贝叶斯深度学习的温和介绍
一、说明
欢迎来到令人兴奋的概率编程世界!本文是对这个领域的温和介绍,你只需要对深度学习和贝叶斯统计有一个基本的了解。如果像我一样,你听说过贝叶斯深度学习,并且你猜它涉及贝叶斯统计,但你不知道它是如何使用的,那么你来对地方了。
二、传统深度学习的局限性
传统深度学习的主要局限性之一是,尽管它们是非常强大的工具,但它们并不能衡量其不确定性。
聊天 GPT 可以公然自信地说出虚假信息。分类器输出的概率通常未经校准。
不确定性估计是决策过程的一个重要方面,特别是在医疗保健、自动驾驶汽车等领域。我们希望一个模型能够估计何时非常不确定将受试者归类为脑癌,在这种情况下,我们需要医学专家的进一步诊断。同样,我们希望自动驾驶汽车在识别新环境时能够减速。
为了说明神经网络估计风险有多糟糕,让我们看一个非常简单的分类器神经网络,最后有一个softmax层。
softmax有一个非常容易理解的名字,它是一个Soft Max函数,这意味着它是max函数的“更平滑”版本。这样做的原因是,如果我们选择一个“硬”max函数,只是以最高概率取类,那么所有其他类的梯度将为零。
使用 softmax,类的概率可以接近 1,但永远不会完全为 1。由于所有类的概率总和为 1,因此仍有一些梯度流向其他类。
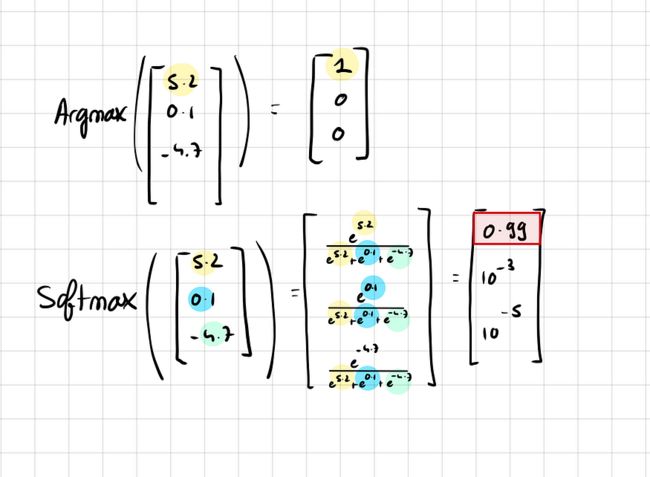
硬最大与软最大,图片由作者提供
但是,softmax函数也存在一个问题。它输出校准不佳的概率。应用 softmax 函数之前值的微小变化会被指数压缩,从而导致输出概率的最小变化。
这通常会导致过度自信,即使面对不确定性,模型也会为某些类提供高概率,这是softmax函数的“max”性质所固有的特征。
将传统神经网络(NN)与贝叶斯神经网络(BNN)进行比较可以突出不确定性估计的重要性。当 BNN 遇到来自训练数据的熟悉分布时,它的确定性很高,但随着我们远离已知分布,不确定性会增加,从而提供更真实的估计。
以下是对不确定性的估计:

传统 NN 与贝叶斯 NN,图片由作者提供
您可以看到,当我们接近在训练期间观察到的分布时,模型是非常确定的,但是随着我们远离已知分布,不确定性会增加。
三、贝叶斯统计简要回顾
贝叶斯统计中有一个中心定理需要知道:贝叶斯定理。

贝叶斯定理,图片来源:作者
- 先验是我们认为在任何观察之前最有可能的θ分布。例如,对于抛硬币,我们可以假设正面朝上的概率是高斯的概率,大约p = 0.5
- 如果我们想尽可能少地放置感应偏置,我们也可以说 p 在 [0,1] 之间是均匀的。
- 给出参数θ的可能性,我们得到观测值X,Y的可能性有多大
- 边际可能性是在所有可能的θ上积分的可能性。它之所以被称为“边际”,是因为我们通过对所有概率进行平均来边缘化θ。
贝叶斯统计中要理解的关键思想是,您从先验开始,这是您对参数可能是什么(它是一个分布)的最佳猜测。通过你所做的观察,你调整你的猜测,你得到一个后验分布。
请注意,先验和后验不是对θ的准时估计,而是概率分布。
为了说明这一点:
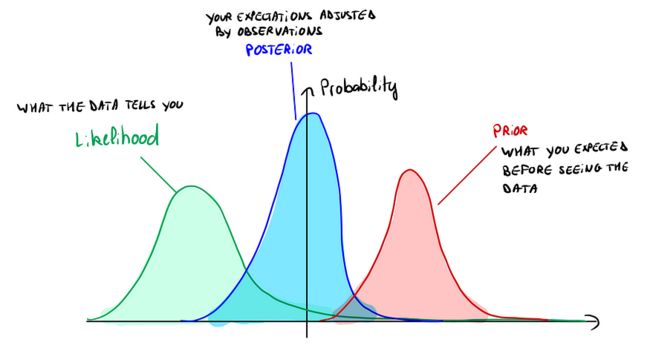
图片来源:作者
在这张图片上,你可以看到先验向右移动,但可能性重新平衡了我们的先验向左,后验介于两者之间。
四、贝叶斯深度学习简介
贝叶斯深度学习是一种结合了两种强大数学理论的方法:贝叶斯统计和深度学习。
与传统深度学习的本质区别在于对模型权重的处理:
在传统的深度学习中,我们从头开始训练一个模型,我们随机初始化一组权重,并训练模型,直到它收敛到一组新的参数。我们学习一组权重。
相反,贝叶斯深度学习采用更动态的方法。我们从对权重的先验信念开始,通常假设它们服从正态分布。当我们向数据公开我们的模型时,我们调整了这个信念,从而更新了权重的后验分布。从本质上讲,我们学习权重的概率分布,而不是单个集合。
在推理过程中,我们平均所有模型的预测,并根据后验加权它们的贡献。这意味着,如果一组权重极有可能,则其相应的预测被赋予更多的权重。
让我们将所有这些形式化:

推理,图片来自作者
贝叶斯深度学习中的推理使用后验分布对θ(权重)的所有潜在值进行积分。
我们还可以看到,在贝叶斯统计中,积分无处不在。这实际上是贝叶斯框架的主要限制。这些积分通常是难以处理的(我们并不总是知道后验的基元)。因此,我们必须进行计算成本非常高的近似。
五、贝叶斯深度学习的优势
优势1:不确定性估计
- 可以说,贝叶斯深度学习最突出的好处是它的不确定性估计能力。在医疗保健、自动驾驶、语言模型、计算机视觉和定量金融等许多领域,量化不确定性的能力对于做出明智的决策和管理风险至关重要。
优势2:提高培训效率
- 与不确定性估计概念密切相关的是提高训练效率。由于贝叶斯模型意识到自己的不确定性,因此它们可以优先从不确定性(因此,学习潜力)最高的数据点学习。这种方法被称为主动学习,可以带来令人印象深刻的有效和高效的培训。

主动学习有效性的演示,图片来自作者
如下图所示,使用主动学习的贝叶斯神经网络只需 98,1 张训练图像即可达到 000% 的准确率。相比之下,不利用不确定性估计的模型往往以较慢的速度学习。
优势3:电感偏置
贝叶斯深度学习的另一个优点是通过先验有效地使用归纳偏置。先验允许我们对模型参数的初始信念或假设进行编码,这在存在领域知识的情况下特别有用。
考虑生成AI,其想法是创建类似于训练数据的新数据(如医学图像)。例如,如果你正在生成大脑图像,并且你已经知道大脑的总体布局——里面的白质,外面的灰质——这些知识可以包含在你的先验中。这意味着您可以为图像中心白质的存在以及两侧的灰质的存在分配更高的概率。
从本质上讲,贝叶斯深度学习不仅使模型能够从数据中学习,而且还使它们能够从知识点开始学习,而不是从头开始。这使其成为适用于各种应用的有力工具。

白质和灰质,图片由作者提供
六、贝叶斯深度学习的局限性
看来贝叶斯深度学习太不可思议了!那么,为什么这个领域被如此低估呢?事实上,我们经常谈论生成AI,聊天GPT,SAM或更传统的神经网络,但我们几乎从未听说过贝叶斯深度学习,为什么会这样?
限制1:贝叶斯深度学习很糟糕
理解贝叶斯深度学习的关键是我们“平均”模型的预测,只要有平均值,就会在参数集上有一个积分。
但是计算积分通常是棘手的,这意味着没有封闭或显式的形式可以使该积分的计算变得快速。所以我们不能直接计算它,我们必须通过采样一些点来近似积分,这使得推理非常慢。
想象一下,对于每个数据点x,我们必须平均出10,000个模型的预测,并且每个预测可能需要1秒才能运行,我们最终得到一个无法扩展大量数据的模型。
在大多数商业案例中,我们需要快速且可扩展的推理,这就是为什么贝叶斯深度学习不那么受欢迎的原因。
限制2:近似误差
在贝叶斯深度学习中,通常需要使用近似方法(如变分推理)来计算权重的后验分布。这些近似值可能会导致最终模型中的错误。近似的质量取决于变分族和散度的选择,正确选择和调整可能具有挑战性。
限制 3:模型复杂性和可解释性增加
虽然贝叶斯方法提供了改进的不确定性度量,但这是以增加模型复杂性为代价的。BNN 可能很难解释,因为我们现在对可能的权重进行了分布,而不是一组权重。这种复杂性可能会导致解释模型决策的挑战,尤其是在可解释性是关键的领域。
人们对XAI(可解释AI)的兴趣越来越大,传统的深度神经网络已经很难解释,因为很难理解权重,贝叶斯深度学习更具挑战性。
无论您是有反馈,想法要分享,想与我合作,还是只是想打个招呼,请填写下面的表格,让我们开始对话。
打招呼
七、引用
- 加拉马尼,Z.(2015)。概率机器学习和人工智能。自然,521(7553),452-459。链接
- Blundell,C.,Cornebise,J.,Kavukcuoglu,K.和Wierstra,D.(2015)。神经网络中的权重不确定性。arXiv预印本arXiv:1505.05424。链接
- Gal, Y., & Ghahramani, Z. (2016).作为贝叶斯近似的 Dropout:表示深度学习中的模型不确定性。在机器学习国际会议上(第1050-1059页)。链接
- Louizos,C.,Welling,M.和Kingma,D.P.(2017)。通过 L0 正则化学习稀疏神经网络。arXiv预印本arXiv:1712.01312。链接
- 尼尔,R.M.(2012)。神经网络的贝叶斯学习(第118卷)。施普林格科学与商业媒体。链接