MySQL索引特性
目录
一、索引
二、MySQL 与磁盘交互基本单位
三、索引的理解
一、索引
为什么要有索引?
首先我们插入一个8000000条记录的数据,再来查询数据,看看没有索引的情况下,会耗费多长时间。

当执行完这几条命令时,我们会发现数据量很大,所占内存为:565mb。![]()
当我们选择显示所有数据,当然mysql会阻塞住,数据量太大了。

当我们强制的展示所有的数据时,mysql会被操作系统kill掉,因为mysql检索数据需要将文件中的数据加载到内存中,当操作系统检测到mysql占用太多内存资源,就会将mysql这个进程终止。

我们只能aborted掉,我们可以指定某个数来查询。

仅仅如此都耗费了3.54sec,这次我们来建立索引看看效果。

我们会发现效果显著。
二、MySQL 与磁盘交互基本单位
而 MySQL 作为一款应用软件,可以想象成一种特殊的文件系统。它有着更高的IO场景,所以,为了提高 基本的IO效率, MySQL进行IO的基本单位是16KB (后面统一使用 InnoDB 存储引擎讲解)。
16 * 1024 = 16384。

之前的博客讲到过我们操作系统与磁盘交互的基本单位是4KB。 MySQL 进行IO的基本单位是 16KB,意味着单次的IO效率更高,这个基本数据单元,在 MySQL这里叫做page。
三、索引的理解
建立测试表。
![]()
无序的插入数据。
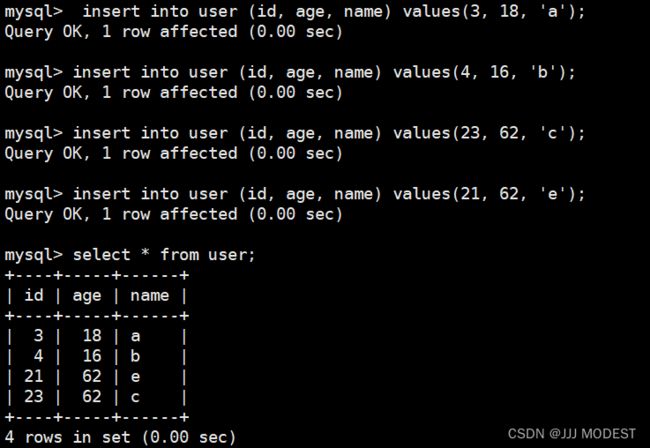
我们会发现数据是有序排列的。
不同的page都是16kb,使用prev 和 next 构成双向链表。

因为有主键的问题, MySQL 会默认按照主键给我们的数据进行排序,从上面的Page内数据记录可以看 出,数据是有序且彼此关联的。
插入数据时排序的目的,就是优化查询的效率。

这样,我们就可以通过多个Page遍历,Page内部通过目录来快速定位数据。可是,貌似这样也有效率问 题,在Page之间,也是需要 MySQL 遍历的,遍历意味着依旧需要进行大量的IO,将下一个Page加载到 内存,进行线性检测。这样就显得我们之前的Page内部的目录,有点杯水车薪了。
所以我们在Page中放入其他Page的目录,通过目录检索Page,便方便很多。

将整个模型完整表述就是这样的:
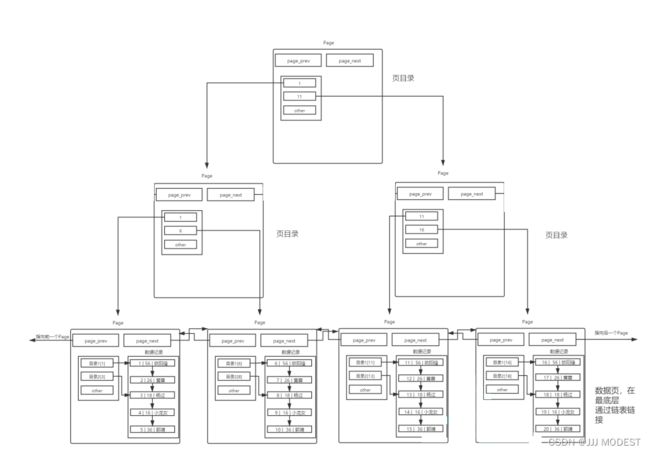 这就是B+树。
这就是B+树。
B+树的结构特点:
1.非叶子节点不存储真正数据,存储page指针与页目录,只具有索引功能。
2.叶子节点彼此之间相连接
为什么不用B树?
B树:

我们可以发现他的非叶子结点不仅携带索引信息也携带数据,并且叶子结点之间不相连。
Mysql中不以B树作为建立索引的底层数据结构,原因就是 1. B树非叶子结点携带数据,就不能存储更多的目录 2.叶子节点没有连接,不便于范围查找。
聚簇索引 VS 非聚簇索引
如今我们现在所学习到的就是聚簇索引。B+树和数据耦合在一起。
InooDB存储引擎存储数据采用聚簇索引。
那非聚簇索引为结构与数据不存放在一起。
像MyISAM存储引擎采用非聚簇索引。其中叶子节点中存储的是存放数据的地址,而不是数据本身。

user1与user都是表结构只不过使用的是不同的存储引擎。
user表采用InnoDB引擎,采用聚簇索引,user.ibd文件中存放的为数据与索引。
user1表采用MyISAM引擎,采用非聚簇索引,user1.MYI存放索引,user1.MYD存放数据。
我们还需要知道:
1.具有主键的表,每一个表都有一个B+树。
2.而没有主键的表会有隐藏的主键来协助生成B+树。
3.内存加载数据时,不一定需要将B+树全部加载,而是按需加载。
为什么其他结构不行?
1.二叉搜索树,深度过深,意味着内存中要加载的数据就会很多,所以系统和硬盘的IO的次数增多,并且有可能退化成线性结构,效率更低。
2.AVL&&红黑树,深度深,系统和硬盘的IO的次数增多。
3.Hash,MySQL 是支持HASH的,不过 InnoDB 和 MyISAM 并不支持。