Pytorch深度学习-----损失函数(L1Loss、MSELoss、CrossEntropyLoss)
系列文章目录
PyTorch深度学习——Anaconda和PyTorch安装
Pytorch深度学习-----数据模块Dataset类
Pytorch深度学习------TensorBoard的使用
Pytorch深度学习------Torchvision中Transforms的使用(ToTensor,Normalize,Resize ,Compose,RandomCrop)
Pytorch深度学习------torchvision中dataset数据集的使用(CIFAR10)
Pytorch深度学习-----DataLoader的用法
Pytorch深度学习-----神经网络的基本骨架-nn.Module的使用
Pytorch深度学习-----神经网络的卷积操作
Pytorch深度学习-----神经网络之卷积层用法详解
Pytorch深度学习-----神经网络之池化层用法详解及其最大池化的使用
Pytorch深度学习-----神经网络之非线性激活的使用(ReLu、Sigmoid)
Pytorch深度学习-----神经网络之线性层用法
Pytorch深度学习-----神经网络之Sequential的详细使用及实战详解
文章目录
- 系列文章目录
- 一、损失函数是什么?
-
- 1.常见的损失函数及其解释
- 2.实战
-
- 2.1. 范数损失L1 Loss
- 2.2. 均方误差损失MSE Loss
- 2.3. 交叉熵损失CrossEntropyLoss
- 3.在神经网络模型中使用交叉熵损失函数
一、损失函数是什么?
在PyTorch深度学习中,损失函数(Loss Function)是一个用于计算模型预测输出和实际输出之间的误差的函数。它用于衡量模型的性能,并通过反向传播算法更新模型的权重和参数,以减小预测输出和实际输出之间的误差。
1.常见的损失函数及其解释
均方误差损失(MSE Loss): MSE Loss是一种常用于回归问题的损失函数。它计算预测输出和实际输出之间的均方误差,即预测值与实际值之差的平方的平均值。MSE Loss对于数据的高斯分布假设较为合理,适用于预测连续变量的任务。
交叉熵损失(Cross-Entropy Loss): 交叉熵损失是一种常用于分类问题的损失函数。它衡量的是两个概率分布之间的差异。在PyTorch中,可以使用torch.nn.CrossEntropyLoss来实现交叉熵损失。这个类结合了LogSoftmax和NLLLoss(负对数似然损失)两个操作,使得模型在训练时更加高效。交叉熵损失对于数据的伯努利分布假设较为合理,适用于分类任务。
L1范数损失(L1 Loss): L1 Loss计算预测输出和实际输出之间的绝对值差值的平均值。相比MSE Loss,L1 Loss对异常值不敏感,因此在处理存在异常值的数据集时可能更加适合。L1 Loss也被称为Mean Absolute Error (MAE)。
Softmax交叉熵损失(Softmax Cross-Entropy Loss): Softmax交叉熵损失是用于多分类任务的损失函数。它首先将模型的输出通过Softmax函数转换成概率分布,然后计算该分布与实际分布之间的交叉熵损失。这个损失函数可以用于解决多分类问题。
官网中关于损失函数(部分)如下图所示
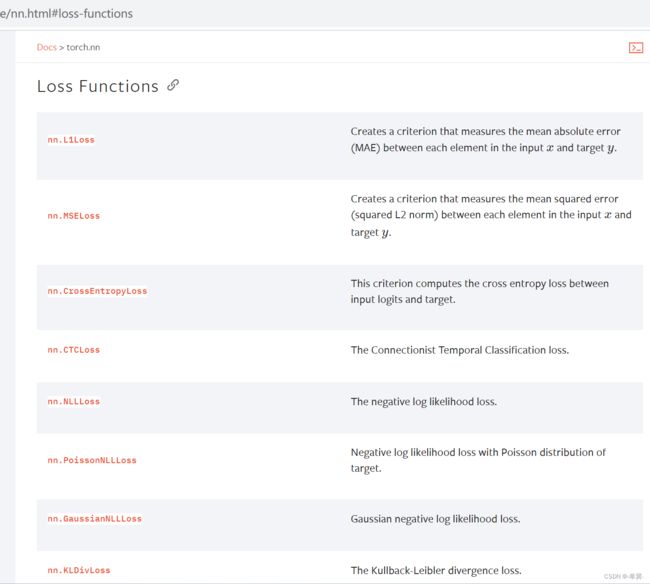
2.实战
2.1. 范数损失L1 Loss
torch.nn.L1Loss(size_average=None, reduce=None, reduction='mean')
参数解释:
size_average(可选,默认为 None):这是一个布尔值或整数,用于指定是否对所有输入批次的输出进行平均。如果设置为 True,则对所有输入批次的输出进行平均。如果设置为整数 n,则对前 n 个输入批次的输出进行平均。如果设置为 None,则根据 reduce 参数的值决定是否进行平均。
reduce(可选,默认为 None):这是一个布尔值,用于指定是否对输入批次的输出进行减少。如果设置为 True,则对输入批次的输出进行减少,返回一个标量。如果设置为 False,则返回每个输入批次的输出的张量。如果 size_average 和 reduce 都为 None,则根据 reduction 参数的值决定是否进行减少和平均。
reduction(可选,默认为 ‘mean’):这是一个字符串,用于指定如何对输入批次的输出进行减少。可选的值有 ‘mean’、‘sum’ 和 ‘none’。如果设置为 ‘mean’,则对输入批次的输出进行平均。如果设置为 ‘sum’,则对输入批次的输出求和。如果设置为 ‘none’,则不进行减少,返回每个输入批次的输出的张量。
计算公式:
即平均绝对误差

代码实践
import torch
# 实例化
criterion1 = torch.nn.L1Loss()
criterion2 = torch.nn.L1Loss(reduction="sum")
# 实际输出值
output = torch.tensor([1.0, 2.0, 3.0])
# 目标值
target = torch.tensor([2.0, 2.0, 2.0])
# 平均值损失值
loss = criterion1(output, target)
print(loss) # 输出:tensor(0.6667)
# 误差和
loss1 = criterion2(output,target)
print(loss1) # tensor(2.)
即( (2-1)+(2-2)+(3-2))/3=2/3=0.6667
2.2. 均方误差损失MSE Loss
torch.nn.MSELoss(size_average=None, reduce=None, reduction='mean')
参数解释
size_average(可选,默认为 None):这是一个布尔值或整数,用于指定是否对所有输入批次的输出进行平均。如果设置为 True,则对所有输入批次的输出进行平均。如果设置为整数 n,则对前 n 个输入批次的输出进行平均。如果设置为 None,则根据 reduce 参数的值决定是否进行平均。
reduce(可选,默认为 None):这是一个布尔值,用于指定是否对输入批次的输出进行减少。如果设置为 True,则对输入批次的输出进行减少,返回一个标量。如果设置为 False,则返回每个输入批次的输出的张量。如果 size_average 和 reduce 都为 None,则根据 reduction 参数的值决定是否进行减少和平均。
reduction(可选,默认为 ‘mean’):这是一个字符串,用于指定如何对输入批次的输出进行减少。可选的值有 ‘mean’、‘sum’ 和 ‘none’。如果设置为 ‘mean’,则对输入批次的输出进行平均。如果设置为 ‘sum’,则对输入批次的输出求和。如果设置为 ‘none’,则不进行减少,返回每个输入批次的输出的张量。
公式
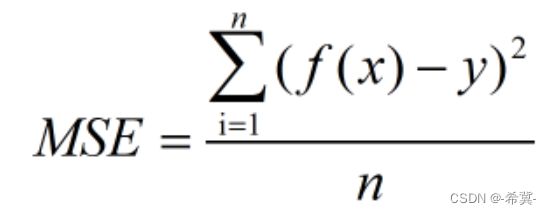
代码实践
import torch
# 实例化
criterion1 = torch.nn.MSELoss()
criterion2 = torch.nn.MSELoss(reduction="sum")
# 实际输出值
output = torch.tensor([1.0, 2.0, 5.0])
# 目标值
target = torch.tensor([2.0, 2.0, 2.0])
# 平方值损失值
loss = criterion1(output, target)
print(loss) # 输出:tensor(3.3333)
# 误差和
loss1 = criterion2(output,target)
print(loss1) # tensor(10.)
即:((2-1)2+(2-2)2+(5-2)2)/3=10/3=3.333
若reduction="sum"即取差值的平方和。
2.3. 交叉熵损失CrossEntropyLoss
torch.nn.CrossEntropyLoss(weight=None, size_average=None, ignore_index=- 100, reduce=None, reduction='mean', label_smoothing=0.0)
参数解释
weight:一个可选的 tensor,用于对每个类别的损失进行加权。这个张量的轴应该与输出的张量轴匹配,且长度等于类别的数量。如果未提供,则使用均匀权重。
size_average:一个可选参数,决定如何计算批处理中损失函数的平均值。如果设置为 True,则对每个样本的损失进行平均。如果设置为 False,则返回每个样本的损失。如果未提供,则根据损失函数是否具有 reduce 属性来决定。
ignore_index:一个可选参数,指定应忽略哪些标签。默认情况下,忽略标签为 -100 的元素。
reduce:一个可选参数,决定是否对批处理中的损失进行汇总。如果设置为 True,则对批处理中的损失进行汇总。如果设置为 False,则返回每个样本的损失。如果未提供,则根据损失函数是否具有 reduce 属性来决定。
reduction:一个可选参数,用于指定如何对批处理中的损失进行汇总。默认情况下,对损失进行平均。其他可能的值包括 ‘mean’、‘sum’ 和 ‘none’。
label_smoothing:一个可选参数,指定标签平滑的强度。默认情况下,不进行标签平滑。该参数的值应该在 0 到 1 之间。
公式

其中log是以e为底,exp是指数函数
注意的点:
交叉熵损失函数在PyTorch中的输入要求如下:
输入x的形状为(batch_size, num_classes)或(num_classes,)。其中,batch_size代表批量大小,num_classes代表类别数量。
输入y的形状为(batch_size,),其中每个元素是对应样本的目标标签的索引值。
即为交叉熵损失函数的输入要求是一个二维张量,第一维是批次大小,第二维是类别数
代码实践
代码如下图所示:
import torch
import torch.nn as nn
# 设置三分类问题,假设是人的概率是0.1,狗的概率是0.2,猫的概率是0.3
x = torch.tensor([0.1, 0.2, 0.3])
print(x)
y = torch.tensor([1]) # 设目标标签为1,即0.2狗对应的标签,目标标签张量y
x = torch.reshape(x, (1, 3)) # tensor([[0.1000, 0.2000, 0.3000]]),批次大小为1,分类数3,即为3分类
print(x)
print(y)
# 实例化对象
loss_cross = nn.CrossEntropyLoss()
# 计算结果
result_cross = loss_cross(x, y)
print(result_cross)
3.在神经网络模型中使用交叉熵损失函数
代码如下:
import torch
import torchvision
from torch.utils.data import DataLoader
# 准备数据集
dataset = torchvision.datasets.CIFAR10(root="dataset", train=False, transform=torchvision.transforms.ToTensor(), download=True)
# 数据集加载器
dataloader = DataLoader(dataset, batch_size=1)
"""
输入图像是3通道的32×32的,
先后经过卷积层(5×5的卷积核)、
最大池化层(2×2的池化核)、
卷积层(5×5的卷积核)、
最大池化层(2×2的池化核)、
卷积层(5×5的卷积核)、
最大池化层(2×2的池化核)、
拉直、
全连接层的处理,
最后输出的大小为10
"""
# 搭建神经网络
class Lgl(torch.nn.Module):
def __init__(self):
super(Lgl, self).__init__()
self.conv1 = torch.nn.Conv2d(in_channels=3,out_channels=32,kernel_size=5,padding=2)
self.maxpool1 = torch.nn.MaxPool2d(kernel_size=2)
self.conv2 = torch.nn.Conv2d(in_channels=32,out_channels=32,kernel_size=5,padding=2)
self.maxpool2 = torch.nn.MaxPool2d(kernel_size=2)
self.conv3 = torch.nn.Conv2d(in_channels=32,out_channels=64,kernel_size=5,padding=2)
self.maxpool3 = torch.nn.MaxPool2d(kernel_size=2)
self.flatten = torch.nn.Flatten()
self.linear1 = torch.nn.Linear(1024,64)
self.linear2 = torch.nn.Linear(64, 10)
def forward(self, x):
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.maxpool2(x)
x = self.conv3(x)
x = self.maxpool3(x)
x = self.flatten(x)
x = self.linear1(x)
x = self.linear2(x)
return x
# 实例化
lgl = Lgl()
loss = torch.nn.CrossEntropyLoss()
# 对每一张图片进行CrossEntropyLoss损失函数计算
# 使用损失函数loss计算预测结果和目标标签之间的交叉熵损失
for data in dataloader:
imgs, target = data
out = lgl(imgs)
result = loss(out, target)
print(result)
上述代码解读:
导入所需的库:
torch和torchvision库用于构建和训练神经网络。
DataLoader用于创建数据加载器,用于处理训练数据的批量加载。
准备数据集:
使用torchvision提供的datasets模块加载CIFAR-10数据集。
将数据集转换为张量类型,并准备为输入训练模型的形式。
搭建神经网络模型:
定义一个继承自nn.Module的类Lgl,表示我们的模型。
在构造函数__init__中,使用nn.Conv2d定义了三个卷积层和nn.Linear定义了两个全连接层。
在forward方法中,按顺序将输入数据传递给网络的各个层,通过卷积、池化和线性变换进行特征提取和分类。
实例化模型和损失函数:
创建一个Lgl类的实例lgl作为我们的模型。
创建一个CrossEntropyLoss类的实例loss作为我们的损失函数,用于计算预测结果和目标标签之间的交叉熵损失。
遍历数据集并进行计算:
使用数据加载器dataloader遍历准备好的数据集。
对于每个batch的数据,将输入图像传递给模型lgl进行前向传播计算,得到预测结果。
使用损失函数loss计算预测结果和目标标签之间的交叉熵损失。
打印输出的损失结果。
声明:本篇文章(包括本专栏所有文章),未经许可,谢绝转载。