大屏实时计算深度剖析(Flink 入门 技术体系剖析 实战 数据处理设计方案 核心技术点)
大屏实时计算深度剖析
- 大屏实时计算深度剖析
-
- 1. 实时计算应用场景
-
- 1.1 智能推荐
- 1.2 实时数仓
- 1.3 大数据分析应用
- 2. Flink快速入门
-
- 2.1 Flink概述
- 2.2 Flink基础案例
- 2.3 Flink部署配置
- 2.4 Flink任务提交
- 3. Flink接入体系
-
- 3.1 Flink Connectors
- 3.2 JDBC(读/写)
- 3.3 HDFS(读/写)
- 3.4 ES(写)
- 3.5 KAFKA(读/写)
- 3.6 自定义序列化(Protobuf)
- 4. Flink大屏数据实战
- 4.1 双十一大屏数据
-
- 4.2 Canal同步服务安装
- 4.3 热销商品统计
- 4.4 区域分类统计
- 4.5 订单状态监控统计(CEP)
- 4.6 商品UV统计
- 4.7 布隆过滤器
大屏实时计算深度剖析
1. 实时计算应用场景
1.1 智能推荐
什么是智能推荐?
定义: 根据用户行为习惯所提供的数据, 系统提供策略模型,自动推荐符合用户行为的信息。
例举:
比如根据用户对商品的点击数据(时间周期,点击频次), 推荐类似的商品;
根据用户的评价与满意度, 推荐合适的品牌;
根据用户的使用习惯与点击行为,推荐类似的资讯。
应用案例:
- 小红书推荐系统
- 实时流处理
- Flink处理(新一代大数据处理引擎)

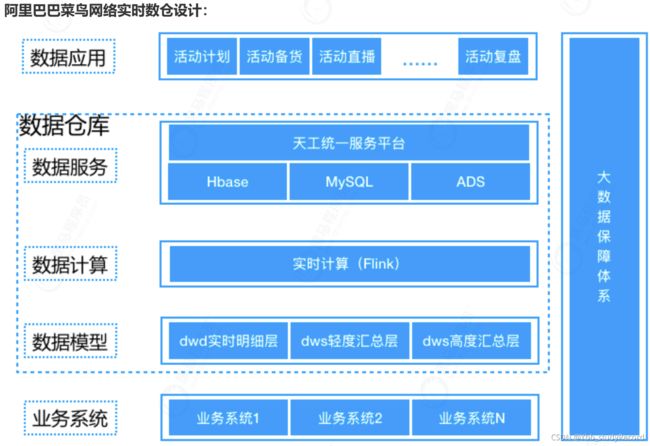
1.2 实时数仓
什么是实时数仓
数据仓库(Data Warehouse),可简写为DW或DWH,是一个庞大的数据存储集合,通过对各种业务数
据进行筛选与整合,生成企业的分析性报告和各类报表,为企业的决策提供支持。实时仓库是基于
Storm/Spark(Streaming)/Flink等实时处理框架,构建的具备实时性特征的数据仓库。
应用案例
分析物流数据, 提升物流处理效率。
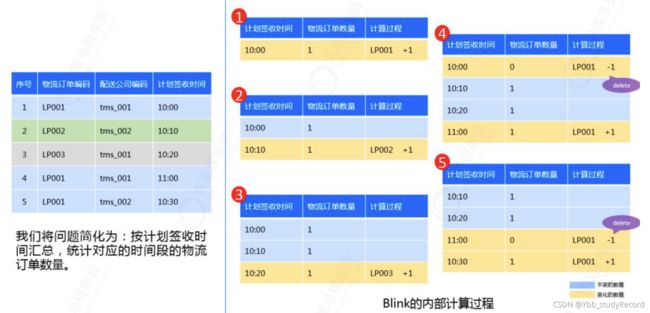
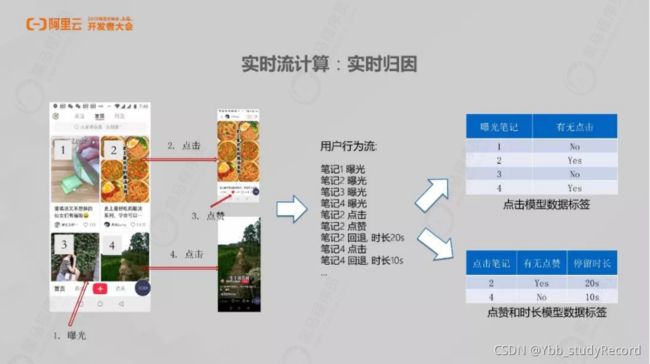
数仓分层处理架构(流式ETL):
E: extraction,抽取数据
T:transformation,转换
L:loading,加载
ODS -> DWD -> DWS -> ADS
ODS(Operation Data Store):操作数据层, 一般为原始采集数据。
DWD(Data Warehouse Detail) :明细数据层, 对数据经过清洗,也称为DWI。
DWS(Data Warehouse Service):汇总数据层,基于DWD层数据, 整合汇总成分析某一个主题域的服务数据,一般是宽表, 由多个属性关联在一起的表, 比如用户行为日志信息:点赞、评论、收藏等。
ADS(Application Data Store): 应用数据层, 将结果同步至RDS(Relational Database Service)数据库中, 一般做报表呈现使用。

1.3 大数据分析应用
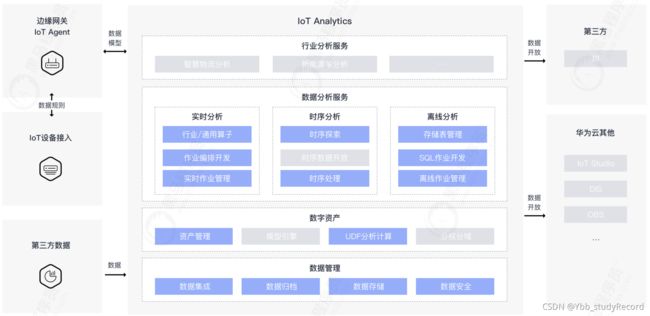
- IoT数据分析
1) 什么是IoT
物联网是新一代信息技术,也是未来发展的趋势,英文全称为: Internet of things(IOT),顾名思义, 物联网就是万物相联。物联网通过智能感知、识别技术与普适计算等通信感知技术,广泛应用于网络的融合中,也因此被称为继计算机、互联网之后世界信息产业发展的第三次浪潮。
2) 应用案例
物联网设备运营分析:设备激活数量、设备活跃时间、访问日志、告警统计

华为Iot数据分析平台架构
2. 智慧城市
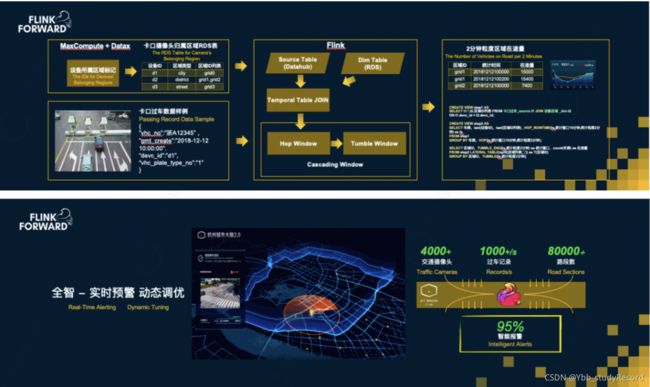
城市中汽车越来越多, 川流不息,高德地图等APP通过技术手段采集了越来越多的摄像头、车流的数据。
但道路却越来越拥堵,越来越多的城市开始通过大数据技术, 对城市实行智能化管理。
2018年, 杭州采用AI智慧城市,平均通行速度提高15%,监控摄像头日报警次数高达500次,识别准确率超过92%,AI智慧城市通报占全体95%以上,在中国城市交通堵塞排行榜, 杭州从中国第5名降至57名。
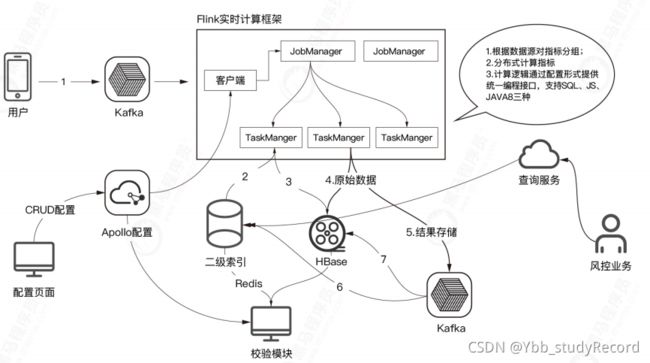
3. 金融风控
风险是金融机构业务固有特性,与金融机构相伴而生。金融机构盈利的来源就是承担风险的风险溢价。
金融机构中常见的六种风险:市场风险、信用风险、流动性风险、操作风险、声誉风险及法律风险。其中最主要的是市场风险和信用风险。
线上信贷流程,通过后台大数据系统进行反欺诈和信用评估:
4. 电商行业
用户在电商的购物网站数据通过实时大数据分析之后, 通过大屏汇总展示, 比如天猫的双11购物
活动,通过大屏, 将全国上亿买家的订单数据可视化,实时性的动态展示,包含总览数据,流式
TopN数据,多维区域统计数据等,极大的增强了对海量数据的可读性。

TopN排行:

2. Flink快速入门
2.1 Flink概述
Flink是什么
Flink是一个面向数据流处理和批处理的分布式开源计算框架。
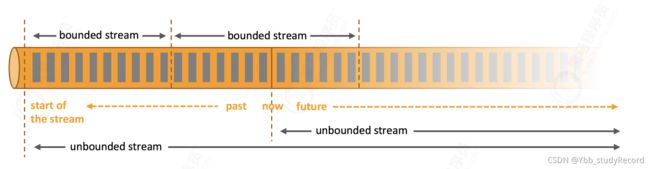
无界流VS有界流
任何类型的数据都可以形成流数据,比如用户交互记录, 传感器数据,事件日志等等。
Apache Flink 擅长处理无界和有界数据集。 精确的时间控制和有状态的计算,使得 Flink能够运行任何处理无界流的应用。流数据分为无界流和有界流。
1) 无界流:有定义流的开始,但没有定义流的结束, 会不停地产生数据,无界流采用的是流处理方式。
2) 有界流:有定义流的开始, 也有定义流的结束, 需要在获取所有数据后再进行计算,有界流采用的是批处理方式。
编程模型
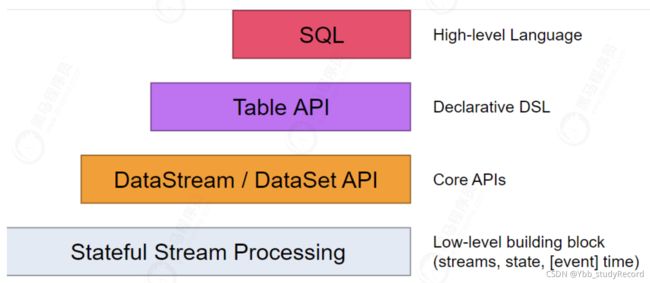
DataSet 一般用来处理有界流数据。
DataStream一般用来处理无界流数据。
2.2 Flink基础案例
- 环境搭建配置
POM配置
FLINK集成
<properties>
<project.build.sourceEncoding>UTF-8project.build.sourceEncoding>
<flink.version>1.11.2flink.version>
<java.version>1.8java.version>
<scala.binary.version>2.11scala.binary.version>
<maven.compiler.source>${java.version}maven.compiler.source>
<maven.compiler.target>${java.version}maven.compiler.target>
<log4j.version>2.12.1log4j.version>
<spring.boot.version>2.1.6.RELEASEspring.boot.version>
<mysql.jdbc.version>5.1.47mysql.jdbc.version>
properties>
<dependencies>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-walkthrough-common_${scala.binary.version}
artifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-streaming-java_${scala.binary.version}
artifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-clients_${scala.binary.version}artifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<version>1.18.8version>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-compiler-pluginartifactId>
<version>3.1version>
<configuration>
<source>${java.version}source>
<target>${java.version}target>
configuration>
plugin>
plugins>
build>
2. 批处理案例
功能: 通过批处理方式,统计日志文件中的异常数量。
代码:
public class BatchProcessorApplication {
public static void main(String[] args)throws Exception {
// 1. 定义运行环境
ExecutionEnvironment env =
ExecutionEnvironment.getExecutionEnvironment();
// 2. 读取数据源(日志文件)
DataSource<String> dataSource =
env.readTextFile("data/order_info.log");
// 3. 清洗转换数据
dataSource.flatMap(new FlatMapFunction<String, Tuple2<String,
Integer>>() {
@Override
public void flatMap(String s, Collector<Tuple2<String, Integer>>
collector) throws Exception {
// 1) 根据正则,提取每行日志的级别
Pattern pattern = Pattern.compile("\\[main\\](.*?)\\[");
Matcher matcher = pattern.matcher(s);
if (matcher.find()) {
// 2) 如果匹配符合规则,放置元组内
collector.collect(new Tuple2<>(matcher.group(1).trim(),
1));
}
}
}).groupBy(0).sum(1).print();// 根据日志级别,汇总统计,打印结果
}
}
- 流处理案例
功能: 根据IP统计访问次数
代码:
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import
org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
/**
* @Auther: Ybb
* @Date: 2021/08/29/12:26 下午
* @Description:
*/
public class StreamProcessorApplication {
public static void main(String[] args) throws Exception{
// 1. 创建运行环境
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 读取socket数据源
DataStreamSource<String> socketTextStream =
env.socketTextStream("192.168.116.141", 9911, "\n");
// 3. 转换处理流数据
socketTextStream.flatMap(new FlatMapFunction<String, Tuple2<String,
Integer>>() {
@Override
public void flatMap(String s, Collector<Tuple2<String, Integer>>
collector) throws Exception {
// 4. 根据分隔符解析数据
String[] elements = s.split("\t");
collector.collect(new Tuple2<>(elements[0], 1));
}
}).keyBy(0).timeWindow(Time.seconds(5)).sum(1).print().setParallelism(1);
env.execute("accessLog");
}
}
[root@localhost ~]# systemctl stop firewalld
[root@localhost ~]# systemctl disable firewalld
Removed symlink /etc/systemd/system/multi-
user.target.wants/firewalld.service.
Removed symlink /etc/systemd/system/dbus-
org.fedoraproject.FirewallD1.service.
[root@localhost ~]# systemctl status firewalld
● firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; disabled;
vendor preset: enabled)
Active: inactive (dead)
Docs: man:firewalld(1)
8月 19 15:59:24 localhost.localdomain systemd[1]: Starting firewalld -
dynamic firewall daemon...
8月 19 15:59:27 localhost.localdomain systemd[1]: Started firewalld - dynamic
firewall daemon.
8月 19 15:59:27 localhost.localdomain firewalld[667]: WARNING:
AllowZoneDrifting is enabled....w.
8月 19 16:02:32 localhost systemd[1]: Stopping firewalld - dynamic firewall
daemon...
8月 19 16:02:32 localhost systemd[1]: Stopped firewalld - dynamic firewall
daemon.
Hint: Some lines were ellipsized, use -l to show in full.
## 安装nc,网络工具
[root@localhost ~]# yum install -y nc
## 保持监听9911端口号
[root@localhost ~]# nc -lk 9911
192.168.116.141 click
192.168.116.141 click
2.3 Flink部署配置
- 安装配置JDK8环境
## 解压
[root@localhost opt]# tar -zxvf jdk-8u301-linux-x64.tar.gz
## 配置环境变量
[root@localhost opt]# vi /etc/profile
export JAVA_HOME=/opt/jdk1.8.0_301
export JRE_HOME=$JAVA_HOME/jre
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=./://$JAVA_HOME/lib:$JRE_HOME/lib
## 使生效
[root@localhost jdk1.8.0_301]# source /etc/profile
## 版本验证
[root@localhost jdk1.8.0_301]# java -version
java version "1.8.0_301"
Java(TM) SE Runtime Environment (build 1.8.0_301-b09)
Java HotSpot(TM) 64-Bit Server VM (build 25.301-b09, mixed mode)
- 下载Flink安装包
官方地址
安装包
[root@localhost opt]# wget https://mirrors.bfsu.edu.cn/apache/flink/flink- 1.11.4/flink-1.11.4-bin-scala_2.11.tgz
- 安装配置
1) 解压
[root@localhost opt]# tar -zxvf flink-1.11.4-bin-scala_2.11.tgz
2)运行
[root@localhost bin]# ./start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host localhost.
Starting taskexecutor daemon on host localhost.
主节点访问端口:
vi conf/masters:
localhost:8081
- 访问控制台
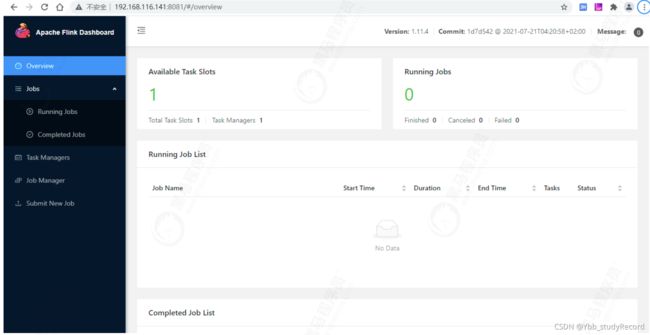
Available Task Slots: 有效任务槽数量
对应配置文件: vi conf/flink-conf.yaml
taskmanager.numberOfTaskSlots: 1
TaskManger与JobManager关系
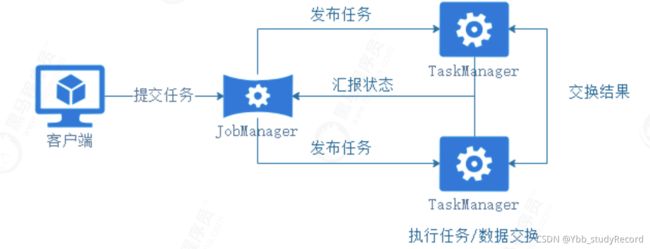
Client 用来提交任务给 JobManager,JobManager 分发任务给 TaskManager 去执行,TaskManager 会采用心跳的方式, 汇报任务的执行状态。
JobManager 负责整个 Flink 集群任务的调度以及资源的管理。
TaskManager 负责具体的任务执行和对应任务在每个节点上的资源申请和管理。
2.4 Flink任务提交
第一种方式: 界面提交
- 修改代码配置
socket数据源连接,采用主机名称配置
DataStreamSource<String> socketTextStream = env.socketTextStream("flink",
9911, "\n");
[root@flink flink-1.11.4]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4
localhost4.localdomain4
::1 localhost localhost.localdomain localhost6
localhost6.localdomain6
192.168.116.141 flink
192.168.116.141 localhost
- 工程代码打包
POM文件增加打包插件
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-compiler-pluginartifactId>
<version>3.5.1version>
<configuration>
<source>1.8source>
<target>1.8target>
configuration>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-shade-pluginartifactId>
<version>2.3version>
<executions>
<execution>
<phase>packagephase>
<goals>
<goal>shadegoal>
goals>
<configuration>
<filters>
<filter>
<artifact>*:*artifact>
<excludes>
<exclude>META-INF/*.SFexclude>
<exclude>META-INF/*.DSAexclude>
<exclude>META-INF/*.RSAexclude>
excludes>
filter>
filters>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTra
nsformer">
<mainClass>cn.itcast.flink.stream.StreamProcessorApplicationmainClass>
transformer>
transformers>
configuration>
execution>
executions>
plugin>
plugins>
build>
注意,这里不能采用spring-boot-maven-plugin打包插件, 否则flink不能正常识别。
- 提交任务
上传Jar包

接下来,在flink节点上, 开启Socket交互端口9911
[root@flink1 flink-1.11.2]# nc -lk 9911
然后提交并执行任务
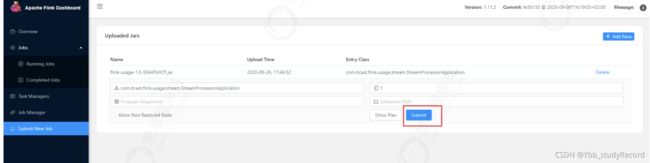
savepoint path: 容错机制中快照保存的路径。
4. 运行验证
nc发送一些数据, 在TaskManager当中可以查看输出结果。
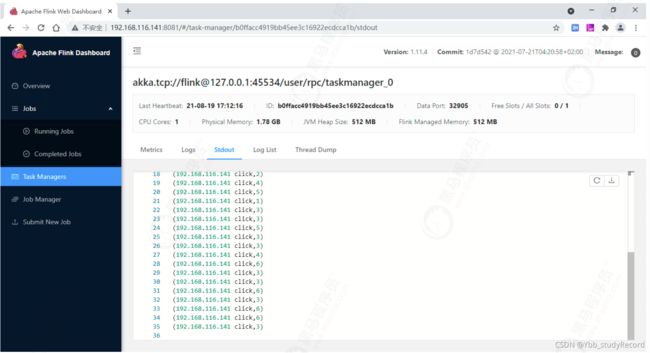
第二种方式: 命令行提交
在flink控制台清除原有的Job任务。
5. 上传Jar包 将Jar包上传至flink服务器:
[root@localhost examples]# ll
总用量 54944
drwxr-xr-x. 2 501 games 194 7月 25 09:49 batch
-rw-r--r--. 1 root root 56261345 8月 19 17:18 flink-usage-1.0-SNAPSHOT.jar
drwxr-xr-x. 2 501 games 50 8月 19 16:46 gelly
drwxr-xr-x. 3 501 games 19 8月 19 16:46 python
drwxr-xr-x. 2 501 games 241 8月 19 16:46 streaming
drwxr-xr-x. 2 501 games 209 8月 19 16:46 table
- 提交任务
采用命令行方式提交任务:
[root@flink flink-1.11.4]# ./bin/flink run -c
cn.itcast.flink.stream.StreamProcessorApplication flink-usage-1.0-
SNAPSHOT.jar
Job has been submitted with JobID ac79195ba9ee0dfa03f0039aa7855dbe
- 验证结果
发送一些数据并在控制台验证输出结果。
3. Flink接入体系
3.1 Flink Connectors
Flink 连接器包含数据源输入与汇聚输出两部分。Flink自身内置了一些基础的连接器,数据源输入包含文件、目录、Socket以及 支持从collections 和 iterators 中读取数据;汇聚输出支持把数据写入文件、标准输出(stdout)、标准错误输出(stderr)和 socket。
官方地址
Flink还可以支持扩展的连接器,能够与第三方系统进行交互。目前支持以下系统:
Flink还可以支持扩展的连接器,能够与第三方系统进行交互。目前支持以下系统:
- Apache Kafka (source/sink)
- Apache Cassandra (sink)
- Amazon Kinesis Streams (source/sink)
- Elasticsearch (sink)
- Hadoop FileSystem (sink)
- RabbitMQ (source/sink)
- Apache NiFi (source/sink)
- Twitter Streaming API (source)
- Google PubSub (source/sink)
- JDBC (sink)
常用的是Kafka、ES、HDFS以及JDBC。
3.2 JDBC(读/写)
Flink Connectors JDBC 如何使用?
功能: 将集合数据写入数据库中
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-connector-jdbc_2.11artifactId>
<version>1.11.2version>
dependency>
代码:
import org.apache.flink.connector.jdbc.JdbcConnectionOptions;
import org.apache.flink.connector.jdbc.JdbcSink;
import org.apache.flink.connector.jdbc.JdbcStatementBuilder;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.Arrays;
import java.util.List;
/**
* @Auther: Ybb
* @Date: 2021/08/29/12:38 下午
* @Description:
*/
public class JDBCConnectorApplication {
public static void main(String[] args)throws Exception {
// 1. 创建运行环境
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 创建集合数据
List<String> list = Arrays.asList(
"192.168.116.141\t1601297294548\tPOST\taddOrder",
"192.168.116.142\t1601297294549\tGET\tgetOrder"
);
// 3. 读取集合数据,写入数据库
env.fromCollection(list).addSink(JdbcSink.sink(
// 配置SQL语句
"insert into t_access_log(ip, time, type, api) values(?, ?, ?, ?)",
new JdbcStatementBuilder<String>() {
@Override
public void accept(PreparedStatement preparedStatement,
String s) throws SQLException {
System.out.println("receive ====> " + s);
// 解析数据
String[] elements = String.valueOf(s).split("\t");
for (int i = 0; i < elements.length; i++) {
// 新增数据
preparedStatement.setString(i+1, elements[i]);
}
}
},
// JDBC 连接配置
new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withUrl("jdbc:mysql://192.168.116.141:3306/flink?useSSL=false")
.withDriverName("com.mysql.jdbc.Driver")
.withUsername("root")
.withPassword("123456")
.build()
));
// 4. 执行任务
env.execute("jdbc-job");
}
}
数据表:
DROP TABLE IF EXISTS `t_access_log`;
CREATE TABLE `t_access_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`ip` varchar(32) NOT NULL COMMENT 'IP地址',
`time` varchar(255) NULL DEFAULT NULL COMMENT '访问时间',
`type` varchar(32) NOT NULL COMMENT '请求类型',
`api` varchar(32) NOT NULL COMMENT 'API地址',
PRIMARY KEY (`id`)
) ENGINE = InnoDB AUTO_INCREMENT=1;
自定义写入数据源
功能:读取Socket数据, 采用流方式写入数据库中。
代码:
public class CustomSinkApplication {
public static void main(String[] args)throws Exception {
// 1. 创建运行环境
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 读取Socket数据源
DataStreamSource<String> socketTextStream =
env.socketTextStream("192.168.116.141", 9911, "\n");
// 3. 转换处理流数据
SingleOutputStreamOperator<AccessLog> outputStreamOperator =
socketTextStream.map(new MapFunction<String, AccessLog>() {
@Override
public AccessLog map(String s) throws Exception {
System.out.println(s);
// 根据分隔符解析数据
String[] elements = s.split("\t");
// 将数据组装为对象
AccessLog accessLog = new AccessLog();
accessLog.setNum(1);
for (int i = 0; i < elements.length; i++) {
if (i == 0) accessLog.setIp(elements[i]);
if (i == 1) accessLog.setTime(elements[i]);
if (i == 2) accessLog.setType(elements[i]);
if (i == 3) accessLog.setApi(elements[i]);
}
return accessLog;
}
});
// 4. 配置自定义写入数据源
outputStreamOperator.addSink(new MySQLSinkFunction());
// 5. 执行任务
env.execute("custom jdbc sink");
}
自定义数据源
private static class MySQLSinkFunction extends RichSinkFunction<AccessLog>{
private Connection connection;
private PreparedStatement preparedStatement;
/**
* @description 创建数据库连接
* @author Ybb
* @date 2021/8/29 12:58 下午
* @params *@params [parameters]
* @return void
*/
@Override
public void open(Configuration parameters) throws Exception {
String url="jdbc:mysql://192.168.11.14:3306/flik?useSSL=fales";
String username="admin";
String password="admin";
connection= DriverManager.getConnection(url,username,password);
String sql="insert into xxx_log(ip,time,type,api) valuse(?,?,?,?)"
preparedStatement=connection.prepareStatement(sql);
}
@Override
public void close() throws Exception {
try {
if (null==connection)connection.close();
connection=null;
}catch (Exception e){
e.printStackTrace();
}
}
@Override
public void invoke(AccessLog accessLog, Context context) throws Exception {
preparedStatement.setString(1,accessLog.getIp());
preparedStatement.setString(2,accessLog.getTime());
preparedStatement.setString(3,accessLog.getType());
preparedStatement.setString(4,accessLog.getApi());
preparedStatement.execute();
}
}
AccessLog:
@Data
public class AccessLog {
/**
* IP地址
*/
private String ip;
/**
* 访问时间
*/
private String time;
/**
* 请求类型
*/
private String type;
/**
* API地址
*/
private String api;
private Integer num;
}
测试数据:注意 \t
192.168.116.141 1603166893313 GET getOrder
192.168.116.142 1603166893314 POST addOrder
自定义读取数据源
功能: 读取数据库中的数据, 并将结果打印出来。
代码:
public static void main(String[] args) {
// 1. 创建运行环境
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 配置自定义MySQL读取数据源
DataStreamSource<AccessLog> streamSource = env.addSource(new
MySQLSourceFunction());
// 3. 设置并行度
streamSource.print().setParallelism(1);
// 4. 执行任务
env.execute("custom jdbc source");
}
3.3 HDFS(读/写)
通过Sink写入HDFS数据
功能: 将Socket接收到的数据, 写入至HDFS文件中。
依赖
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-connector-filesystem_2.11artifactId>
<version>1.11.2version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>2.8.1version>
dependency>
代码:
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.fs.StringWriter;
import org.apache.flink.streaming.connectors.fs.bucketing.BucketingSink;
import org.apache.flink.streaming.connectors.fs.bucketing.DateTimeBucketer;
/**
* @Auther: Ybb
* @Date: 2021/08/29/1:06 下午
* @Description:
*/
public class HDFSSinkApplication {
public static void main(String[] args) {
// 1. 创建运行环境
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 读取Socket数据源
// DataStreamSource socketTextStream =
env.socketTextStream("127.0.0.1", 9911, "\n");
DataStreamSource<String> socketTextStream =
env.socketTextStream("192.168.116.141", 9911, "\n");
// 3. 创建hdfs sink
BucketingSink<String> bucketingSink = new BucketingSink<>("F:/itcast/Flink/hdfs");
bucketingSink.setBucketer(new DateTimeBucketer<>("yyyy-MM-dd--HHmm"));
bucketingSink.setWriter(new StringWriter())
.setBatchSize(5 * 1024)// 设置每个文件的大小
.setBatchRolloverInterval(5 * 1000)// 设置滚动写入新文件的时间
.setInactiveBucketCheckInterval(30 * 1000)// 30秒检查一次不写入 的文件
.setInactiveBucketThreshold(60 * 1000);// 60秒不写入,就滚动写入新的文件
// 4. 写入至HDFS文件中
socketTextStream.addSink(bucketingSink).setParallelism(1);
// 5. 执行任务
env.execute("flink hdfs source");
}
}
数据源模拟实现:
<dependency>
<groupId>io.nettygroupId>
<artifactId>netty-allartifactId>
<version>4.1.16.Finalversion>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
<version>${spring.boot.version}version>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-jpaartifactId>
<version>${spring.boot.version}version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>${mysql.jdbc.version}version>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-redisartifactId>
<version>2.1.1.RELEASEversion>
dependency>
public class NettyServerHandler extends ChannelInboundHandlerAdapter {
/* 客户端通道记录集合*/
public static List<Channel> channelList = new ArrayList<>();
@Override
public void channelActive(ChannelHandlerContext ctx) throws Exception {
System.out.println("Server >>>> 连接已建立:" + ctx);
super.channelActive(ctx);
// 将成功建立的连接通道,加入到集合当中
channelList.add(ctx.channel());
}
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws
Exception {
System.out.println("Server >>>> 收到的消息:" + msg);
}
@Override
public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause)
throws Exception {
System.out.println("Server >>>> 读取数据出现异常");
cause.printStackTrace();
ctx.close();
}
@Override
public void channelUnregistered(ChannelHandlerContext ctx) throws Exception
{
super.channelUnregistered(ctx);
// 移除无效的连接通道
channelList.remove(ctx.channel());
}
@Override
public void channelInactive(ChannelHandlerContext ctx) throws Exception {
super.channelInactive(ctx);
// 移除无效的连接通道
channelList.remove(ctx.channel());
}
}
import io.netty.bootstrap.ServerBootstrap;
import io.netty.channel.*;
import io.netty.channel.nio.NioEventLoopGroup;
import io.netty.channel.socket.SocketChannel;
import io.netty.channel.socket.nio.NioServerSocketChannel;
import io.netty.handler.codec.string.StringDecoder;
import io.netty.handler.codec.string.StringEncoder;
import io.netty.handler.logging.LogLevel;
import io.netty.handler.logging.LoggingHandler;
import java.util.Random;
/**
* @Auther: Ybb
* @Date: 2021/08/29/1:08 下午
* @Description:
*/
public class SocketSourceApplication {
/**
* 服务端的端口
*/
private int port;
/**
* 初始化构造方法
*
* @param port
*/
public SocketSourceApplication(int port) {
this.port = port;
}
/**
* ip 访问列表
*/
private static String[] accessIps = new String[]{
"192.168.116.141",
"192.168.116.142",
"192.168.116.143"
};
/**
* 请求访问类型
*/
private static String[] accessTypes = new String[]{
"GET",
"POST",
"PUT"
};
/**
* 请求接口信息
*/
private static String[] accessApis = new String[]{
"addOrder",
"getAccount",
"getOrder"
};
public void runServer() throws Exception {
// 1. 创建netty服务
// 2. 定义事件boss监听组
NioEventLoopGroup bossGroup = new NioEventLoopGroup();
// 3. 定义用来处理已经被接收的连接
NioEventLoopGroup workerGroup = new NioEventLoopGroup();
try {
// 4. 定义nio服务启动类
ServerBootstrap serverBootstrap = new ServerBootstrap();
// 5. 配置nio服务启动的相关参数
serverBootstrap.group(bossGroup, workerGroup)
.channel(NioServerSocketChannel.class)
// tcp最大缓存连接个数,tcp_max_syn_backlog(半连接上限数量)
.option(ChannelOption.SO_BACKLOG, 128)
// 保持连接的正常状态
.childOption(ChannelOption.SO_KEEPALIVE, true)
// 根据日志级别打印输出
.handler(new LoggingHandler(LogLevel.INFO))
.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
protected void initChannel(SocketChannel socketChannel)
throws Exception {
// 管道注册handler
ChannelPipeline pipeline = socketChannel.pipeline();
// 编码通道处理
pipeline.addLast("decode", new StringDecoder());
// 转码通道处理
pipeline.addLast("encode", new StringEncoder());
// 处理接收到的请求
pipeline.addLast(new NettyServerHandler());
}
});
System.out.println(">>>>>server 启动<<<<<<<");
// 6. 开启新线程,模拟数据,广播发送
new Thread(new Runnable() {
@Override
public void run() {
try {
while (true) {
String accessLog = getAccessLog();
System.out.println("broadcast (" +
NettyServerHandler.channelList.size() + ") ==> " + accessLog);
if (NettyServerHandler.channelList.size() > 0) {
for (Channel channel :
NettyServerHandler.channelList) {
channel.writeAndFlush(accessLog);
}
}
Thread.sleep(1000);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}).start();
// 7. 启动netty服务
ChannelFuture channelFuture = serverBootstrap.bind(port).sync();
channelFuture.channel().closeFuture().sync();
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 获取访问日志
*
* @return
*/
private String getAccessLog() {
StringBuilder stringBuilder = new StringBuilder();
stringBuilder.append(accessIps[new
Random().nextInt(accessIps.length)]).append("\t")
.append(System.currentTimeMillis()).append("\t")
.append(accessTypes[new
Random().nextInt(accessTypes.length)]).append("\t")
.append(accessApis[new
Random().nextInt(accessApis.length)]).append("\t\n");
return stringBuilder.toString();
}
/**
* netty服务端启动
*
* @param args
*/
public static void main(String[] args) throws Exception {
new SocketSourceApplication(9911).runServer();
}
}
读取HDFS文件数据
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* @Auther: Ybb
* @Date: 2021/08/29/1:14 下午
* @Description:
*/
public class HDFSSourceApplication {
public static void main(String[] args) {
// 1. 创建运行环境
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 读取HDFS数据源
DataStreamSource<String> file =
env.readTextFile("hdfs://192.168.116.141:9090/hadoop-env.sh");
// 3. 打印文件内容
file.print().setParallelism(1);
// 4. 执行任务
env.execute("flink hdfs source");
}
}
Hadoop环境安装
- 配置免密码登录
生成秘钥:
[root@flink1 hadoop-2.6.0-cdh5.15.2]# ssh-keygen -t rsa -P ''
Generating public/private rsa key pair.
将秘钥写入认证文件:
[root@flink1 .ssh]# cat id_rsa.pub >> ~/.ssh/authorized_keys
修改认证文件权限:
[root@flink1 .ssh]# chmod 600 ~/.ssh/authorized_keys
- 配置环境变量
将Hadoop安装包解压, 将Hadoop加入环境变量/etc/profile:
export HADOOP_HOME=/opt/hadoop-2.6.0-cdh5.15.2
export PATH=$HADOOP_HOME/bin:$PATH
执行生效:
source /etc/profile
- 修改Hadoop配置文件
1) 修改hadoop-env.sh文件
vi /opt/hadoop-2.6.0-cdh5.15.2/etc/hadoop/hadoop-env.sh
修改JAVA_HOME:
export JAVA_HOME=/opt/jdk1.8.0_301
2)修改core-site.xml文件
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://flink:9090value>
property>
configuration>
这里的主机名称是flink。
3)修改hdfs-site.xml文件
<configuration>
<property>
<name>dfs.replicationname>
<value>1value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/opt/hadoop-2.6.0-cdh5.15.2/tmpvalue>
property>
configuration>
4)修改mapred-site.xml文件
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
configuration>
5)修改slaves文件
flink
这里配置的是单节点, 指向本机主机名称。
6)修改yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
- 启动Hadoop服务
[root@flink hadoop-2.6.0-cdh5.15.2]# ./sbin/start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
21/08/23 11:59:17 WARN util.NativeCodeLoader: Unable to load native-
hadoop library for your platform... using builtin-java classes where
applicable
Starting namenodes on [flink]
flink: starting namenode, logging to /opt/hadoop-2.6.0-
cdh5.15.2/logs/hadoop-root-namenode-flink.out
flink: starting datanode, logging to /opt/hadoop-2.6.0-
cdh5.15.2/logs/hadoop-root-datanode-flink.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /opt/hadoop-2.6.0-
cdh5.15.2/logs/hadoop-root-secondarynamenode-flink.out
21/08/23 11:59:45 WARN util.NativeCodeLoader: Unable to load native-
hadoop library for your platform... using builtin-java classes where
applicable
starting yarn daemons
starting resourcemanager, logging to /opt/hadoop-2.6.0-
cdh5.15.2/logs/yarn-root-resourcemanager-flink.out
flink: starting nodemanager, logging to /opt/hadoop-2.6.0-
cdh5.15.2/logs/yarn-root-nodemanager-flink.out
上传一个文件, 用于测试:
hdfs dfs -put /opt/hadoop-2.6.0-cdh5.15.2/etc/hadoop/hadoop-env.sh /
如果上传失败
1)可能是namenode没有启动,则执行如下命令
hadoop namenode -format
2)检查/etc/hosts文件配置
[root@flink hadoop-2.6.0-cdh5.15.2]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4
localhost4.localdomain4
::1 localhost localhost.localdomain localhost6
localhost6.localdomain6
192.168.116.141 flink
192.168.116.141 localhost
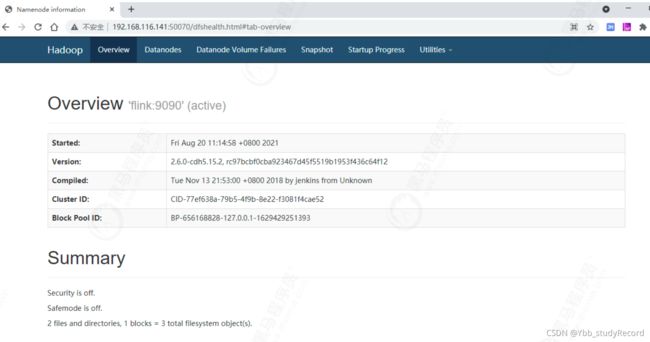
- 访问验证
http://192.168.116.141:50070/dfshealth.html#tab-overview
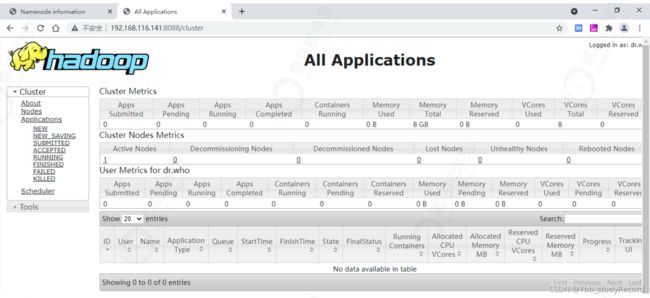
http://192.168.116.141:8088/cluster
3.4 ES(写)
ES服务安装
- 到官网下载地址下载6.8.1版本的gz压缩包, 不要下载最新版本, Spring Boot等项目可能未及时更新支持。
- 解压安装包
tar -xvf elasticsearch-6.8.1-linux-x86_64.tar.gz
- ElasticSearch不能以Root身份运行, 需要单独创建一个用户
1. groupadd elsearch
2. useradd elsearch -g elsearch -p elasticsearch
3. chown -R elsearch:elsearch /opt/elasticsearch-6.8.1
执行以上命令,创建一个名为elsearch用户, 并赋予目录权限。
4. 修改配置文件
vi config/elasticsearch.yml, 只需修改以下设置:
#集群名称
cluster.name: my-application
#节点名称
node.name: node-1
#数据存储路径
path.data: /opt/elasticsearch-6.8.1/data
#日志存储路径
path.logs: /opt/elasticsearch-6.8.1/logs
# 绑定IP地址
network.host: 192.168.116.141
# 指定服务访问端口
http.port: 9200
# 指定API端户端调用端口
transport.tcp.port: 9300
- 指定JDK版本
最新版的ElasticSearch需要JDK11版本, 下载JDK11压缩包, 并进行解压。
修改环境配置文件
vi bin/elasticsearch-env
参照以下位置, 追加一行, 设置JAVA_HOME, 指定JDK11路径。
JAVA_HOME=/opt/jdk11
# now set the path to java
if [ ! -z "$JAVA_HOME" ]; then
JAVA="$JAVA_HOME/bin/java"
else
if [ "$(uname -s)" = "Darwin" ]; then
# OSX has a different structure
JAVA="$ES_HOME/jdk/Contents/Home/bin/java"
else
JAVA="$ES_HOME/jdk/bin/java"
fi
fi
- 关闭ConcMarkSweepGC
JDK9版本以后不建议使用ConcMarkSweepGC, 如果不想出现提示, 可以将其关闭
vi config/jvm.options
将UseConcMarkSweepGC注释:
## GC configuration
#-XX:+UseConcMarkSweepGC
...
## G1GC Configuration
# NOTE: G1GC is only supported on JDK version 10 or later.
# To use G1GC uncomment the lines below.
#-XX:-UseConcMarkSweepGC
...
- 启动ElasticSearch
- 切换用户
su elsearch
- 以后台常驻方式启动
bin/elasticsearch -d
7. 问题处理
出现max virtual memory areas vm.max_map_count [65530] is too low, increase to at
least 错误信息
修改系统配置:
vi /etc/sysctl.conf
添加
vm.max_map_count=655360
执行生效
sysctl -p
vi /etc/security/limits.conf
在文件末尾添加
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
elsearch soft nproc 125535
elsearch hard nproc 125535
重新切换用户即可:
su - elsearch
FLINK ES写入功能实现
功能: 将Socket流数据, 写入至ES服务。
依赖
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-connector-elasticsearch6_2.11artifactId>
<version>1.6.0version>
dependency>
代码:
import org.apache.flink.api.common.functions.RuntimeContext;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.elasticsearch.ElasticsearchSinkFunction;
import org.apache.flink.streaming.connectors.elasticsearch.RequestIndexer;
import org.apache.flink.streaming.connectors.elasticsearch6.ElasticsearchSink;
import org.apache.flink.streaming.connectors.elasticsearch6.RestClientFactory;
import org.apache.http.HttpHost;
import org.elasticsearch.action.ActionRequest;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.Requests;
import org.elasticsearch.client.RestClientBuilder;
import java.util.ArrayList;
import java.util.HashMap;
/**
* @Auther: Ybb
* @Date: 2021/08/29/1:24 下午
* @Description:
*/
public class ElasticSinkApplication {
public static void main(String[] args) {
// 1. 创建运行环境
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 读取socket数据源
DataStreamSource<String> socketTextStream =
env.socketTextStream("localhost", 9911, "\n");
// 3. 配置es服务信息
ArrayList<HttpHost> httpHosts = new ArrayList<>();
httpHosts.add(new HttpHost("192.168.116.141", 9200, "http"));
// 4. 数据解析处理
ElasticsearchSink.Builder<String> esSinkBuilder = new
ElasticsearchSink.Builder<>(
httpHosts,
new ElasticsearchSinkFunction<String>() {
@Override
public void process(String s, RuntimeContext
runtimeContext, RequestIndexer requestIndexer) {
requestIndexer.add(createIndexRequest(s));
}
private IndexRequest createIndexRequest(String s) {
HashMap<String, String> map = new HashMap<>();
String[] elements = String.valueOf(s).split("\t");
for (int i = 0; i < elements.length; i++) {
if (i == 0) map.put("ip", elements[i]);
if (i == 1) map.put("time", elements[i]);
if (i == 2) map.put("type", elements[i]);
if (i == 3) map.put("api", elements[i]);
}
return Requests.indexRequest()
.index("flink-es")
.type("access-log")
.source(map);
}
});
// 5. es写入配置
esSinkBuilder.setBulkFlushMaxActions(1);
esSinkBuilder.setRestClientFactory(new RestClientFactory() {
@Override
public void configureRestClientBuilder(RestClientBuilder
restClientBuilder) {
restClientBuilder.setMaxRetryTimeoutMillis(5000);
}
});
// 6. 添加es的写入器
socketTextStream.addSink(esSinkBuilder.build());
socketTextStream.print().setParallelism(1);
// 7. 执行任务
env.execute("flink es sink");
}
}
查看index信息:
http://192.168.116.141:9200/_cat/indices?v
查看具体数据:
http://192.168.116.141:9200/flink-es/_search
3.5 KAFKA(读/写)
Kafka安装
- 下载Kafka_2.12-1.1.1安装包
- 将安装包解压
tar -xvf kafka_2.12-1.1.1.tgz
- 修改kafka配置
只修改绑定IP, 因为是单节点, 其他按默认配置来。
[root@flink kafka_2.12-1.1.1]# vi config/server.properties
listeners=PLAINTEXT://192.168.116.141:9092
advertised.listeners=PLAINTEXT://192.168.116.141:9092
如有多个IP地址, 绑定为对外访问的IP。 4. 启动zookeeper服务
kafka安装包内置了zookeeper,可以直接启动。
bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
- 启动kafka服务
bin/kafka-server-start.sh -daemon config/server.properties
Flink Kafka 读取功能
功能: 通过flink读取kafka消息队列数据, 并打印显示。
依赖
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-connector-kafka_2.11artifactId>
<version>1.11.2version>
dependency>
代码:
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import java.util.Properties;
/**
* @Auther: Ybb
* @Date: 2021/08/29/1:35 下午
* @Description:
*/
public class KafkaSourceApplication {
public static void main(String[] args) {
// 1. 创建运行环境
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 设置Kafka服务连接信息
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "192.168.116.141:9092");
properties.setProperty("group.id", "flink_group");
// 3. 创建Kafka消费端
FlinkKafkaConsumer flinkKafkaConsumer = new FlinkKafkaConsumer(
"flink-source", // 目标topic
new SimpleStringSchema(), // 序列化配置
properties
);
// flinkKafkaConsumer.setStartFromEarliest(); // 尽可能从最早的记录开始
// flinkKafkaConsumer.setStartFromLatest(); // 从最新的记录开始
// flinkKafkaConsumer.setStartFromTimestamp(...); // 从指定的时间开始(毫秒)
// flinkKafkaConsumer.setStartFromGroupOffsets(); // 默认方法
// 4. 读取Kafka数据源
DataStreamSource dataStreamSource =
env.addSource(flinkKafkaConsumer);
dataStreamSource.print().setParallelism(1);
// 5. 执行任务
env.execute("Flink kafka source");
}
}
通过kafka生产者命令测试验证
[root@flink kafka_2.12-1.1.1]# bin/kafka-console-producer.sh --broker-list 192.168.116.141:9092 --topic flink-source
扩展点:kafka消息的消费处理策略:
// kafkaProducer.setStartFromEarliest(); // 尽可能从最早的记录开始
// kafkaProducer.setStartFromLatest(); // 从最新的记录开始
// kafkaProducer.setStartFromTimestamp(...); // 从指定的时间开始(毫秒)
// kafkaProducer.setStartFromGroupOffsets(); // 默认的方法
Flink Kafka 写入功能
功能: 将Socket的流数据,通过flink 写入kafka 消息队列。
代码:
public class kafkaSinkApplication {
public static void main(String[] args) {
// 1. 创建运行环境
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 读取socket数据源
DataStreamSource<String> socketTextStream =
env.socketTextStream("localhost", 9911, "\t");
// 3. kafka生产者配置
FlinkKafkaProducer flinkKafkaProducer = new FlinkKafkaProducer(
"192.168.116.141:9092", // broker 列表
"flink-topic", // 目标 topic
new SimpleStringSchema() // 序列化方式
);
// 4. 添加Kafka写入器
socketTextStream.addSink(flinkKafkaProducer);
socketTextStream.print().setParallelism(1);
// 5. 执行任务
env.execute("flink kafka sink");
}
}
通过kafka消费者命令测试验证:
[root@flink kafka_2.12-1.1.1]# bin/kafka-console-consumer.sh --bootstrap- server 192.168.116.141:9092 --topic flink-topic
控制消息的发送处理模式:
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "192.168.116.141:9092");
FlinkKafkaProducer flinkKafkaProducer = new FlinkKafkaProducer(
"flink-topic",
new KeyedSerializationSchemaWrapper(new
SimpleStringSchema()),
properties,
FlinkKafkaProducer.Semantic.EXACTLY_ONCE
提供了三种消息处理模式:
- Semantic.NONE :Flink 不会有任何语义的保证,产生的记录可能会丢失或重复。
- Semantic.AT_LEAST_ONCE (默认设置):类似 FlinkKafkaProducer010
版本中的setFlushOnCheckpoint(true) ,这可以保证不会丢失任何记录(虽然记录可能会重复)。 - Semantic.EXACTLY_ONCE :使用 Kafka 事务提供精准一次的语义。无论何时,在使用事务写入 Kafka时,都要记得为所有消费 Kafka 消息的应用程序设置所需的 isolation.level ( read_committed 或 read_uncommitted - 后者是默认值)。
- Kafka 的消息可以携带时间戳,指示事件发生的时间或消息写入 Kafka broker 的时间。
kafkaProducer.setWriteTimestampToKafka(true);
3.6 自定义序列化(Protobuf)
在实际应用场景中, 会存在各种复杂传输对象,同时要求较高的传输处理性能, 这就需要采用自定义的序列化方式做相应实现, 这里以Protobuf为例做讲解。
功能: kafka对同一Topic的生产与消费,采用Protobuf做序列化与反序列化传输, 验证能否正常解析数据。
- 通过protobuf脚本生成JAVA文件
在syntax = "proto3";
option java_package = "cn.flink.connector.kafka.proto";
option java_outer_classname = "AccessLogProto";
// 消息结构定义
message AccessLog {
string ip = 1;
string time = 2;
string type = 3;
string api = 4;
string num = 5;
}
通过批处理脚本,生成JAVA文件:
@echo off
for %%i in (proto/*.proto) do (
F:/itcast/Flink/tar/protoc.exe --proto_path=./proto --java_out=../java
./proto/%%i
echo generate %%i to java file successfully!
)
注意, 路径要配置正确。
2. 自定义序列化实现
添加POM依赖:
<dependencies>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-connector-kafka_2.11artifactId>
<version>1.11.2version>
dependency>
<dependency>
<groupId>com.google.protobufgroupId>
<artifactId>protobuf-javaartifactId>
<version>3.8.0version>
dependency>
<dependency>
<groupId>org.springframeworkgroupId>
<artifactId>spring-beansartifactId>
<version>5.1.8.RELEASEversion>
dependency>
dependencies>
AccessLog对象:
import lombok.Data;
import java.io.Serializable;
@Data
public class AccessLog implements Serializable {
private String ip;
private String time;
private String type;
private String api;
private Integer num;
}
序列话好之后会根据AccessLog对象得到一个序列号的文件 CustomSerialSchema:
CustomSerialSchema:
import org.apache.flink.api.common.serialization.DeserializationSchema;
import org.apache.flink.api.common.serialization.SerializationSchema;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.springframework.beans.BeanUtils;
import java.io.IOException;
import java.nio.charset.Charset;
import java.nio.charset.StandardCharsets;
import static org.apache.flink.util.Preconditions.checkNotNull;
/**
* @Auther: Ybb
* @Date: 2021/08/29/1:42 下午
* @Description:
*/
public class CustomSerialSchema implements DeserializationSchema<AccessLog>,
SerializationSchema<AccessLog> {
private static final long serialVersionUID = -7319637733955723488L;
private transient Charset charset;
public CustomSerialSchema() {
this(StandardCharsets.UTF_8);
}
public CustomSerialSchema(Charset charset) {
this.charset = checkNotNull(charset);
}
public Charset getCharset() {
return charset;
}
/**
* 反序列化实现
*
* @param bytes
* @return
* @throws IOException
*/
@Override
public AccessLog deserialize(byte[] bytes) throws IOException {
AccessLog accessLog = null;
try {
AccessLogProto.AccessLog accessLogProto =
AccessLogProto.AccessLog.parseFrom(bytes);
accessLog = new AccessLog();
BeanUtils.copyProperties(accessLogProto, accessLog);
return accessLog;
} catch (Exception e) {
e.printStackTrace();
}
return accessLog;
}
@Override
public boolean isEndOfStream(AccessLog accessLog) {
return false;
}
/**
* 序列化处理
*
* @param accessLog
* @return
*/
@Override
public byte[] serialize(AccessLog accessLog) {
AccessLogProto.AccessLog.Builder builder =
AccessLogProto.AccessLog.newBuilder();
BeanUtils.copyProperties(accessLog, builder);
return builder.build().toByteArray();
}
/**
* 定义消息类型
*
* @return
*/
@Override
public TypeInformation<AccessLog> getProducedType() {
return TypeInformation.of(AccessLog.class);
}
}
3. 通过flink对kafka消息生产者的实现
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import java.util.Properties;
public static void main(String[] args) throws Exception {
// 1. 创建运行环境
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 读取Socket数据源
DataStreamSource<String> socketTextStream =
env.socketTextStream("localhost", 9911, "\n");
// 3. 转换处理流数据
SingleOutputStreamOperator<AccessLog> outputStreamOperator =
socketTextStream.map(new MapFunction<String, AccessLog>() {
@Override
public AccessLog map(String value) throws Exception {
System.out.println(value);
// 根据分隔符解析数据
String[] arrValue = value.split("\t");
// 将数据组装为对象
AccessLog accessLog = new AccessLog();
accessLog.setNum(1);
for (int i = 0; i < arrValue.length; i++) {
if (i == 0) accessLog.setIp(arrValue[i]);
if (i == 1) accessLog.setTime(arrValue[i]);
if (i == 2) accessLog.setType(arrValue[i]);
if (i == 3) accessLog.setApi(arrValue[i]);
}
return accessLog;
}
});
// 3. Kakfa的生产者配置
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "192.168.116.141:9092");
FlinkKafkaProducer kafkaProducer = new FlinkKafkaProducer(
"192.168.116.141:9092", // broker 列表
"flink-serial", // 目标 topic
new CustomSerialSchema() // 序列化 方式
);
// 4. 添加kafka的写入器
outputStreamOperator.addSink(kafkaProducer);
socketTextStream.print().setParallelism(1);
// 5. 执行任务
env.execute("flink kafka protobuf sink");
}
}
开启Kafka消费者命令行终端,验证生产者的可用性:
[root@flink1 kafka_2.12-1.1.1]# bin/kafka-console-consumer.sh --bootstrap-
server 192.168.116.141:9092 --topic flink-serial
1601649380422GET"
getAccount
1601649381422POSTaddOrder
1601649382422POST"
- 通过flink对kafka消息订阅者的实现
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import java.util.Properties;
public static void main(String[] args) throws Exception {
// 1. 创建运行环境
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 设置kafka服务连接信息
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "192.168.116.141:9092");
properties.setProperty("group.id", "flink_group");
// 3. 创建Kafka消费端
FlinkKafkaConsumer flinkKafkaConsumer = new FlinkKafkaConsumer(
"flink-serial", // 目标 topic
new CustomSerialSchema(), // 自定义序列化
properties);
// 4. 读取Kafka数据源
DataStreamSource<AccessLog> dataStreamSource =
env.addSource(flinkKafkaConsumer);
dataStreamSource.print().setParallelism(1);
// 5. 执行任务
env.execute("flink kafka protobuf source");
}
}
通过flink的kafka生产者消息的发送, 对消费者的功能做测试验证。
4. Flink大屏数据实战
4.1 双十一大屏数据
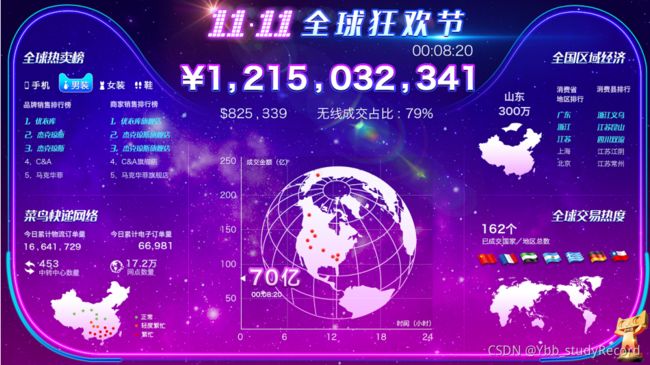
- 总览数据
总销售量/总销售金额
TopN: 热销商品/商品类目/商品PV/商品UV
- 区域/分类数据
不同区域销售排名
不同分类销售排名

4.2 Canal同步服务安装
- 下载安装包
安装包
后台管理包 - 解压
解压安装包:
mkdir -p /opt/canal
tar -xzvf canal.deployer-1.1.4.tar.gz -C /opt/canal/
解压管理包:
mkdir -p /opt/canal-admin
tar -xvf canal.admin-1.1.4.tar.gz -C /opt/canal-admin
- 初始化管理数据库
导入初始化数据脚本:
mysql -uroot -p123456 < /opt/canal-admin/conf/canal_manager.sql
- 修改MySQL服务同步配置
编辑配置文件:
vi /etc/my.cnf
增加同步配置:
[mysqld]
log-bin=mysql-bin # 开启 binlog
binlog-format=ROW # 选择 ROW 模式
server_id=1 # MySQL ID服务标识
重启服务:
systemctl restart mariadb
检查同步功能是否开启
mysql> show variables like 'log_bin';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| log_bin | ON |
+---------------+-------+
1 row in set (0.01 sec)
创建同步用户:
mysql> FLUSH PRIVILEGES;
mysql> CREATE USER canal IDENTIFIED BY 'canal';
赋予同步所需权限:
mysql> GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO
'canal'@'%';
Query OK, 0 rows affected (0.00 sec)
mysql> FLUSH PRIVILEGES;
Query OK, 0 rows affected (0.00 sec)
- 修改后台管理配置文件
vi /opt/canal-admin/conf/application.yml
配置内容:
server:
port: 8089
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
spring.datasource:
address: 192.168.116.141:3306
database: canal_manager
username: root
password: 123456
driver-class-name: com.mysql.jdbc.Driver
url:
jdbc:mysql://${spring.datasource.address}/${spring.datasource.database}?
useUnicode=true&characterEncoding=UTF-8&useSSL=false
hikari:
maximum-pool-size: 30
minimum-idle: 1
canal:
adminUser: admin
adminPasswd: admin
先启动后台管理服务, 再启动Canal服务, 后台管理服务启动命令:
/opt/canal-admin/bin/startup.sh
访问:http://192.168.116.141:8089/
登录: admin/123456
6. Canal服务配置
vi /opt/canal/conf/canal_local.properties
配置内容:
# register ip
canal.register.ip = 192.168.116.141
# canal admin config
canal.admin.manager = 192.168.116.141:8089
canal.admin.port = 11110
canal.admin.user = admin
canal.admin.passwd = 4ACFE3202A5FF5CF467898FC58AAB1D615029441
# admin auto register
canal.admin.register.auto = true
canal.admin.register.cluster =
启动Canal服务:
/opt/canal/bin/startup.sh local
- 后台管理配置
修改Server管理配置:
# 指向ZK服务地址
canal.zkServers = 192.168.116.141:2181
# Canal同步方式
canal.serverMode = kafka
# mq服务地址
canal.mq.servers = 192.168.116.141:9092
修改Instance配置(如果没有, 则新建,载入模板即可):
# mysql 同步服务ID标识, 不要配置冲突
canal.instance.mysql.slaveId=121
# mysql 同步主节点连接配置
canal.instance.master.address=192.168.116.141:3306
# 数据库用户名
canal.instance.dbUsername=canal
# 数据库用户密码
canal.instance.dbPassword=canal
# 数据同步消息队列
canal.mq.topic=order_binlog
# 修改需要同步的数据库
canal.instance.filter.regex=flink.t_order
regex同步配置规则:
常见例子:
- 所有表:.* or …
- canal schema下所有表: canal…*
- canal下的以canal打头的表:canal.canal.*
- canal schema下的一张表:canal.test1
- 多个规则组合使用:canal…*,mysql.test1,mysql.test2 (逗号分隔)
4.3 热销商品统计
功能实现流程:
- 订单数据源的实现
- flink代码功能实现
- Flink 与 Spring Boot的集成
- 测试验证,比对SQL:
select goodsId, sum(execPrice * execVolume) as totalAmount from t_order
where execTime < 时间窗口的结束时间戳 group by goodsId order by totalAmount
desc
- 数据呈现
消费者
[root@flink kafka_2.12-1.1.1]# bin/kafka-console-consumer.sh --bootstrap-server
192.168.116.141:9092 --topic order_binlog
[root@flink kafka_2.12-1.1.1]# bin/kafka-console-consumer.sh --bootstrap-server
192.168.116.141:9092 --topic orderAddress_binlog
[root@flink kafka_2.12-1.1.1]# bin/kafka-console-consumer.sh --bootstrap-server
192.168.116.141:9092 --topic orderPayment_binlog
删除Kafka主题
[root@flink kafka_2.12-1.1.1]# vi config/server.properties
delete.topic.enable=true
[root@flink kafka_2.12-1.1.1]# ./bin/kafka-topics.sh --delete --topic
order_binlog --zookeeper 192.168.116.141:2181
[root@flink kafka_2.12-1.1.1]# ./bin/kafka-topics.sh --delete --topic
orderAddress_binlog --zookeeper 192.168.116.141:2181
[root@flink kafka_2.12-1.1.1]# ./bin/kafka-topics.sh --delete --topic
orderPayment_binlog --zookeeper 192.168.116.141:2181
import cn.itcast.flink.screen.database.bo.HotOrder;
import cn.itcast.flink.screen.database.bo.Order;
import cn.itcast.flink.screen.database.json.GsonConvertUtil;
import cn.itcast.flink.screen.database.repository.HotOrderRepository;
import cn.itcast.flink.screen.database.spring.ApplicationContextUtil;
import com.google.gson.JsonArray;
import com.google.gson.JsonObject;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.common.state.ListState;
import org.apache.flink.api.common.state.ListStateDescriptor;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.functions.windowing.WindowFunction;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.util.Collector;
import org.springframework.boot.Banner;
import org.springframework.boot.CommandLineRunner;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.transaction.annotation.EnableTransactionManagement;
import java.util.*;
@SpringBootApplication
@ComponentScan(basePackages = {"cn.itcast"})
@EnableTransactionManagement
public class ScreenDatabaseApplication implements CommandLineRunner {
public static void main(String[] args) {
SpringApplication application = new SpringApplication(ScreenDatabaseApplication.class);
application.setBannerMode(Banner.Mode.OFF);
application.run(args);
}
@Override
public void run(String... args) throws Exception {
// 运行Flink任务
executeFlinkTask();
}
/**
* 执行Flink任务处理
*
* @throws Exception
*/
private void executeFlinkTask() throws Exception {
// 1. 创建flink运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 添加数据源(Kafka)
Properties props = new Properties();
props.setProperty("bootstrap.servers", "192.168.116.141:9092");
props.setProperty("group.id", "flink_group");
FlinkKafkaConsumer<String> flinkKafkaConsumer = new FlinkKafkaConsumer<String>(
"order_binlog",
new SimpleStringSchema(),
props
);
flinkKafkaConsumer.setStartFromEarliest(); // 尽可能从最早的记录开始
DataStreamSource<String> orderDataStreamSource = env.addSource(flinkKafkaConsumer);
// 3. 设置并行度
env.setParallelism(1); // 算子层面 > 环境 > 客户端 > 系统
// 4. 设置事件时间
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
// 5. 数据过滤
orderDataStreamSource.filter(new FilterFunction<String>() {
@Override
public boolean filter(String orderStr) throws Exception {
JsonObject jsonObject = GsonConvertUtil.getSingleton().getJsonObject(orderStr);
boolean isDdl = jsonObject.get("isDdl").getAsBoolean();
String type = jsonObject.get("type").getAsString();
return !isDdl && "insert".equalsIgnoreCase(type);
}
})
// 6. 数据转换
.flatMap(new FlatMapFunction<String, Order>() {
@Override
public void flatMap(String orderKafkaStr, Collector<Order> collector) throws Exception {
JsonArray data = GsonConvertUtil.getSingleton().getJsonObject(orderKafkaStr).getAsJsonArray("data");
for (int i = 0; i < data.size(); i++) {
JsonObject asJsonObject = data.get(i).getAsJsonObject();
Order order = GsonConvertUtil.getSingleton().cvtJson2Obj(asJsonObject, Order.class);
System.out.println("order >> " + order);
collector.collect(order);
}
}
})
// 7. 添加水印
.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<Order>(Time.seconds(0)) {
@Override
public long extractTimestamp(Order order) {
return order.getExecTime();
}
})
// 8. 根据商品id分组
.keyBy(Order::getGoodsId)
// 9. 设置时间窗(每3秒计算一次24小时内收到的订单)
.timeWindow(Time.hours(24), Time.seconds(3))
// 10. aggregate聚合统计(增量的形式,进来一条数据就统计一条数据)
.aggregate(
new AggregateFunction<Order, Order, Order>() {
@Override
public Order createAccumulator() {
Order order = new Order();
order.setTotalAmount(0L);
return order;
}
@Override
public Order add(Order order, Order order2) {
order2.setTotalAmount(
order2.getTotalAmount() + order.getExecPrice() * order.getExecVolume());
order2.setGoodsId(order.getGoodsId());
return order2;
}
@Override
public Order getResult(Order order) {
return order;
}
@Override
public Order merge(Order order, Order acc1) {
return null;
}
},
new WindowFunction<Order, HotOrder, Long, TimeWindow>() {
// 时间窗口对象 转换
@Override
public void apply(Long goodsId, TimeWindow timeWindow, Iterable<Order> iterable, Collector<HotOrder> collector) throws Exception {
Order order = iterable.iterator().next();
collector.collect(new HotOrder(goodsId, order.getGoodsName(), order.getTotalAmount(), timeWindow.getEnd()));
}
})
// 11. 根据TimeWindow分组
.keyBy(HotOrder::getTimeWindow)
// 12. 商品topN排行
.process(new KeyedProcessFunction<Long, HotOrder, String>() {
private ListState<HotOrder> hotOrderListState;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
hotOrderListState = getRuntimeContext().getListState(
new ListStateDescriptor<HotOrder>("hot-order", HotOrder.class)
);
}
@Override
public void processElement(HotOrder hotOrder, Context context, Collector<String> collector) throws Exception {
// 将数据添加到状态列表
hotOrderListState.add(hotOrder);
context.timerService().registerEventTimeTimer(hotOrder.getTimeWindow());
}
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector<String> out) throws Exception {
// 商品topN排行
ArrayList<HotOrder> hotOrders = new ArrayList<>();
hotOrderListState.get().forEach(hotOrder -> hotOrders.add(hotOrder));
hotOrders.sort(Comparator.comparing(HotOrder::getTotalAmount).reversed());
hotOrderListState.clear();
// 添加到es
HotOrderRepository hotOrderRepository = (HotOrderRepository) ApplicationContextUtil.getBean("hotOrderRepository");
hotOrders.forEach(hotOrder -> {
hotOrder.setId(hotOrder.getGoodsId());
hotOrder.setCreateDate(new Date(hotOrder.getTimeWindow()));
hotOrderRepository.save(hotOrder);
System.out.println("ES hotOrder" + hotOrder);
});
}
});
// 13. 执行任务
env.execute("es hotOrder");
}
}
kibana服务安装
Kibana是一个针对Elasticsearch的开源分析及可视化平台,用来搜索、查看交互存储在Elasticsearch索
引中的数据。
6. 到官网下载, Kibana安装包, 与之对应6.8.1版本, 选择Linux 64位版本下载,并进行解压。
7. Kibana启动不能使用root用户, 使用上面创建的elsearch用户, 进行赋权
chown -R elsearch:elsearch kibana-6.8.1-linux-x86_64
- 修改配置文件
vi config/kibana.yml , 修改以下配置:
# 服务端口
server.port: 5601
# 服务地址
server.host: "0.0.0.0"
# elasticsearch服务地址, 填写集群所有节点地址, 之间用逗号分割
elasticsearch.hosts: ["http://192.168.116.141:9200""]
- 启动kibana
./kibana -q
看到以下日志, 代表启动正常
log [01:40:00.143] [info][listening] Server running at http://0.0.0.0:5601
如果出现启动失败的情况, 要检查集群各节点的日志, 确保服务正常运行状态
4.4 区域分类统计
- 增加订单地址信息数据源
- 创建对应的表与实体
实体: OrderAddress
BO: JoinOrderAddress(订单数据与地址数据的合并对象)
BO: HotDimensionOrder(ES存储的映射对象), 注意这里的ID唯一性, 如果是按省份统计,
ID存储省份信息,如果是按地级市统计, ID则存储为市区信息。 - 改造订单数据源, 增加缓存写入, 地址信息数据源增加缓存的读取。
- 修改Canal的后台配置, 增加地址数据源的监听队列。
- 区域双流统计的核心代码实现:
1)增加双流的kafka配置, 每个流监听不同的数据队列。
2)每个流要加上时间水印, 设定时间窗, 设定值比后面聚合的时间窗稍小一些。
3)根据订单ID做join匹配。
4) 根据区域做汇总统计(省份、城市)。
5) 将数据写入至ES。 - 测试验证
验证SQL:
select province, goodsId, sum(execPrice * execVolume) totalAmount from
t_order odr left join t_order_address adr on odr.id = adr.orderId where
odr.execTime < 时间窗结束时间
group by province, goodsId order by province, totalAmount desc
import cn.itcast.flink.screen.database.bo.HotDimensionOrder;
import cn.itcast.flink.screen.database.bo.HotOrder;
import cn.itcast.flink.screen.database.bo.JoinOrderAddress;
import cn.itcast.flink.screen.database.bo.Order;
import cn.itcast.flink.screen.database.json.GsonConvertUtil;
import cn.itcast.flink.screen.database.pojo.OrderAddress;
import cn.itcast.flink.screen.database.repository.HotDimensionRepository;
import cn.itcast.flink.screen.database.repository.HotOrderRepository;
import cn.itcast.flink.screen.database.spring.ApplicationContextUtil;
import com.google.gson.JsonArray;
import com.google.gson.JsonObject;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.JoinFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.common.state.ListState;
import org.apache.flink.api.common.state.ListStateDescriptor;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor;
import org.apache.flink.streaming.api.functions.windowing.WindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.util.Collector;
import org.springframework.boot.Banner;
import org.springframework.boot.CommandLineRunner;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.transaction.annotation.EnableTransactionManagement;
import java.util.*;
@SpringBootApplication
@ComponentScan(basePackages = {"cn.itcast"})
@EnableTransactionManagement
public class ScreenDimensionApplication implements CommandLineRunner {
public static void main(String[] args) {
SpringApplication application = new SpringApplication(ScreenDimensionApplication.class);
application.setBannerMode(Banner.Mode.OFF);
application.run(args);
}
@Override
public void run(String... args) throws Exception {
// 运行Flink任务
executeFlinkTask();
}
/**
* 执行Flink任务处理
*
* @throws Exception
*/
private void executeFlinkTask() throws Exception {
// 1. 创建flink运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 添加数据源(Kafka)
Properties props = new Properties();
props.setProperty("bootstrap.servers", "192.168.116.141:9092");
props.setProperty("group.id", "flink_group");
// 2.1 订单数据源的读取
FlinkKafkaConsumer<String> orderKafkaConsumer = new FlinkKafkaConsumer<String>(
"order_binlog",
new SimpleStringSchema(),
props
);
orderKafkaConsumer.setStartFromEarliest(); // 尽可能从最早的记录开始
DataStreamSource<String> orderDataStreamSource = env.addSource(orderKafkaConsumer);
// 2.2 地址数据源的读取
FlinkKafkaConsumer<String> addressKafkaConsumer = new FlinkKafkaConsumer<String>(
"orderAddress_binlog",
new SimpleStringSchema(),
props
);
addressKafkaConsumer.setStartFromEarliest(); // 尽可能从最早的记录开始
DataStreamSource<String> addressDataStreamSource = env.addSource(addressKafkaConsumer);
// 3. 设置并行度
env.setParallelism(1);
// 4. 设置事件时间
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
// 5. 数据过滤转换处理
// 5.10 订单过滤
SingleOutputStreamOperator<Order> orderOperator = orderDataStreamSource.filter(new FilterFunction<String>() {
@Override
public boolean filter(String orderKafkaStr) throws Exception {
JsonObject jsonObject = GsonConvertUtil.getSingleton().getJsonObject(orderKafkaStr);
String isDdl = jsonObject.get("isDdl").getAsString();
String type = jsonObject.get("type").getAsString();
return "false".equalsIgnoreCase(isDdl) && "insert".equalsIgnoreCase(type);
}
})
// 5.11 订单转换
.flatMap(new FlatMapFunction<String, Order>() {
@Override
public void flatMap(String orderKafkaStr, Collector<Order> collector) throws Exception {
JsonArray data = GsonConvertUtil.getSingleton().getJsonObject(orderKafkaStr).getAsJsonArray("data");
for (int i = 0; i < data.size(); i++) {
JsonObject asJsonObject = data.get(i).getAsJsonObject();
Order order = GsonConvertUtil.getSingleton().cvtJson2Obj(asJsonObject, Order.class);
System.out.println("order >> " + order);
collector.collect(order);
}
}
})
// 5.12 订单添加水印
.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<Order>(Time.seconds(0)) {
@Override
public long extractTimestamp(Order order) {
return order.getExecTime();
}
});
// 5.20 地址过滤
SingleOutputStreamOperator<OrderAddress> addressOperator = addressDataStreamSource.filter(new FilterFunction<String>() {
@Override
public boolean filter(String orderKafkaStr) throws Exception {
JsonObject jsonObject = GsonConvertUtil.getSingleton().getJsonObject(orderKafkaStr);
String isDdl = jsonObject.get("isDdl").getAsString();
String type = jsonObject.get("type").getAsString();
return "false".equalsIgnoreCase(isDdl) && "insert".equalsIgnoreCase(type);
}
})
// 5.21 地址数据转换
.flatMap(new FlatMapFunction<String, OrderAddress>() {
@Override
public void flatMap(String orderKafkaStr, Collector<OrderAddress> collector) throws Exception {
JsonArray data = GsonConvertUtil.getSingleton().getJsonObject(orderKafkaStr).getAsJsonArray("data");
for (int i = 0; i < data.size(); i++) {
JsonObject asJsonObject = data.get(i).getAsJsonObject();
OrderAddress orderAddress = GsonConvertUtil.getSingleton().cvtJson2Obj(asJsonObject, OrderAddress.class);
System.out.println("orderAddress >> " + orderAddress);
collector.collect(orderAddress);
}
}
})
// 5.22 添加地址水印
.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<OrderAddress>(Time.seconds(0)) {
@Override
public long extractTimestamp(OrderAddress orderAddress) {
return orderAddress.getExecTime();
}
});
// 6. 订单数据流和地址数据流的join处理
orderOperator.join(addressOperator)
.where(Order::getId).equalTo(OrderAddress::getOrderId)
// 6.1 设置滚动时间 (这里的时间, 相比下面的时间窗滑动值slide快一些2s)
.window(TumblingEventTimeWindows.of(Time.seconds(2)))
// 6.2 使用apply合并数据流
.apply(new JoinFunction<Order, OrderAddress, JoinOrderAddress>() {
@Override
public JoinOrderAddress join(Order order, OrderAddress orderAddress) throws Exception {
return JoinOrderAddress.build(order, orderAddress);
}
})
// 6.3 将合并之后的数据,添加水印
.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<JoinOrderAddress>(Time.seconds(0)) {
@Override
public long extractTimestamp(JoinOrderAddress joinOrderAddress) {
return joinOrderAddress.getExecTime();
}
})
// 6.4 根据省份和商品ID进行数据分组
.keyBy(new KeySelector<JoinOrderAddress, Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> getKey(JoinOrderAddress joinOrderAddress) throws Exception {
return Tuple2.of(joinOrderAddress.getProvince(), joinOrderAddress.getGoodsId());
}
})
// 6.5 设置时间窗(每3秒统计24小时数据)
.timeWindow(Time.hours(24), Time.seconds(3))
// 6.6 使用aggregate进行聚合处理
.aggregate(
new AggregateFunction<JoinOrderAddress, JoinOrderAddress, JoinOrderAddress>() {
@Override
public JoinOrderAddress createAccumulator() {
JoinOrderAddress joinOrderAddress = new JoinOrderAddress();
joinOrderAddress.setTotalAmount(0L);
return joinOrderAddress;
}
@Override
public JoinOrderAddress add(JoinOrderAddress joinOrderAddress, JoinOrderAddress joinOrderAddress2) {
joinOrderAddress2.setTotalAmount(
joinOrderAddress2.getTotalAmount() + joinOrderAddress.getExecPrice() * joinOrderAddress.getExecVolume()
);
joinOrderAddress2.setProvince(joinOrderAddress.getProvince());
joinOrderAddress2.setGoodsId(joinOrderAddress.getGoodsId());
return joinOrderAddress2;
}
@Override
public JoinOrderAddress getResult(JoinOrderAddress joinOrderAddress) {
return joinOrderAddress;
}
@Override
public JoinOrderAddress merge(JoinOrderAddress joinOrderAddress, JoinOrderAddress acc1) {
return null;
}
},
new WindowFunction<JoinOrderAddress, HotDimensionOrder, Tuple2<String, Long>, TimeWindow>() {
@Override
public void apply(Tuple2<String, Long> stringLongTuple2, TimeWindow timeWindow,
Iterable<JoinOrderAddress> iterable, Collector<HotDimensionOrder> collector) throws Exception {
JoinOrderAddress joinOrderAddress = iterable.iterator().next();
collector.collect(new HotDimensionOrder(joinOrderAddress, timeWindow.getEnd()));
}
})
// 6.7 根据时间结束窗口时间分组
.keyBy(HotDimensionOrder::getTimeWindow)
// 6.8 省市商品topN销售统计process
.process(new KeyedProcessFunction<Long, HotDimensionOrder, String>() {
private ListState<HotDimensionOrder> hotDimensionOrderListState;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
hotDimensionOrderListState = getRuntimeContext().getListState(
new ListStateDescriptor<HotDimensionOrder>("hot-dimension-order", HotDimensionOrder.class)
);
}
@Override
public void processElement(HotDimensionOrder hotDimensionOrder, Context context, Collector<String> collector) throws Exception {
// 将数据添加到状态列表
hotDimensionOrderListState.add(hotDimensionOrder);
context.timerService().registerEventTimeTimer(hotDimensionOrder.getTimeWindow());
}
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector<String> out) throws Exception {
ArrayList<HotDimensionOrder> hotDimensionOrders = new ArrayList<>();
hotDimensionOrderListState.get().forEach(hotDimensionOrder -> hotDimensionOrders.add(hotDimensionOrder));
hotDimensionOrders.sort(Comparator.comparing(HotDimensionOrder::getProvince)
.thenComparing(HotDimensionOrder::getGoodsId, Comparator.reverseOrder()));
hotDimensionOrderListState.clear();
// 将数据发送到es
HotDimensionRepository hotDimensionRepository = (HotDimensionRepository) ApplicationContextUtil.getBean("hotDimensionRepository");
hotDimensionOrders.forEach(hotDimensionOrder -> {
hotDimensionOrder.setId(hotDimensionOrder.getProvince()+hotDimensionOrder.getGoodsId());
hotDimensionOrder.setCreateDate(new Date(hotDimensionOrder.getTimeWindow()));
hotDimensionRepository.save(hotDimensionOrder);
System.out.println("es hotDimensionOrder >> " + hotDimensionOrder);
});
}
});
// 7. 执行任务
env.execute("es hotDimensionOrder");
}
}
4.5 订单状态监控统计(CEP)
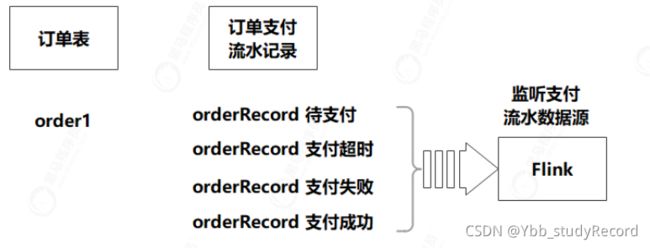
- 增加订单支付流水数据源
- 创建对应的表与实体
实体: OrderPayment
BO: JoinOrderAddress - 修改Canal的后台配置, 增加地址数据源的监听队列。
- 核心代码实现:
1)实现订单支付流水数据源的监听处理。
2)定义CEP处理规则,解析出支付成功的订单。 - 测试验证
检查订单状态是未支付 -》 已支付的数据
select * from t_order_payment pay where exists (
select 1 from t_order_payment tmp where tmp.orderId = pay.orderId and
tmp.status = 0
) and pay.status = 1
检查超时的数据: 初始状态为0, 指定时间之内没有已支付的数据。
6. 拓展实现, 热门商品统计排行,只统计支付成功的数据。
// 1. 创建flink运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 添加数据源(Kafka)
Properties props = new Properties();
props.setProperty("bootstrap.servers", "192.168.116.141:9092");
props.setProperty("group.id", "flink_group");
FlinkKafkaConsumer<String> orderPaymentKafkaConsumer = new FlinkKafkaConsumer<String>(
"orderPayment_binlog",
new SimpleStringSchema(),
props
);
orderPaymentKafkaConsumer.setStartFromEarliest(); // 尽可能从最早的记录开始
DataStreamSource<String> orderPaymentDataStreamSource = env.addSource(orderPaymentKafkaConsumer);
// 3. 设置并行度
env.setParallelism(1);
// 4. 设置事件时间
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
// 5. 数据过滤、转化、及添加时间水印
KeyedStream<OrderPayment, Long> orderPaymentLongKeyedStream = orderPaymentDataStreamSource.filter(new FilterFunction<String>() {
@Override
public boolean filter(String orderKafkaStr) throws Exception {
JsonObject jsonObject = GsonConvertUtil.getSingleton().getJsonObject(orderKafkaStr);
String isDdl = jsonObject.get("isDdl").getAsString();
String type = jsonObject.get("type").getAsString();
return "false".equalsIgnoreCase(isDdl) && "insert".equalsIgnoreCase(type);
}
})
.flatMap(new FlatMapFunction<String, OrderPayment>() {
@Override
public void flatMap(String orderKafkaStr, Collector<OrderPayment> collector) throws Exception {
JsonArray data = GsonConvertUtil.getSingleton().getJsonObject(orderKafkaStr).getAsJsonArray("data");
for (int i = 0; i < data.size(); i++) {
JsonObject asJsonObject = data.get(i).getAsJsonObject();
OrderPayment orderPayment = GsonConvertUtil.getSingleton().cvtJson2Obj(asJsonObject, OrderPayment.class);
System.out.println("orderPayment >> " + orderPayment);
collector.collect(orderPayment);
}
}
})
.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<OrderPayment>(Time.seconds(0)) {
@Override
public long extractTimestamp(OrderPayment orderPayment) {
return orderPayment.getUpdateTime();
}
})
// 6. 根据订单id分组
.keyBy(OrderPayment::getOrderId);
// 7. 通过CEP机制, 判断支付成功的数据
Pattern<OrderPayment, ?> pattern = Pattern.<OrderPayment>begin("begin").where(new SimpleCondition<OrderPayment>() {
@Override
public boolean filter(OrderPayment orderPayment) throws Exception {
return orderPayment.getStatus() == 0;
}
}).next("next").where(new SimpleCondition<OrderPayment>() {
@Override
public boolean filter(OrderPayment orderPayment) throws Exception {
return orderPayment.getStatus() == 1;
}
}).within(Time.seconds(15));
PatternStream<OrderPayment> patternStream = CEP.pattern(orderPaymentLongKeyedStream, pattern);
OutputTag orderExpired = new OutputTag<OrderPayment>("orderExpired"){};
SingleOutputStreamOperator<OrderPaymentResult> select = patternStream.select(orderExpired, new PatternTimeoutFunction<OrderPayment, OrderPaymentResult>() {
@Override
public OrderPaymentResult timeout(Map<String, List<OrderPayment>> map, long l) throws Exception {
OrderPaymentResult orderPaymentResult = new OrderPaymentResult();
OrderPayment orderPayment = map.get("begin").iterator().next();
orderPaymentResult.setOrderId(orderPayment.getOrderId());
orderPaymentResult.setStatus(orderPayment.getStatus());
orderPaymentResult.setUpdateTime(orderPayment.getUpdateTime());
orderPaymentResult.setMessage("支付超时");
return orderPaymentResult;
}
}, new PatternSelectFunction<OrderPayment, OrderPaymentResult>() {
@Override
public OrderPaymentResult select(Map<String, List<OrderPayment>> map) throws Exception {
OrderPaymentResult orderPaymentResult = new OrderPaymentResult();
OrderPayment orderPayment = map.get("next").iterator().next();
orderPaymentResult.setOrderId(orderPayment.getOrderId());
orderPaymentResult.setStatus(orderPayment.getStatus());
orderPaymentResult.setUpdateTime(orderPayment.getUpdateTime());
orderPaymentResult.setMessage("支付成功");
return orderPaymentResult;
}
});
select.print("payed");
// 8. 执行任务
env.execute("payed job");
}
}
4.6 商品UV统计
功能: 统计商品在一段时间内的UV(Unique Visitor)
核心代码:
import cn.itcast.flink.screen.database.bo.GoodsAccessLog;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import org.springframework.boot.Banner;
import org.springframework.boot.CommandLineRunner;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.transaction.annotation.EnableTransactionManagement;
import java.util.HashSet;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.Set;
@SpringBootApplication
@ComponentScan(basePackages = {"cn.itcast"})
@EnableTransactionManagement
public class ScreenUniqueVisitorApplication implements CommandLineRunner {
public static void main(String[] args) {
SpringApplication application = new SpringApplication(ScreenUniqueVisitorApplication.class);
application.setBannerMode(Banner.Mode.OFF);
application.run(args);
}
@Override
public void run(String... args) throws Exception {
// 运行Flink任务
executeFlinkTask();
}
/**
* 执行flink任务处理
*
* @throws Exception
*/
public void executeFlinkTask() throws Exception {
// 1. 创建运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.IngestionTime);
env.setParallelism(1);
// 2. 读取数据源(goods_access.log)
DataStreamSource<String> goodsAccessDataStreamSource = env.readTextFile("data/goods_access.log");
// 3. 数据解析转换处理
goodsAccessDataStreamSource.flatMap(new FlatMapFunction<String, GoodsAccessLog>() {
@Override
public void flatMap(String goodsAccessStr, Collector<GoodsAccessLog> collector) throws Exception {
// 获取Json中的data数据
// 根据分隔符解析数据
String[] elements = goodsAccessStr.split("\t");
System.out.println("receive msg => " + goodsAccessStr);
// 将数据组装为对象
GoodsAccessLog goodsAccessLog = new GoodsAccessLog();
goodsAccessLog.setIp(elements[0]);
goodsAccessLog.setAccessTime(Long.valueOf(elements[1]));
goodsAccessLog.setEventType(elements[2]);
goodsAccessLog.setGoodsId(elements[3]);
collector.collect(goodsAccessLog);
}
})
.filter(new FilterFunction<GoodsAccessLog>() {
@Override
public boolean filter(GoodsAccessLog goodsAccessLog) throws Exception {
return goodsAccessLog.getEventType().equals("view");
}
})
.keyBy(GoodsAccessLog::getGoodsId)
.timeWindow(Time.seconds(10))
.process(new ProcessWindowFunction<GoodsAccessLog, Map<String, String>, String, TimeWindow>() {
@Override
public void process(String key, Context context, Iterable<GoodsAccessLog> elements,
Collector<Map<String, String>> collector) throws Exception {
Set<String> ipSet = new HashSet<>();
Map<String, String> goodsUV = new LinkedHashMap<>();
elements.forEach(log -> {
ipSet.add(log.getIp());
});
goodsUV.put(key, context.window().getEnd() + ":" + ipSet.size());
collector.collect(goodsUV);
}
})
.print("uv result").setParallelism(1);
// 5. 执行任务
env.execute("job");
}
}
4.7 布隆过滤器
功能: 统计商品在一段时间内的UV(采用布隆过滤器)
核心代码:
);
// 5. 执行任务
env.execute("job");
}
/**
* 自定义窗口触发器
*/
public static class CustomWindowTrigger extends Trigger<GoodsAccessLog, TimeWindow> {
@Override
public TriggerResult onElement(GoodsAccessLog element, long timestamp, TimeWindow window, TriggerContext ctx) throws Exception {
// 对象到达时进行触发和清除
return TriggerResult.FIRE_AND_PURGE;
}
@Override
public TriggerResult onProcessingTime(long time, TimeWindow window, TriggerContext ctx) throws Exception {
// 处理时间之内,继续执行
return TriggerResult.CONTINUE;
}
@Override
public TriggerResult onEventTime(long time, TimeWindow window, TriggerContext ctx) throws Exception {
// 到达数据的事件时间
return TriggerResult.CONTINUE;
}
@Override
public void clear(TimeWindow window, TriggerContext ctx) throws Exception {
}
}
/**
* 自定义布隆过滤器处理
*/
private class CustomUVBloom extends ProcessWindowFunction<GoodsAccessLog, Tuple2<String, String>, String, TimeWindow> {
private transient ValueState<BloomFilter> bloomState;
private transient ValueState<Long> countState;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
ValueStateDescriptor<BloomFilter> bloomFilterValueStateDescriptor = new ValueStateDescriptor<BloomFilter>("bloomState", BloomFilter.class);
bloomState = getRuntimeContext().getState(bloomFilterValueStateDescriptor);
countState = getRuntimeContext().getState(new ValueStateDescriptor<Long>("count-state", Long.class));
}
@Override
public void process(String s, Context context, Iterable<GoodsAccessLog> elements, Collector<Tuple2<String, String>> out) throws Exception {
BloomFilter bloomFilter = bloomState.value();
if(bloomState.value() == null ) {
// 设定期望插入的数据量
bloomFilter = BloomFilter.create(Funnels.unencodedCharsFunnel(), 1000000);
countState.update(0L);
}
Iterator<GoodsAccessLog> accessLogs = elements.iterator();
while(accessLogs.hasNext()) {
GoodsAccessLog log = accessLogs.next();
// 判断是否包含重复的访问IP
String repeatKey = log.getIp() + log.getGoodsId();
if(!bloomFilter.mightContain(repeatKey)) {
bloomFilter.put(repeatKey);
countState.update(countState.value() + 1);
bloomState.update(bloomFilter);
out.collect(Tuple2.of(log.getGoodsId(), countState.value().toString()));
}
}
}
}
}