图像算法助力提效转转商品审核
文章目录
-
- 一、商品审核背景介绍
- 二、自动审核方案
- 2.1、商品展示图和对应的sku信息是否一致
- 2.2、商品拍摄是否清晰
- 2.3、商品是否贴了防拆标、是否脏污、是否处于中心区域
- 2.4、算法的应用策略
- 三、总结
一、商品审核背景介绍
转转是一家主营二手商品交易的电商平台。根据交易主体的不同,可以形成C2C、C2B、B2C等交易关系。比如个人用户在转转app的自由市场发布商品进行售卖属于C2C模式、转转公司提供手机和其他电子产品的邮寄与上门回收C2B服务,转转app还提供官方验和质保与售后的二手B2C商品。本文将重点介绍转转 B2C 卖场商品上架审核过程中图像算法的应用。
由于二手商品的非标品性质,即便同一sku下的不同库存商品间也存在着成色差异。平台为了提升用户体验,增加商品信息的透明度,在展示二手商品时全部采用实拍商品图,避免使用渲染的标品图片。这就涉及到对每个上架商品的相关展示图片进行信息准确性、图片质量等各方面的审核问题。
业务发展初期,上架商品的相关展示图片均由人工审核来保证图片的质量和准确性,审核的内容主要有以下几个方面:
- 展示图与实际商品是否一致,避免“货不对板”的情况出现;
- 展示图照片是否清晰,流水化作业的商品图拍摄过程中偶尔会出现相机对焦失误的情况;
- 手机、平板电脑等电子产品需要保证没有脏污,并在重点部位贴防拆标;
- 为了商品图片在app中的展示效果,要对商品图进行适当剪裁使得商品在图片中居中。
随着业务的发展,每日上架商品日益增多,人工审核在审核效率和准确性上逐渐暴露出了一些问题:
- 审核工作枯燥、易疲劳,人工审核出错概率较高;
- 图片清晰度的判断偏主观,不同审核人员之间的审核标准很难拉齐;
- 人工审核处理量已经逐渐落后于商品上架量,对于卖场商品的发布造成了瓶颈。
针对审核内容里面的重复性工作,我们使用了图像领域相关的分类、回归、检测等技术,用算法模型输出辅助人工判断,在提升了审核结果的准确度的同时大幅提升了审核流程的效率。
二、自动审核方案
上架审核需要审核的内容包括以下几点:
- 商品展示图和对应的sku信息是否一致。
- 商品拍摄是否清晰。
- 商品是否贴了防拆标。
- 商品是否脏污。
- 商品是否处于图像中心区域。
针对需要审核需要,我们设计了如下解决方案:
需要审核的项目 解决方案 商品展示图和对应的sku是否一致 图像匹配 商品拍摄是否清晰 回归方案 商品是否贴了防拆标 检测方案 商品是否脏污 检测方案 商品是否处于图像中心区域 检测方案
下图给出了B2C商品上架审核主要的审核项示意图:
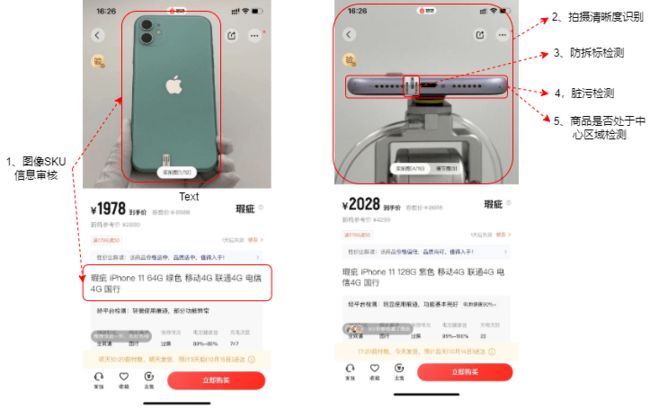
2.1、商品展示图和对应的sku信息是否一致
商城售卖商品都需要对商品进行实物拍照展示,但是在商品上架到商城的过程中,由于人工失误等情况,会出现商品展示图和对应的sku信息不匹配的情况。举个简单的例子,商品的sku信息是iphone11-红色,但是展示图却是iphoneX-绿色。
这个问题可以和图像分类问题对应上,相当于根据图像信息,判断商品类别。但是简单的使用分类算法无法很好的解决我们的问题,直接使用分类存在以下问题:
- 类别是有限的,不管输入图像是否在类别中,都一定会输出一个类别。
- 由于类别的固定,导致无法处理新增的sku。
由于分类方法存在上面的问题,我们改变了策略,使用图像匹配的方案。我们训练一个较好的特征提取器,再使用图像匹配方案,就可以较好的解决新加类别的问题。我们选取的方案和学术中的Face Recognition 、Person Re-Identification、Image Retrieval等方向的解决方案基本一致,主要流程包括图像特征提取、图像相似度计算、排序、输出结果。其中图像特征提取这块是大家研究的重点方向,传统图像匹配特征包括SIFT、SURF、ORB特征等,基于深度学习的图像特征提取主要是CNN神经网络进行特征提取。下图给出了我们的方案:
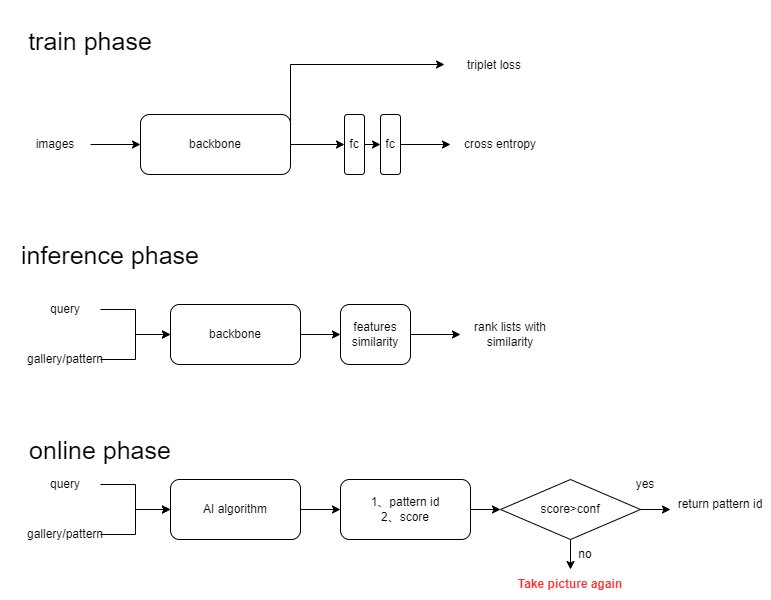
训练阶段:
训练阶段主要是使用交叉熵损失联合三元组损失训练一个分类网络,其中骨干网络尝试了MobileNet、ResNet、ShuffleNet、OSNet等。我们的实验结果显示ResNet模型的精度略高,因此选取了ResNet作为我们的骨干网络。
L = − 1 N ∑ i N ( y i log ( p i ) + ( 1 − y i ) log ( 1 − p i ) ) \begin{equation} L=-\frac 1N\sum_{i}^N{(y_i\log(p_i) + (1 - y_i)\log(1 - p_i))} \end{equation} L=−N1i∑N(yilog(pi)+(1−yi)log(1−pi))
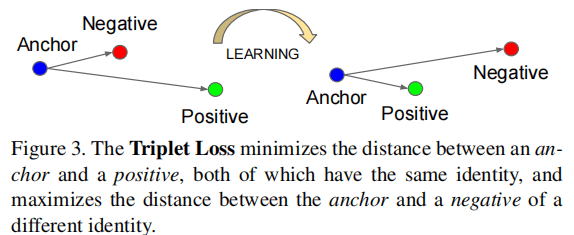
L = ∑ i N [ ∣ ∣ f ( x i a ) − f ( x i p ) ∣ ∣ 2 2 − ∣ ∣ f ( x i a ) − f ( x i n ) ∣ ∣ 2 2 + α ] + \begin{equation} L =\sum_{i}^N [||f(x_i^a)-f(x_i^p)||_2^2-||f(x_i^a)-f(x_i^n)||_2^2+\alpha ]_+ \end{equation} L=i∑N[∣∣f(xia)−f(xip)∣∣22−∣∣f(xia)−f(xin)∣∣22+α]+
公式1给出的是二分类交叉熵损失函数,其中 p i p_i pi表示样本 i i i的输出值, y i y_i yi表示样本 i i i对应的标签。
公式2给出了三元组损失函数, f ( x i a ) f(x_i^a) f(xia)表示锚点样本 i i i对应的特征向量, f ( x i p ) f(x_i^p) f(xip)表示与锚点样本 i i i类别相同的样本对应的特征向量, f ( x i n ) f(x_i^n) f(xin)表示与锚点样本 i i i不同类别的样本对应的特征向量。特征空间内,负样本距离锚点样本的距离减去正样本到锚点的距离应大于 α \alpha α。
交叉熵损失函数是常见的分类损失函数,三元组损失函数是人脸识别、行人重识别中常用的损失函数。三元组损失函数,可以使特征在特征空间呈现一簇一簇的特征,其带来的好处就是可以得到更加鲁棒的特征。若单独使用三元组损失函数,模型的收敛速度较慢,因此我们使用交叉熵损失和三元组损失进行联合监督学习,以加速模型收敛,同时提升模型精度。
测试阶段:
测试阶段选取训练好的backbone做特征提取器,用来提取embedding特征。提取查询图像特征并与gallery库中的特征计算余弦相似度,得到相似性排序列表,再选取排序列表中top1图像对应的类别作为查询图像的类别输出。但是我们在构建gallery时,一个sku存放了三张图像,对应着不同的拍摄场景,因此我们对top5输出进行knn后得到查询图像对应的sku。
上线运行:
为了保证匹配算法输出的sku一定是准确的,我们输出了排序列表中的top1相似度,当相似度小于一定值threshold时,会输出报警信息,进行人工审核。这个策略保证了算法输出的sku信息准确性。
2.2、商品拍摄是否清晰
拍摄商品的过程中,由于商品移动或者没对好焦距,导致拍摄出的商品较为模糊。为了给用户带更好的购物体验,我们会在审核的过程中打回这些商品,重新拍出符合要求的商品图后才能上架。单纯针对图像拍照是否清晰,可以理解为图像分类问题。由于图像是否模糊的标注具有主观性,同时二分类无法很好的刻画出图像的模糊度,因此在实际的审核过程中,一线审核人员对于轻微模糊的图像往往会给出不同的判定结果,这类情况大大的影响了审核结果的一致性,导致商城中的商品展示效果有好有坏。
为了解决上面的问题,我们把图像的模糊度分为三个级别,模糊度由高到低分别是明显模糊、轻微模糊、清晰。并给出对应的分值,分别为2,1,0分。多人对同一张图进行打分,并去掉同时出现打分为明显模糊和清晰的图像,剩余的图像进行数值归一化,得到图像的模糊度分值。当然,我们可以把模糊程度细分为四类,比如明显模糊,轻微模糊、细微模糊、清晰,并且让更多的标注人员标注同一张图,这样我们可以得到更加细腻的标签值,这样也能带来更好的预测结果。但是鉴于资源有限,我们只把模糊度划分为三个级别,让三个同学进行标注。由此,我们把二分类问题转化为了回归问题,并且可以很好的隔离开业务标准。下面的表格给出了我们如何把分类任务变成回归任务。
图片名 同学一打分 同学二打分 同学三打分 总分(0-6) 归一化得分 图片1 明显模糊 轻微模糊 明显模糊 5 5/6=0.83 图片2 轻微模糊 轻微模糊 明显模糊 4 4/6=0.67 图片3 清晰 轻微模糊 清晰 1 0.17 … … … … … …
M S E = ∑ i N ( y i − y i ^ ) 2 \begin{equation} MSE =\sum_{i}^N (y_i-\hat{y_i}) ^2 \end{equation} MSE=i∑N(yi−yi^)2
同样的,我们还是使用卷积神经网络,然后把分类损失函数变成回归损失函数,我们选用了MSE作为回归任务的损失函数,其中 y i ^ \hat{y_i} yi^表示样本 i i i的预测值, y i y_i yi表示样本的标签。
模型的输出值代表图像的模糊程度,我们把二分类任务变成回归任务后,可以带来诸多好处。首先就是算法开发与业务解耦合,不会因为业务标准的变更导致算法模型失效;同时业务方可以根据业务需求设置不同的模糊度阈值用来控制商城图像的清晰程度。
2.3、商品是否贴了防拆标、是否脏污、是否处于中心区域
针对商品是否贴了防拆标、是否脏污、是否处于中心区域问题,我们使用检测方案。这三个项中,防拆标和物品的检测都较为简单。防拆标检测中的防拆标特征单一,因此比较容易训练出一个检测准确率相当模型;商品是否居中检测中,物品较大,且数据好收集,也能训练出一个准确率相当高的商品检测模型。
脏污的检测则比较困难,因为部分脏污目标较小,且样本不易获取。针对这个问题,我们在数据收集的过程中选取主动学习的策略去寻找到更多正样本(检测任务中的正样本指的是我们需要检测的样本类)。其方式也很简单,我们在初期使用一批数据训练检测模型,随后用该模型以非常低的置信度在大批量未标注的数据中选取可疑正样本,再让人工对该批数据进行标注,随后再用新数据更新训练模型,这便是一轮循环。我们可以多次重复该步骤,最后可以得到一个媲美人工的检测模型。
2.4、算法的应用策略
对于计算机视觉中常见的分类、检测等任务,我们无法同时保证模型的召回和精度同时达到100%的指标,因此在实际的应用过程中,需要结合实际业务,考虑选取模型是采用高精度还是高召回的状态。下图给出了召回率和精度关系的曲线图(图片来源于周志华老师的<机器学习>一书)
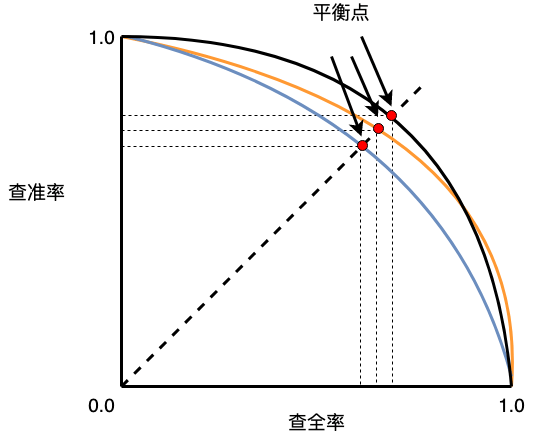
针对我们的审核业务,我们采取的是高召回策略,也就是保证模型可以尽可能把不符合要求的商品图都找出来,其代价就是精度会相应的降低。我们召回有拍摄有问题商品后,会人工介入审核,因此那些被误召回的例子不会对业务造成影响。
在算法的辅助下,目前上架审核同学的工作量降低了50%。经过算法的商品图像中,有50%的商品通过算法,可以直接上架到商城app,剩余的疑似有问题的商品都会被算法识别出来,然后再人工复审。
三、总结
我们在第一节介绍了商品上架审核的背景,我们为什么要审核以及审核的内容,同时分析了当前业务中人工审核面临的一些问题,然后给出了算法赋能业务带来的好处。
在第二节,我们详细的介绍了算法模块。根据上架审核项的不同,我们采用了三种方式分别去解决三个不同的任务。并介绍了算法应用落地所选取的高召回率牺牲预测精度的方案,以及这种方案的可行性,最后给出了算法上线取得的效果。
转转研发中心及业界小伙伴们的技术学习交流平台,定期分享一线的实战经验及业界前沿的技术话题。
关注公众号「转转技术」(综合性)、「大转转FE」(专注于FE)、「转转QA」(专注于QA),更多干货实践,欢迎交流分享~