析CPU要跳转的目的地址,检查这个地址是否超过了ntoskrnl.exe的可接受范围
- 查找IAT钩子:遍历每个DLL的每个IAT以检查是否存在任何钩子,特别要注意Kernel32.DLL和NTDLL.DLL,因为它们是进入OS的用户空间接口
- 经典的Rootkit检测工具:IceSword和XueTr
第十章 病毒检测技术及检测对抗技术
1.特征值检测病毒的思路(P249简答)
(1)采集已知的病毒样本:即使是同一种病毒,感染不同类型的宿主时,一般也需进行不同样本的采集
(2)从病毒样本提取特征值:特征值应足够特殊且控制在合适长度。可采用把病毒在计算机屏幕上出现的信息作为特征值或将病毒的标识作为特征值
(3)将特征值纳入病毒特征数据库:使用扫描引擎实现病毒特征的匹配,打开被检测文件,进行二进制检索,检查是否含有病毒特征数据库中的病毒特征值,以此可判断文件是否染毒、染有何种病毒
特征值检测方法的优点:检测准确,可识别病毒的特征,误报率低,并且依据检测结果可做解毒处理
第十一章 恶意软件样本捕获与分析
1.什么是蜜罐,用途是什么,举例说明(P275)
蜜罐通常是指没有采取安全防范措施且主动暴露在网络中的计算机,其内部运行着多种多样的行为记录程序和特殊用途的"自我暴露程序",相当于一个恶意软件样本收集池。
利用蜜罐可以监控网络攻击行为、收集攻击工具和恶意代码、分析攻击方法、推测攻击意图和动机,甚至还可能根据蜜罐收集到的蛛丝马迹追踪到攻击者
2.恶意软件样本捕获方法(P275)
- 蜜罐:见上面知识点
- 用户上报:个人用户发现恶意软件后主动上报给安全研究人员
- 云查杀平台上传:通过分布在全球的大量客户端获取可疑程序的最新信息,并主动上传到服务器,但存在个人隐私问题
- 诱饵邮箱:主动注册大量邮箱,定期收取电子邮件,从其中得到部分流行的恶意软件样本
- 样本交流:部分反病毒公司之间合作或反病毒人士分享恶意软件样本
3.恶意软件样本分析(P278)
- 虚拟机环境准备
- 系统监控:使用systeminternal即可
- 包含进程监控(Process Explorer)、文件监控、注册表监控、网络连接分析、系统自启动项分析、内核监控、完整性检测
第十三章 软件自我保护技术
1.花指令(P305)
-
定义:软件作者可能会在代码中加入一些特殊数据来扰乱反汇编程序,使其无法正确的转化出真实的反汇编代码,这些特殊的数据被称为花指令。
-
反汇编主要有两种算法
- 线性扫描算法:依次逐个将每一条指令都反汇编成汇编指令
- 花指令模式为跳转指令+干扰代码,跳转指令典型的有0FH和0E8H
- 递归进行算法:模拟CPU的执行过程,根据控制流(代码可能的执行顺序)来反汇编,对每条可能的路径都进行扫描
- 对付线性扫描算法的方法对它没用,需要引导反汇编工具将特定花指令数据当做控制流程中的指令片段进行反汇编,如通过无效跳转进行错误引导
- 线性扫描算法:依次逐个将每一条指令都反汇编成汇编指令
2.如何检测调试器是否存在(P312简答)
(1)查找是否有调试器进程
(2)查找调试器进程或文件的特征码
(3)查找特定的调试器服务
(4)查找调试器窗口
(5)句柄检测
(6)检测DBGHELP模块
(7)SeDebugPrivilege方法
可能会出的简答汇总
1.可信计算的基本思想
2.请你大致写出计算机的启动过程
3.一般来说,Win32病毒是怎样被运行的
4.什么是SQL注入,举个例子
5.进程隐藏技术
6.特征值检测病毒的思路
7.如何检测调试器是否存在