问世28年经久不衰,大厂为何独爱这门技术?(文末送书5本)

♂️ 个人主页:@艾派森的个人主页
✍作者简介:Python学习者
希望大家多多支持,我们一起进步!
如果文章对你有帮助的话,
欢迎评论 点赞 收藏 加关注+
目录
前言
一、为什么要学习推荐系统?
二、行业老兵拆解大厂技术细节
三、掌握核心基础:在线模块4大阶段
四、攻克难题,让推荐系统更丝滑
五、研发一线专家亲授,这些人最爱学
六、AI+未来势不可挡,小艾邀你乘风破浪
文末福利
前言
缺什么网购商城就推什么
想吃瓜瞬间就弹出相关新闻
想打卡的餐厅神速推出优惠团购
……
这大概是很多网民的日常——感觉大脑被装了监视器!
其实,在每一次浏览中,推荐系统的作用都举足轻重!它就好像掌握了“读心术”的AI,时时刻刻给你推荐感兴趣的内容。
自1994 年美国明尼苏达大学研究组推出第一个自动化推荐系统GroupLens,距今已有 29 年。
得益于腾讯、YouTube、快手等公司在推荐、广告等业务场景中的应用,当下推荐系统已经进入蓬勃发展、百花齐放的新时代,甚至已经有研究人员试图利用大模型来增强推荐系统了。
可见,推荐系统已经成为AI领域的热门选手之一!
今天,小艾就用这本《推荐系统技术原理与实践》揭开推荐技术的神秘面纱。

一、为什么要学习推荐系统?
虽然搭建推荐系统是门技术活,但弄清楚推荐系统的价值和意义,有助于开发者更好地打造真正造福浏览者和企业的优质系统。
维基百科对”推荐系统“的定义:一种信息过滤系统,主要功能是预测用户对物品的评分和偏好。
作者认为,推荐系统的核心是“链接”用户和信息,既可以帮助用户发现他们感兴趣的信息,也可以将信息推送给感兴趣的用户。
经过20多年的积累和沉淀,推荐系统已经发展成为一门独立学科。它不仅应用广泛,还与很多其他跨学科知识和技术有着很强的关联性,比如人工智能、心理学、市场营销等。
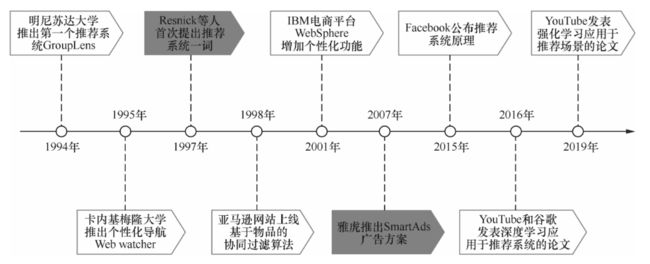
不仅如此,国内外很多大厂都专研了相关理论和技术,比如Youtube、华为等国内外知名企业。
这样一门普及度高、覆盖面广、实用性强的技术,想必不论是从就业还是应用的角度,推荐系统对于开发者的吸引力都极强!
与此同时,推荐系统在互联网时代所面临的挑战与日俱增,需要从企业和用户端同时着手解决问题:
▮ 企业端:如何做到千人千面,为每个用户提供个性化的服务,提升产品的使用率和用户黏性?
▮ 用户端:面对海量的信息,如何高效检索自己感兴趣的内容?
想了解这些疑问,请各位开发者跟随小艾继续往下看。
二、行业老兵拆解大厂技术细节
除了对理论与问题的深入阐释,作者也以一个行业资深老兵的身份,对诸多论文与实践的技术细节都进行了深入解读:
YouTube 算法工程师的论文“Deep Neural Networks for YouTube Recommendations”指出了将优化用户观看时长设为最终优化目标的建模方法。根据另一篇有关强化学习的论文“Top- KOff-Policy Correction for a REINFORCE Recommender System”,模型上线后总的用户观看时长提升 0.86%。

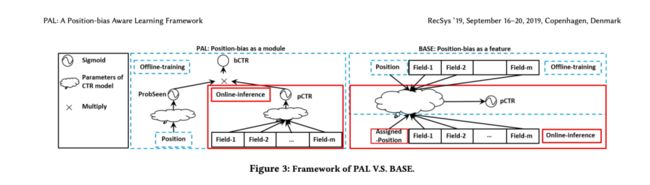
华为发表了PAL模型相关论文来解决位置偏置(position bias)问题,主要通过联合训练来消除这个问题,这样用户可以在更优的位置看见被推荐的信息。
阿里巴巴的淘宝算法推荐团队提出了将优势特征蒸馏(Privileged Features Distillation,PFD)应用于淘宝推荐,CTR提升5%,CVR提升2.3%。此后,爱奇艺借鉴阿里妈妈提出的Rocket Training,最终,爱奇艺短视频场景响应时长提升6.5%,点击率提升2.3%;图文推荐场景响应时长提升4.5%,点击率提升14%。

阿里定向广告的新一代粗排架构COLD则是新的算法和算力联合迭代视角下的产物。COLD把算力作为变量进行优化,可以实现效果和算力的平衡。它的训练和在线打分都是实时的,可以更好地适用数据分布的变化。COLD已经在阿里定向广告的各个主要业务上得到广泛应用并取得了显著的效果。

相信如此细致的技术剖析,会让你在翻看本书时眼前一亮!
三、掌握核心基础:在线模块4大阶段
在作者看来,推荐系统本质上是为了解决“用户”和“资源”的匹配问题。
为了满足这个要求,实践中可以将推荐系统按功能模块划分为离线、近线、在线和前端应用 4个模块。
其中最重要的是在线模块,因为它决定了“向用户推送什么”和“用户会看到什么”这两个核心问题,本书也将围绕推荐系统的在线模块展开讲解。

从图中可以看出,在线模块一般分为召回、粗排、精排和重排 4 个阶段。
▮ 召回阶段:主要根据用户部分特征,从海量信息里快速找出用户潜在感兴趣的内容,然后进入排序阶段。
传统的个性化召回主要基于协同过滤和矩阵分解,最近发展起来的模型化召回主要包括图表征召回、浅层模型化召回、深度匹配模型化召回以及语言模型化召回。
▮ 粗排阶段:通过少量用户和物品特征,使用简单模型对召回的结果进行简单排序。
粗排的目标是在满足算力约束的前提下,选出满足后链路需求的集合。与精排相比,粗排主要有算力约束和解空间问题两个特点:粗排有较严格的延迟约束,一般在 50ms 以内;线上打分的候选集更大,往往是精排候选集的数十倍。
▮ 精排阶段:精排是对候选集进行精准排序。
精排阶段是推荐系统最关键、最具技术含量的部分,也是大多数推荐技术聚焦提升的部分。特征工程及特征交叉的自动化一直是推动推荐系统技术演进最主要的方向。
▮ 重排阶段:选出满足数据多样性的最优组合,以及实现整体收益的最大化。
从整屏效果出发,精排给出的 Top-K 不一定是最优解,还要考虑上下文信息,因此需要重排再次优化。
这4个阶段不仅是推荐系统的基础,也是本书的脉络所在,全书内容均围绕这几个阶段展开。
可以看出,除了常用的手段,模型技术已经开始赋能在线模块的各个阶段,作者在书中也充分阐述了如何解决相关的痛点。
四、攻克难题,让推荐系统更丝滑
正如前文多次提到的,模型技术已经融入了推荐系统的开发。当然,在实际的模型训练中也出现了新的问题:
一方面,模型的损失函数无法得到较低的值,没有真正收敛;另一方面,模型在训练集上拟合得很好,损失函数的值很低,但是在测试集上的效果却没有那么好。
如果能解决上述问题,推荐系统无疑会更加丝滑顺畅,给用户更好的体验感。

让我们看看作者是如何阐述解决方案的。
首先,这两个问题分别对应欠拟合和过拟合的概念。
▮ 欠拟合:指模型无法得到较低的训练误差
▮ 过拟合:指模型的训练误差远小于泛化误差
与这两个问题息息相关的因素是模型复杂度和训练集大小。平衡好这两个因素,就能解决欠拟合和过拟合问题。书中给出了如下思路。
一般来说,处理欠拟合通常有加大模型的规模、增加特征规模、减少正则化、修改模型结构这几种方法,每一种方法都各有特色:
▮ 加大模型的规模:使算法更好地拟合训练集,从而防止欠拟合。
▮ 增加特征规模:如果增加特征引起了过拟合,可以加入正则化来抵消。
▮ 减少正则化:通过减少 L1 正则、L2 正则或 dropout避免模型欠拟合。
▮ 修改模型结构:比如修改神经网络模型结构,可以同时影响训练误差和泛化误差。
与之对应的,处理过拟合的办法则包括减小模型规模、添加更多的训练数据、加入正则化、提前终止模型训练、通过特征选择减少特征的数量和种类等。
可以看出,过拟合与欠拟合对应的是相反的问题,因此大多数技术手段也是相反的。
过往,受限于技术水平,开发者需要在欠拟合和过拟合之间进行权衡。如今,数据可得性提升、算力更强,需要权衡的情况在变少,并且支持在不增加模型训练误差的同时降低泛化误差,推荐系统必将更加精准和人性化。
五、研发一线专家亲授,这些人最爱学
读到这里,你会发现本书的脉络清晰、实践性强,对相关从业人员的技术困惑点把握得也更加细致。
这主要是因为作者文亮本身就是一名一线研发人员,拥有超过5年的机器学习与推荐系统实践经验,作为奇虎360推荐场景的核心研发人员,曾主导深度学习在奇虎360信息流推荐场景的落地工作。独具优势的背景让他能在书中兼顾系统性的理论和实践。
在作者看来,下面3类人群是最适合本书的目标读者:
▮ 相关领域的开发人员:深入学习推荐系统的完整技术结构,并应用于业务工作中。
▮ 有机器学习基础、想进入推荐系统领域的初学者:了解推荐系统的技术原理以及大型互联网公司的业务实践。
▮ 计算机相关专业学生:从零开始了解推荐系统的知识体系。
此外,对推荐系统感兴趣的产品研发人员和运营人员也可以酌情阅读。
除了到位的基础知识和实践案例,书中还设置了“补充知识”板块来解读易被忽视的技术原理,每一章末尾还有汇总表格提炼精华技术方案。

同时,异步社区(https://www.epubit.com/)也会一如既往地提供相关资源和后续服务。
六、AI+未来势不可挡,小艾邀你乘风破浪
如今,AI+推荐已经成为很多领域的一种趋势,通过数据分析、智能推荐等方式,为消费者提供更加个性化、精准的服务。
相信在未来,随着人工智能技术不断发展,推荐算法也会越来越成熟,在更多领域得到应用。希望读者能够以此书为契机,搭上这列数字化时代的快车!
文末福利
《推荐系统技术原理与实践》免费包邮送出5本!
- 抽奖方式:评论区随机抽取5位小伙伴免费送出!
- 参与方式:关注博主、点赞、收藏、评论区评论“人生苦短,拒绝内卷!”(切记要点赞+收藏,否则抽奖无效,每个人最多评论三次!)
- 活动截止时间:2023-08-12 20:00:00
- 购买链接:《推荐系统技术原理与实践》
名单公布时间:2023-08-12 21:00:00