Linux基础知识学习()
一、Linux的磁盘分区及目录
Linux的配置是通过修改配置文件来完成。
1.1、Linux磁盘分区
Linux可以将磁盘分为多个分区,每个分区可以被当做一个独立的磁盘使用,磁盘类型:主分区、扩展分区、逻辑分区。
主分区标记为活动,用于操作系统的引导,一块磁盘最多划分4个主分区,主分区存放操作系统的文件或用户数据。
扩展分区:主分区小于4个时才可以划分扩展分区,一块磁盘最多有一个扩展分区,扩展分区不能保存任何数据,必须在扩展分区中进一步划分逻辑分区,用户数据只能保存在逻辑分区中。
逻辑分区:扩展分区中可以建立多个逻辑分区。
Linux中大多数硬件都是以文件的方式进行管理,这些硬件设备被映射到”/dev”目录下对应的文件中,在‘/dev’目录下每个磁盘分区映射为一个文件,这些文件采用字母加数据的形式,如:
/dev/xxyN
其中的xx表示区名所在磁盘的设备类型,一般hd代表IDE接口的磁盘,sd代表SCSI或SATA即可的磁盘(光盘驱动器及U盘),fd代表软盘驱动器,tty是一种字符型的终端设备ttySn是串口设备。“y”表示分区所在的磁盘是当前接口的第几个设备比如第一个SCSI硬盘就是“/dev/sda”,第二个SCSI硬盘就是“/dev/sdb”。“N”表示分区的序号,前四个分区(主分区或扩展分区)使用1-4表示,逻辑分区从5开始。
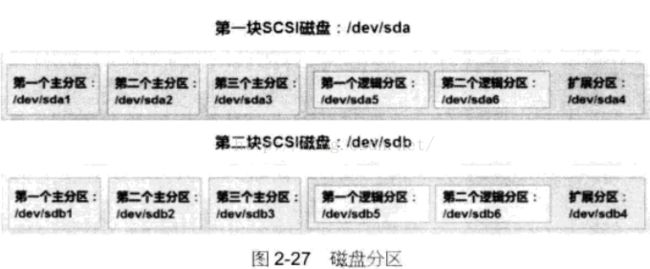
分区完成后,用户并不能直接使用这些分区,需要格式化后再通过 mount命令挂载后才能使用,如使用mount命令将“/dev/sdb2”挂载到“/mnt/disk”目录,所有保存到/mnt/disk目录下的数据就会被保存到/dev/sdb2分区中。
1.2、Linux文件系统及目录结构
文件系统是一种存储和组织计算机文件及数据的方法,文件系统通常使用硬盘和光盘的存储设备,并维护设备中的物理位置。
Linux操作系统默认操作FAT、FAT32两种文件系统,默认情况下不支持NTFS系统,推荐使用ext3(第三版的扩展文件系统)文件系统。ext3是一种日志文件系统,在对系统数据进行写操作前,会把写操作内容写入一个日志文件中,一旦操作被意外中止,系统能够在重新启动时根据日志完成该写操作。
Linux文件系统中,文件是存储信息的基本结构。文件、目录、硬件设备都以文件的形式表示,文件名可以由字符、数据、原点、下划线组成,长度不超过256个字符。Linux中通过圆点区分文件名和扩展名帮助用户区分文件类型,用户可以根据自己需要随意假如自己的扩展名。Linux中有4种文件类型:普通文件,如文本文件、图片文件、视频文件、shell脚本文件;目录文件:特殊的文件;链接文件;特殊文件;
文件系统采用树形的结构。
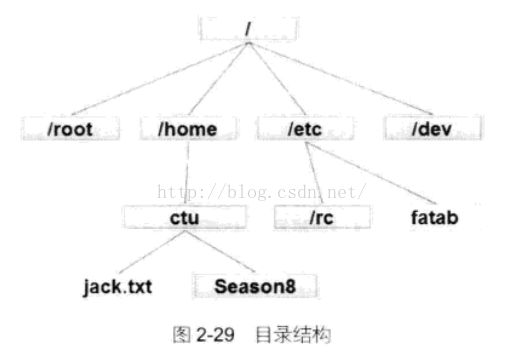
Linux中每个用户有个家目录,如果是管理员(root用户)家目录是/root,若是普通用户家目录是/home。路径,从一个目录到另一个目录或文件的道路被称为路径,“.”表示当前目录,“..”当前目录的父目录,“~”当前用户的家目录,“-”上一个目录。
二、常用命令
poweroff:关闭系统 reboot:重启计算机 clear:清除终端显示 pwd :显示当前目录 cd:改变当前目录 . :表示当前目录 .. : 表示当前目录的父目录 ~“”表示home目录
- 上一个工作目录
mv :移动命令 cp:复制命令 rm:删除命令 mount:挂载命令 chamod:改变权限命令
cat:打印命令 mkdir:新建文件夹 lsmod:查询设备
netstate -nl :查看网络状态 netstate -nlu :查看UDP状态
ifconfig 查看网络配置 ifconfig -a:所有的网卡 ifconfig eth0 up/down 打开或关闭eth0设备 ifconfig 可以用来配置IP和网络掩码。 ping:查看网络是否通 date:查询时间 date -s :修改系统时间 cal:日历
man 命令:查看命令的使用方法。 kill 进程号:结束一个进程
2.1、vim命令
命令模式,启动后默认处于该模式,其他模式用ESC键或者Ctrl+C切换到命令模式。
插入模式,和txt文档编辑一样编辑,在命令模式下用i、o、a命令进入该模式。
可视模式,该模式下可用方向键进行内容选择,然后进行复制、粘贴和其他操作,在命令模式下使用v进入该 模式。
块操作模式,该模式下可用方向键进行内容选择,选择时可模拟鼠标选择的方式。在命令模式下使用ctrl+v进入该模式
修改模式,该模式下,类似于其他软件用insert键来完成切换。命令模式下用R进入该模式。
扩展命令模式,该模式下可以执行一些扩展命令。命令模式下使用‘:’进入该模式。
vim几种操作选择:“o” 可以只读方式打开该文件,“e”可正常编辑,使用该方式注意确定其他用户没有正在编 辑这个文件,“r”从临时交换文件中回复,“q”退出编辑该文件,“a”放弃并同时撤销后续命令的执行,“d”删除临时交换文件。
文件编辑完成,希望关闭需要首先切换到命令模式,击中退出方式::q 直接退出,:q!强行退出,如果文件内容发生改变则不保存,:wq保存并退出,:wq!强行保存并退出,一般用于文件是只读的情况下,但是文件的拥有者是当前用户。
2.2、Vim常用的操作键
命令模式常用的操作键:
G:移动到文件的最后一行
nG:n为数字,移动到文件的第n行。
/word: 向下查找关键字word
?word: 向上查找关键字word
n:重复前一个查找
N:反复重复前一个查找
:n,$s/a/b: 替换第n行开始到最后一行中每一行的第一个a为b。
:n$s/a/b/g: 替换第h开始到最后一行每一行所有的a为b,n位数字,若n为.表示从当前行开始到最后一行
d$: 删除光标所在位置到该行最后一个字符。
dd: 剪切当前行。
yy: 复制所选内容
nyy: 复制从光标开始n行内容
p: 将已经复制的内容粘贴到光标下一行。
P: 将已经复制的内容粘贴奥光标上一行。
u: 复原上一个操作。
ctrl+R: 重复前一个操作。
o: 当前下插入空行,并进入插入模式。
O: 当前下插入空行,并进入插入模式。
. : 重复前一个动作。
i : 进入插入模式,从当前光标所在位置插入。
I : 插入模式,从当前行第一个非空格处插入。
r : 插入模式,替换光标所在字符。
R: 进入修改模式。
ESC键:返回命令模式。
(2) 扩展命令模式常用操作键
:w —- 保存。
:w! —- 文件为只读时强制保存,不过能否保存还要看文件的权限。
:q —- 离开vim。
:q! —– 强制退出。
:wq ——- 保存后离开。
:x —— 保存后离开。
:w[文件名] —– 另存为新文件。
v ———- 进入可视模式。
ctrl+V —— 进入块操作模式。
:r[文件名] —– 将文件名的文件读到光标后面。
n1,n2 w[文件名] —– 将n1到n2另存为新文件
:new —– 新增水平窗口
:new filename — 新增水平窗口,并在新增的窗口加载filename文件。
:v new —– 新增垂直窗口。
:v filename —– 新增垂直窗口,并在新增窗口加载filename文件。
ctrl+W+方向键 —- 切换窗口。
:only —- 紧保留目前的窗口。
:set nu —– 显示行号
:set nonu —- 不显示行号
:set readonly —– 文件只读,除非使用!可写。
:set ic —- 查找是忽略大小写。
:set noic —- 查找时不忽略大小写。
三、桌面环境
Linux的桌面图形界面有很多种,GNOME KDE Fluxbox Xfce FVWM sawflish WindowMaker等,最常用的是GNOME和KDE两种。
3.1、远程管理
Telnet协议是Internet远程登录服务的标准协议,提供了在本地计算机上完成远程主机工作的能力,用户可以在Telnet程序中输入命令,这些命令会在远程服务器上运行。传统的Telnet安全性差,许多服务器会将Telnet服务关闭,使用更安全的SSH。
ubuntu 开启Telnet服务步骤, http://www.linuxdiyf.com/linux/17355.html
SSH是Secure Shell 的缩写,为建立在应用层和传输层上的安全协议,SSh对所传数据进行加密保证了数据的安全而且数据是经过压缩的提高了传输速度。SSH可以代替Telnet,又可以为TFP、POP提供一个安全通道。
Linux及windows客户端通过SSH链接到服务器的方法:
(1) Linux客户端
Linux客户访问SSH服务器通过以下几个命令完成:
① ssh [-CflRv] [用户名@] SSH服务器 [命令] ,
SSH服务器指定要链接的服务器,可以使用FQDN或IP地址。
用户名@:指定链接SSH服务器的用户名,不指定用户时默认以root用户链接。
命令:使用ssh命令可以链接到服务器,有时需要在SSH服务器上执行一个命令时,可以直接通过此 参数指定需要执行的命令。
-C:启用压缩功能
-f: 在询问密码之后且在执行[命令]之前,将ssh转到后台运行。
-L:将本地系统中的某个端口转发到远程系统。
-R: 将远程系统 的某个端口转发到本地端口
-v: 显示与连接和传送有关的调试信息。
例如: ssh 192.168.159.11 通过ssh连接到远程计算机,默认使用root用户。如果是第一次连接到远 程计算机,本地主机的用户需要生成连接远程主机的RSA公钥,在此出现的警告输入yes。退出远程 连接服务器,输入exit。
② SCP命令可以使用SSH的方式在远程主机和本地主机复制文件或目录,语法如下,
scp [-Cpqrv] [[用户名@]复制源主机:]复制源文件[[用户名@]复制目标主机:][复制目标文件]
如果是windows客户端,可以用putty。
(2) RDP
在Windows中可通过“远程桌面”功能连接到远程的计算机进行管理。
四、Linux命令基础
4.1、Linux命令分类
Linux操作系统中,命令分为两种:Shell内部命令、Shell外部命令。
Shell内部命令:shell内部命令是一些较为简单的又常用的命令,如cd、mkdir、rm等,这些命令在shell启动时载入内存。
Shell外部命令:Linux中大多数命令属于外部命令,每一个shell外部命令都一个独立的可执行程序,也就是shell的外部命令是一些实用工具程序,管理员可以独立的在shell环境下安装或卸载这些shell外部命令。
Linux的内部命令可以在任何目录任何时间执行,而外部命令在执行时,Linux必须找到对应的可执行程序。Shell中一个名为PATH的环境变量,该变量包括一些路径用于shell自动搜索。
cat /etc/shells 来查看系统中的shell种类。
Shell中的引号分为三种:单引号,双引号,反引号
由单引号引起来的符号都作为普通字符出现。特殊字符用单引号引起来后,失去原来的意义,变为普通字符解释。
双引号的作用与单引号类似,区别在于没那么严格,单引号忽略所有的特殊字符,双引号中的3中特殊字符不被忽略 $ \ ‘。
反引号· 位于键盘的左上角,被反引号引起来的被shell解释为 命令行
用#做注释。
4.2、Linux命令格式
Shell解释器在用户和内核之间相当于一个翻译的角色,负责解释用户输入的命令。shell是操作系统和用户进行交互的界面。命令的基本格式:
命令 [选项] [参数]
命令是需要执行的操作,选项是对命令的要求,参数用于描述命令的作用对象。比如 ls -l /root ,命令是ls,选项-l表示要以长格式显示文件信息,/root 是 ls的命令参数,表示ls命令作用的对象是 /root目录。
五、Linux的目录及文件管理
5.1、Linux的主要目录
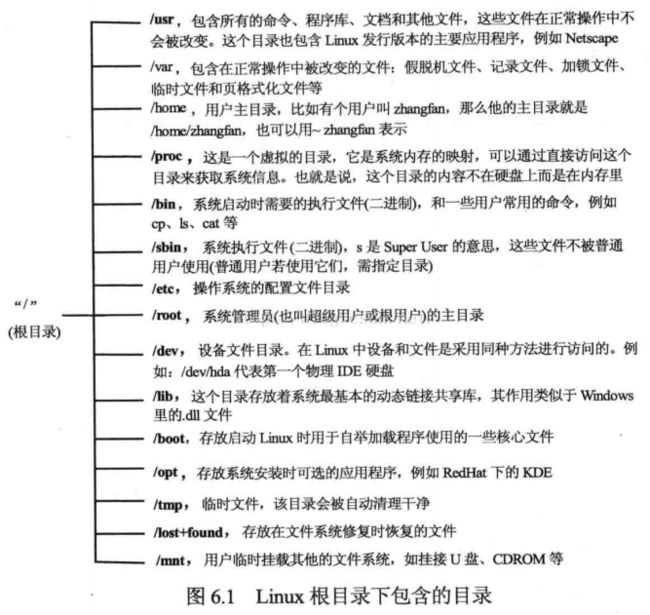
/ :根目录,一台计算机只有一个根目录,所有内容都是从跟目录开始。如/etc ,先从根目录开始在进入etc目录
/root:系统管理员的家目录。
/bin:存放了标准的Linux工具,如ls、cp、rm等。该目录已经包含在PATH中,使用该目录程序无需使用路径
/boot:用于加载程序的文件。
/proc:操作系统运行时,进程信息及内核信息,如果CPU、硬盘分区、内存信息等存放在该目录。
/etc:存放系统的配置方面的文件,如在系统安装vsftpd这个软件,你想要修改vstpd配置文件的时候,vstpd的配置文件就在/etc/vstpd目录下。
/etc/init.d 存放系统或以system V模式启动的服务脚本。
/etc/xinetd.d: 如果服务是通过xinetd模式运行的,服务的脚本要放在这个目录下。
/etc/rc.d : 存放BSD方式启动脚本,如定义网卡开启脚本等。
/etc/X11:存放X-Windows相关的配置文件
/dev :主要存放与设备(包括外设)有关的文件。
/home :存放每个用户的家目录。每个用户的设置文件,桌面文件夹、用户数据都放在这里。
/tmp :临时目录。
/bin、/usr/bin:大部分系统命令都是二进制文件形式保存。一般用户使用的命令都在这两个目录,系统核心命令工具,如cd、ls、cp、等都在/bin目录。如Web浏览器为于/usr/bin目录,可以与其他用户共享使用。
/sbin、/usr/sbin :存放root用户的命令文件。
/usr/local :用于存放手动安装的软件。
/usr/share:存放系统共用的文件。
/usr/src:存放内核源码的目录。
/var :存放一些经常变化的文件。
/var/log:存放系统的日志。
/opt:存放那些可选的程序。
/lib:系统的库文件
/lost+found:在文件系统中,系统意外崩溃或意外关机时,产生的一些文件碎片放在该目录。
/mnt : 存放挂在存储设备的挂载目录。
/meia:有些发行版使用这个目录来挂载那些USB接口的移动硬盘,CD/DVD驱动器等。
5.2目录结构及操作命令
Linux系统中,以.开头的文件名表示该文件是隐藏文件, ls命令用于显示指定目录的内容,语法:
ls [-anruhtFS1R] –time=
[目录…]:指定要显示内容的目录或目录缩写,如果需要显示多个目录,可在目录名之间使用空格
-a:显示包括影藏文件在内的所有文件及目录。
-n:使用UID和GID代替用户名显示文件或目录所有者和拥有者。
-r:反向排序。
-u:以最后存取时间排序,显示文件和目录。
-h:使用k、M、G为单位,提高信息可读性。
-t:根据文件和目录最后修改时间的顺序显示文件和目录。
mkdir 创建目录,语法如下
mkdir [-p] [-m<目录属性>] 目录名称…
目录名称:需要创建的目录,若需建立多个目录,可在目录名之间使用空格分隔。
-p:如果要建立的目录父目录没创建,则一起建立父级目录。
-m:建立目录时,同时设置目录权限,权限设置方法与chmod命令相同。
5.3、文件操作命令
建立目录是为了有效分类管理文件。
touch:改变文件或目录时间
file:识别文件类型。 Linux系统文件的扩展名只是为了方便使用者识别文件类型,对系统本身没有任何意义。file命令可以识别文件类型,语法如下
file [-bcLz] {-f<文件名>}文件|目录
cp:复制文件或目录。将目录或文件复制到另一个目录,语法如下:
cp [-abdfilprsuv] [-S<备份字符串>] 源文件或目录 目标文件或目录
rm:删除文件或目录,语法如下:
rm [-filrv] 文件或目录
mv:移动或更名现有的文件或目录
mv [-fiub] [-S<备份字符串>] 源目录或文件 目标目录或文件
ln:链接文件或目录,语法如下:
ln [-bdfis] [-S<备份字符串>] 源文件或目录 [链接文件]
locate:查找文件或目录,语法如下
locate 查找内容
该命令只会在保存文件和目录名称的数据苦衷查找。查找内容使用*表示任意字符,?表示任何一个字符。例如tony*zhang ,locate命令会查找以tony开始以zhang结尾的文件或目录。
which:查找文件,语法如下:
which [文件]
该命令只会在PATH环境变量中定义的 路径及命令别名中查找。
whereis:查找文件,语法如下:
whereis [-bu] [-B<目录>] [-M<目录>] [-S<目录>] [文件…]
find :查找文件或目录
gzip:压缩文件,语法如下:
gzip [-cdf1Nnqtvr] [-压缩比] [–bast|–fast] [-S<压缩字尾字符串>] 要压缩的文件
bzip2:压缩文件,语法如下:
bzip2 [-cdfktvz] [-压缩比] 要压缩的文件
tar:压缩备份,可以将多个文件合并为一个文件,打包后文件的扩展名为.tar,默认情况下不压缩tar文件,可以通过选项在打包同时进行压缩。
zip/uzip:ZIP文件压缩与解压。
不同文件的压缩和解压缩:
.zip
解压:unzip filename.zip
压缩:zip filename.zip dirname
.rar
解压:rar -x filename,rar
压缩:rar -a filename.rar dirname
.tar.gz或tgz
解压:tar -zxvf filename.tar.gz
压缩:tar -zcvf
5.4、文本查看命令
cat:显示文件内容,语法如下
cat [-bEsT] [文件..]
head:显示文件内容的最前部分。如法如下:
head [-qv] [-c<显示数目>] [-[n]<显示行数>] [文件…]
tail:显示文件内容的末尾部分
tail [-fqv] [-c<显示数目>] [-[n]<显示行数>][文件..]
more :逐页显示文件内容
grep 查找并显示符合条件的内容,语法如下:
grep [-aciInqvwxE][-显示行数][-e<范本样式>][-f<范本样式>][-d<进行操作>][范本样式][文件或目录]
六、用户及组管理方式
用户组有两种:初始组、额外组。每个用户必须属于一个初始组,可以同时加入多个额外组。Linux将每个用户看做一个32位的整数,这个整数就是UID。Linux内部运作大部分都是使用UID,给人看时才会把UID转换为用户名。有三种用户类型:一般用户、超级用户(root)、系统用户。
每个用户对应一个UID,每个组对应一个UID,建立用户时默认建立一个与用户名相同名称的组,组的GID和用户UID相同。
Linux中所有信息都是通过配置文件的方式保存,用户及组也是。
七、软件的安装及管理
7.1、常见软件安装方式
绿色软件:无需安装直接可以使用。
提供安装程序的软件包:在软件包内提供了install.sh、setup.sh等安装程序或以.bin格式单个执行文件提供 deb方式:deb是Debian软件格式包,文件扩展名.deb,经gzip和tar打包而成,处理这些包的经典程序是dpkg,通过apt来运行。
RPM格式:RPM是在Linux洗广泛使用的软件管理器,RPM仅适用于安装用RPM来打包的软件。
源码方式:使用源码自己通过自己编译生成二进制文件的软件安装方式。
八、Shell脚本
bash Shell 支持在交互模式中一次提交多个命令执行,有三种方法:使用分号隔开、&& 条件隔开,只有前一个命令成功执行时才执行下一个命令、||条件隔开,只有在上一个命令执行失败后才执行下一个命令。
8.1、标准输出重定向
(1) 使用>将输出写入文件,如果指定文件已存在将会删除文件中原来的内容。如:ls /boot > boot.txt
(2) 使用>> 将输出追加到文件,如果指定的文件已存在将会把输出附加到文件中。
8.2、标准错误重定向
(1) 使用2> 将输出写入文件,如果指定的文件已经存在将会删除文件中原来的内容。
(2) 使用2> 将输出追加到文件
8.3、Shell脚本
脚本是为了缩短传统的“预处理-编译-汇编-链接-运行”过程而创建的计算机编程语言。脚本通常是解释运行而非编译。Shell脚本是按行解释的,每个Shell脚本对系统来说就是一个文本文件,在有相应权限下可以使用文本编辑器建立修改Shell脚本文件。
虽然在Linux中扩展名并没有实际作用,但是为了阅读方便,脚本文件一般用sh作为扩展名。
一行中“#”之后的内容表示是注释,注释在执行过程中被忽略。
Shell脚本文件的第一行应该指定向哪个解释器发送指令,“#!/bin/sh”
在执行已编好的脚本时可以使用两种方式:对于有执行权限的脚本文件可以使用“./<文件名>”的方式执行,对于没有执行权限的脚本可以使用“sh<文件名>”的方式执行。
Linux系统中每个进程都是有寿命的,所有进程都是应另个进程的请求而启动,发出请求的进程成为父进程,新启动的进程成为子进程。子进程完成自身任务退出,子进程退出后会返回一个信息给父进程,叫做返回值或退出状态,返回值是一个0~244之间的整数,进程返回0表示执行成功,任何非0都表示某种形式的失败。shell 中把上一个命令的返回值保存在一个名为“ ?”的特殊变量中。可以使用“echo ? ” 的 特 殊 变 量 中 。 可 以 使 用 “ e c h o ?”显示上一个命令是否执行成功。
8.3.1、变量
变量就是会变化的量,Shell允许用户设置和引用shell变量,shell 变量可以用在命令和脚本中,也可以被其他程序作为配置选项而引用。Shell变量有两种类型:环境变量和局部变量。环境变量由子shell继承,局部变量只存在于创建的shell中。每个变量都有一个名称,变量的名称可以是字母字符及下划线组成不能以数字开头。Shell在使用变量钱不需要专门的语句进行定义也不对变量区分数据类型,本质上所有的shell变量都是字符串,shell也运行比较和算术操作。
(1) 局部变量
局部变量的建立和赋值直接使用“变量名=变量值”的 方式。例如变量名strA,值为ctu
strA=ctu
变量赋值可以使用双引号单不是必须的: strA=“ctu”
变量定义之后,用户在不注销的情况下任何时间都可以使用已定义的变量,在使用时必须在变量名前加一个 .例如显示局部变量:echo . 例 如 显 示 局 部 变 量 : e c h o strA.
(2)、环境变量
Linux中允许全体进程使用“变量名=变量值”的方式定义被称为环境变量的变量。环境变量是保存在内核进程中的一部分,无论何时开启一个进程,子进程都会继承环境变量。用户也可以创建环境变量,环境变量的创建分两步,首先定义一个局部变量,然后使用“export”命令将局部变量提升为环境变量。
set命令显示已经定义的变量
env命令显示已定义的环境变量
“unset<变量名>”清除变量 unset strA
8.4、向脚本传递参数
脚本中可以使用“ 1”接收传递给脚本的第一个参数,“ 1 ” 接 收 传 递 给 脚 本 的 第 一 个 参 数 , “ 2”接收第二个参数,可以使用“ ∗”接收所有的参数,使用“ ∗ ” 接 收 所 有 的 参 数 , 使 用 “ 0”获得当前脚本的名称、使用“#”获取传递给脚本的参数个数,使用“ #”获取传递给脚本的参数个数,使用“ $”获得当前脚本的PID。
8.5、流程控制
程序语言一般都是从上向下执行代码,shell通过判断和循环改变脚本的顺序执行。
(1)、判断结构
if、then、else语句提供测试条件,语法如下:
if<条件>; then
#条件为真时执行的内容
fi
if<条件>;then
#条件为真时执行的内容。
else
#条件为假时执行的内容。
fi
if<条件1>;then
#条件为真时执行的条件
elif<条件2>;then
#条件2为真时执行的内容。
else
#前两个条件都为假时执行的内容。
fi。
if语句都必须以fi终止,elif、else是可选的。
(2) case判断结构
case 值 in
模式1)
# 符合模式1时执行的内容
;;
模式 2)
#符合模式2时执行的内容
; ;
esac
其中;;相当于C语言中的break。如果无匹配模式使用星号*匹配该值,再接收其他输入,相当于default。*表示任意字符,?表示任意单字符。
循环结构
bash shell 支持三总类型的循环:for循环一次处理循环体内容直到循环耗尽,until循环直到条件为真前一次执行循环体内的内容,while循环直到条件为假前一次执行循环体内的内容。
while[条件]
do
循环体
done
until [条件]
do
循环体
done
for((初始值;限制值;步长))
do
循环体
done。
有两种方法退出或路过循环:(1)break 用于跳出循环,break直接跳出循环,执行循环后边的,如果是循环嵌套使用break默认是跳出当前循环,也可以指定跳出循环的个数break 2 跳出两套循环。(2)continue 跳出本次循环,执行新一轮的循环。
8.6、函数
function 函数名
{
#函数内容
}
函数可以放在同一个文件中作为一段代码,也可以放在只包含函数的单独文件中,使用函数时像执行脚本一样传入参数。在函数体内容也可以用 1 1 2的方式传入参数。
九、Linux引导及进程管理
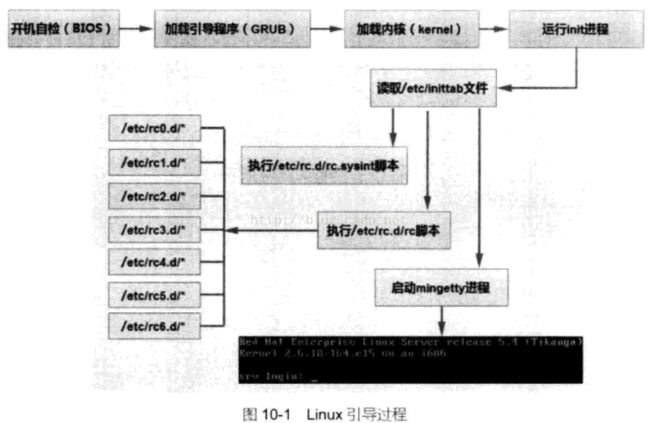
10.1、加载引导程序
BIOS自检最后一步中BIOS把磁盘的第一个数据块(MBR,Master Boot Record)装入内存,并把执行传递这个区域,分为两个阶段执行
(1) 第一阶段,引导程序很小,唯一任务就是定位、装载并把控制权传递给第二阶段的引导程序,这段程序在MBR中所以在文件系统中找不到。
(2)第二阶段,引导程序本身,能够读取有关默认设备的配置信息。第二阶段应道程序通常是文件系统中可识别的二进制文件,完成以下任务:编写合适内核命令行,用于引用正确的根分区;装载合适的初始虚拟磁盘;装载合适的Linux内核并将控制权交给内核。
Ubuntu使用的引导程序是GRUB,GRUB是GNU项目的操作系统引导程序,在/boot/guab目录下,主要配置文件是/boot/grub/grub.conf文件。
GRUB加载内核参数并把控制权交给内核后,Linux内核将完成以下操作:(1) 运行init进程,Linux内核启动的第一个进程就是/sbin/init,这个命令是系统启动时由内核执行的,因此其进程ID(PID)永远是1,只要系统运行init进程就会一直运行,init进程也是系统中最后一个被终止的进程,该进程不接收SIGKILL 信号。init进程功能是启动、停止、监控其他进程。init启动时会读取配置文件/etc/inittab. inittab文件开机是执行,如果改变过了该文件需要重启。用runlevel查看运行级别。
启动时登录shell首先读取脚本文件/etc/profile,该脚本初始化各种环境变量如PATH、HOSTNAME。
10.2、Linux内核模块
内核是操作系统的核心组成部分,主要两个功能:一是充当资源管理器,向进程透明分配内存、CPU访问等资源;二是充当解释器,在进程和硬件之间专递信息。
内核一般使用模块和硬件设备交流,每个模块代码都单独放在一个目标文件中,可以根据需要加载和删除内核模块,内核模块位于/lib/modules/ (uname−r)目录中,用ls/lib/modules/ ( u n a m e − r ) 目 录 中 , 用 l s / l i b / m o d u l e s / (uname -r)查看和管理模块。
lsmod 命令显示当前加载到内核的模块。
modprobe 装载内核模块
rmmod 从内存中删除内核模块
10.3、/proc 目录
proc文件系统是一个伪文件系统,只存在内存中,不占用硬盘空间。
10.4、进程的状态:可运行、自愿休眠、非自愿休眠、挂起的进程、僵尸进程。
free 查看内存状态。
ps 查看进程。
pstree 以树状查看进程
top 显示、管理执行中的程序。
十一、网络管理
Linux内核可以检测出所有链接的PCI设备,可以使用lspci命令验证计算机上的pci设备是否被内核检测到。Linux内核不允许用户以文件的形式访问网卡,也就是在/dev目录下无直接关联网卡的设备节点。Linux通过网络接口访问网卡,并以类似eth0的方式命令,其中字母表示数据连接技术,eth(以太网)、ppp(ppp协议的串口设备)、fddi。
ifconfig命令可以检验所有已识别的网络接口命令。
ifconfig eth0 可以只显示网络接口0的网络信息。
ifconfig eth0 down 禁用以太网0接口
ifconfig eth0 up 启用以太网0接口
11.1、静态路由配置
IP协议以使用路由器连接在一起的机器构成的网络为基础,所有连接到单一IP网络上的机器都有相似的IP地址,并通常使用相同的网络交换机。
每个Linux内核都会有个路由表,路由表从来确定对于一个发送出的数据包,内核使用哪种方法传递数据包,路由表定义了哪个网络接口与本地网络的关系,以及本地网络上充当链接外边网络的机器的身份标识。“Flags”列有G的表示的是网关。
route 命令查看路由表
route -n 路由表按IP地址来显示。
route add default gw IP ,增加新的网关
route del default gw IP ,删除网关
11.2、ARP配置
ARP协议(地址解析协议),基本功能是通过目标的IP地址,查询目标的MAC地址,ARP是IPv4网络层中不可缺少的,IPv6中不再适用。
arp 查看arp
11.3、网络测试
ping测试两台主机之间底层IP联通性
ping IP 直接pingIP地址。
nsloopup 检查DNS查询结果
网络抓包工具wireshark
十二、DHCP
DHCP(动态主机配置协议),是一种网络管理员能够集中管理和自动分配IP网络地址的通信协议。
十三、GCC编译器和GDB调试器
GCC编译器是GNU开源组织发布的Linux下多平台编译器,将多种语言编写的源程序编译、链接成可执行文件,GDB是调试器。
13.1、链接库
函数库实际上是一些头文件(.h)或者库文件(.so或者.a)的集合。Linux下大多数头文件的默认路径是/usr/include,库文件默认路径是/usr/lib/,有时候使用GCC编译时需要为其指定所需要的头文件和库文件的路径。
GCC采用搜索目录的方法查找所需要的文件,-I选项可以向gcc头文件搜索路径中添加新的目录,假如在当前目录下编写了foo.c,而在/home/yang/include/目录下有编译改程序时所需要的头文件(不是在/usr/include/目录下),为了使GCC能够顺利找到,可以使用I选项:
gcc foo.c -I /home/yang/include -o foo
如果使用了不在标准库位置的库文件,可以使用-L选项向gcc库文件搜索路径中添加新的目录,假如在/home/yang/lib/目录有foo.c所需要的库文件。
gcc foo.c -L /home/yang/lib -lfoo -o foo
编译命令中,-l选项,指示gcc去链接库文件libfoo.so,库文件命名时有一个约定,以lib三个字母开头,因此在用-l选项指定链接库文件名时省去了lib三个字母,也就是说gcc对-lfool进行处理时,会自动搜索libfoo.so文件。
Linux下库文件分为两大类:动态链接库(以.so结尾)和静态链接库(通常以.a结尾),区别是所需的代码是在运行时动态加载的还是编译时静态加载的。默认情况下gcc链接时优先使用动态链接库,只有在动态连接口不存在时才考虑使用静态链接库。如果链接库里同时有libfoo.so libfoo.a两个库文件,为了使用静态库文件,使用如下命令:
gcc foo.c -L /home/yang/lib -static -lfoo -o foo
13.2、同时编译多个源程序
如果一个程序有多个源文件组成,foo1.c foo2.c foo3.c 对他们编译生成foo可执行程序,命令如下:
gcc foo1.c foo2.c foo3.c -o foo 等价于下列命令:
gcc -c foo1.c -o foo1.o
gcc -c foo2.c -o foo2.o
gcc -c foo3.c -o foo3.o
gcc foo1.o foo2.o foo3.o -o foo
13.3、管道
GCC生成可执行文件时,需要经过预处理、编译、汇编、链接,几个步骤,而且每个步骤都需要一个临时文件来保存信息,当源文件很多时将会增加系统的开销,可以使用管道来减小开销,
gcc -pipe foo.c -o foo
十四、make的使用和makefile的编写
make工程管理器是Linux下的一个“自动编译管理器”,“自动”是指它能够根据文件的时间戳,自动发现更新过的文件而减少程序编译的工作量,它通过读入Makefile文件的内容来执行大量的编译工作。
make机制的运行环境需要一个命令行程序make和一个文本文件Makefile。make是一个命令工具,用来解释makefile的命令。
假如一个程序 由main.c foo1.c foo2.c foo3.c 组成,makefile文件内容:
all: main.c foo1.c foo2.c foo3.c
gcc main.c foo1.c foo2.c foo3.c -o all
这5个文件应当存放在Linux的同一个目录下,使用make进行自动编译的时候,它会在这个目录下找到makefile文件,在存放文件的目录下输入make命令进行编译。
make是一个Linux下的二进制文件,自动寻找名称为Makefile的文件作为编译文件,如果没有则寻找makefile文件作为编译文件。
make操作管理Makefile文件的规则:
(1) 如果这个工程没有编译过,那么所有C文件都需要被编译和链接。
(2) 如果这个工程的某几个C文件被修改,则只需编译被修改过的C文件,并连接目标程序。
(3) 如果这个工程的头文件被修改了,则需要编译引用这个头文件的C文件,并连接至目标程序。

反斜杠“\”为换行符,某一条规则或命令不能在一行中写完时,可以用它表示换行。5.2程序可以保存为当前目录下的Makefile文件或makefile文件,或makefile文件夹下的文件,在该目录下直接输入命令make就可以自动生成可执行文件all,如果要删除可执行文件和所有的中间目标文件,执行make clean 命令就可以了。
在Makefile中,目标名称指定有以下惯例(当然可以不适用这些惯例):
all:表示编译所有内容,是执行make时默认的最终目标。
clean:表示清除所有的目标文件。
disclean:表示清除所有内容。
install:表示进行安装的内容。
5.2所示Makefile中,目标包含如下内容:最终可执行文件all和8个中间文件*.o;依赖文件即每个冒号后边的那些.c和.h文件,每个.o文件都有一组依赖文件,这些.o文件又是最终all的依赖文件,依赖关系及说明目标文件是由哪些文件生成。定义好依赖关系,后续的代码定义了生成目标的方法,注意一定要以一个Tab键做为开头。
14.1、makefile的书写规则
makefile书写包含两个:一个是依赖关系,一个是生成目标的方法。
makefile中的命令必须以tab键开头。
Makefile中的变量就像是c C++中的宏,代表了一个字符文本,在Makefile执行的时候就会展开,变量可以使用在目标、依赖目标,命令或是makefile的其他部分中。
变量的命名可以包含字符、数字、下划线(可以是数字开头),但是不能有 ‘:’’ #‘ ‘ =‘或是空格、回车,变量名区分大小写。变量在声明时需要给予赋初值,使用时需要在变量前边加上“ ”符号,最好用小括号“()”或花括号""把变量给括起来。如果要使用真实的“ ” 符 号 , 最 好 用 小 括 号 “ ( ) ” 或 花 括 号 " " 把 变 量 给 括 起 来 。 如 果 要 使 用 真 实 的 “ ”字符,那么需要用”$$”


除了使用“=”给变量赋值外,Makefile还支持嵌套定义,例如

执行make all 将会输出 Huh?,Makefile变量的这个特性有利有弊,好处是可以把变量真实值推到后面来定义如:
CFLAGS=$(include_dirs) -O
include_dirs=-Ifoo -Ibar
当CFLAGS在命令中被展开时,会是 -Ifoo -Ibar -O ,使用这种形式的弊端就是递归定义可能会出问题如:
A=$(B)
B=$(A)
这会让make陷入无限循环的变量展开过程中去,make有能检测这样的定义,并报错,为了避免无限循环,定义了另外一种变量“:=”如:
x :=foo
y :=$(x) bar
x :=later
等价于
y := foo bar
x := later
“:=”操作符,使得前边的变量不能使用后面的变量,只能使用前面已经定义好了的变量,如果是这样:
y:=$(x) bar
x :=a
那么y的值是bar 而不是 a bar
“?=”操作符:foo?=bar,如果变量foo没有被定义过,那么变量foo的值就是bar,如果foo被定义过,那么这条语句什么都不做。等价于
ifeq($(origin foo),undefined)
foo=bar
endif
另外一种操作符“+=”给变量追加值,如:
objects= main.o foo.o
objects +=another.o
等价于
objects= main.o foo.o
objects := $(objects) another.o
define 关键字:使用define关键字设置变量的值可以有换行,define指示符后面是变量的名字,另起一行定义变量的值,定义是以endef关键字结束,define中的命令也都是以Tab键开头,否则make将不把它当做命令。
define two-line
echo foo
echo $(bar)
endef
十五、文件的IO操作
有关I/O操作分为两类:基于文件描述符的IO操作,基于流的IO操作。
Linux中,文件提供了简单并一致的接口来处理系统服务与设备,所有的内容都被看成文件,所有的操作都可以归结为对文件的操作。操作系统可以像处理普通文件一样来使用磁盘文件,串口,键盘,显示器,打印机及其他设备。

普通文件:文本文件、二进制文件。普通文件可以直接查看,二级制文件不能打开。
目录文件:只有root用户能写目录文件,其他用户只能读。
设备文件:为操作系统和IO设备提供链接的一种文件,Linux把设备的IO作为普通文件读取和写入,操作内核提供对设备处理和对文件处理统一的接口,每个IO设备都对应一个设备文件,存放在/dev目录 中。
链接文件:提供了一种共享文件的方法。
管道文件:用于进程间传递数据,是进程间通信的一种机制。
套接口文件:在不同计算机的进程间通信也叫套接字。套接字是操作系统内核中的一个数据结构,是网络中节点进行通信的关键。套接字有三种类型:流式套接字,数据报套接字,原始套接字。流式套接字也就是TCP套接字(面向连接的套接字),数据报套接字也就是UDP套接字(无连接的套接字),原始套接字用“SOCK_RAW”表示。
15.1、文件描述符
Linux用文件描述符来访问文件,文件描述符是一个非负整数,用于描述被打开的文件索引值。当内核打开或新建一个文件时,就会返回一个文件描述符。文件描述符0与标准输入相结合,文件描述符1与标准输出相结合,文件描述符2与标准出错相结合。POSIX中用STDIN_FILENO STDOUT_FILENO STDERR_FILENO来代替0、1、2.这三个符号常量位于头文件unistd.h

15.2、文件重定向
shell提供一种方法,任何一个或这三个描述符都能重定向都某一个文件,而不是默认的输入或输出设备。如:
ls>file.list



15.3、文件的创建、打开与关闭
对一个文件操作,首先要求这个文件存在,其次在操作之前将这个文件打开,这样才能对文件进行操作,操作完成后,必须将文件关闭。
(1) open 函数可以打开或创建一个文件,函数说明如下:
#include
#include
#include
int open(const char *pathname ,int flags) ; //打开一个现在文件
int open(const char *pathname ,int flags,mode_t mode); // 打开的文件不存在,则先创建它
返回:若成功,返回文件描述符,若出错返回-1.
参数pathname是一个字符串指针,它指向需要打开(或创建)文件的绝对路径或相对路径名。
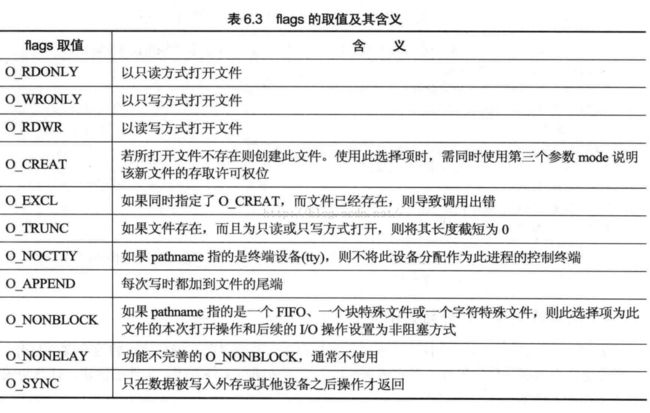
参数flags用于描述打开文件的方式,如下表所示,定义在fcntl.h头文件中,flags的值可以由表中取值逻辑或得到。O_RDONLY,O_WRONLY,O_RDWR这三个参数只能出现一个。
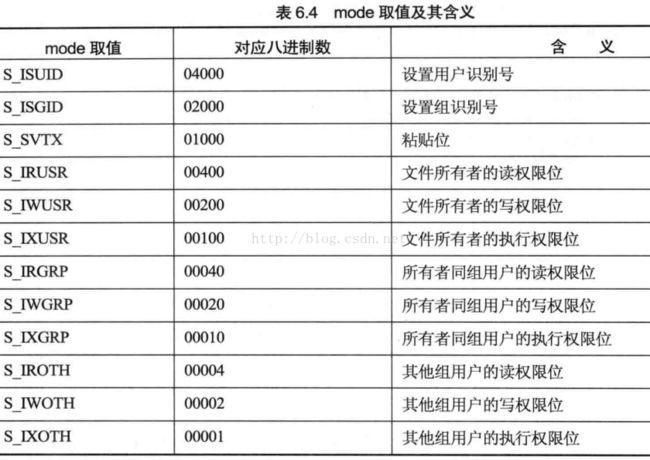
参数mode用于指定所创建文件的权限,使用按位逻辑或的方法进行组合。

创建文件creat()函数,函数原型如下:
#include
#include
#include
int creat(const char *pathname,mode_t mode);
返回:若成功,返回以只写方式打开的文件描述符,若出错返回-1. 参数pathname和mode与open函数的意义相同。
create等效于:open(pathname,O_WRNOLY|O_CREAT|O_TRUNC,mode);
creat的不足之处是以只写的方式打开所创建的文件,如果要创建一个临时文件,并要先写该文件然后读该文件,则必须先调用create、close,然后再调用open 。
(3)close函数
close函数用于关闭一个文件,函数说明如下:
#include
int close(int fd);
返回:若成功返回0,出错返回-1.参数fd是需关闭文件的文件描述符。
(4) 文件的定位
每个打开的文件都有一个与其相关联的“当前文件位移量”,它是一个非负整数,用以度量从文件开始处计算的字节数。打开一个文件时,除非指定O_APPEND选择项,否则该位移量被设置为0.可以调用lseek函数显示的定位一个打开文件,函数说明如下:
#include
#include
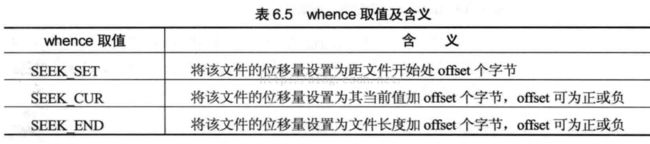
off_t lseek(int fd,off_t offset,int whence); 返回:若成功,返回新的文件位移量,若出错为-1.“lseek”l表示长整型。
fd:文件描述符,offset 表示位移量大小单位字节,
(5) read函数
读写是文件操作的核心内容,实现文件的IO操作必须进其进行读写。read函数说明如下:
#include
ssize_t read(int fd ,void *buff,size_t count);
返回:读到的字节数,若已读到文件尾返回0,若出错返回-1.
fd,文件描述符,buff存放读取的字节,count要读取数据的字节数。
读操作从当前位移量处开始,在成功返回之前,该位移量增加实际读得到的字节数。多种情况实际读到的比要读的少:
读普通文件时,在读到要求的个数字节之前读到了文件末尾,比如读到文件末尾读了30个字节,要求读100个字节,则read返回30,下一次再调用read时返回0.
从终端设备读时,一次最多读一行。
当从网络读时,网络中的缓冲机构可能造成返回值小于要求读的字节数。
某些面向记录的设备,例如磁带,一次返回一个记录。
(6) write函数
用write函数向打开的文件写数据,函数说明如下:
#include
ssize_t write(int fd,void *buf,size_t count);
返回:通常与count值相同,否则出错。
对于普通文件,写操作从文件的当前位移量开始。如果打开文件时指定了O_APPEND选择项,则在每次写操作之前,将文件的位移量设置在文件的结尾处。
od -c 文件名路径,查看该文件的实际内容,命令行中的-c表示以字符的方式打印文件内容。
15.4、文件的属性
Linux的文件系统具有比较复杂的属性,包括文件访问权限、文件所有者,文件本身,文件长度等。
(1) 改变文件的访问权限
chmod、fchmod 这两个函数可以改变现存文件的权限。
#include
#include
int chmod(const char *pathname,mode_t mode);
int fchmod(int fd,mode_t mode);
chmod函数在指定文件上进行操作,pathname是绝对路径或相对路径;fchmod对已经打开的文件进行操作,fd是文件描述符, mode是权限。
shell中直接用chmod命令改变文件权限 比如 chmod 755 文件绝对路径或相对路径。
(2) 改变文件所有者
用户可以调用chown 、fchown 、和lchown 来改变一个文件所有者识别号和组识别号。
#include
#include
int chown(const char *pathname,uid_t owner,gid_t group);
int fchown(int fd,uid_t owner,gid_t group);
int lchown(const char *pathname,uid_t owner,gid_t group);
三个函数若成功返回0,失败返回-1. pathname 绝对路径或相对路径,owner 新的拥有者, group 新的组。
chown 修改指定文件的所有者和组。
fchown 修改已经打开的文件的所有者和组。
lchown 针对符号链接文件。
(3) 重命名
一个普通文件或者一个目录文件都可以被重命名,rename函数如下:
#include
int rename(const char *oldname,const char *newname);
返回:若成功返回0,若出错返回-1. rename参数会将oldname所指定文件名称改为参数newname所指定的文件名称,若newname存在则会删除。oldname和newname指向同一个文件时不会做任何修改。
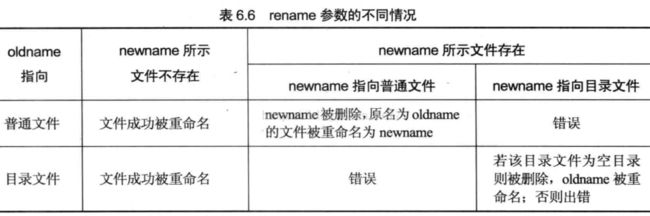
不能将一个目录文件重命名为它的子文件。
(4) 修改文件的长度
stat结构体成员st_size 包含了一字节为单位的文件的长度,此字段只对普通文件、目录文件和符号链接文件有意义。
对于普通文件,其文件长度可以是0.
对于目录文件,文件长度通常是一个数,例如16或512的整数倍。
对于链接文件,文件长度是在文件名中的实际字节数。
截短文件可以调用函数truncate 和ftruncate,说明如下:
#include
#include
int truncate(const char *pathname,off_t len);
int ftruncate(int fd ,off_t len);
返回:若成功返回0,若出错返回-1.
15.5、 文件的其他操作
(1) stat、fstat、lstat函数
Linux系统中所有的文件都有一个对应的索引节点,该节点包含了文件的相关信息,这些信息保存子啊stat结构体中,可通过这三个函数进行查看。
#include
#include
int stat(const char *pathname,struct stat *sbuf);
int stat(int fd,struct stat *sbuf);
int lstat(const char *pathname, struct stat *sbuf);
返回:成功返回0,出错返回-1.

头文件
(2) dup dup2函数
这两个函数用来服装一个现存的文件描述符。
#include
int dup(int fd);
int dup2(int fd,int fd2);
(3) fcntl函数,可以改变已经打开的文件的性质。
15.5、特殊文件的操作
(1) 创建目录 mkdir
(2) 删除空目录 rmdir
(3)opendir closedir readdir
十六、基于流的IO操作
流IO是C语音的标准库提供的,这些IO可以代替系统中提供的read和write函数。
流和FILE对象:上一章对IO操作是基于文件描述符的,打开文件返回文件描述符,然后基于文件描述符对文件进行操作。对于标准的IO库,操作则是基于流进行。用标准的IO打开或创建一个文件是,已经使一个流和一个文件相结合。
打开一个流时,标准IO函数fopen返回一个指向FILE的指针。对流的IO操作类似对文件描述符的IO操作,调用fopen函数打开一个文件,并返回一个FILE指针,流成功打开后,就可以调用标准IO进行操作 。当完成操作后,需要执行清空缓冲、保存数据等操作。然后将流关闭,如果不关闭流,可能造成数据的丢失,fclose().
16.1、标准输入、标准输出、标准出错
使用流IO时,会自动打开标准输入、标准输出、标准出错。文件描述符用STDIN_FILENO STDOUT_FILENO STDERR_FILENO 来表示,这三个符号常量在
基于流IO是,通过预定义文件指针,stdin stdout stderr来引用标准输入、标准输出、标准出错的,定义在头文件
16.2、 缓存
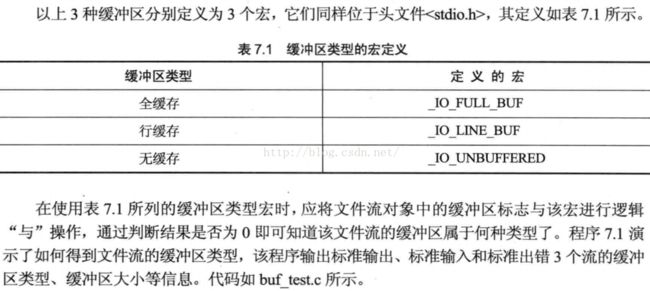
基于流的操作最终会调用read和write函数进行IO操作。为了尽可能减少使用read和write函数的次数,流对象通常会提供缓冲区(缓存),标准IO提供了3中类型的缓存:
全缓存:直到缓冲区被填满,才调用系统IO函数。
行缓存:直到遇到换行符“\n”才进行IO操作。
无缓存:数据会立即读入或输出到外存文件或设备上。
16.3、设置缓存的属性
缓存具有自己的属性,包括缓冲区的类型和缓冲区的大小。调用fopen打开一个流时,就开辟了缓冲区,系统会赋予其一个默认的属性值。也可以根据自己需求来设定缓冲区的属性值,调用如下函数:
#include
void setbuf(FILE *fp,char *buf);
void setbuffer(FILE *fp,char *buf,size_t size);
void setlinebuf(FILE *fp);
int setvbuf(FILE *fp,char *buf,int mode,size_t size); 返回:0 成功,非0 失败
这四个函数对流属性进行操作,操作对象是一个已经打开的流。
fp 指向FILE结构体的指针。
setbuf 用于将缓冲区设置为全缓存或无缓存,参数buf执行缓冲区的指针。buf指向一个真实缓冲区地址时,此函数将缓冲区设置为全缓冲,大小由预定义常数BUFSIZ指定,当buf为NULL时,设置为无缓冲,此函数,当做激活或禁止缓冲区的开关。
setbuffer的功能和使用方法与setbuf类似,区别是有程序员指定缓冲区的大小,由size确定。
setlinebuf 用于将缓冲区设定为行缓存。
setvbuf 比较灵活,fp buf size含义与setbuffer函数相同,mode用于指定缓冲区类型,_IOFBF全缓存、_IOLBF 行缓存、_IONBF 无缓存。三个常量在
最好在打开流还没对流操作之前,设置流的属性。
16.4、缓存的冲洗
冲洗,就是将IO操作写入缓存中的内容清空,清空可以是将缓存区内容丢掉也可以是保存到文件中,相应库函数如下:
#include
int fflush(FILE * fp);
#include
void fpurge(FILE *fp);
fflush函数将缓存区尚未吸入文件的数据强制性写入文件中,成功返回0,失败返回EOF。
fpurge函数,用于将缓冲区中的数据完全清除。
16.5、流的打开与关闭
对一个流操作之前,先将他打开,也就是建立某一个流同某个文件或设备的关联,只有这样才能对这个流进行操作。打开流函数如下:
#include
FILE *fopen(const char *pathname,const char *type);
FILE *freopen(const char *pahtname,const char *type,FILE *fp);
FILE *fdopen(int fd,const char *type);
三个函数若成功返回文件指针,若出错则为NULL。
三个函数的区别有以下几点:
fopen 打开一个文件由pathname指定文件。
freopen 在一个特定流(有fp指示)打开一个指定的文件(路径名有pathname指示),若该流已经打开则先关闭。此函数用于将一个指定的文件打开为一个预定义的流:标准输入、标准输出,或标准出错。
fdopen 取一个现存的文件描述符,并使一个标准的IO流与该描述符相结合。此函数常用于由创建管道和网络通信通道函数获得的描述符,因为这些特殊类型文件不能使用标准的IOfopen函数。
type参数,指定了该IO流的读写方式,该值以一个字符串的形式传入。
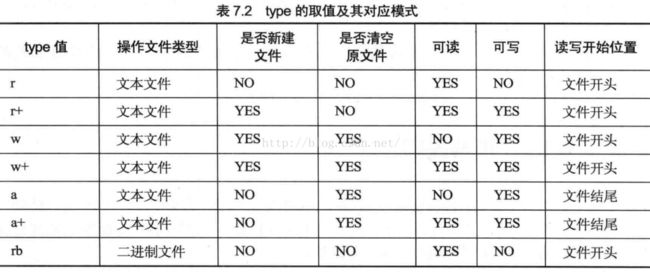
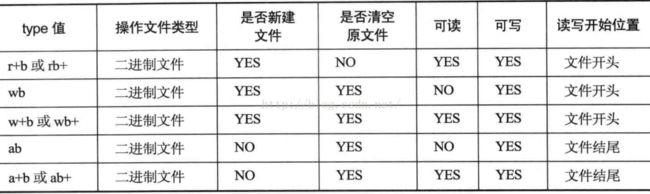
type 取值字符串中包含 a的表示 追加写,即流打开以后,文件的读写位置在文件的末尾。type 字符串中包括字母b的表示流以二进制的形式打开,其他的则表示以文本的形式打开。对于Linux系统来说没有意义,因为Linux系统下,二进制文件和文本文件都是普通文件,是字节流。
fopen打开成功返回文件指针,若出错则返回NULL,出错原因有以下三种:
指定路径有错误
type参数是一个非法的字符串
文件的操作权限不够。
fdopen函数用在一个已经打开的文件描述符上打开一个流。与fopen不同,由于文件已经打开,fdopen不会创建文件,也不会将文件截短为0.
(2) 流的关闭
在所需的操作完成以后,必须将流关闭。fclose用于关闭一个流,函数如下:
#include
int fclose(FILE *fp);
若成功则返回0,若失败则返回EOF(-1,定义在stdio.h)。
对流的操作完成后,必须关闭它,大多数流的操作都是基于缓冲机制的,fclose在关闭流之前会将缓冲区的内容写入文件或者设备。fclose如果关闭的是本地文件,出错的几率很小,如果关闭的是一个网络环境中的远程文件,fclose函数就有可能出错,这时就要检查返回值了。
15.6、流的读写
打开了流,则可在4种不同类型的IO进行选择,对其进行读、写操作。
基于字符的IO:每次读写一个字符数据的IO方式,如果流是带缓存的,则由标准IO函数处理所有缓存。
基于行的IO:当输入内容遇到‘\n’换行符的时候,则将换行符之前的内容送到缓冲区IO中的方式成为基于行的IO。
直接IO:输入输出操作以记录为单位进行读写。
格式化IO:printf scanf 函数。
(1) 基于字符的IO
基于字符的IO通常是处理单个字符的。以下3个函数用于读入一个字符:
# include
int getc(FILE *fp);
int fgetc(FILE *fp);
int getchar(void);
返回:若成功则返回读入字符的值,若已处文件尾端或出错则为EOF。
前两个函数中,参数fp表示要读入字符的文件,getc可被实现为宏,fgetc不能实现为宏。getc的参数不能是具有副作用的表达式。(副作用表达式:通过++ 等操作改变参数的值)
getchar只能用来从标准输入输出流总输入数据,相当于调用以stdin为参数的getc函数即,getc(stdin) 。
这三个函数以unsigned char 类型转换为int的方式返回下一个字符。
(2) 字符的输出
以下三个函数用于字符的输出:
#include
int putc(int c FILE *fp);
int fputc(int c ,FILE *fp);
int putchar(int c);
返回: 若成功则为C,若出错则为EOF。
putc和fputc第一个字符表示要输出的字符,第二个参数表示输出的文件,如果成功输出一个字符,则返回输出的字符,若出错则返回EOF。
与输入函数一样,putchar(c)等同于putc(c,stdout);putc可被实现为宏,fputc不能实现为宏。
(3) 基于行的IO
当输入内容遇到‘\n’换行符的时候,则将流中\n之前的内容送到缓冲区的IO方式成为基于行的IO。
行的输入:
fgets和gets函数实现输入一行字符串,函数如下:
#include
char *fgets(char *buf,int n,FILE *fp);
char *gets(char *buf);
返回:若成功返回缓冲区首地址,若已处文件尾或者出错则为NULL。
fgets函数的第一个参数表示存放读入串的缓冲区,第二个参数n表示读入字符个数,不能超过缓存区长度。fgets函数一直读知道遇到一个换行符为止,如果在n-1个字符内未遇到换行符,最后一个字节用于存放字符串结束标志\0 ,fgets函数会将换行符存入缓冲区。
gets函数从标准输入读取一行并将其存入一个缓冲区。
行的输出:
fputs和puts 函数实现输出一行字符串,函数原型如下:
#include
int fputs(const char *buf,FILE *restrict fp);
int puts(const char *str);
fputs第一个参数表示存放输出内容的缓冲区,第二参数表示要输出的文件。成功返回输出的字节数,失败返回-1.
puts 用于向标准输出输出一行字符串。
(3)直接IO
字符读写和行的读写函数是以一个字节或一次一行的方式进行IO操作,比如一次读或写整个机构,为了使用getc或putc,必须循环整个机构,一次读或写一个字节,fputs遇到null或换行符字节就停止, 二进制IO操作解决了这个问题:
#include
size_t fread(void *ptr,size_t size,size_t nmenb,FILE *fp);
size_t fwrite(void *ptr,size_t,size_t nmenb,FILE*fp);
ptr 缓冲区指针,size 目标文件的大小,nmemb 欲读取或写入的字节个数,fp文件指针。
格式化的IO:
格式化IO是IO最常见的IO方式,比如printf 和scanf
格式化输出有4个printf函数:
#include
int printf(const char *format,…);
int fprintf(FILE *fp,const char *format,…);
两个函数的返回,若成功返回实际输出的字节数,若出错为负值。
int sprintf(char *st,const char *fromat,…);
int snprintf(char *st,size_t size,const char *format,…);
格式化输入的3个scanf函数:
#include
int scanf(const char *format,…);
int fscanf(FILE *fp,const char *format,…);
int sscanf(char *str,const char *format,…);
十六、进程控制
进程是一个程序的一次执行过程,程序是进程的一种静态描述,系统中运行的每个程序都是在它的进程中运行的。进程:在自身虚拟空间运行的一个单独的程序。进程的要素:有一段程序供进程运行,专用的系统堆栈空间,进程控制块(task_struct),独立的存储空间。进程缺少一个要素时,我们成其为线程。
Linux系统中所有的进程都是由一个进程号为1的init进程衍生而来的。Linux有3中进程:交互进程(shell)、批处理进程,监控进程(守护进程)。
每个进程在创建时都会被分配一个数据结构,成为进程控制块(process control block ,PCB)。PCB包括一些信息:进程标识符,进程当前状态,进程相应的程序和数据地址,进程资源清单,进程优先级,CPU现场保护区,进程同步与通信机制,进程所在队列PCB的链接字,与进程相关的其他信息。进程ID(PID)是一个非负整数范围 0–32767,Linux的专用进程:ID 0 是调度进程,常常成为交换进程。ID1 是init进程,UNIX早期版本中是/etc/init 新版本是/sbin/int。该进程负责在内核自举后启动一个Unix系统。inti通常读与系统有关的初始化文件/etc/rc*,并将系统引导到一个状态,init进程不会终止。一个或多个进程合起来构成进程组,一个或多个进程组合起来构成一个会话。这样可以对进程进行批量操作。
ps 查看自己系统中目前有多少个进程,ps -aux 列出系统中进程的详细信息。
Linux 提供getpid函数来返回系统当前前程的PID,函数如下:
#include
#include
pid_t getpid(void);
16.1、进程的控制是通过函数调用实现的,其中包括系统调用函数也包括库函数。接下来学习进程的创建、等待、终止等具体操作的相关函数调用。
(1) fork 和vfork 函数
创建一个进程,最基本的系统调用是fork,系统用fork派生一个进程,函数如下:
#include
#include
pid_t fork(void);
返回: 若成功,父进程中返回子进程ID,子进程中返回0,若出错返回-1.
fork的作用是复制一个进程。子进程是父进程的复制,即子进程从父进程得到了数据段和堆栈的复制,这些需要分配新的内存,而只读的代码段,通常使用共享内存的方式访问。
fork函数的用途:一个进程希望复制自身,从而父子进程能执行不同段的代码,进程想执行另外一个程序。创建新进城后会返回给父进程子进程的ID,因为没有一个函数得到一个父进程所有子进程的ID,子进程返回0,因为子进程可以通过调用getppid()函数得到父进程的 pid。在fork之后是进入父进程还是子进程不确定。
Linux中创建新进程的方法只有一个,就是fork ,system()最后调用的也是fork。
另一个创建进程的方法vfork,函数如下:
#include
#include
pid_t vfork(void);
返回和fork一样:父进程中返回子进程的ID,子进程返回0,返回-1错误。
fork和vfork区别:fork要复制父进程的数据段,vfork不需要完全复制父进程的数据段,在子进程没有调用exec或exit之前,共享数据段。fork不对父子进程的执行顺序进行任何限制,在vfork调用中,子进程先运行父进程挂起,子进程调用exec或exit之后父进程的执行次序才不再有限制。
(2) exec() 函数
Linux使用exec函数来执行新的程序,以新的子进程完全代替原有的进程,exec是一个函数族,指的是一组函数,一共有6个:
#include
int execl(const char *pathnaem,const char *arg,…);
int execlp(const char *filename,const char *arg,…);
int execle(const char *pathname,const char *arg,…,char *const envp[]);
int execv(const char *pathname, char *const argv[]);
int execvp(const char *filename,char *const argv[]);
int execve(const char *pathname,char *const argv[],char *const envp[]);
返回:若成功无返回值,若出错 -1
函数命中含有字母“l”的,其参数个数不定,参数由所调用程序的命令行参数列表组成,最后一个NULL表示结束。
函数名中含有字母“v”的,则是使用一个字符串数组指针argv指向参数列表,这一字符串数组和含有字母“l”的函数中的参数完全相同,同样以“NULL”结束。
函数名中含有字母“p”的函数可以自动在环境变量PATH指定的路径中搜索要执行的程序,因此它的第一个参数为filename,表示可执行函数的文件名。而其他函数需要用户在参数列表中指定该程序路径,所以其第一个参数为pathname。
函数名中有字母“e”的,比其他函数多含有一个参数envp,这是一个字符串数组指针,用于指定环境变量。调用函数execle,execve 时,用户自行设定子程序的环境变量,存放在参数envp所指定的字符串数组中,这个字符串数组也必须由NULL结束。其他函数则是接收当前环境变量。
execve才是真正意义上的系统调用,其他都是在此基础上经过包装的库函数。exec函数族作用是根据指定的文件名找到可执行文件,并用它来取代调用进程的内容,也就是在调用进程内部执行一个可执行文件。这里的可执行文件既可以是二进制文件,也可是任何Linux下可执行的脚本文件。
exec函数族的函数执行成功后不会返回,因为调用进程的实体,包括代码段,数据段和堆栈等都已经被新的内容取代,只是进程ID等一些表面上的信息保持原样。如果调用失败了,才会返回-1,从原程序的调用点接着往下执行。
当有程序认为不能做贡献了,它可以调用任何一个exec,让自己以新的面貌重生。普遍情况是,如果进程想执行另一个程序,它就可以fork一个新进程,然后调用任何一个exec,这样看起来好像通过执行应用程序而产生了一个新进程一样。
fork调用进程的数据段和堆栈会复制到新的子进程,而fork之后我们调用exec函数会将复制过来的东西会被抹掉,很浪费时间,于是设计了一种copy on write技术,fork结束后并不立即复制父进程内容,到了真正实用的时候才复制。
理解exec:
实际的main函数 int main(int argc,char *argv[],char *envp[]);
参数argc指出了运行该程序时命令行参数的个数,数组argv存放了所有命令行参数,数组envp存放了所有的环境变量。环境变量指的是一组值,从用户登录后就一直存在,很多应用程序需要依靠它来确定系统的一些细节,最常见的环境变量是PATH,它指出了应到哪里去搜索应用程序,如/bin HOME也是比较常见的环境变量,她指出了我们在系统中的 个人目录。环境变量一般以字符串“XXX=xxx”的形式存在,XXX表示变量名,xxx表示变量值。
argv数组和argvp数组存放的都是指向字符串的指针,这两个数组都以一个NULL元素表示数组的结尾。
(3) exit()和_exit() 函数
系统调用是用来终止一个进程的,执行到exit系统调用,进程就会停止剩下的所有操作,清除包括PCB在内的各种数据结构,并终止本进程的运行,函数原型:
#include
_exit()函数用于正常终止一个程序,函数原型:
#include
void _exit(int status);
status取值:0 表示没有意外的正常结束;其他数值表示出现了错误,进程非正常结束,实际编程时可以用wait系统调用接收子进程的返回值。
区别:_exit()立即进入内核,exit先执行一些清除处理(包括调用执行终止处理程序,关闭标准的IO等)然后进入内核。
一个进程调用了exit后,该进程并不马上消失,而是留下一个成为僵尸进程的数据结构,不占用内存。
(3) wait 和waitpid 函数
#include
#include
pid_t wait(int *status);
pid_t waitpid(pid_t pid,int *status,int options);
若成功返回进程ID,失败返回-1。
进程一旦调用了wait,就立即阻塞自己,有wait自动分析是否当前进程的某个子进程已经退出,如果让它找到一个僵尸子进程,wait就会收集这个子进程的信息,并把它彻底销毁后返回;如果没有找到这样一个子进程,wait就会一直阻塞在这里,只有有一个出现为止。
参数status用来保存被收集进程退出时的一些状态,它是一个指向int类型的指针。如果对这个子进程是如果死掉的毫不关心,则可以设定这个参数为NULL。
pid=wait(NULL);
如果成功,wait会返回被收集的子进程ID,如果调用进程没有子进程,调用就会失败,返回-1,errno被置位ECHILD。
wait和waitpid作用相同,waitpid用来指定等待的进程,可以使进程不挂起而立即返回。参数pid指定所等待进程,

options提供了一些额外的选项来控制waitpid,Linux支持WNOHANG WUNTRACED,可以使用|将这两个参数链接起来,也可以设置为0.
进程简述:fork执行产生了一个和父进程一样的进程(数据段、堆栈,共享代码段),随着exec执行,新进程金蝉脱壳,开始一个全新的进程,并替代原来的进程。进程结束可以自然结束或被其他进程结束:自己结束执行到main}或者调用exit函数(留下僵尸进程)、return函数,wait、_wait函数清除掉僵尸进程。
(5) 用户ID和组ID。
与某一进程相关联的ID有6个:实际用户ID、实际组ID、有效用户ID、有效组ID、保存的设置用户ID、保存的设置组ID,通常,有效用户ID等于实际用户ID,有效组ID等于实际组ID。相关函数:
#include
#include
uid_t getuid(void);
gid_t getgid(void);
gid_t getegid(void);
uid_t gettuid(void);
返回:进程的相关用户ID。
getuid用于获得实际用户标识符,getgid获得实际的组ID,gettuid获得有效的组ID,getegid获得有效的组标识符。
(6) system 函数
system函数是一个和操作系统先关的函数,用户可以使用它在自己的程序中调用系统提供的各种命令。system函数原型:
#include
int system(const char *cmdstring);
十七、信号
信号是进程间通信的机制,信号不是将数据发送给某一进程,而是用于通知一个进程某一个特定事件的发生。信号全称为软中断信号,也叫软中断。软中断信号用来通知进程发生了异步事件,进程之间可以互相通过系统调用kill()发送软中断信号,内核也可以给进程发送信号。信号用来通知某个进程发生了某个事件,并不给进程传送数据。
进程处理信号的方法:(1)类似于中断的处理程序,对于需要处理的信号,进程可以指定处理函数。(2)忽略某个信号,对信号不做任何处理。(3) 对该信号的处理保留系统的默认值,大多数是使得进程终止,进程通过系统调用signal()来指定进程对某个信号的处理。
进程表的表项中有一个软中断信号域,该域中的每一个位对应一个信号,当有信号发给进程时对应位置位。进程对不同的信号可以同时保留,对于同一个信号,进程并不知道来过多少个。
每个信号都有一个名字,都以SIG开头。例如SIGABRT是夭折信号,进程调用abort()函数时产生这种信号。SIGALRM是闹钟信号,alarm()函数设置的时间超过后产生此信号。头文件
shell下键入kill -l 或者man 7 signal 查看信号。
17.1、内核对信号的处理
内核给进程发送软中断的方法:在进程所在的进程表中的信号域设置对应的位(内核通过在进程struct task_struct结构中信号域中设置相应的位来实现向进程发送一个信号)。进程检查是否收到信号的时机:进程即将从内核态返回用户态时,所以进程处于内核态时软中断信号不立即起作用,进程要返回用户态时先处理完信号才返回用户态,或者一个进程要进入或者离开一个适当的低优先级睡眠状态时。
17.2、信号操作的相关函数
(1) signal函数
要对一个信号进行处理,需要给出此信号发生时系统所调用的处理,可以作为一个特定的信号注册相应的处理函数。如果源程序注册了针对某一个特定信号的处理程序,不论当时程序执行到何处,一旦进程接收到该信号,相应的调用就会发生,调用signal函数来注册某个特定信号的处理程序,函数如下:
#include
void (*signal(int signum,void (*handler)(int)))(int);
返回:若成功则返回以前的信号处理配置,若出错则为SIG_ERR
参数signum,所注册函数对应的信号名,handler的取指:常数SIG_IGN、常数SIG_DFL或接到此信号后要调用的函数的地址。如果指定SIG_IGN,则向内核表示忽略此信号(SIGKILL SIGSTOP不能忽略),如果指定SIG_DFL表示接收到此信号后的动作是系统默认动作。当指定函数地址时,我称此为捕捉此信号,成函数为信号处理程序或信号捕捉函数。
signal函数有两个参数,返回一个函数指针,signum是一个整型数,第二个参数是函数指针,它指向的函数需要一个整形参数,无返回值。
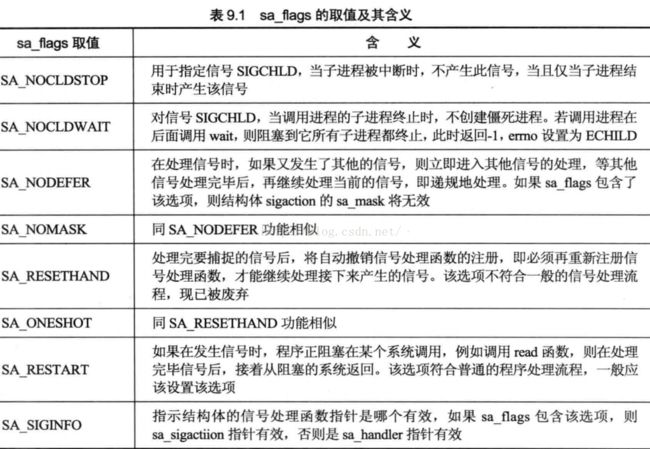
(2) sigaction函数
sigaction函数的功能是检查或修改与指定信号相关联的处理动作,此函数可以完全替代signal函数,sigaction函数如下:
#include
int sigaction(int signum,const struct sigaction *act,struct sigaction *oldact);
返回:成功返回0,出错返回-1.
signum是要捕捉的信号。act是一个结构体,里边包含了信号处理函数的地址、处理方式等信息。参数oldact是一个传出参数,sigaction调用成功后,oldact里边包含以前对signum信号的处理方式的信息。
struct sigaction
{
void(*sa_hanlder)(int)
void (*sa_sigaction)(int,siginfo_t *,void *);
sigset_t sa_mask;
int sa_flags;
void (*sa_restore)(void);
}
字段sa_handler是一个函数指针,用于指向原型为void handler(int)的信号处理函数地址,即老类型的信号处理函数。
字段sa_sigaciton是一个函数指针,指向void handler(int iSignNum,siginfo_t *pSiginfo,void *pReserved);的信号处理函数,新类型信号处理函数。该函数三个参数意义: iSigNum传入的信号,pSiginfo与该信号相关的一些信息,是个结构体。pReserve的,保留。
字段sa_handler sa_sigaction应该只有一个有效,如果用老信号处理机制,让sa_handler指向正确的函数,如果用新的信号处理机制,让sa_sigaction指向正确处理函数,并让sa_flags包含SA_SIGINFO选项。
sa_mask是一个包含信号集合的结构体,表示被阻塞的信号。
(3)信号集
为了方便同时对多个信号进行处理,Linux系统中引入了信号集的概念。 信号集用于表示多个信号所组成集合的数据类型,信号集定义为sigset_t类型的变量,5个处理信号集的函数:
#include
int sigemptyset(sigset_t *set); 将set指向的信号集设定为空,不包含任何信号。
int sigfillset(sigset_t *set); 将set指定的信号集设定为满,即包含所有信号。
int sigaddset(sigset_t *set,int signum); 将signum所代表的信号添加到set指定的信号集。
int sigdelset(sigset_t *set,int signum); 将signum代表的信号从set信号集中删除。
返回:成功返回0,错误返回-1.
#include
int sigismember(const sigset_t *set,int signum); 检查signum代表的信号是否存在于set信号集中。
返回:若为真返回1,为假返回0.
set 指向信号集的指针,signum表示一个信号。
(4) 信号的发送
发送信号函数:kill raise sigque alarm setitimer abort 。
kill 函数用于向某一给定进程或进程组发送信号,函数如下:
#include
#include
int kill(pid_t pid, int signum); 返回:成功返回0,出错返回-1.
pid表示进程或进程组的编号,signum发送的信号。如果signum0 可以检查进程是否存在。
raise 函数用于向进程本身发送信号,函数如下:
#include
#include
int raise(int signum); 返回:0成功, -1 错误。
sigqueue函数
sigqueue函数是针对实时信号提出的,支持信号带有参数,通常与函数sigaction配合使用,函数如下:
#include
#include
int sigqueue(pid_t pid,int signum,const union sigval val); 若成功返回0,出错返回-1.
pid是指定信号的进程ID,signum 将发送的信号,union signal 是一个联合数据结构,指定了信号传递的参数,即4字节值,定义如下:
typedef union sigval
{
int sival int;
void *sigval_ptr;
} sigval_t;
sigqueue比kill传递了跟多的附加信息,单sigqueue只能向一个进程发送信号,而不能发送信号给一个进程组。如果signum=0将会执行错误检查,但实际上不发送任何信号,
十八、进程间通信
进程间通信(InterProgress Communication,IPC)就是在不同进程之间传播或交换信息。进程的空间是相互独立的,按说是不能相互访问,唯一的例外是共享内存区,内核可以提供共享内存的条件。
Linux的进程间通信的方法有管道、消息队列、信号量、共享内存区、套接口等。管道分为命名管道、无名管道。消息队列、信号量、共享内存成为系统IPC。管道、消息队列、信号量和共享内存用于本地进程间的通信,套接口用于远程进程间通信。
管道(pipe)及命名管道(named pipe):管道用于亲缘关系进程间的通信,命名管道克服了管道没有名字的限制,除具有管道的所有功能外,还用于无亲缘关系进程间的通信。
进程间通信就是让多个进程之间相互访问,这种访问包括程序运行时适时的数据,也包括对方的代码段。
18.1、管道
管道(pipe)也叫匿名管道,是在两个进程之间实现一个数据流通的通道。相当于文件系统上的一个文件,来缓存所需要的数据。略区别于文件,管道中的数据读出后,管道中就没有数据了。管道会随着进程的结束而被系统清除,创建一个管道时生成两个文件描述符,对于管道所使用的文件描述符并没有路径名。经常使用|来链接连个命令。
管道从数据流上全双工管道和半双工管道,管道没有命名的成为匿名管道,管道是半双工的,数据只能向一个方向流动。只能用于父子进程和兄弟进程之间。单独构成一个独立的文件系统。数据的读出和写入。管道的缓冲区是有限制的。管道传送的是无格式字节流,要求管道的读出和写入房必须事先约定好数据格式。
Linux下使用pipe函数创建一个匿名管道,函数原型如下:
#include
int pipe(int fd[2]);
返回:若成功则返回0,若出错则返回-1.
参数fd[2]是个长度为2的文件描述符组,fd[0]是读出端的文件描述符,fd[1]是写入段的文件描述符。函数成功返回后,则自动维护一个从fd[1]到 fd[0]的数据管道。管道的关闭则使用基于文件描述符的close函数。
可以使用read和write函数对管道进行操作,管道的读出端只能读数据管道的输入端只能输入数据,如果从输入端读或者从输出端写都会出错,一般的IO操作函数都可以用于管道,open close write read等。
对一个读端已经关闭的管道进程操作是,会产生SIGPIPE,说明管道读端已经关闭,并且write操作返回-1,error值设为EPIPE,对于SIGPIPE信号进行捕捉处理。
如果要建立一个父进程到子进程的数据通道,可以先调用pipe函数紧接着调用fork函数,由于子进程会自动继承父进程的数据段,则父子进程同时拥有管道的操作权,管道的方向取决于用户怎么维护该管道。
要建立一个父进程到子进程的数据通道,也就是在子进程读出之前在父进程中写入数据,那么要在父进程中关闭管道的输出端,相应的在父进程中关闭管道的写入端,当维护子进程到父进程的数据通道时,父进程中关闭写入端,子进程中关闭读出端。使用pipe及fork组合,可以构造所有的父进程与子进程或子进程到兄弟进程的管道。
(2) 命名管道
命名管道也成为FIFO,它是一种文件类型,在文件系统中可以找到它,创建一个FIFO类似于创建一个文件。在程序中可以通过查看文件stat结构体中的st_mode成员的值来判断该文件是否为FIFO。即使不存在亲缘关系的进程也可以通过FIFO中路径名进行交互。
FIFO遵守先进先出的规则,对管道及FIFO的读总是从开始处返回数据,对它们写则把数据添加到末尾,不支持Sleek等文件定位操作。shell中可以使用mkfifo命令建立一个命名管道, mkfifo [option] name … option选择中选择要创建FIFO的模式,使用形式为 -m mode,这里的mode指出将要创建FIFO的八进制模式。
创建FIFO类似于创建一个普通文件,FIFO文件可以通过文件名来访问,函数原型如下:
#include
#include
int mkfifo(const char *pathname,mode_t mode);
返回:成功返回0,错误返回-1.
第一个参数路径名,也就是FIFO文件的名字,第二个参数与open函数中的mode参数相同。如果mkfifo的第一个参数是一个已经存在的路径名时,则返回EEXIST错误,典型的调用会先判断是否返回该错误,如果返回,则直接打开FIFO就可以了。FIFO文件隐形的规定不具有执行权限。
(3) 命名管道的读写
系统调用open打开一个命名管道,使用read和write函数对命名管道进行读写,close关闭一个管道,unlink删除一个命名管道。
(4) 消息队列
消息队列是一种以链表式结构组织的一组数据,存放在内核中,由各进程通过消息队列标识符来引用。管道是随进程持续的,消息队列是随内核持续的。
消息队列类型:POSIX消息队列及System V 消息队列,System 消息队列目前被大量使用。system V消息队列是随内核持续的,只有在内核重启或者显示删除一个消息队列时,该消息队列才会真正删除。系统中记录消息队列的数据结构(struct ipc_ids msg_ids)位于内核中,消息中所有消息对垒都可以在结构msg_ids中找到访问入口。
消息队列就是一个消息的链表。每个消息队列都有一个队列头,用结构struct msg_queue来描述,队列头包含了消息队列键值、用户ID、组ID、消息队列中消息数目等。




(1) 消息队列的创建与打开
消息队列的内核持续性要求每个消息队列在系统范围内都对应唯一的键值,要获得一个消息队列的引用标识符(ID)—-即创建或打开消息队列,只需要提供该消息的键值即可。
获得特定文件名的键值的系统调用是ftok,函数如下:
#include
#include
key_t tfok (char *pathname,char proj);
返回:若成功则返回一个消息队列的键值,若失败则返回-1. 该函数并不直接对消息队列进行操作,但在调用msgget() 函数获得消息队列标识符前,调用该函数。
创建或打开一个消息队列的系统调用为msgget,函数原型如下:
#include
#include
#include
int msgget(key_t key,int msgflag);
返回:若成功则为消息队列的引用标识符(ID),若失败则返回-1. 参数key是一个键值,由ftok获得,msgflg参数是一些标志位,可以取下值:IPC_CREAT、IPC_EXCL/IPC_NOWAIT或三者的逻辑或结果。
以下情况将会创建一个新的消息队列:
如果没有消息队列与键值key相对应,并且msgflg包含了IPC_CREAT标志位。
key参数为IPC_PRIVATE (设置成该标志并不是其他进程不能访问该消息队列,只意味着将创建新的消息队列。)
(2) 消息队列的读写
使用消息队列进行进程间通信,要对消息队列进行读和写的操作,写操作即向消息队列中发送数据,读操作即从消息队列中读出数据。
消息队列由两部分组成:消息类型和所传递数据,用数据结构struct msgbuf 来表示,消息类型通常是一个长整数。设定一个传递1024个字节长度的消息,可将结构定义如下:
struct msgbuf
{
long msgtype; // 消息类型,消息队列中读取消息的依据
char msgtext[1024]; // 消息内容,大小可调整
}
对于发送消息,首先预制一个msgbuf缓冲区并写入消息类型,调用响应的发送函数即可;对读消息来说,首先分配一个msgbuf缓冲区,把消息读入缓冲区即可。
向消息队列发送数据;
#include
#include
#include
int msgsnd(int msgid,const void *prt,size_t nbytes,int flags);
返回:若成功返回0,出错返回-1.
msgsnd向一个消息队列发送一个消息,该消息被追加到队列的末尾。msgid代表队列的标识符,prt指向要发送的消息,nbytes 数据长度,flags用于指定消息队列满时的处理方法。对于发消息来说,有意义的flags标志位IPC_NOWAIT,指明在消息队列没有足够空间发送消息时,msgsnd是否等待。当消息队列满时,如果设置了IPC_NOWAIT位,则立刻出错返回,否则发送消息的进程被阻塞,直至消息队列中有空间或消息队列被删除时,函数立刻返回。
造成msgsnd等待的条件有两种: 当前的大小与消息队列中的字节个数超过消息队列的总容量。 消息队列中的消息数不小于消息队列的总容量。
msgsnd 解除阻塞的条件有3个:不满足上述两个条件。msqid代表的消息队列被删除。调用msgsnd的进程被某个信号中断。
从消息队列中接收数据,函数原型:
#include
#include
#include
int msgrcv(int msqid,void *prt ,size_t nbytes,long type ,int flags);
返回:成功返回消息的数据长度,若出错则返回-1.
此函数用于从指定消息队列中读取一个消息数据。msqid代表消息队列的引用标识符,prt 缓冲区,nbytes 字节个数,flags消息队列满时的处理方法。

获得或设置消息队列的属性:
消息队列的信息基本上都保存在消息队列头中,分配一个类似于消息队列头结构struct msqid_ds来返回消息队列属性;keil设置该数据结构,函数如下:
#include
#include
#include
int msgctl(int msqid,int cmd ,struct msqid_ds *buf);
返回:成功返回0,否则返回-1.
系统调用对由msgid表示的消息队列执行cmd操作,cmd操作有三种:IPC_STAT IPC_SET IPCRMID.
IPC_STAT:用来获取队列消息,返回的信息存贮在buf指向的msqid_ds结构中。
IPC_SET : 该命令用设置消息队列属性,属性包括msg_perm.uid msg_perm.pid msg_perm.mode msg_qbytes同时影响msg_ctime 成员。
IPC_RMID:删除msqid消息队列。
18.5、共享内存
共享内存是linux下最快速最有效的进程间通信方式。两个不同进程A、B共享内存的意思是,同一物理内存被映射到进程A、B各自的进程地址空间。进程A可以即时看到进程B对共享内存数据的更新,反之B也可以看到A。
二十、网络编程
OSI七层模型是设计和描述网络通信的基本框架,描述了网络硬件和软件如果以层的方式协同工作进行网络通信。

(1)物理层
物理层并不是指物理设备或屋里媒体,而是有关物理设备通过屋里媒体进行互联的描述和规定,物理层定义了接口的机械特性、电气特性、功能特性、规程特性等。
物理层以比特流的方式传送来自数据链路层的数据,不理会数据的格式和含义,它接收数据后直接传给数据链路层,物理层只能看到0和1.
(2) 数据链路层
数据链路层是OSI模型的第二层,负责从一台计算机到另一台计算机无差错的传输数据帧,允许网络层通过网络连接进行虚拟的无差错传输。
通常,数据链路层发送一个数据帧后,等待接收方确认。接收方 数据链路层检测帧传输过程中产生的任何问题,没有经过确认和损坏的帧都要进行重传。
(3) 网络层
负责信息地址和将逻辑地址与名字转换为物理地址。
网络层,数据传送的单位是包。网络层的任务是选择合适的路径和转发数据包,使发送方数据包能够正确的按照地址寻找到接收方的路径,并将数据包交给接收方。网络层负责最佳路径的选择。
网络层向传输成提供服务,同时将网络地址翻译成物理地址,还能协调发送、传输及接收设备能力不平衡的问题,网络层对数据进行分段和重组。
(4) 传输层
保证在不同子网的两台设备之间数据包可靠、顺序、无差错的 传输。传输层数据传输的单位是段。传输层负责端到端通信(一台计算机到另一台计算机),中间可以有一个或多个交换节点。
传输层主要功能是将接收到的乱序数据包从新排序,并验证所有的分组是否已被接收到。
(5) 会话层
会话层是利用传输层提供的端到端的服务,向表示层或会话用户提供会话服务。会话层的功能是在两个节点间建立、维护和释放面向用户的链接,并对会话进行管理和控制,保证会话数据可靠传送。
会话连接和传输连接的三种关系:一对一关系,一个会话连接对应一个传输关系,一对多,一个会话连接对应多个传输关系;多对一关系,多个会话连接对应一个传输关系。
会话层协议有结构化查询语言SQL、远程进程呼叫RPC、Xwindows系统、AppleTalk会话协议、数字网络结构会话控制协议DNA SCP等。
(6) 表示层
表示层以下各层主要负责数据在网络传输时不会出错,但是数据传输没有错不代表数据所表示的信息没有错。表示层专门负责有关网络计算机信息表示方式问题。
(7) 应用层
直接与用户和应用程序打交道,负责对软件提供接口使程序能使用网络。应用层不只为OSI模型外的其他应用程序提供服务。应用层协议:虚拟终端协议Telnet、简单邮件传输协议SMTP、简单网络管理协议SNMP、域名服务系统DNS、超文本传输协议HTTP。
TCP/IP协议族中最重要的协议是传输控制协议TCP、网络互连协议IP,TCP和IP负责管理和引导数据报在Internet上的传输,TCP负责和远程主机的连接,IP负责寻址,使报文被送到目的地。
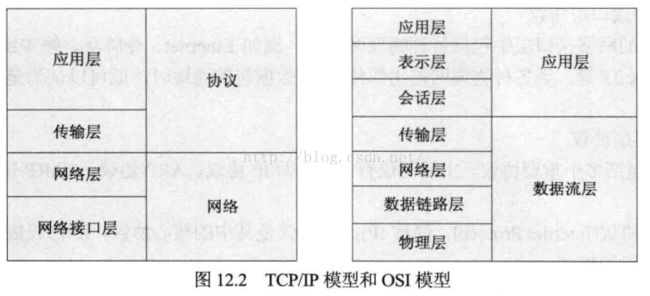
(1) 网络接口层协议
TCP/IP网络接口层中包括各种无力层协议,如以太网、令牌环、帧中继、ISDN和分组交换网X.25。
(2) 网络层协议
网络层包括多个重要协议:有4个主要协议比如IP协议、ARP协议、RARP协议和ICMP协议。
IP协议:规定网际协议层数据报分组的格式。
ICMP因特网控制消息协议:提供网络控制和消息传递功能。
ARP地址解析协议:将逻辑地址解析成物理地址。
RARP反地址解析:通过RARP广播将物理地址解析成逻辑地址。
(3)传输层协议
主要有TCP和UDP协议,基于套接字的网络编程,是基于这两个协议实现的。
传输控制协议TCP:TCP是面向连接的协议,用三次握手和滑动窗口机制来保证传输的可靠性和进行流量控制。
用户数据报协议UDP:面向无连接不可靠的传输。
(1) 传输控制协议TCP
TCP和UDP最大区别是TCP是面向连接的,UDP是面向无连接的。
TCP协议采用许多机制保证端到端节点之间的可靠数据传输,如采用序列号、确认重传、滑动窗口等。
首先,TCP为所发送的每一个报文段加上序列号,保证每一个报文段能被接收方接收并只被正确的接收一次。
其次,TCP采用具有重传功能的积极确认技术作为可靠数据流传输服务的基础。确认指接收端在正确的接收到报文段之后向发送端返回一个确认(ACK)信息。发送方将每个已发送的报文段备份在自己的发送缓冲区里,而且在收到相应的确认之前不会丢弃所保存的报文段的。“积极”指发送方在每一个报文段发送完毕的同时启动一个定时器,假如定时器的定时期满而关于报文段的确认信息还没收到,则发送方任务该报文段已经丢失并主动重发。为了避免由于网络延迟引起的迟到确认和重复确认,TCP在每个确认信息中捎带一个报文段的序号,使接收方能正确的将报文段和确认联系起来。
最后,采用可变长的滑动窗口协议进行流量控制,防止由于发送端与接收端之间的不匹配而引起数据丢失。
(2)TCP 链接的建立
TCP链接的建立包括建立连接、数据传输和拆除连接3个过程。 TCP通过TCP端口提供链接服务,最后通过连接服务来接收好而发送数据。TCP连接的申请、打开、关闭必须遵守TCP协议的规定。TCP使用三次握手来建立连接,链接可以由任一一方发起,也可以同时发起。一台主机上的TCP软件主动发起连接请求,另一台主机上的TCP软件只能被动的等待握手。
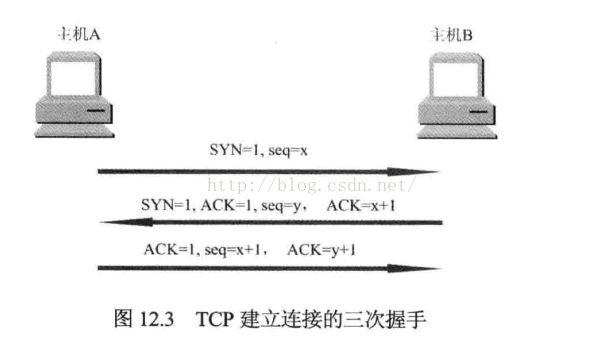
三次握手:
① 源主机A的TCP向目的主机B发出连接请求报文段,首部中的SYN(同步)标志位应置为1,表示想与目标主机B进行通信,并发送一个同步序列号X(例 SEQ=100)进行同步,表示在后面数据传送时第一个数据字节的序列号是X+1(101).
② 目标主机B的TCP收到连接请求报文后,如同意,则发回确认,在报文中将ACK位和SYN位置1.确认号为X+1,同时也为自己选择一个序列号Y。
③ 源主机A的TCP收到目标主机的确认后想目标主机B给出确认,其ACK置为1,确认号Y+1,而自己的序号为X+1。TCP标准规定,SYN置1的报文段要消耗掉一个序号。
链接建立,源主机A向主机B发送第一个数据报文段时,其序号让为X+1,因为前一个确认报文段并不消耗序号。
TCP连接建立后,可以发送数据,数据发送结束,需要关闭链接,连接的关闭必须由通信双方共同完成。通信的一方没有数据需要发送给对方时,可以使用FIN段向对方发送关闭连接请求。虽然不在发送数据,但不排斥在这个连接上继续接受数据,只有当通信的对方也递交了关闭连接的请求后,TCP连接才完全关闭。
(3) 用户数据报协议UDP
UDP在传送数据之前不需要建立连接,对方的传输层在收到UDP报文后,不需要给出确认信号。
UDP协议特点:在UDP传送前不需要建立连接,传输前发送方和接收方相互交换信息使双方同步;UDP不对收到的数据进行排序,UDP报文中没有关于数据顺序的信息(TCP的序号),而且报文不一定是顺序到达;UDP对接收到的数据报不发送确认信号,发送端不知道数据是否被正确接收,也不会重发数据;UDP比TCP传输快。
(4) 客户机/服务器模式(C/S模式)
要求每个应用程序有两个部分组成:一个部分负责启动通信,另一个部分负责对它进行应答。

20.2、套接口编程
套接口是操作系统内核的一个数据结构,是网络中节点进行通信的门户。网络编程也称为套接口编程。
套接口也就是网络进程的ID,网络通信归根到底是进程间的通信。网络中,每一个节点(计算机或路由器)都有一个网络地址即IP地址,两个进程通信时,首先要确定各自所在网络节点的网络地址,但是网络地址只能确定所在的计算机,一台计算机上可能同时运行着多个进程,所以还需要端口号进一步确定和哪个进程通信。一台计算机上,一个端口号一次只能分配给一个进程,进程和端口号是一一对应的。
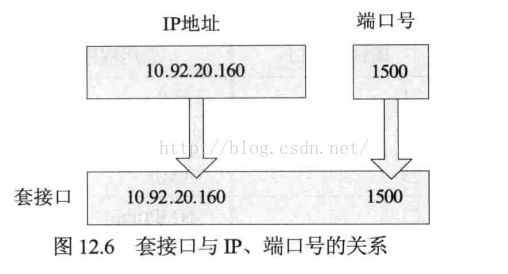
网络地址和端口号信息放在一个结构体中,组成套接口的地址结构,大多数套接口函数都需要指向一个套接口地址结构的指针作为参数,以此来传递信息,每个协议族都定义了自己的套接口地址结构,套接口地址结构以
sockaddr_开头。
套接口三种类型:流式套接口(TCP套接口 SOCK_STREAM)、数据报套接口(UDP套接口 SOCK_DGRAM)、原始套接口(SOCK_RAW)。
网络技术中,端口有2中意思:一是物理端口,二是逻辑意义上的端口,一般指TCP/IP 协议中的端口,范围从0~65535.端口分为两类:一类是固定通用的端口,数值为0~1024,另一类是一般端口,用来随时分配给请求通信的客户进程。
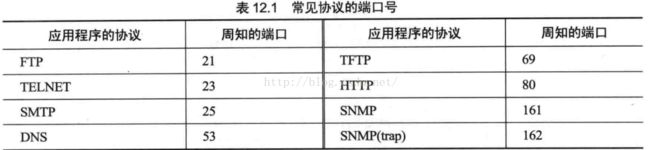
套接口的数据结构
在bind、connect等系统调用中,特定于协议的套接口地址结构指针都要强制转换成该通用的套接口地址结构指针,通用套接口数据接口在sys/socket.h 中,如下:
struct sockaddr
{
uint8_t sa_len;
sa_family_t sa_family;
char sa_data[14];
}
IPv4套接口地址数据结构:
IPv4套接口地址数据结构以socketaddr_in命名,在netinet/in.h中,如下:
struct socketaddr_in
{
uint8_t sin_len; // 数据长度成员,一般不设置
sa_family_t sin_fanmily ; // 套接口结构地址族,IPv4为AF_INET
in_port_t sin_port; // 16位端口号。
strtct in_addr sin_addr; // 32位的IP地址
unsigned char sin_zero[8]; // 未用
}
struct in_addr
{
in_addr_t s_addr; //32位的IP地址。
}
20.3、基本函数
(1) 字节排序函数
计算存储方式分为大端模式、小段模式。端口号和IP地址都是以网络字节顺序存储的,网络字节顺序使用的是大端模式。某个系统所用是自己顺序为主机字节序。主机字节序和网络字节序的排序函数:
#include
uint32_t htonl(uint32_t hostlogn);
uint16_t htons(uint16_t hostshort);
返回的是网络字节。
uint32_t ntohl(uint32_t netlong);
uint16_t ntohs(uint16_t netshort);
返回的是主机字节。
4个转换函数中,h代表host,n代表network,s代表short,l代表long。
(2) 字节操纵函数
套接口编程中,需要一起操纵结构体中的某几个字节,字节操纵函数如下:
#include
void bzero(void *dest,size_t nbytes); // 从dest指定地址开始的n个字节设置为0
void bcopy(const void *src,void *dest,size_t nbytes); // 复制函数
int bcmp(const void *ptrl,const void *ptr2,size_t nbytes);
void memset(void *dest,int c,size_t len);
void memcpy(void *dest,const void *src,size_t nbytes);
int memcmp(const void *ptrl,const void *ptrl,size_t nytes);
以b打头的函数有系统提供,以mem开头的由ANSI C提供。
(3) IP地址转换函数
TCP/IP网络上,用的IP都是以‘.’隔开的十进制数表示,套接口的数据结构中用的是32位的网络字节顺序的二进制数值,转换函数如下:
#include
int inet_aton(const char *straddr,struct in_addr *addrptr);
返回:转换成功返回1,不成功返回0.
将点分十进制IP地址转换为网络字节序的32位二级制数值。输入的点分十进制放在参数straddr中,返回二进制数值放在addrptr中。
char *inet_ntoa(struct in_addr inaddr);
返回:若成功则返回点分十进制数串的指针,失败返回NULL。
调用结果作为函数的返回值返回给调用它的函数。
int_addr_t inet_addr(const char *straddr);
返回:成功返回32位二进制的网络字节序地址,出错返回INADDR_NONE。
(4) IP和域名的转换
#include
struct hostent *gethostbyname(const char *hostname);
实现域名或主机名到IP地址的转换,hostname指向存放域名或主机名的字符。
struct hostent *gethostbyaddr(const char *addr,size_t len ,int family);
实现IP地址到主机名或域名的转换。addr指向一个含有地质结构(in_addr)的指针,len是结构大小,对于IPV4 是4,IPv6值为16.
返回:成功返回hosten指着,失败返回NULL,同时设置全局变量h_errno为相应的值。h_errno值如下:
HOST_NOT_FOND主机没找到,TRY_AGNAIN出错重试,NO_RECOVERY不可修复性错误,NO_DATA指定的名字有效但没有记录。
结构体struct hostent定义:
struct hostent
{
char *h_name ; // 主机的正式名称
char *h_aliases; // 主机的别名
int h_addrtype; // 主机的地址类型
int h_length; // 主机的地址长度
char **h_addr_list; // 主机的IP地址列表
}
20.3、TCP套接口编程
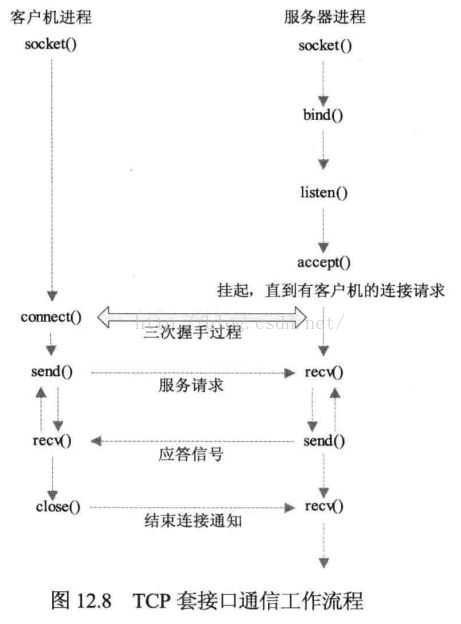
大致工作流程:
(1) 服务器用soket()函数建立一个套接口,用这个套接口完成通信的监听及数据收发。
(2) 服务器用bind()函数来绑定一个端口号和IP地址,使套接口与指定的IP和端口相连。
(3) 服务器调用listen()函数,使服务器的这个端口和IP处于监听状态,等待网络中客户机的连接。
(4) 客户机用socket()函数建立一个套接口,设定远程IP和端口号
(5) 客户机用connect()函数连接远程计算机的端口
(6) 服务器调用accept()函数来接收远程计算机的连接请求,建立与客户机通信连接。
(7) 建立连接后,客户机用write()函数(或send()函数)向socket中写入数据。也可以用read()函数(或recv()函数)读取服务器发来的数据。
(8) 服务器用(7)的函数来接收和发送数据。
(9) 完成通信后,使用close()关闭socket连接。
创建套接口:
系统调用socket生成一个套接口描述符,函数如下:
#include
#include
int socket(int family,int type,int protocol);
若成功返回套接口描述符,若失败返回-1.
参数family指明协议族,PF_UNIX(UNIX协议族)、PF_INET(IPv4协议)、PF_INET6(IPv6协议)、AF_ROUTE(路由套接口)等,type指明通信字节流类型:SOCK_STAREAM(TCP方式)、SOCK_DGRAM(UDP方式)、SOCK_RAW(原始套接口)、SOCK_PACKET(支持数据链路访问)等,参数protocol可设置为0。
socket系统调用为套接口在sockfs文件系统中分配一个新的文件和dentry对象,并通过文件描述符把它们与调用进程联系起来,进程可以像访问一个文件一样访问套接口在sockfs中对应的文件。进程不能用open()来访问该文件。
绑定端口
socket函数建立一个套接口后,需要使用bind函数在这个套接口上绑定一个指定端口和IP地址,函数如下:
#include
#incldue
int bind(int sockfd,const struct sockaddr *my_addr,socklen_t addrlen);
返回:成功返回0,失败返回-1.
参数sockfd表示已经建立的socket描述符,my_addr sockaddr类型的指针,addrlen 表示myaddr的长度。
等待监听函数
socket的端口一直处于等待状态,监听网络中所有的客户机,耐心等待某一个客户机的发送请求,如果有连接请求,端口就会接受这个连接,函数如下:
#include
int listen(int sockfd,int backlog);
返回:成功返回0,失败返回-1
sockfd表示已经建立的套接口,backlog表示同时处理的最大连接请求数目。listen并未真正的建立连接,真正接受客户端连接的是accept();通常listen函数在socket() bind() 之后调用,然后调用accept();
listen 函数只适用于SOCK_STREAM SOCK_DGRAM的socket类型,如果socket为AF_INET,在backlog最大设为128.
接受连接函数
如果某个时刻有客户机请求,并不是理解处理这个请求,而是将这个请求放入等待队列中,系统空闲时处理请求,函数accept() 如下:
#include
#include
int accept(int sockfd,sturct sockaddr *addr,socklen_t *addrlen);
返回:成功返回新的套接口描述符,失败返回0.
参数sockfd表示层处于监听状态的socket,addr是一个sockaddr类型结构体类型指针,系统会把远程主机的信息保存到这个结构体,addrlen 表示sockaddr的内存长度。
当addr接受一个链接时,会返回一个新的sock描述符,以后的数据传输和读取通过新的sock编号来处理。
请求连接函数
所谓请求连接,指在客户机向服务器发送信息之前,需要先发送一个连接请求,请求与服务器建立TCP通信连接,connect函数完成这项功能,函数如下:
#include
#include
int connect(int sockfd,const struct sockaddr *serv_addr,int addrlen);
返回:成功返回0,失败返回-1.
参数sockfd表示已经建立的socket,serv_addr结构体来存储远程服务器的IP与端口信息,addrlen表示sockaddr结构体的长度。
connect函数将本地的socket连接到serv_addr指定的服务器IP与端口号上去。
数据发送函数
建立完套接口并连接到远程主机上以后,可以把信息发送到远程主机上,而对于远程主机发送来的信息,本地主机需要进行接收处理。
用connect函数连接到远程计算机后,可以用send函数将信息发送到对方的计算机,对方也可以用send函数将应答信息发送到本地计算机,send函数如下:
#include
#include
int send(int sockfd,const void *msg,int len,unsigned int flags);
返回:成功返回已发送的字符数,失败返回-1.
flags一般设置为0.

数据接收函数recv如下:
#include
#include
int recv(int sockfd,void *buf,int len ,unsinged int flags);
返回:成功返回接收到的字节数,失败返回-1.

(8) write与read函数
当socket连接建立以后,向这个socket中写入数据即表示想远程主机中传送数据,从socket中读数据则相当于从远程主机中接收数据。read和write函数在socket编程中和send recv函数功能类似。
#include
ssize_t read(int fd,const char *buf);
ssize_t write(int fd,const char *buf,size_t count);
20.4、UDP套接口编程
UDP是一个无连接不可靠的传输层服务,域名服务系统DNS,网络文件系统NFS使用的是UDP连接。
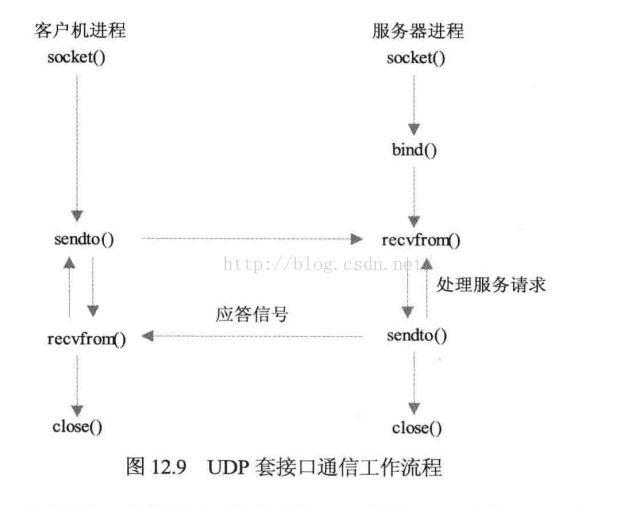
TCP套接字必须先建立连接(客户端connect请求连接,服务器listen()和accept()),而UDP不需要建立连接,它在电泳socket生成一个套接字后,在服务器端用bind绑定一个端口和IP,然后服务器进程挂起与recvfrom()调用,等待某一个客户机的请求,客户机sendto()请求同样挂起与recvfrom()调用,等待并接受服务器应答信号,数据完成后客户端调用close()释放通信链路。
数据发送函数sendto,相当于TCP连接中的send()或write函数,sendto函数如下:
int sendto(int sockfd,const void *msg,int len,unsigned int flags,struct sockaddr *toaddr,int *addrlen);
数据接收函数recvfrom相当于TCP中的read 或recv函数。如下:
#include
int recvfrom(int sockfd,void *buf,int len,unsigned int flags,struct sockaddr *fromaddr,int *addrlen);
20、5 原始套接口
有三种套接字:SOCK_STREAM SOCK_DGRAM SOCK_RAW ,原始套接口只能有root权限的用户创建,原始套接字有如下特点:
① 使用原始的套接口可以读写ICMP(互联网控制消息协议)及ICMPv6分组。
② 原始套接字可以读写特殊的IP数据包,内核不处理这些数据包的IP协议字段,而出错的诊断将依靠协议字段的意义。
③ 利用原始套接字通过设置IP_HDRINCL套接口选项建造自己的IP头部。
原始套接口的创建
int sockfd;
sockfd=socket(AF_INET,SOCK_RAW,protocol);
TCP套接字和UDP套接口的protocol为0,原始套接字的protocol取指可以是IPPROTO_ICMP IPPROTO_TCP IPPROTO_UDP等,不同类型协议创建不同的原始套接字。
二十一、图形界面编程
图形用户界面(Graphical user interface)简称GUI,是指采用图形的方式显示的计算机操作用户界面。GUI的组成部分包括桌面、视窗、单一文件界面、多文件界面、标签、菜单、图表、按钮等。用来进行图形用户界面编程的工具(库)成为GUI工具包(GUI库),GUI库是构造图形界面所使用的一套按钮、滚动条、菜单和其他对象集合。可供使用的GUI库,如Motif、Qt、GTK+等,最常用的是GTK+ 和Qt。
21.1、窗口
窗口是一个应用程序的框架,程序的所有内容与用户的交互都在这个窗口中,设置应用程序界面时第一步是建立一个窗口。gtk_window_new()函数建立一个GTK+窗口,函数如下:
#include
GtkWidget *gtk_window_new(Gtk WindowType type);
返回:若成功,返回一个GTKWidget类型的指针,失败返回空指针NULL。参数type表示一个窗口状态常量,可能的取值以下两种:
GTK_WINDOW_TOPLEVEL:表示这个窗口是一个正常的窗口。窗口可以最小化,在窗口管理中可以看到这一窗口按钮。窗口控制器相当于windows下的任务栏。
GTK_WINDOW_POPUP: 表示这个窗口是一个弹出式窗口,不可以最小化。但这个窗口是一个独立运行的程序,并不是一个对话框。
gtk_window_new()函数的返回值是一个GtkWidget类型的指针,图形界面的所有元素都会返回这个指针。GTKWidget结构体的定义:
typedef struct
{
GtkStyle *style; // 元件的风格
GtkRequisition requisition; // 元件的位置
GtkAllocation allocation; // 允许使用的空间
GtkWindow *window; // 元件所在的窗口或父窗口
GtkWidget *parent; // 元件的父窗口
}GtkWidget;
新建一个窗口以后,这个窗口不会马上显示出来,需要调用窗口显示函数gtk_window_show()来显示这个窗口,函数如下:
#include
void gtk_window_show(GtkWidget *widget);
参数widget是一个GtkWidget类型的结构体指针,指向需要显示的窗口。
设置窗口标题gtk_widnow_set_title()函数如下:
#include
void gtk_window_set_title();
指针title所指向的字符串必须是英文字符的,但如果我们想要显示中文字符,使用g_locale_to_utf8()函数进行批注。
设置窗口的大小和位置
窗口的大小指的是窗口的宽度和高度,用gtk_widget_set_usize() 函数来设置一个窗口的初始大小。窗口的位置指的是窗口的左上角顶点到屏幕左边和顶边的距离,可以用gtk_widget_set_uposition()函数来设置一个窗口的初始位置,函数下:
include
void gtk_widget_set_usize(GtkWidget *widget,gint width,gint height);
void gtk_widget_set_position(GtkWidget *widget ,gint x,gin y);
标签:
标签是程序中的一个文本,这个文本可以显示一定的信息,用户不能输入和改变标签内容,界面中的提示信息和显示内容都是通过标签来实现的。
新建一个标签:
使用标签之前,需要新建一个标签,gtk_lable_new() 用来新建一个标签,函数:
#include
GtkWidget * gtk_lable_new(gchar *text);
返回:成功则返回一个GtkWidget的指针,若失败则返回NULL。
参数text表示要显示的内容,和窗体一样,新建标签后需要调用显示函数gtk_widget_show()来显示这个标签,函数如下:
#include
void gtk_widget_show(GtkWidget *lable);
参数label表示gtk_lable_new()新建的标签,无返回值
将标签添加到窗口:
GTK+窗口中,除了window窗口外,其他的原件都必须放在一个容器中,例如新建的标签不能直接显示,需要放在一个容器中。gtk_container_add()函数的作用就是把一个元件放置在一个容器中,函数如下:
#include
void gtk_container_add(GtkContaner *contaner,GtkWidget *widget);
container是一个父级的容器指针,widget是需要放置元件的指针。无返回值。
gkt_table_add()可以将一个标签添加到一个表格中,然后用gtk_container_add()将表格添加到窗口中。
设置和获取标签的文本
用gkt_lable_get_text()函数来获取一个标签的文本,使用gtk_lable_set_text()函数来设置一个标签的文本,函数如下:
#include
const char *gkt_lable_get_text(GtkLable *lable); 返回:成功返回标签文本的字符串指针,失败NULL
void gtk_lable_set_text(GtkLable *lable,gchar *text); 无返回值
lable 是一个指向标签的指针,text表示标签需要设置文本。
按钮:
新建一个按钮,函数:
GtkWidget * gtk_button_new(gchar *lable);
返回:若成功,返回一个GtkWidget 指针,失败返回NULL。
新建成功后,调用gtk_widget_show()来显示这个按钮。
设置和获取按钮的标签:
按钮的标签指的是按钮上的文字,gtk_button_get_lable()获取某个按钮的标签,函数gtk_button_set_lable();设置某个按钮的标签,函数如下:
#include
const char *gtk_button_get_lable(GtkButton *button);
void gkt_button_set_lable(GtkButton *button ,const gchar *lable);
button指向按钮的指针,lable ,按钮标签的内容。按钮通常伴随着一个事件。
文本框:
gtk_entry_new();函数来新建一个文本框,如下
GtkWidget * gtk_entry_new(void);
GtkWidget *gkt_entry_new_with_max_length(gint max);
两个函数的作用一样,max表示最多输入的字符个数。
设置和获取文本框内容
#include
const char *gtk_entry_get_text(GtkEntry *entry);
void gtk_entry_set_text(GtkEntry entry ,const gchar *text);
GTK 是用utf8显示的,所显示的字符都需要utf8才能正常显示,使用g_local_to_utf();函数来转换,可以使用中文。本地字符和utf8字符的转换函数:
gchar * g_local_to_utf8(gchar *string,gssize len,gsize *bytes_read,gsize *bytes_written,GError **error);
gchar * g_local_from_utf8(gchar *string,gssize len,gsize *bytes_read,gsize *bytes_written,GError **error);
21.2、界面布局元件
界面布局元件包括表格、框、窗格等。表格是界面中最常用的元件,通过在单元格中插入不同元件来实现布局和排列。如果一个元件中可以放其他的元件,这个元件叫容器。
表格的建立,函数如下:
#include
GtkWidget *gtk_table_new(guint rows,guint columns,gboolean homogeneous);
参数rows表示行数,columns表示列数,homogeneous是一个布尔值,如果设置为TURE则每个单元格大小相同,如果设置为FALSE则表格的大小会根据单元格中元件的大小自动调整。表格并不真正显示,只是容纳其他元件和布局用的。
将其他元件添加到表格中,函数如下:
#include
void gtk_table_attach(GtkTable *table ,GtkWidget *child,guint left_attach,guint right_attach,guint top_attach,guint bottom_attach,GtkAttachOptions xoption,GtkAttachOptions yoptions,guint xpadding,guint ypadding);
参数xoptions和yoptions 分别表示元件在表格中的 水平方向和垂直方向对其方式,xpadding,ypadding 分别表示元件与边框水平方向和垂直方向的边距。
GtkOptions的取值有三个:GTK_EXPAND元件以设置的大小显示,如果大于容器的大小则容器自动变大,GTK_SHRINK 如果元件大于容器的大小,则自动缩小元件,GTK_FILL元件填充整个单元格。
嵌套表格:
设计复杂界面时,需要在一个表格中添加表格,实现表格嵌套,表格也是一个普通元件,可以把一个表格添加到另一个表格的单元格中。
22.3、信号与回调函数
图形界面的程序是事件驱动的程序,程序进入gtk_main()函数后,等待事件的发生,一旦发生某个事件,相应的信号将产生,如果程序中定义了相应的消息处理函数(回调函数),系统会自动进行调用。
信号的作用是对某一个元件添加一个用户交互的功能,g_signal_connect() 可以把一个信号处理函数(回调函数)添加到一个元件上,在元件和处理函数间建立关联,函数如下:
gulong g_signal_connect(GtkObject *object,gchar *name,Gcallback callback_func,gpointer func_data);
参数object是一个元件的指针,指向将产生信号的元件。name表示消息或时间的类型,一个按钮的所有事件类型:activate 激活的时候发生,clicked 单击以后发生,enter 鼠标指针进入这个按钮以后发生,leave 鼠标离开这个按钮以后发生,pressed 鼠标按下以后发生,released 鼠标释放以后发生。
参数callback_func表示信号产生后将要执行的回调函数,func_data 传递给回调函数的数据。
函数的返回值用于区分一个元件的一个事件对应的多个回调函数,一个元件上可以有很多个事件比如按钮的单击和双机,每个事件可以有0个或多个处理函数。
(2) 回调函数
消息处理函数(回调函数)原型:
#include
void callback_func(GtkWidget *gtkwidget,gpointer func_data);
参数gtkwidget指向要接收消息的元件,func_data指向消息产生时传递给该函数的数据。
附件:我遇到的问题及解决办法(如果错误,深入学习后再来修改)
1、安装CH340驱动(源码)
(1) 下载了CH340驱动的压缩包.zip格式
(2) 用U盘拷贝到虚拟机的home目录。
(3) unzip filename.zip 解压缩文件,文件中包含了.c 文件 和makefile
(4) make 命令进行编译
(5) apt install sl 命令进行安装
源码的安装方式:
(1) 下载源码包,根据压缩包的类型使用相应的命令进行解压缩
(2) 进入解压缩后的目录 执行 ./configure 命令检查安装环境(库函数、头文件),可以指定安装目录,如果不指定默认在当前目录。
(3) make 生成makefile 文件
(4) make install 进行安装。
2、minicom安装
ubuntu使用命令sudo apt-get install minicom 进行安装,也可以从光盘镜像或者源码安装。
第一次配置使用root用户权限使用命令:minicom -s 然后就可以配置,配置完成后保存,在etc目录下就有了minicom文件夹保存配置。
3、可以用ls -l 或者ll 命令来查看目录下各个文件的类型及读写执行权限,d开头的是目录文件,l开头的是链接文件,_开头的是普通文件,b开头的是块设备,c开头的是字符设备。浅蓝色的是目录,绿色的是可执行文件。
chmod命令可以改变目录或文件的权限,比如chmod 755 a.txt 755分别表示拥有者、组、其他用户的权限,值按照r、w、x顺序,允许就为1,不允许为0,比如rwxr-xr–权限就是754.
bin文件夹存放的是二进制文件,主要是用户命令。
lib文件夹存放的是动态的链接库。
(2)可以去/sys/bus/usb-serial/drivers/ 查看USB转串口设备以及设备号
4、shell的环境变量,PATH、HOME、HOSTNAME、LOGNAME、”echo $环境变量”显示环境变量的信息。
临时变量(自定义变量)使用export变成环境变量。
export PATH=/home/yang :$PATH ,添加环境变量并保持原来的,用来加载除了/lib和/usr/lib以外的其他链接库。
$引用变量。
5、Ubuntu 建立的sh文件,执行时很多情况下需要修改文件的权限。
6、 .tar.xz 压缩包的安装
解压安装包: tar -vxf xxx.tar.gz
进入解压后的包: cd xxx
配置编译环境:./configure
进行编译:make
安装软件:make install
7、Ubuntu下GTK+环境的安装
先去/usr/include 目录下看看有没有gtk-2.0
安装依赖关系:sudo apt-get install build-essential libgtk2.0-dev
编译文件: gcc -o xxx -c xxx.c `pkg-config –cflags –libs gtk+-2.0`
注意:
.c文件的执行需要包括pkg的配置命令,否则会提示找不到gtk.h
符号“`” 上斜点的位置作在键盘esc键下边 带~号的键。