IBM HR Analytics 员工流失 EDA 和可视化绩效分析
IBM HR Analytics 员工流失与绩效分析
- 背景
- 导入库
- 输出前五行
- 数据清洗
-
- 检查空值
- 删除不必要的列
- 可视化
-
- 商务旅行直方图
- 离家的距离箱形图
- 教育与数字公司的关系
- 年龄和月收入散点图
- 按教育领域和工作角色划分的工作满意度
- 相关矩阵的交互式热图
背景
揭示导致员工流失的因素,并探讨重要问题,例如“按工作角色和流失情况显示离家距离的详细信息”或“按教育程度和流失情况比较平均月收入”。这是由 IBM 数据科学家创建的虚构数据集。
-
教育程度
1 ‘大专以下’
2 ‘大专’
3 ‘学士’
4 ‘硕士’
5 ‘博士’ -
环境满意度
1 “低”
2 “中”
3 “高”
4 “非常高” -
工作投入度
1 “低”
2 “中”
3 “高”
4 “非常高” -
工作满意度
1 “低”
2 “中”
3 “高”
4 “非常高” -
绩效评级
1 ‘低’
2 ‘好’
3 ‘优秀’
4 ‘杰出’ -
关系满意度
1 “低”
2 “中”
3 “高”
4 “非常高” -
工作与生活平衡
1 “差”
2 “好”
3 “更好”
4 “最好”
文件中列名
| Age | 年龄 |
|---|---|
| Attrition | 消耗 |
| BusinessTravel | 商务旅行 |
| DailyRate | 每日比率 |
| Department | 部门 |
| DistanceFromHome | 离家距离 |
| Education | 教育 |
| EducationField | 教育领域 |
| EmployeeCount | 员工帐户 |
| EmployeeNumber | 员工数量 |
| EnvironmentSatisfaction | 环境满意度 |
| Gender | 性别 |
| HourlyRate | 小时比率 |
| JobInvolvement | 工作投入 |
| JobLevel | 工作级别 |
| JobRole | 工作角色 |
| JobSatisfaction | 工作满意度 |
| MaritalStatus | 婚姻状况 |
| MonthlyIncome | 每月收入 |
| MonthlyRate | 月费率 |
| Num CompaniesWorked | 工作的公司数量 |
| Over18 | 18以上 |
| OverTime | 加班 |
| Percent SalaryHike | 百分比工资 |
| PerformanceRating | 绩效评级 |
| RelationshipSatisfaction | 关系满意度 |
| StandardHours | 标准工时 |
导入库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
import plotly.express as px
import seaborn as sns
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
输出前五行
df = pd.read_csv('/kaggle/input/ibm-hr-analytics-attrition-dataset/WA_Fn-UseC_-HR-Employee-Attrition.csv')
df.head()

df.dtypes
Age int64
Attrition object
BusinessTravel object
DailyRate int64
Department object
DistanceFromHome int64
Education int64
EducationField object
EmployeeCount int64
EmployeeNumber int64
EnvironmentSatisfaction int64
Gender object
HourlyRate int64
JobInvolvement int64
JobLevel int64
JobRole object
JobSatisfaction int64
MaritalStatus object
MonthlyIncome int64
MonthlyRate int64
NumCompaniesWorked int64
Over18 object
OverTime object
PercentSalaryHike int64
PerformanceRating int64
RelationshipSatisfaction int64
StandardHours int64
StockOptionLevel int64
TotalWorkingYears int64
TrainingTimesLastYear int64
WorkLifeBalance int64
YearsAtCompany int64
YearsInCurrentRole int64
YearsSinceLastPromotion int64
YearsWithCurrManager int64
dtype: object
数据清洗
检查空值
df.isna().sum()
Age 0
Attrition 0
BusinessTravel 0
DailyRate 0
Department 0
DistanceFromHome 0
Education 0
EducationField 0
EmployeeCount 0
EmployeeNumber 0
EnvironmentSatisfaction 0
Gender 0
HourlyRate 0
JobInvolvement 0
JobLevel 0
JobRole 0
JobSatisfaction 0
MaritalStatus 0
MonthlyIncome 0
MonthlyRate 0
NumCompaniesWorked 0
Over18 0
OverTime 0
PercentSalaryHike 0
PerformanceRating 0
RelationshipSatisfaction 0
StandardHours 0
StockOptionLevel 0
TotalWorkingYears 0
TrainingTimesLastYear 0
WorkLifeBalance 0
YearsAtCompany 0
YearsInCurrentRole 0
YearsSinceLastPromotion 0
YearsWithCurrManager 0
dtype: int64
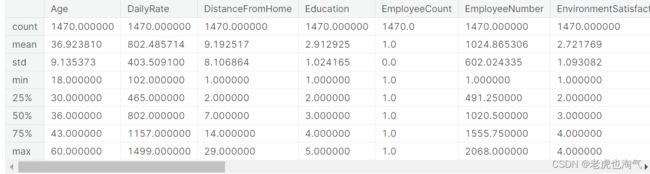
df.describe()
df.Age.unique()

我们可以看到,有些列可以删除,因为它们没有增加任何价值:
a.员工数量
b.员工人数
C.标准工作时间:每个人工作80小时
d.18岁以上:所有工作的人都在18岁以上
删除不必要的列
df= df.drop(['EmployeeCount','EmployeeNumber','Over18','StandardHours'],axis = 1)
可视化
商务旅行直方图
sns.histplot(data=df, x='BusinessTravel', element='step', color='purple', stat='percent')

我们可以看到大多数工作需要员工出差,但很少。大约20%的工作需要经常出差,10%没有出差。
离家的距离箱形图
sns.boxplot(data=df, y='DistanceFromHome', color='green')

从这个箱线图中,我们可以看到,员工平均要走7公里才能到达办公室,其中75%的员工要走1到14公里才能到达办公室。让我们看看离家的距离和损耗之间是否有任何关系
1.根据百分位数划分数据
cut_labels = ['Near', 'Reasonable', 'Far']
cut_bins = [-1, df['DistanceFromHome'].quantile(0.33), df['DistanceFromHome'].quantile(0.67), df['DistanceFromHome'].max() + 1]
df['DistanceGroup'] = pd.cut(df['DistanceFromHome'], bins=cut_bins, labels=cut_labels)
2.计算每组的退出概率
probabilities = df.groupby('DistanceGroup').apply(lambda group: sum(group['Attrition'] == 'Yes') / len(group)).reset_index()
probabilities.columns = ['DistanceGroup', 'Probability']
3.绘制这些概率
plt.figure(figsize=(10, 6))
sns.barplot(x='DistanceGroup', y='Probability', data=probabilities, order=cut_labels)
plt.title('Probability of Attrition by Distance Group')
plt.ylabel('Probability of Quitting')
plt.xlabel('Distance from Home Group')
plt.show()

我们可以看到,与住在附近或合理距离的人相比,住得远的人戒烟的概率更高
教育与数字公司的关系
sns.barplot(data=df, y='NumCompaniesWorked', x='Education', palette='Set3')
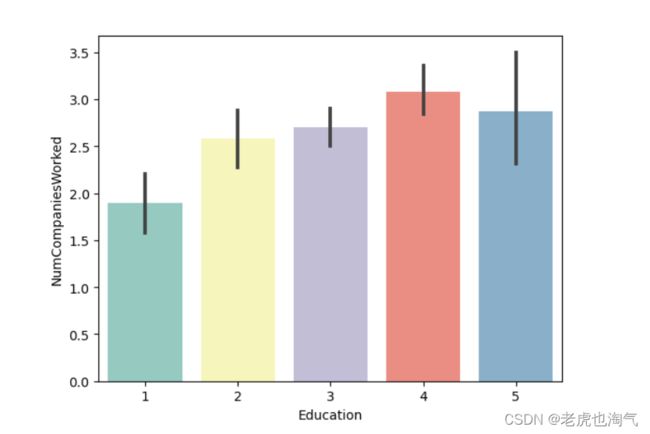
我们可以看到,平均而言,上过高中的人换工作的频率较低。然而,拥有硕士学位的人更容易流失
年龄和月收入散点图
sns.scatterplot(data=df, x='Age', y='MonthlyIncome')

从散点图中,我们可以看到,随着人们年龄的增长,高薪的机会越来越多,年长的雇员往往挣得更多,然而,工资差距也在扩大。
sns.scatterplot(data=df, x='Age', y='TotalWorkingYears', hue='Attrition')
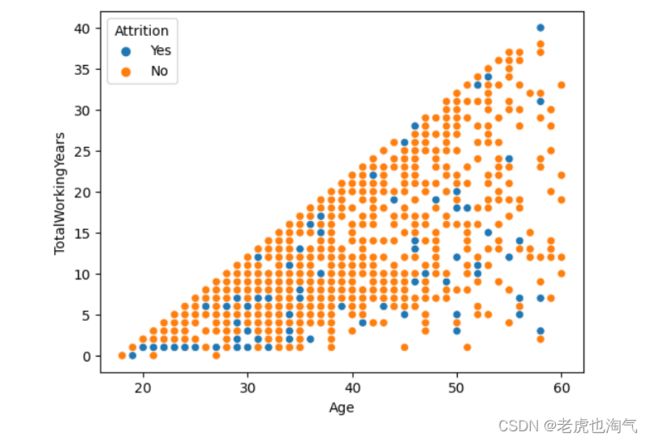
从散点图来看,与经验丰富的同行相比,刚开始职业生涯的人通常更容易辞职
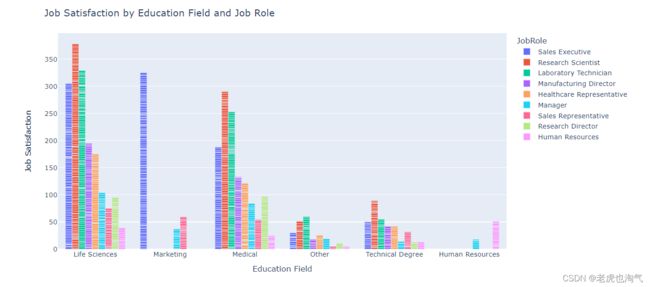
按教育领域和工作角色划分的工作满意度
fig = px.bar(df, x='EducationField', y='JobSatisfaction', color='JobRole', barmode='group')
fig.update_layout(
xaxis_title='Education Field',
yaxis_title='Job Satisfaction',
title='Job Satisfaction by Education Field and Job Role')
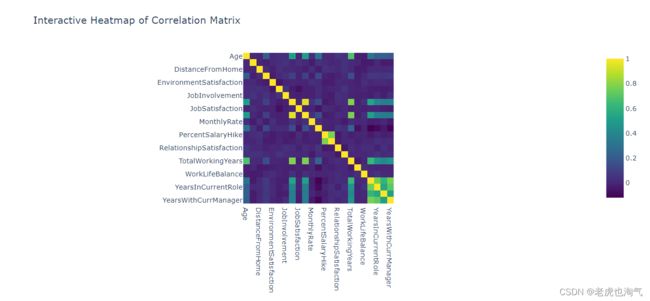
相关矩阵的交互式热图
correlation_matrix = df.corr()
fig = px.imshow(correlation_matrix, color_continuous_scale='Viridis', title='Interactive Heatmap of Correlation Matrix')
fig.show()