干货 | 面向多任务学习和领域泛化的公平感知机器学习
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!

讲者简介
赵辰:
贝勒大学助理教授。博士毕业于美国得克萨斯大学达拉斯分校计算机专业。主要研究方向为公平性学习在数据发掘,机器学习,深度学习上的研究和应用。在包括KDD,CVPR, AAAI,WWW,ICASSP等会议与期刊上发表过多篇论文,并受邀担任KDD,NeurIPS,AAAI,ICDM,AISTATS等人工智能领域顶级国际会议程序委员和审稿人。
个人主页:
https://charliezhaoyinpeng.github.io/homepage/
分享内容
面向多任务学习和领域泛化的公平感知机器学习
报告简介
现如今,因为人类曾经做出的决定现在被委托给了自动化系统,机器学习在我们的生活中扮演着越来越重要的角色。近年来,越来越多的报道指出,高科技公司应用的人工智能系统揭示了人类的偏见。例如,有新闻揭露曾经的亚马逊公司人工智能招聘系统对少数群体存在偏见。因此,开发负责任和值得信赖的机器学习模型的一个关键组成部分是确保这些模型不会不公平地损害任何人口的子群体。然而大多数现有的公平感知算法都专注于解决局限于单个任务或静态环境的机器学习问题。对于在不断变化的环境中联合多个有偏见的任务去学习一个公平的模型的研究几乎很少被涉及。在这次演讲中,赵辰老师重点介绍了一些关于公平意识机器学习的已发表和正在进行的工作,这些作品涉及在线/离线范式和静态/变化环境的设置。最后,对今后的研究方向和其他课题的研究工作进行展望。
1)Background
Why fariness in machine learning is important?
人工智能在我们的生活中扮演了越多越多的角色,已经融入到日常的生活、科技产品中。在很多应用中,其中的技术通常都是基于human bias的数据进行训练的,所以训练模型在某种程度上会受到人类偏见的影响。

Motivations
下图中以一个实际的例子说明。给定一组混合的男女厨师在厨房中工作的照片,利用深度学习模型进行一个二分类任务,其中的标签可以判定一个人是否在烹饪,但是照片中的人物可以被纵向分类成男、女。但是受人类偏见的影响,模型预测出的结果更多地显示女性在厨房中扮演厨师的角色,这其实就是一种偏见性的预测。

所以,从机器学习的角度来讲,预测模型产生的predicted outcome在某些程度上会受到敏感性信息的影响,但是本身不影响模型的分类任务。那么,我们希望训练一个相对公平的模型,使得模型预测的结果与敏感性信息是相对独立的,即可以相互独立在一个可接受的范围内。

我们将该问题优化成如下图所示的数学形式:其中,y表示样本的标签,f表示model,y弧表示模型的产出,s代表sensitive information。

Brief introduction of fairness-aware machine learnning?
2)Fairness-Aware Machine Learning
我今天从两方向、四象限来介绍公平感知机器学习的相关知识。
Offline Learning & Static Environment
3)Multi-task fairness learning based on nonparametric statistical tests
在传统的机器学习模型中,我们希望训练training domain中的所有数据使其在test domain中有很好的展现力。当有多个模型时,我们期望能有一种统一的方法来训练,所有模型能够共享一套参数。
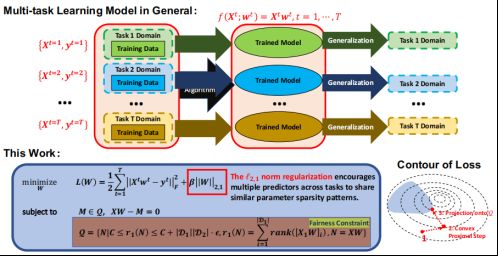
在这项工作中,我们开发了一种基于有偏训练数据集的多任务回归模型的新颖的公平学习方法,使用流行的基于秩的非参数独立性测试,即Mann Whitney U统计量,来测量目标变量和受保护变量之间的依赖关系。为了有效地解决这个学习问题,我们首先将问题重新表述为一个新的非凸优化问题,其中基于单个对象的分组排序函数定义非凸约束。然后,我们开发了一种基于非凸交替方向乘子法(NC-ADMM)框架的高效模型训练算法,其中主要挑战之一是实现基于排序函数定义的先前非凸集的有效投影预测。通过对合成数据集和真实数据集进行广泛的实验,我们验证了我们的新方法在与公平学习相关的几个流行指标上相对于几种最先进的竞争方法的性能。

4)Fair meta-learning for few-shot supervised learning
在训练步骤中学习对未见过的类进行泛化的问题(少样本分类),已经引起了相当大的关注。基于初始化的方法,例如基于梯度的模型不可知元学习(MAML),通过“学习微调”来解决小样本学习问题。这些方法的目标是学习正确的模型初始化,以便可以通过少量的梯度更新步骤从一些带标签的示例中学习新类的分类器。少样本元学习以其快速适应能力和对未见过的任务的准确性泛化而闻名。公平地学习并获得不带偏见的结果是人类智能的另一个重要标志,而这一点在小样本元学习中很少被触及。
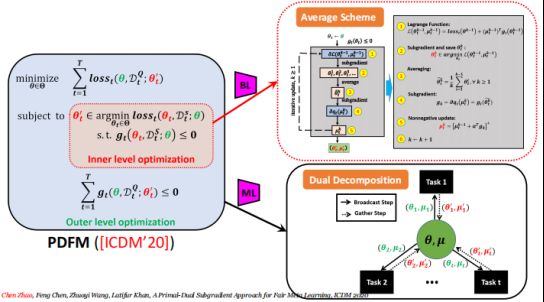
在这项工作中,我们提出了一种原始-对偶公平元学习框架,即PDFM,该框架仅使用基于相关任务的数据的几个示例来学习训练公平的机器学习模型。关键思想是学习公平模型的原始参数和对偶参数的良好初始化,以便它可以通过几个梯度更新步骤适应新的公平学习任务。PDFM不是通过网格搜索手动调整双参数作为超参数,而是通过次梯度原对偶方法联合优化原始参数和对偶参数的初始化,以实现公平的元学习。
我们进一步实例化了一个使用决策边界协方差(DBC)作为每个任务的公平性约束的偏差控制示例,并通过将其应用于各种三个现实世界数据集的分类来证明我们提出的方法的多功能性。我们的实验表明,与此设置之前的最佳工作相比,有很大的改进。
Online Learning & Static Environment
5)Fairness-Aware Online Meta-Learning with Multiple Tasks
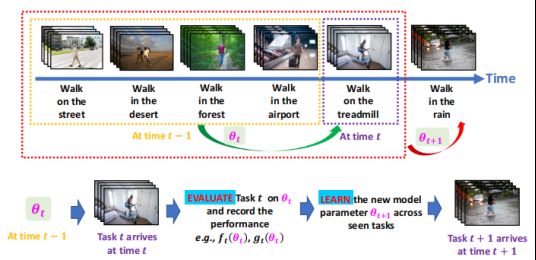
综合来说,这种Fairness-Aware Online Meta-Learning有很多task,步骤大致如下图所示。在t-1时刻,有一个meta-level模型;当到t时刻,即新的任务来到时,采用θt对新的任务进行测试,测试结果以及损失值都会被记录下来。然后,我们会把新学的任务加进去之后再去学θt+1这样一个参数。之后,我们再move到新的循环。如何在这个过程中学到新的meta-level参数,是一个比较重要的关键点。
6)Fairness-Aware Online Meta-learning, KDD 2021
本文首次提出了一种新颖的在线元学习算法,即FFML,它是在不公平预防的背景下进行的。FFML的关键部分是学习在线公平分类模型的原始参数和对偶参数的良好先验,这些参数分别与模型的准确性和公平性相关。该问题以双层凸凹优化的形式表述。
7)The regret
整个的online meta-learning可以被看成在最小化一个regret。上述两个步骤最大的假设是:所有的task来自同一个domain,我们要考虑的就是task domain在某一时间点发生变化的时候,work该怎样快速适应这个方式。

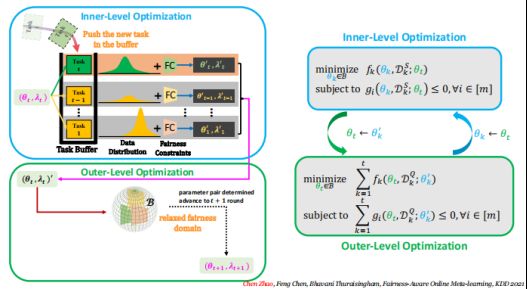
8)Bi-level optimization
整个优化过程可以被看作是一个Bi-Level Optimization双层优化,是一种你中有我,我中有你的过程。Interval-level的一个output被当成了meta-level的input,meta-level的output也会被当成interval-level的input,如此不断迭代更新。
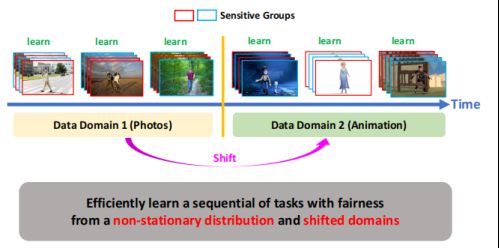
Offline Learning & Changing Environment
Adaptive Fairness-Aware Online Meta-Learning for Changing Environments
当domain发生变化的时候,如何快速适应新的domain?
An intuitive approach
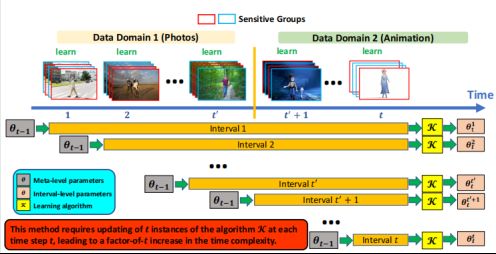
在online-learning中研究出合适的算法是非常重要的。如下图所示,假设将算法命名为K,在适应不同域时就可以将每个任务建立的interval统一传入meta-level parameter。根据之前的算法,可以针对每个interval得到的meta-level parameter。我们对所有的结果加权平均就能得到最后的meta-level parameter。为了可以更好地适应域,我们一般会让权重在新的域上更大,也使得新学到的meta-level parameter更加适应后面的域,让任务也更好适应。

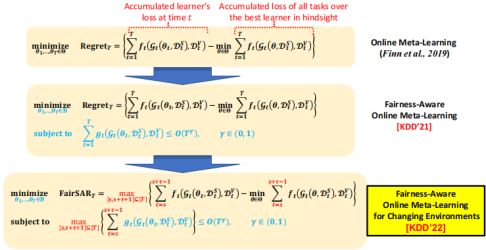
Strongly adaptive regret in fairness-aware online meta-learning
Regret会随着interval的增加而改变,在之前的工作中有很多的interval,loss regret就需要从所有interval里挑出最大的regret进行最小化。对于fairness notion来说,我们对每个interval都计算出一个fairness notion,然后挑出最大的fairness notion进行最小化。
Updating interval parameters leads to high time complexity
但是上述方法是存在缺陷的,最大的缺陷在于interval会随着时间的增多而增大,并呈线性增长。其时间复杂度也会很大,针对这个问题我们改进了一些工作。
Adaptive geometric covering(AGC) intervals
我们的研究动机是为了降低时间复杂度,所以我们将所有的interval用log的方式分成了4个不同的set,并且每个set中的interval长度一致。我们将log对数以2为底,算出每个set的固定长度。
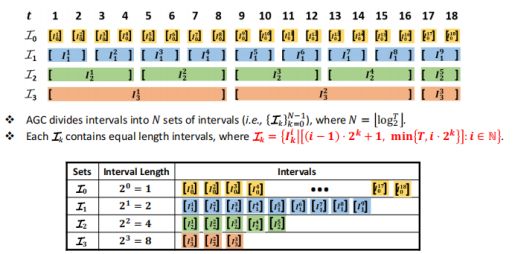
Target set - a selected subset of intervals
每个时间点,我们会取一定的interval set,即target set。其中包括了所有的interval,但却是以时间点开头的。

The learning experts
我们构建了一个算法,使得每一个interval可以想象成expert的learning process。它分为两部分,包括active experts和sleeping experts。但是active experts或者sleeping experts是随着时间t在动态变化的。
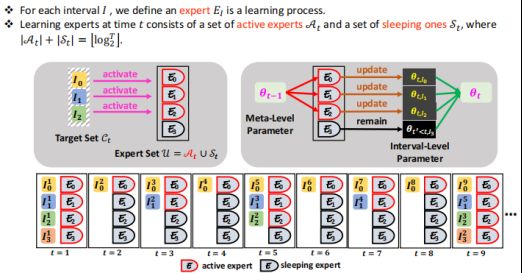
Learning with experts
t=1时,active experts挑选每个set中的第一个当作target set。t=2时,只有一个被选入了target set,激活第一个为active experts,剩下的就是sleeping experts。在t=3的时候,以此类推。
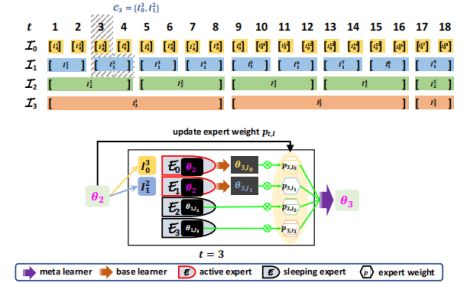
Online Learning & Changing Environment
Domain generalization(DG) problems
领域泛化研究的问题是从若干个具有不同数据分布的数据集(领域)中学习一个泛化能力强的模型,以便在未知的测试集上取得较好的效果。DG问题中,我们只能访问若干个用于训练的源域数据,测试数据是不能访问的。
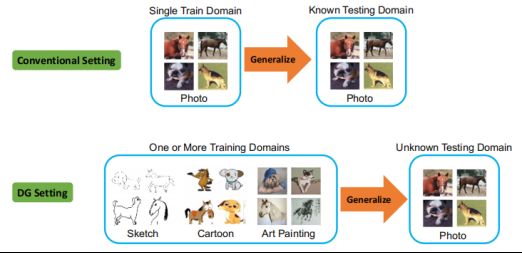
Solutions
为了解决domain generalization Fairness-aware的问题,我们将整个问题分为两个stage。Stage1用来训练encoder与decoder,在stage2中假设stage1是训练完的,那么domain generalization其实是任意的AI训练模型的方式都是在模拟真人,学习真人的特征。

9)Research on Other Topics
我们后续的研究方向主要分为两点:一是不确定性推理与量化,二是领域泛化,比如与causal models结合进行一些纯理论的分析、时间序列分析等等。

整理:陈研
审核:赵辰
提醒
点击“阅读原文”跳转到00:00:01
可以查看回放哦!
往期精彩文章推荐

记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了1100多位海内外讲者,举办了逾550场活动,超600万人次观看。

我知道你
在看
哦
~
![]()
点击 阅读原文 观看回放!