Explorable Tone Mapping Operators
Abstract
色调映射在高动态范围(HDR)成像中起着至关重要的作用。 它的目的是在有限动态范围的介质中保存HDR图像的视觉信息。 虽然许多工作已经提出从HDR图像中提供色调映射结果,但大多数只能以一种预先设计的方式进行色调映射。 然而,声调映射质量的主观性因人而异,声调映射风格的偏好也因应用而异。 本文提出了一种基于学习的多模态色调映射方法,该方法不仅获得了良好的视觉质量,而且探索了风格的多样性。 该方法基于Byclegan[1]的框架,通过操纵不同的潜在码,可以提供多种专家级的声调映射结果。 最后,我们证明了所提出的方法在定性和定量上都优于现有的音调映射算法。
I. INTRODUCTION
在现实世界中,自然场景的动态范围(DR)往往太宽(DR>10^7),相机无法捕捉,尤其是对太阳等直射光源。 由于多曝光融合技术[2]的发展,我们可以将不同曝光的图像中的所有细节融合到一张高动态范围(HDR)图像中。
HDR图像包含丰富的视觉信息,需要较高的位深度来存储大动态范围的数据。 然而,大多数显示设备只能显示低动态范围的图像(LDR,通常存储在8位)。 然后提出了色调映射算法,将HDR图像压缩为LDR图像,同时尽量保留感知内容。
在过去的二十年里,人们提出了一系列的音调映射算法[3]、[4]、[5]、[6]。 其中许多方法将HDR图像分解为两个部分:一个是经过平滑处理但仍保持原始全局动态范围的基本层,另一个是仅具有局部边缘或细节信息的细节层。 在将基础层和细节层融合回LDR图像之前,基础层通常被压缩以减小动态范围,而细节层被增强或提升以保留更好的视觉内容。
该方案将HDR图像中的低频信息和高频信息分开处理,在保持LDR图像局部细节的同时,大大压缩了图像的动态范围。 因此,将HDR图像分解为基础层和细节层对色调映射方法的质量有很大影响,而分解的方式几乎构成了不同方法之间的主要区别。
至于细节增强,一些方法试图使黑暗物体周围的区域变亮,从而导致光晕伪影[3]。 另外一些方法过分强调边缘信息,从而产生不切实际的过增强结果[7]。 虽然有一些方法可以解决这些问题,但它们通常只在特定类型的图像上有效,并且需要大量的参数调整才能获得最佳的结果[4]。 这个调优过程通常很耗时,而且很难重现。
最近还提出了基于深度学习的声调映射方法。 它们通常被建模为图像到图像的翻译任务。 杨等人[8]使用自动编码器架构将HDR图像转换为LDR图像。 然而,像不真实的颜色和对比度这样的伪影可以在他们的结果中看到。 拉纳等人[9]使用多尺度CGAN架构。 但是,当测试图像的尺度与训练图像不同时,仍然存在光环伪影,并可能导致其他伪影。 此外,上述基于深度学习的声调映射方法都是一对一映射,提供的主观风格较少。
本文提出了一种基于学习的多模态声调映射方法。 该方法可分为两个部分。 一个是EdgePreservingNet,它输出局部变化的内核,用于将输入的HDR图像分解为基础层和细节层。 另一个是预测全局音调压缩曲线的ToneCompressingNet。 两者都根据输入HDR图像的内容和动态范围自适应动态运行。
该方法以最小的伪影获得了良好的质量,在客观和主观上都优于现有的调音算法。 此外,由于Bicclegan[1]的体系结构,我们的方法可以从单个HDR图像中产生多样化的视觉吸引力的tonemapped结果。
我们的主要贡献总结如下:
1)提出了一种基于深度学习的音调映射方法,该方法由一个边缘保留网和一个ToneCompressingNet组成。
2)通过整合bicclegan体系结构,本文提出的方法能够从单个HDR图像中生成不同的色调映射结果。
3)利用双边滤波器,在保持HDR图像高频信息的同时压缩了动态范围的大部分。
4)与现有方法相比,该方法的主观评价和客观评价均较好。
II. RELATED WORK
A. Tone mapping
在过去的二十年里,人们提出了许多声调映射算法。 根据算法的工作方式,它们可以大致分为全局方法和局部方法。 全局色调映射方法在HDR图像的每个像素上使用单一的色调映射曲线[10],[11],这往往会造成对比度和细节信息的损失。 相比之下,局部音调映射方法利用空间特性自适应地执行此任务[12]。 全局方法需要更少的计算时间,而局部方法生成更好的细节。 局部方法通常将图像分解为两个部分:平滑的基础层和细节层[13]。 在局部方法中,晕影通常发生在边缘周围。 局部色调映射算法主要是为了减少这些伪影而提出的。 Durand和Dorsey在[3]中提出了使用边缘保持的双边滤波器来进行色调映射,但是在一些图像中仍然存在晕影。 曼蒂克等人[7]提出了对比处理框架,但细节被过度增强。 法布曼等人[14]提出了一种使用加权最小二乘滤波器的多尺度方案。 梁等人[6]提出了混合L1-L0分解模型。
虽然前人的工作取得了很好的效果,但对于不同的图像,通常需要进行超参数调整以达到最佳的视觉质量和减少晕影伪影。 近年来,基于深度学习的方法被提出,不需要参数调整,利用强大的GPU大大缩短了计算时间。 帕特尔等人[15]使用生成对抗网络(GAN)[16]来执行音调映射。 但问题过于简单化,只能在256×256的小块上进行测试。 杨等人[8]应用带有跳过连接的自动编码器网络将HDR图像传输到LDR空间。 然而,它们未能在一般HDR图像上产生良好的结果。 拉纳等人[9]使用条件生成对抗网络(CGAN)[17]和多尺度方案对图像进行色调映射。 虽然结果获得了很高的TMQI[18]分数,但结果包含光环伪影。 在这项工作中,我们采用BycleGan[1]来允许我们的模型生成多个高质量的色调映射图像。 分解方案使我们的模型能够产生没有晕轮效应的有吸引力的结果。
B. Multimodal image-to-image translation
模式崩溃是CGAN[17]中的一个著名问题。 鲍等人[19]提出了CVAE-GAN,它将变分自动编码器与生成对抗网络相结合,生成现实和不同的结果。 朱等人[1]将CVAE-GaN和CLR-GaN[20]、[21]、[22]组合成双环算法,使编码器产生的潜在码具有可逆性,并显示出更好的性能。 杨等人[23]在生成器中提出了一个新的正则化项来解决这种模式崩溃问题。
III. METHOD
A. Learning-based Bilateral Filters
双边滤波[3]是最常见的调音算子之一。 该算子的核心思想是将HDR图像分解为基础层和细节层,分别代表HDR图像的大部分动态范围和高频信息。 然而,基础层和细节层通常是通过一些手工制作的边缘保持过滤器和压缩操作来分解的。 由于参数量大,调优这些过滤器和操作通常是困难和耗时的。
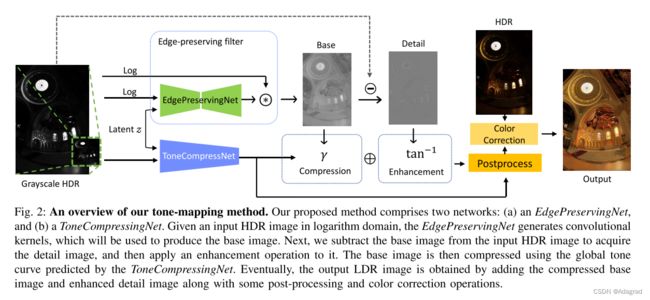
代替手工制作的过滤器和操作,我们提出了一个基于学习的方案,如图所示 2. 该方案包括两个网络:(a)EdgePreservingNet和(b)ToneCompressingNet。 为了避免伪影,我们将EdgePreservingNet设为核预测网络(KPN)[24]。 因此,给定输入的HDR图像在对数域,EdgePreservingNet生成卷积核来生成基图像。 接下来,通过从输入HDR图像中减去基本图像来获取细节图像。 为了提高图像的视觉质量,我们对细节图像进行了增强处理。 然后使用ToneCompressingNet(典型的Conv-FC网络)预测的全局色调曲线对基图像进行压缩。 最后,将压缩后的基础图像和增强后的细节图像相加,并进行后处理和颜色校正,得到输出的LDR图像。 图 3展示了一个分解图像的例子。
EdgePreservingNet和ToneCompressingNet是使用BycleGan框架联合训练的,这将在第三-C节中描述。 值得一提的是,在训练过程中向这些网络中输入各种随机潜在码Z,使它们能够生成各种LDR图像。 此外,在第III-D节将介绍一个潜在代码优化方案,以帮助用户找到合适的潜在代码。
B. Tone Mapping Operators
我们将U-Net[25]体系结构应用于EdgePreservingNet,它由一个带有跳过连接的编码器-解码器组成。 正如Gu等人所建议的那样[12]中,输入的HDR图像首先被变换到对数域,然后归一化到[0,1]以适应人类的感知。 EdgePreservingNet不是直接生成基图像,而是预测一个大小为h×w×k^2的像素级滤波器,其中k是核大小,h,w是图像的高度和宽度。 然后对每个像素WP处的预测核进行归一化
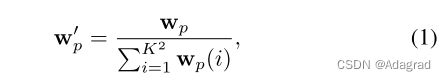
其中I被称为WP的每个元素。 图 4表明这种归一化对色调映射的性能至关重要。
因此,通过在对数域中对输入HDR图像IHDR应用卷积来给出基图像IBASE
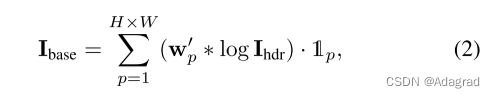
其中1p表示像素p的值为1,否则为0。 然后通过idetail=ihdr-ibase获得细节图像。

ToneCompressingNet由一系列连续的卷积层和一些完全连接的层组成。该网络可以预测压缩速率γ基以及后处理γ后的程度。压缩后的基本图像由



D. Latent Code Optimization
回忆一下,色调映射是一个主观的任务,也就是说,人们喜欢不同类型或风格的色调映射图像。虽然我们的方法允许用户通过调整潜码来改变样式,但是由于搜索空间非常大,要找到合适的样式仍然是一个很大的挑战。在测试阶段,我们提出了一种优化音调映射的代表性评估指标TMQI[18]的方案,以帮助用户过滤掉不合适的潜在码,而不是使用随机潜码。给定一个训练良好的音调映射算子,该算子具有固定的模型参数和初始潜码,然后使用Adam[30]优化器通过反向传播迭代优化潜码。一般来说,这个过程通过大约30次迭代收敛。在该方案中,用户只需从少数候选码中选择潜在码即可。请注意,TMQI和我们的模型都是可微的。
V. CONCLUSIONS
提出了一种新的基于深度学习的调音方法。 该方法在定性和定量上均优于现有的传统方法和基于学习的方法。 我们还提供了一个用户研究,使实验结果更有说服力。 此外,通过调整潜在代码,该方法可以产生多种专家级的音调映射结果。
至于未来的工作,使潜在的代码更易于解释和调整可能是一个可能的方向。