多分类评估 Micro, Macro & Weighted Averages of F1 Score和适用场景
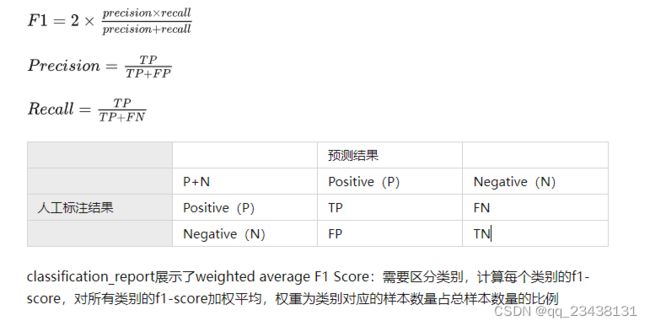
classification_report展示了weighted average F1 Score:需要区分类别,计算每个类别的f1-score,对所有类别的f1-score加权平均,权重为类别对应的样本数量占总样本数量的比例
Micro F1 Score:不需要区分类别,直接使用总体样本计算f1-score
Macro F1 Score:需要区分类别,根据每个类别,分别计算P、R、F1-score,将所有类别的f1-score取平均。
Accuracy :
from sklearn.metrics import f1_score
from sklearn.metrics import classification_report
f1_score([0,0,0,0,1,1,1,2,2], [0,0,1,2,1,1,2,1,2],average="micro")
0.5555555555555556
f1_score([0,0,0,0,1,1,1,2,2], [0,0,1,2,1,1,2,1,2],average="macro")
0.546031746031746
print(classification_report([0,0,0,0,1,1,1,2,2], [0,0,1,2,1,1,2,1,2]))
precision recall f1-score support
0 1.00 0.50 0.67 4
1 0.50 0.67 0.57 3
2 0.33 0.50 0.40 2
avg / total 0.69 0.56 0.58 9根据数据集选择哪种f1 score
如果数据集中类别不均衡,且每个类别都同等重要,使用Macro F1 Score;
如果数据集中类别不均衡,且数据集中样例多的类别更重要,使用Weighted Average F1 Score;
如果数据集中类别均衡,且想要一个简单的易理解的指标评估整体效果,使用Micro F1 Score;